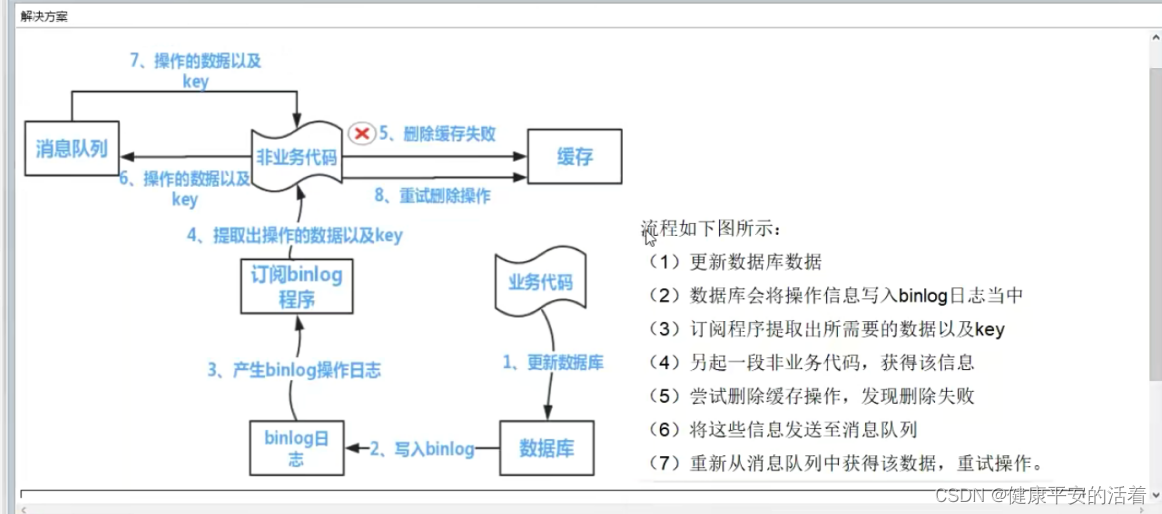
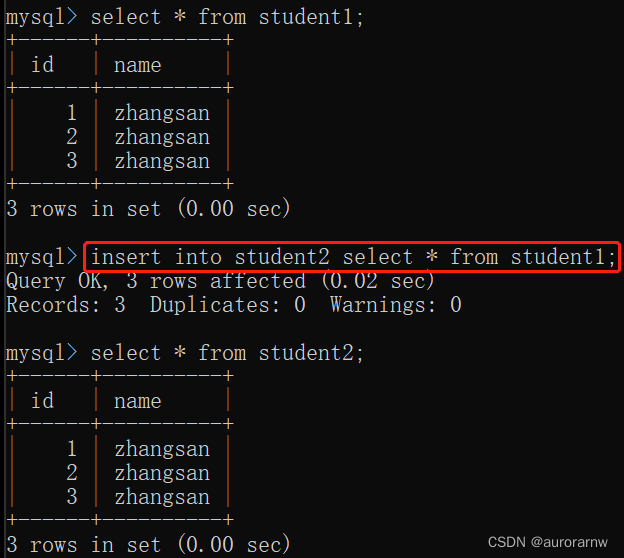
PS:插入查询结果
把一张表查询出的结果,插入到另一张表中。要求两张表的列数和列类型要匹配。
前面讲的所有select规则在此处都适用~

1.聚合查询
- 聚合查询:行和行之间进行运算。
- 带表达式查询:列和列之间进行运算。
常⻅的聚合函数(SQL里内置的函数)有:
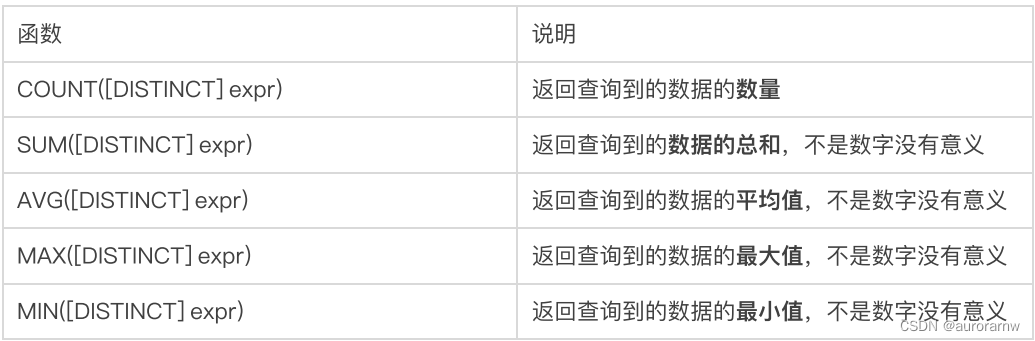
它们都是针对表中某个列的所有行来进行运算的~
MySQL的函数,相当于Java里的方法:
聚合函数需要设置参数,在查询中可以使用多次聚合函数,可以多个聚合函数一起使用。
不是数字的数据,直接舍弃。
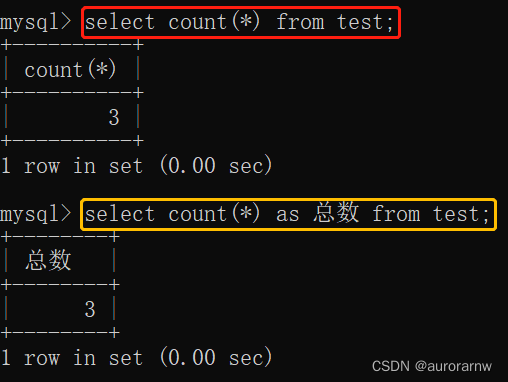
1.1.count函数
返回查询到的数据的条数。
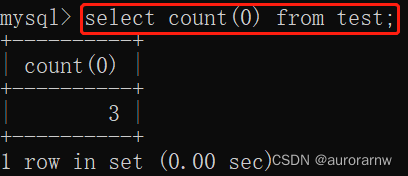
用法一:
能查询出所有null和非null的数据总和。推荐使用,最标准,MySQL、SQL Server、Oracle都能使用。
用法二:
能查询出所有null和非null的数据总和。兼容性不是很好,MySQL能用,其他数据库不一定能用。
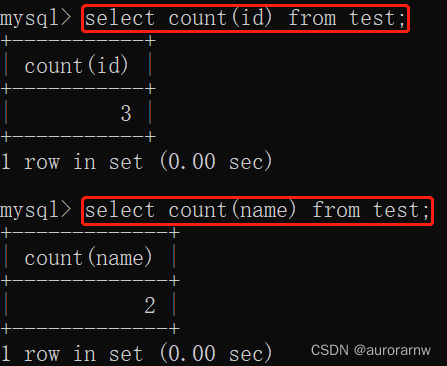
用法三:
count(列名),查询当前字段中非null的数据总和。不推荐使用,查询结果极不稳定。
建议写成:
用法四:
count(表达式)。
count(1)1就是常数表达式。
在不同的count统计场景下,要使用不同的count查询。
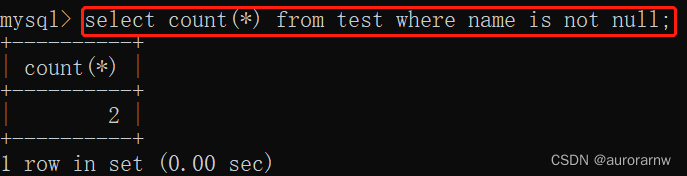
若要查询表中非null的数据总和,建议使用count(*)配合where条件使用。
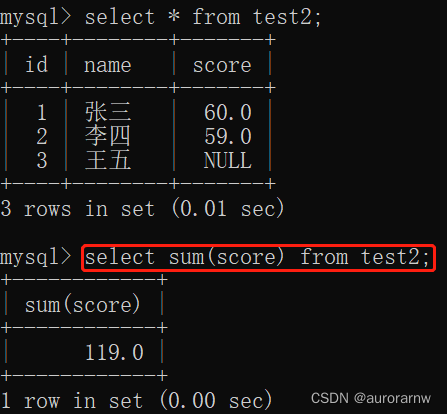
1.2.sum函数
返回查询到的数据的总和,不是数字没有意义。
PS:sum函数执行逻辑——只会统计有效的数据
判断数据是否为有效数据:
- 若是有效数据:会将其加入已经计算的结果集中。
- 若不是有效数据(NULL或非数值型(比如varchar型)):会将其看作0,并加入已经计算的结果集中。
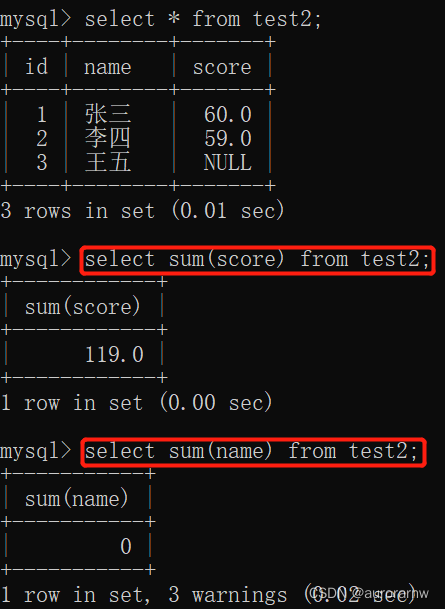
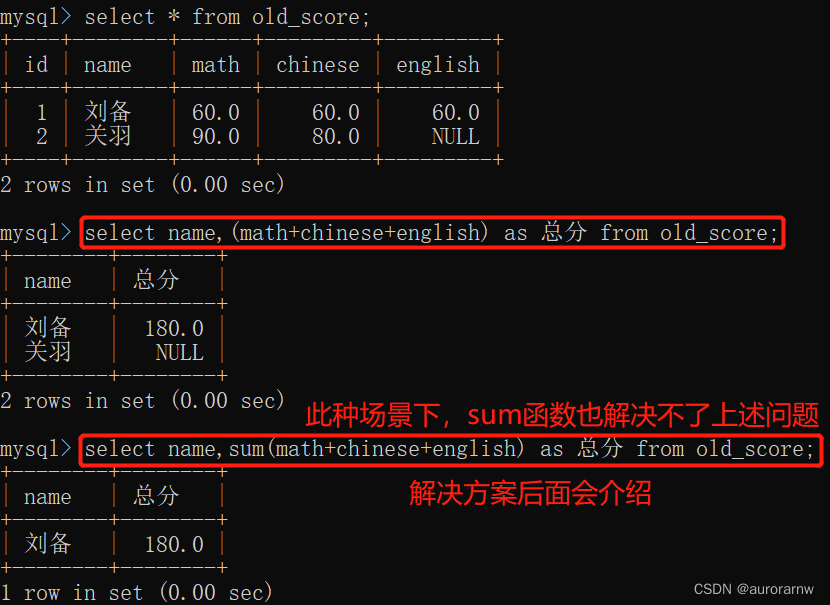
PS:sum函数查询 VS 表达式求和查询
若要求和查询的数据中包含NULL:
- sum函数:会把除去NULL外的其他数据进行求和运算。
- 表达式求和:直接得到和为NULL。
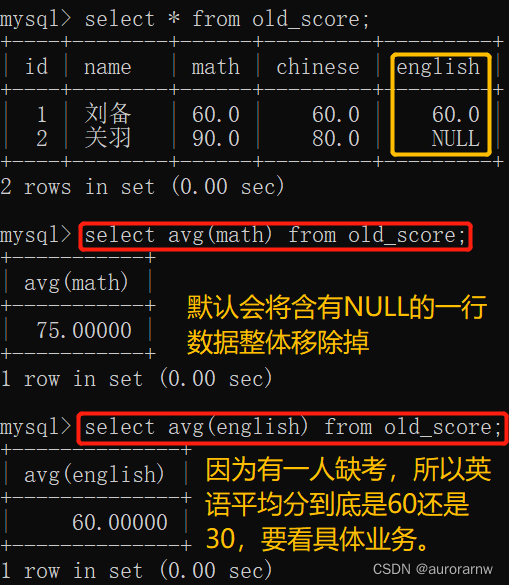
1.3.avg函数
返回查询到的数据的平均值,不是数字没有意义,会将含有不合规范数据的一行数据整体舍弃掉。
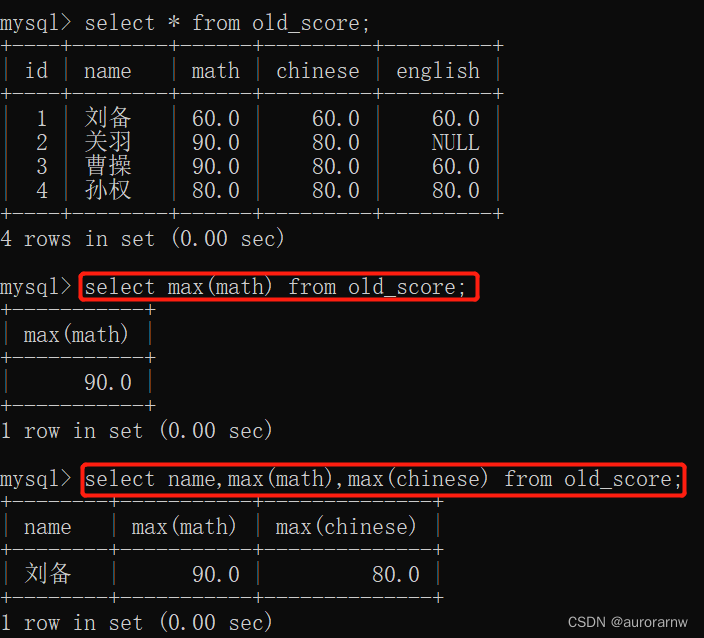
1.4.max函数
返回查询到的数据的最⼤值,不是数字没有意义。
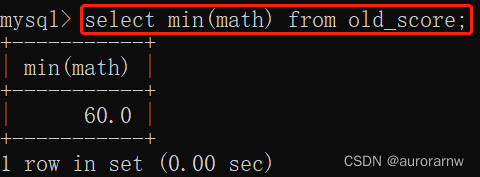
1.5.min函数
返回查询到的数据的最⼩值,不是数字没有意义。

PS:ifnull函数
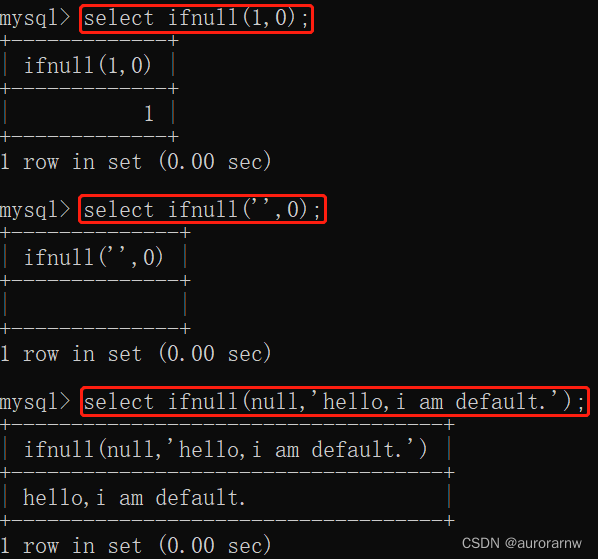
ifnull函数是 MySQL 控制流函数之⼀,它接收两个参数,如果第一个参数不是 NULL,则返回第⼀个参数,否则返回第⼆个参数。
ifnull(参数1,参数2);
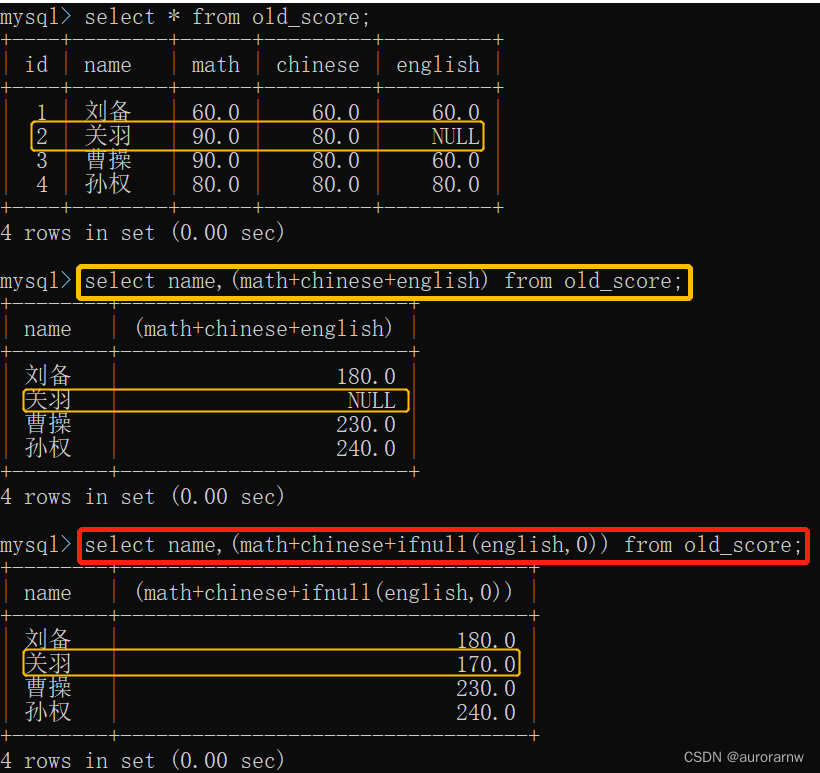
使用ifnull函数的实例——解决遗留问题:总成绩为null的问题
另外的解决⽅案:使⽤⾮空约束或默认值 0 来解决。
注:
- 在公司里多使用分布式多份部署,一份程序部署到了多台服务器,处理能力会是原来的多倍,但没有办法把MySQL分成多份。
- so~MySQL的资源很紧缺,而程序的资源相对不紧缺。在MySQL中应尽量不使用表达式和函数(它们应该是在Java程序里)。
所以这种问题最好在建表时就设置好非空约束,从而避免ifnull查询,减轻MySQL负担。

2.分组查询group by
select 中使⽤ group by ⼦句可以对指定列进⾏分组查询。需要满⾜:使⽤ group by 进⾏分组查询时,select 指定的字段必须是“分组依据字段”,其他字段若想出现在 select 中则必须包含在聚合函数中。
select 列名1, sum(列名2),...from 表名 group by 列名1, 列名3;PS:distinct(去重) VS group by(分组)
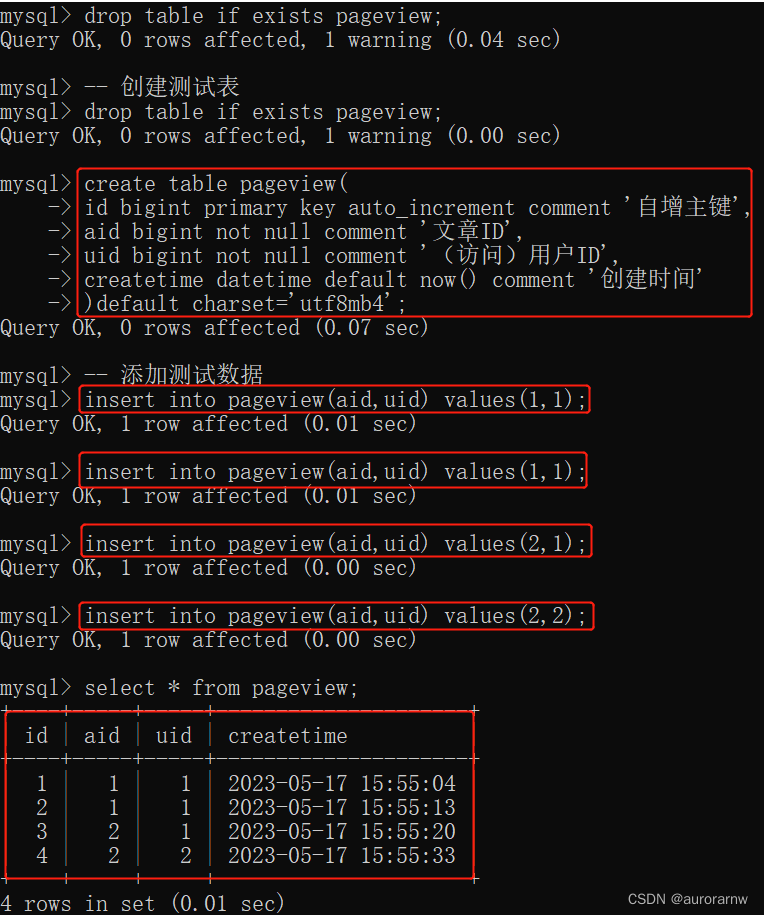
①创建测试数据
②distinct使用
基本语法:
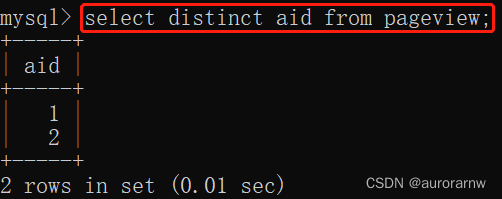
select distinct 列名 [,列名...] from 表名;a.单列去重
根据 aid(文章 ID)去重:
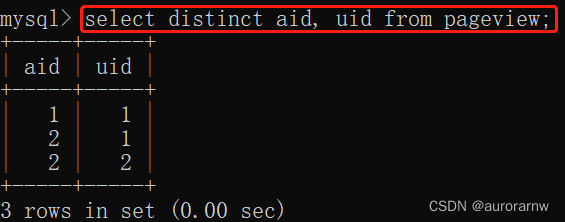
b.多列(两列及以上)去重
根据 aid(文章 ID)和 uid(用户 ID)联合去重:
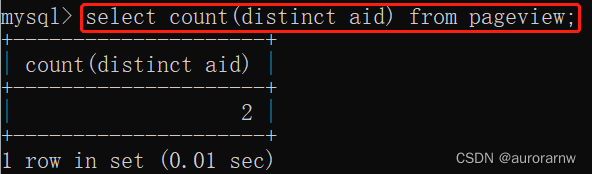
c.聚合函数 + distinct
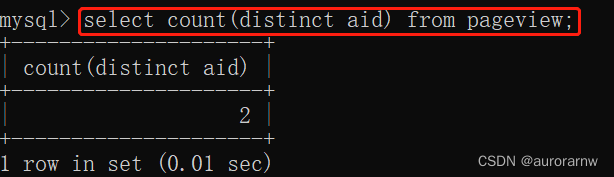
计算 aid 去重之后的总条数:
③group by使用
基本语法:
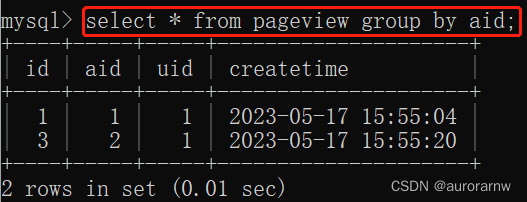
select 列名 [,列名...] from 表名 group by 列名a.单列去重
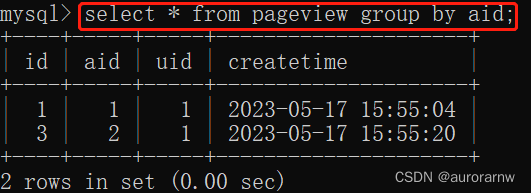
根据 aid(文章 ID)去重:
与 distinct 相比 group by 可以显示更多的列,而 distinct 只能展示去重的列。
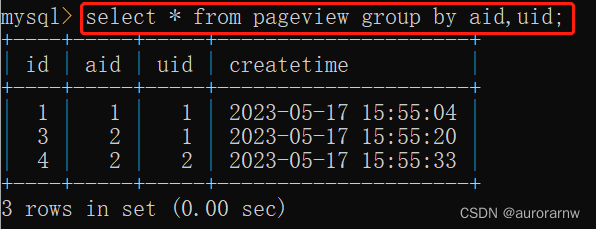
b.多列去重
根据 aid(文章 ID)和 uid(用户 ID)联合去重:
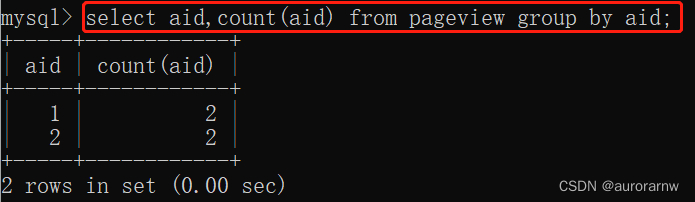
c.聚合函数 + group by
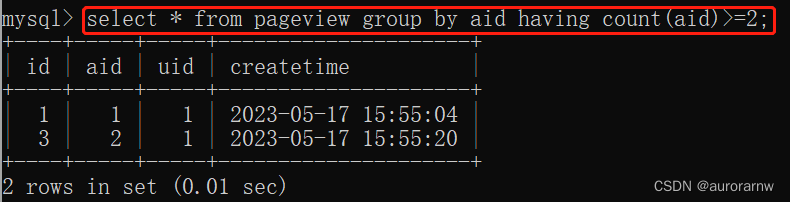
统计每个 aid 的总数量:
从上述结果可以看出,使用 group by 和 distinct 加 count 的查询语义是完全不同的,distinct + count 统计的是去重之后的总数量,而 group by + count 统计的是分组之后的每组数据的总数。
④distinct 和 group by的区别
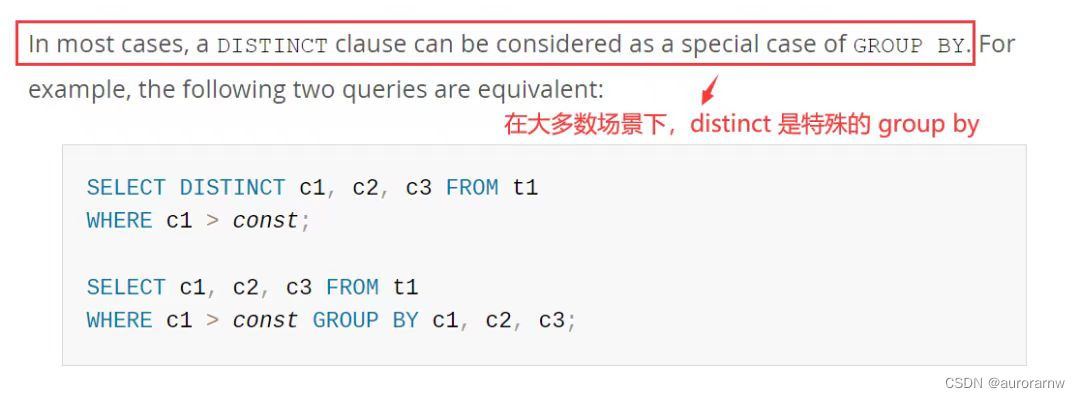
官方文档在描述 distinct 时提到:在大多数情况下 distinct 是特殊的 group by:
但二者还是有一些细微的不同的,比如以下几个:
区别1:查询结果集不同
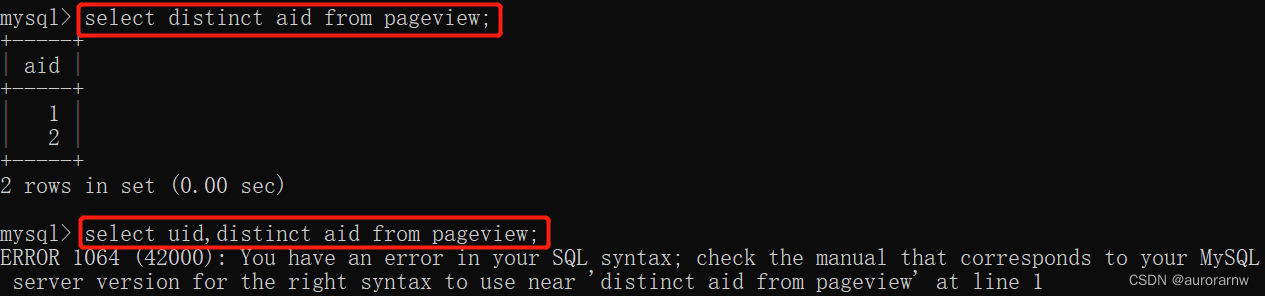
1)当使用 distinct 去重时,查询结果集中只有去重列信息。当试图添加非去重字段查询时,SQL 会报错:
2)而使用 group by 排序可以查询一个或多个字段:
区别2:使用业务场景不同
1)统计去重之后的总数量需要使用 distinct。使用 distinct 统计某列去重之后的总数量:
2)而统计分组明细,或在分组明细的基础上添加查询条件时,就得使用 group by 了。使用 group by 统计分组之后数量大于 2 的文章:
区别3:性能不同
- 如果去重的字段有索引,那么 group by 和 distinct 都可以使用索引,此情况它们的性能是相同的。
- 而当去重的字段没有索引时,distinct 的性能就会高于 group by,因为在 MySQL 8.0 之前,group by 有一个隐藏的功能会进行默认的排序,这样就会触发 filesort 从而导致查询性能降低。