13 人工神经网络(2)
- 多层神经网络-非线性分类问题
- 多层神经网络的损失函数不是凸函数,很难计算解析解
- 通常采用梯度下降法,得到数据解,梯度下降法可以用来求解函数极值问题
- 批量梯度下降
- 随机梯度下降
- 小批量梯度下降
13.1 小批量梯度下降法
13.1.1 批量梯度下降法

- 之前的算法采用的都是批量梯度下降法
- 每一步迭代的时候都会用到所有的样本,计算量大的惊人
- 即使使用向量计算,仍十分耗费时间
13.1.2 随机梯度下降法(Stochastic Gradient Decent,SGD)
- 每次迭代只选择一个样本训练模型,使网络的输出尽可能逼近这个样本的标签值,当训练误差足够小时,结束本次训练,在输入下一个新的样本,显然使用前面样本训练的网络参数不一定能够使得后面的新样本误差最小,所以这个新样本需要再重新训练网络,重复这个过程,直到所有的样本都训练一遍之后。
- 这个过程称为一轮:使用所有样本训练一遍
- 反复训练多轮,直到网络对所有样本的误差足够小。
- 参数更新非常频繁,训练次数非常多,无法快速收敛
- 不易于实现并行计算
- 所以现在说的随机梯度下降通常是指小批量梯度下降算法
13.1.3 小批量梯度下降(Mini-Batch Gradient Decent,MBGD)
- 也成为小批量随机梯度下降(Mini-Batch SGD)
- 把数据分为多个小批量,每次迭代使用一个小批量来训练模型
- 每个小批量中的所有样本共同决定了本次迭代中梯度的方向
- 一轮:使用所有小批量训练一遍
- 需要训练多轮,使网络对所有样本的误差足够小
- 每次迭代的训练样本数固定,与整个训练集的样本数量无关
- 训练大规模数据集
- 是抽样(Samping的思想
- 从数据集中随机抽取出来一部分样本,它们的特征可以在一定程度上代表完整数据集的特征
- 应该是独立同分布:小批量样本能够代表整个样本集的特征。但是实际中,是很难做到这一点的。
- 随机抽取:小批量样本的特征和整体样本的特征存在差异
- 小批量梯度下降
- 小批量样本计算出的梯度和使用全部样本计算出的标准梯度之间存在偏差。
- 总体向最优化的方向前进
- 提高模型的泛化能力
13.2 梯度下降法的优化
- 多层神经网络使用梯度下降法,无法保证一定可达到最小值点
13.2.1 影响小批量下降法的主要因素
- 小批量样本的选择
- 批量大小
- 学习率
- 梯度
13.2.1.1 小批量样本的选择
- 在每轮训练之前,打乱样本顺序
- 因为数据集的连续样本之前有高度的相关性
13.2.1.2 小批量样本的数量(mini-batch size)(批量大小)
- 批量中的样本数量越多,梯度方向越准确,迭代次数越少
- 批量梯度下降法:小批量样本=整个数据集
- 批量中的样本数量越少,随机性越大,迭代次数越多
- 随机梯度下降法:小批量样本数=1
- 充分利用处理器资源,进行并行计算
- 批量大小使用2的幂数:32,64,128,256
13.2.1.3 学习率
- 之前都是设置为固定的学习率
- 学习率设置过小,收敛速度慢;
- 学习率设置过大,震荡,无法收敛
- 动态调整学习率:在训练过程中,动态的调整学习率
- 对于凸函数,可以采用学习率衰减(Learning Rate Decay)/学习率退火(Learning Rate Annealing)
- 开始训练时,设置较大学习率,加快收敛速度
- 迭代过程中,学习率随着迭代次数逐渐减小,避免震荡
- 调节学习率–非凸函数
- 周期性的增大学习率
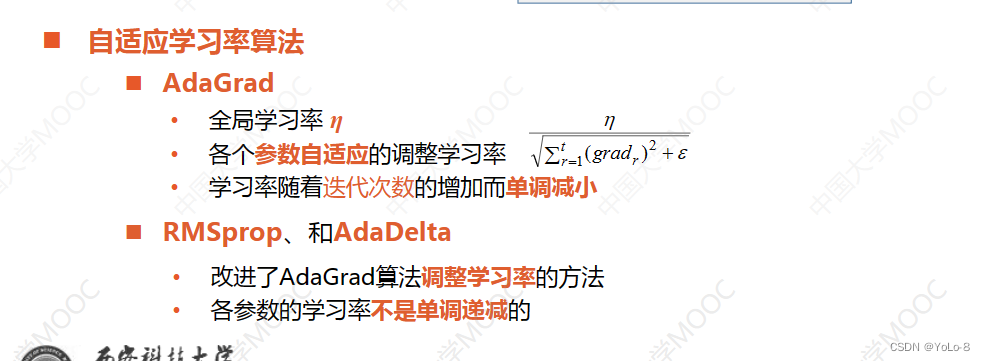
- 自适应的调整学习率
- 自适应调整每个参数的学习率
-
自适应学习率算法
-
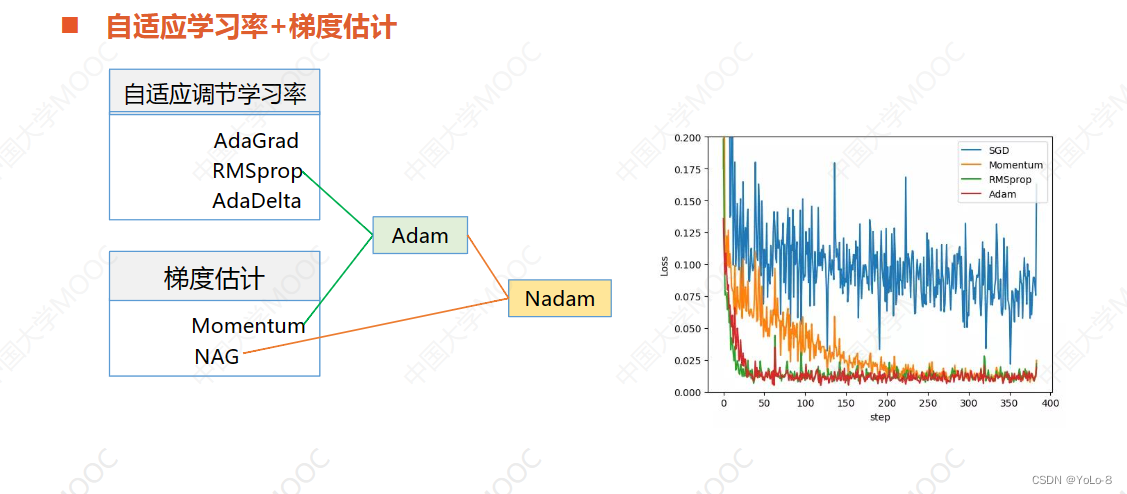
梯度估计
动量项的作用

-
牛顿加速梯度算法(Nesterov Accelerated Gradient,NAG)

13.3 keras和tf.keras
13.3.1 keras
- Python编写的开源人工神经网络库
- 采用面向对象的方法编写,提供了大量的封装好的模块,使得搭建神经网络模型就好像搭建积木一样简答快捷,容易上手
- keras支持神经网络和深度学习领域的主流算法,并且具有很好的可扩展性
- 支持多操作系统下的多GPU并行计算
- 作为深度学习库的前端,快速构建和训练深度学习模型
- 要注意的是,keras只是一个前端工具,是介于计算引擎和程序员之间的接口,不能离开后端计算引擎独立的工作,keras默认的后端是tensorflow,也可以指定其他的如CNTK、Theano
- 因此使用keras时,可以使用两种方法:第一种方法是把keras作为一个独立的开发工具进行安装,tensorflow作为它的后端;第二种方法是将它作为tensorflow的高级API来使用,在tensorflow1.4版本之后,keras已经成为tensorflow的官方API
- Tensorflow具备keras的简单性
- Keras具备Tensorflow的强大性,能够在任何规模,一切平台上实现人工智能的应用
- 一般时第二种方式
13.4 Sequential模型
- tf.keras
- TensorFlow的高级API
- 快速搭建和训练神经网络模型
- 主要数据结构时模型(model)
- Sequential模型
- 其是Keras中的一种神经网络框架,可以被认为是一个容器,其中封装了神经网络的结构
- 只有一组输入和一组输出
- 各层之间按照先后顺序堆叠,前面一层的输出就是后面一层的输入,通过不同层的堆叠构建出神经网络
13.4.1 建立Sequential模型
model=tf.keras.Sequential()
>>> import tensorflow as tf
>>> model = tf.keras.Sequential()
>>> model
<tensorflow.python.keras.engine.sequential.Sequential object at 0x00000210D1ABFCC8>
13.4.2 添加层
model.add(tf.keras.layers...)
tf.keras.layers.Dense( # Dense表示全连接层
inputs # 输入该网络层的数据,表示这个层中神经元的个数
activation # 激活函数,以字符串的形式给出,如‘relu’、‘softmax’、‘sigmoid’、‘tanh’
input_shape # 输入数据的形状,全连接神经网络的第一层接受来自输入层的数据,必须要指定形状,后面的层接受前面一层的输出,不用再指明输入数据的情况
)
13.4.3 查看摘要
在定义神经网络之后,可以使用它的summary()方法来查看网络的结构和参数信息
model.summary()
13.4.4 对于多分类任务-三层神经网络
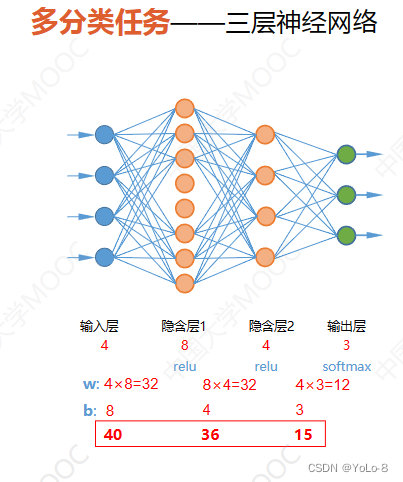
下面我们就是用Sequential模型来构建这个网络
>>> import tensorflow as tf
>>>
>>> model = tf.keras.Sequential()
>>> model.add(tf.keras.layers.Dense(8,activation="relu",input_shape=(4,))) # 添加第一层
隐含层,其中有8个神经元,采用relu函数作为激活函数,输入数据的形状为4
>>> model.add(tf.keras.layers.Dense(4,activation="relu")) # 添加第二层隐含层,relu激活
函数,采用上层输出作为输出,不用说明输入
>>> model.add(tf.keras.layers.Dense(3,activation="softmax")) # 添加输出层
>>>
>>> model.summary()
Model: "sequential_1"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
dense (Dense) (None, 8) 40
_________________________________________________________________
dense_1 (Dense) (None, 4) 36
_________________________________________________________________
dense_2 (Dense) (None, 3) 15
=================================================================
Total params: 91
Trainable params: 91
Non-trainable params: 0
_________________________________________________________________
也可以采用下面形式,直接将其作为参数,建议大家使用第一种方式
model = tf.keras.Sequential([
tf.keras.layers.Dense(8,activation="relu",input_shape=(4,)),
tf.keras.layers.Dense(4,activation="relu"),
tf.keras.layers.Dense(3,activation="softmax")])
13.4.5 配置训练方法
model.compile(loss,optimizer,metrics)
- loss:是损失函数
- optimizer:是优化器
- metrics:是模型训练时希望输出的评测指标
13.4.5.1 model.compile()的损失函数loss
- 损失函数:这是tf.keras中常用的损失函数,可以以字符串方式给出,也可以是函数形式
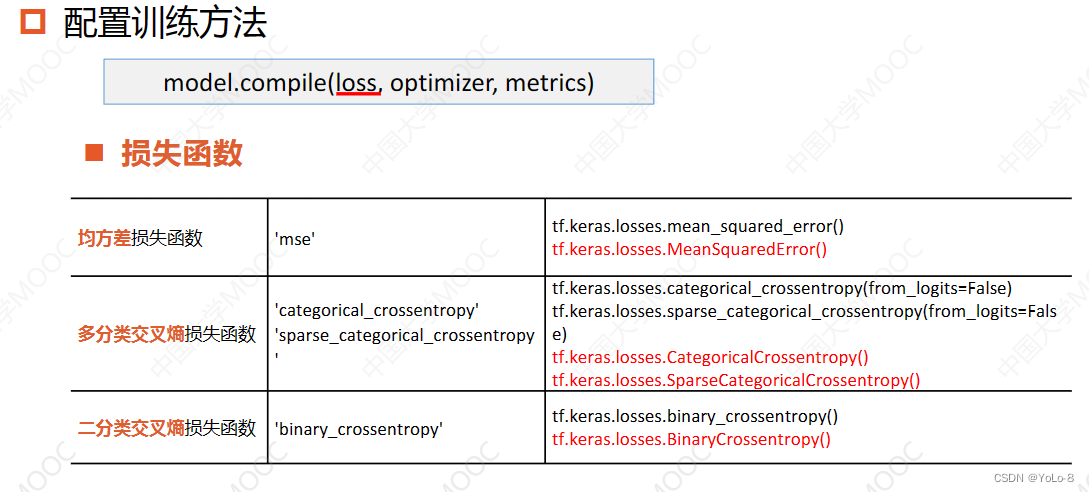
- 第二行的第一个用于独热编码方式的标签值,交叉熵损失函数中有一个参数from_logits是神经网络在输出前已经使用softmax函数将预测结果变换为概率分布,所有的输出之和为1,前面介绍的多分类网络都是这样做的;也有没有的网络在输出前没有经过softmax变化,是原始的输出,那么需要将这个参数的值设置为true
- 第二行的第二个用于自然顺序码的标签值
- 第三行是逻辑回归时使用的交叉熵损失函数,与激活函数sigmoid搭配使用,实现二分类任务
13.4.5.2 model.compile()的优化器optimizer

- 可以使用前面的字符串形式,也可以使用后面的函数形式
- 使用后面的函数形式,可以配置参数
- 在tensorflow1.x中,使用tf.train.optimizer
- 在tensorflow2.x中,使用tf.keras.optimizer广泛使用
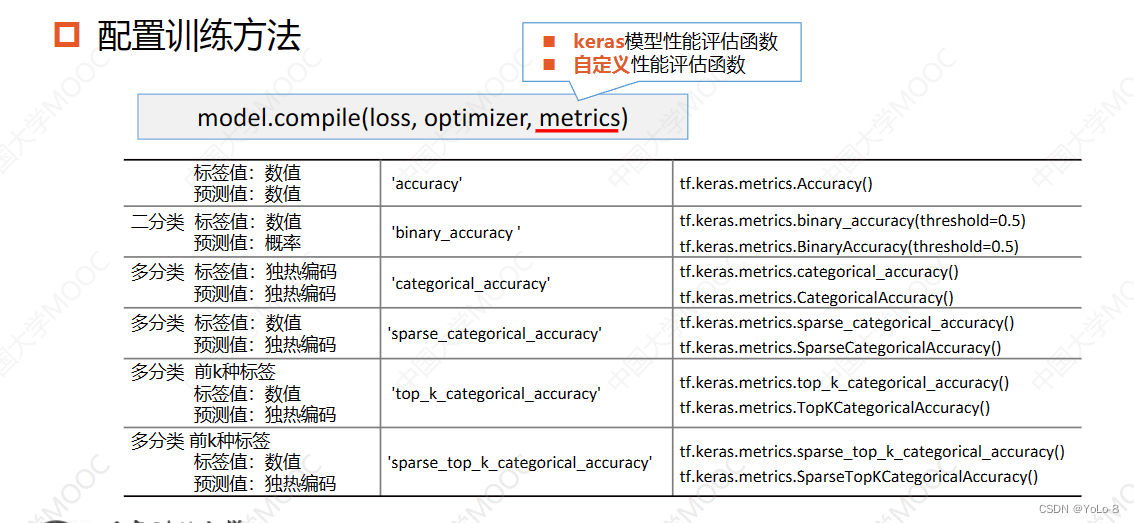
13.4.5.3 model.compile()的评测指标metrics
- 这里可以使用keras模型性能评估函数
- 自定义性能评估函数
13.4.5.4 iris鸢尾花数据中的配置
- 这是鸢尾花分类中的语句
model.compile(optimizer=tf.keras.optimizers.SGD(lr=0.1),
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=False),
metrics=[tf.keras.metrics.SparseCategoricalAccuracy()])
- 优化器采用小批量下降法,这里使用函数形式应用,设置学习率为0.1
- 鸢尾花数据集中,鸢尾花的类别采用自然顺序码表示,神经网络的输出经过softmax函数变换后得到的向量模式,因此损失函数采用稀疏交叉熵损失函数,参数from_logits设置为False,iris标签值数值,预测值是独热编码
- 准确率函数稀疏交叉熵准确率,注意要使用中括号括起来,在这里,可以使用多个评价函数
- 如果我们已经把鸢尾花的标签值由数值形式改为了独热编码形式,那么就要改为相应的如下形式
model.compile(optimizer=tf.keras.optimizers.SGD(lr=0.1),
loss=tf.keras.losses.CategoricalCrossentropy(from_logits=False),
metrics=[tf.keras.metrics.CategoricalAccuracy()])
13.4.5.5 手写数字识别中的配置Mnist
其中的参数全部采用字符串形式
model.compile(optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['sparse_categorical_accuracy'])
13.4.6 训练模型
model.fit(训练集的输入特征,训练集的标签,
batch_size = 批量大小,
epochs = 迭代次数,
shuffle = 是否每轮训练之前打乱数据,默认为true
validation_data = (测试集的输入特征,测试集的标签),这个参数和下面那个参数是二选一的,如果同时给出,data将覆盖比例
validation_split = 从训练集划分多少比例给测试集,取值为0~1
validation_freq = 测试频率,每隔多少论训练,输出一次评测指标
verbose = 日志显示形式,0:不再标准输出流输出;1:输出进度条记录;2:每个epoch输出一次记录
)
- 在程序运行中,是先执行划分数据集,然后再打乱,因此如果数据是有序的,在执行中,应该首先打乱数据集,
- 下面给出fit方法的输出默认值
model.fit(x=None,y=None,batch_size=32,epochs=1,shuffle=True,validation_data=None,validation_split=0.0,validation_freq=1,verbose=1)
- 下面给出手写数字识别的fit代码
history = model.fit(X_train,y_train,batch_size=32,epochs=5,validation_split=0.2)
history.history # 可以使用这查看列表储存的信息
13.4.7 评估模型
model.evaluate(test_set_x,test_set_y,batch_size,verbose)
第一个返回值是损失,第二个返回值是在model.compile()方法中指定的性能指标
13.4.8 使用模型
训练好模型之后,就可以使用它来进行分类了,通过模型的predict方法来实现
model.predict(x,batch_size,verbose)
- x:数据的属性值
- batch_size:当输入批量数据时,模型就会根据batch_size的大小来分批量的运行数据,这样比每次运行一个样本更快,也防止了同时多个数据超过内存的情况,
13.5 实例: Sequential模型实现手写数字识别
- Sequential模型
- 只有一组输入和一组输出
- 各个层按照先后顺序堆叠
- 实现分为六个步骤
- 建立模型
model = tf.keras.Sequential()
model.add()
- 查看摘要
model.summary()
- 配置训练方法
model.compile()
- 训练模型
model.fit()
- 评估模型
model.evaluate()
- 使用模型
model.predict()
- 在这节课中,我们就是用Sequential模型实现手写数据数据集MNIST
13.5.1 设计神经网络结构
- MNIST数据集中的每个手写图片都是28*28的,用图片作为神经网络的输入时,通常把它拉成一个一维张量送入神经网络,因此输入层中有184个节点
- 我们使用有一个隐含层的全连接网络来实现手写数字识别,这些数字从0到9分为10类,输出层中有十个神经元,分别是当前图片属于每个数字的概率
- 这是一个多分类任务,因此输出层采用softmax函数作为激活函数
- 隐含层我们设计128个神经元,使用relu函数作为激活函数
- 在MNIST数据集中,标签是作为0到9的数字,可以直接使用数值标签计算稀疏交叉熵损失函数,而无需把他们转换为独热编码的形式。损失函数:SparseCategoricalCrossentropy
- 在输入层和隐含层之间共784*128+128=100480参数
- 在隐含层和输出层之间共128*10+10=1290参数
- 一共101770个数字
13.5.2 代码的实现
# 1 导入库
import tensorflow as tf
print("TensorFlow version: ", tf.__version__)
import numpy as np
import matplotlib.pyplot as plt
# 在使用GPU版本的Tensorflow训练模型时,有时候会遇到显存分配的错误
# InternalError: Bias GEMM launch failed
# 这是在调用GPU运行程序时,GPU的显存空间不足引起的,为了避免这个错误,可以对GPU的使用模式进行设置
gpus = tf.config.experimental.list_physical_devices('GPU')# 这是列出当前系统中的所有GPU,放在列表gpus中
# 使用第一块gpu,所以是gpus[0],把它设置为memory_growth模式,允许内存增长也就是说在程序运行过程中,根据需要为TensoFlow进程分配显存
# 如果系统中有多个GPU,可以使用循环语句把它们都设置成为true模式
tf.config.experimental.set_memory_growth(gpus[0], True)
# 2 加载数据
mnist = tf.keras.datasets.mnist
(train_x,train_y),(test_x,test_y) = mnist.load_data()
# (60000,28,28),(60000,),(10000,28,28),(10000,)
# numpy.ndarray,numpy.ndarray,numpy.ndarray,numpy.ndarray
# 3 数据预处理,这里也可以省去,在之后为进行维度变换
# X_train = train_x.reshape((60000,28*28)) # (60000,784)
# X_test = test_x.reshape((10000,28*28)) # (10000,784)
# 对属性进行归一化,使它的取值在0~1之间,同时转换为tensorflow张量,类型为tf.int16
X_train,X_test = tf.cast(train_x/255.0,tf.float32),tf.cast(test_x/255.0,tf.float32)
y_train,y_test = tf.cast(train_y,tf.int16),tf.cast(test_y,tf.int16)
# 4 建立模型
model = tf.keras.Sequential()
# 首先添加一个Flatten,说明输入层的形状,其不进行计算,只是完成形状转换,
# 把输入的属性拉直,变成一维数组,这样在数据预处理阶段,不用改变数据的形状,隐含层中也不用说明输入数据,各层结构更加清晰
model.add(tf.keras.layers.Flatten(input_shape=(28,28)))
model.add(tf.keras.layers.Dense(128,activation="relu")) # 添加隐含层
model.add(tf.keras.layers.Dense(10,activation="softmax")) # 添加输出层
# model.summary()函数查看网络结构和信息
# 5 配置模型的训练方法
model.compile(optimizer = 'adam', # 优化器使用adam,这里不用设置其中的参数,因为keras中已经使用公开的参数作为默认值,大多数情况下,都可以得到好的结果
loss = 'sparse_categorical_crossentropy', # 损失函数使用稀疏交叉熵损失函数
metrics = ['sparse_categorical_accuracy']) # 标签值:0~9;预测值:概率分布,类似于独热编码;所以使用稀疏分类准确率函数
# 6 训练模型
# 从中划分出20%作为测试数据
model.fit(X_train,y_train,batch_size = 64,epochs=5,validation_split=0.2)
# 7 评估模型
# 在这里,使用mnist本身的测试集评估模型
model.evaluate(X_test,y_test,verbose=2)
# 8 使用模型
np.argmax(model.predict([[X_test[0]]]))# 两层中括号
# 随机抽取4个样本
for i in range(4):
num = np.random.randint(1,10000)
plt.subplot(1,4,i+1)
plt.axis("off")
plt.imshow(test_x[num],cmap='gray')
y_pred = np.argmax(model.predict([[X_test[num]]]))
plt.title("y="+str(test_y[num])+"\ny_pred"+str(y_pred))
plt.show()
输出结果为:
rain on 48000 samples, validate on 12000 samples
Epoch 1/5
2021-12-19 21:01:08.858052: I tensorflow/stream_executor/platform/default/dso_loader.cc:44] Successfully opened dynamic library cublas64_100.dll
48000/48000 [==============================] - 3s 53us/sample - loss: 0.3291 - sparse_categorical_accuracy: 0.9077 - val_loss: 0.1822 - val_sparse_categorical_accuracy: 0.9500
Epoch 2/5
48000/48000 [==============================] - 2s 38us/sample - loss: 0.1520 - sparse_categorical_accuracy: 0.9557 - val_loss: 0.1402 - val_sparse_categorical_accuracy: 0.9592
Epoch 3/5
48000/48000 [==============================] - 2s 39us/sample - loss: 0.1061 - sparse_categorical_accuracy: 0.9693 - val_loss: 0.1183 - val_sparse_categorical_accuracy: 0.9656
Epoch 4/5
48000/48000 [==============================] - 2s 39us/sample - loss: 0.0805 - sparse_categorical_accuracy: 0.9766 - val_loss: 0.0995 - val_sparse_categorical_accuracy: 0.9709
Epoch 5/5
48000/48000 [==============================] - 2s 39us/sample - loss: 0.0643 - sparse_categorical_accuracy: 0.9812 - val_loss: 0.0950 - val_sparse_categorical_accuracy: 0.9711
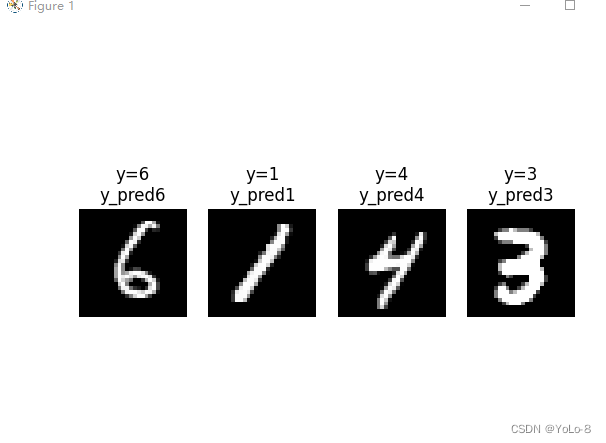
13.6 实例:模型的保存和加载
13.6.1 保存模型参数
model.save_weights(filepath,
overwrite = true,
save_format = None)
- 可以保存为HDF5格式
- 或者TensorFlow的SavedModel格式
13.6.1.1 HDF5格式
- 文件名后缀
- **.h5
- **.keras
- save_format = None时被保存为HDF5格式
- 分层数据格式(Hierarchical Data Format)是一种二进制的文件格式,可以看作是一个包含group和dataset的容器
- group可以看作是一个文件夹,文件夹下存放子文件夹,子文件夹下存放数据
- dataset是具体的数据,类似于numpy中的多维数组
- 使用HDF5来存放数据,效率很高,非常适合存储大量的数据,因此常用来保存多维数据和图像
13.6.1.2 SavedModel格式
- 如果在文件中没有指明后缀,那么模型参数就被保存为TensorFlow的SavedModel格式
- 为了更加清晰,保存为这种格式的时候,会把save_format=“tf”
- SavedModel是Tensorflow特有的一种序列文化格式,采用这种格式时,信息不是被保存在一个文件中,而是需要多个文件
- model.save_weights(“mnist_weights”,save_format=“tf”)
这条语句会出现4个文件,其中checkpoint文件是检查文件,保存模型的相关信息;data文件用来保存所有的可训练变量,也就是模型参数的值;.index文件用来保存变量关键字和值之间对应关系。

13.6.1.3 overwrite参数
- 表示当指定写入的文件已经存在时,是否直接覆盖原来的数据,默认为true
- 如果将这个参数设置为false,那么就会出现提示,文件已经存在,是否进行覆盖
13.6.2 加载模型参数
model.load_weight(filepath)
13.6.2 实例:使用Sequential模型实现手写数字识别进行保存和加载模型参数
- 运行13.5.2的代码之后,可以在最后加上一句
model.save_weight("mnist_weights.h5")
- 然后会出现一个新的文件,在当前目录下
- 当然也可以保存在指定位置
- 然后使用它
# 6 调用已经训练好的参数文件
model.load_weights("mnist_weights.h5")
model.evaluate(X_test,y_test,verbose=2)
13.6.2.1 完整演示代码
# 1 导入库
import tensorflow as tf
print("TensorFlow version: ", tf.__version__)
import numpy as np
import matplotlib.pyplot as plt
# 在使用GPU版本的Tensorflow训练模型时,有时候会遇到显存分配的错误
# InternalError: Bias GEMM launch failed
# 这是在调用GPU运行程序时,GPU的显存空间不足引起的,为了避免这个错误,可以对GPU的使用模式进行设置
gpus = tf.config.experimental.list_physical_devices('GPU')# 这是列出当前系统中的所有GPU,放在列表gpus中
# 使用第一块gpu,所以是gpus[0],把它设置为memory_growth模式,允许内存增长也就是说在程序运行过程中,根据需要为TensoFlow进程分配显存
# 如果系统中有多个GPU,可以使用循环语句把它们都设置成为true模式
tf.config.experimental.set_memory_growth(gpus[0], True)
# 2 加载数据
mnist = tf.keras.datasets.mnist
(train_x,train_y),(test_x,test_y) = mnist.load_data()
# (60000,28,28),(60000,),(10000,28,28),(10000,)
# numpy.ndarray,numpy.ndarray,numpy.ndarray,numpy.ndarray
# 3 数据预处理,这里也可以省去,在之后为进行维度变换
# X_train = train_x.reshape((60000,28*28)) # (60000,784)
# X_test = test_x.reshape((10000,28*28)) # (10000,784)
# 对属性进行归一化,使它的取值在0~1之间,同时转换为tensorflow张量,类型为tf.int16
X_train,X_test = tf.cast(train_x/255.0,tf.float32),tf.cast(test_x/255.0,tf.float32)
y_train,y_test = tf.cast(train_y,tf.int16),tf.cast(test_y,tf.int16)
# 4 建立模型
model = tf.keras.Sequential()
# 首先添加一个Flatten,说明输入层的形状,其不进行计算,只是完成形状转换,
# 把输入的属性拉直,变成一维数组,这样在数据预处理阶段,不用改变数据的形状,隐含层中也不用说明输入数据,各层结构更加清晰
model.add(tf.keras.layers.Flatten(input_shape=(28,28)))
model.add(tf.keras.layers.Dense(128,activation="relu")) # 添加隐含层
model.add(tf.keras.layers.Dense(10,activation="softmax")) # 添加输出层
# model.summary()函数查看网络结构和信息
# 5 配置模型的训练方法
model.compile(optimizer = 'adam', # 优化器使用adam,这里不用设置其中的参数,因为keras中已经使用公开的参数作为默认值,大多数情况下,都可以得到好的结果
loss = 'sparse_categorical_crossentropy', # 损失函数使用稀疏交叉熵损失函数
metrics = ['sparse_categorical_accuracy']) # 标签值:0~9;预测值:概率分布,类似于独热编码;所以使用稀疏分类准确率函数
# 6 调用已经训练好的参数文件
model.load_weights("mnist_weights.h5")
model.evaluate(X_test,y_test,verbose=2)
# 8 使用模型
np.argmax(model.predict([[X_test[0]]]))# 两层中括号
# 随机抽取4个样本
for i in range(4):
num = np.random.randint(1,10000)
plt.subplot(1,4,i+1)
plt.axis("off")
plt.imshow(test_x[num],cmap='gray')
y_pred = np.argmax(model.predict([[X_test[num]]]))
plt.title("y="+str(test_y[num])+"\ny_pred"+str(y_pred))
plt.show()
- save_weight()方法仅保存了神经网络的模型参数
- 使用load_weight方法之前,需要首先定义一个完全相同的神经网络模型,否则就会出现模型没有定义的提示。
- 也就是说
model.load_weights()仅仅是替代了model.fit(),不用重新替代模型
13.6.2 实例:保存整个模型
model.save(filepath,
overwrite=True,
include_optimizer=True,
save_format=None
)
- include_optimizer = True:是否保存优化器当前的状态,默认为true,有时时间过长,我们可能需要终止训练,那么就需要保存当前状态,下次运行时就可以从这个断点开始。
- 可以保存神经网络的结构
- 模型参数
- 配置信息(优化器、损失函数等)
- 优化器状态
13.6.2.1 保存格式
使用方法几乎和保存参数相同

13.6.2.2 加载模型
- 需要使用它时,使用下面语句
tf.keras.models.load_model()
13.6.2.3 使用演示
- 只需要在刚才训练的代码后面增加一条
model.save("mnist_model_all.h5")

- 加载演示
# 1 导入库
import tensorflow as tf
print("TensorFlow version: ", tf.__version__)
import numpy as np
import matplotlib.pyplot as plt
# 在使用GPU版本的Tensorflow训练模型时,有时候会遇到显存分配的错误
# InternalError: Bias GEMM launch failed
# 这是在调用GPU运行程序时,GPU的显存空间不足引起的,为了避免这个错误,可以对GPU的使用模式进行设置
gpus = tf.config.experimental.list_physical_devices('GPU')# 这是列出当前系统中的所有GPU,放在列表gpus中
# 使用第一块gpu,所以是gpus[0],把它设置为memory_growth模式,允许内存增长也就是说在程序运行过程中,根据需要为TensoFlow进程分配显存
# 如果系统中有多个GPU,可以使用循环语句把它们都设置成为true模式
tf.config.experimental.set_memory_growth(gpus[0], True)
# 2 加载数据
mnist = tf.keras.datasets.mnist
(train_x,train_y),(test_x,test_y) = mnist.load_data()
# (60000,28,28),(60000,),(10000,28,28),(10000,)
# numpy.ndarray,numpy.ndarray,numpy.ndarray,numpy.ndarray
# 3 数据预处理,这里也可以省去,在之后为进行维度变换
# X_train = train_x.reshape((60000,28*28)) # (60000,784)
# X_test = test_x.reshape((10000,28*28)) # (10000,784)
# 对属性进行归一化,使它的取值在0~1之间,同时转换为tensorflow张量,类型为tf.int16
X_train,X_test = tf.cast(train_x/255.0,tf.float32),tf.cast(test_x/255.0,tf.float32)
y_train,y_test = tf.cast(train_y,tf.int16),tf.cast(test_y,tf.int16)
# 6 调用已经训练好的参数文件
model = tf.keras.models.load_model("mnist_model_all.h5")
model.evaluate(X_test,y_test,verbose=2)
# 8 使用模型
np.argmax(model.predict([[X_test[0]]]))# 两层中括号
# 随机抽取4个样本
for i in range(4):
num = np.random.randint(1,10000)
plt.subplot(1,4,i+1)
plt.axis("off")
plt.imshow(test_x[num],cmap='gray')
y_pred = np.argmax(model.predict([[X_test[num]]]))
plt.title("y="+str(test_y[num])+"\ny_pred"+str(y_pred))
plt.show()
【参考文献】: 神经网络与深度学习——TensorFlow实践
![[Nacos] Nacos Client获取所有服务和定时更新Client端的注册表 (三)](https://img-blog.csdnimg.cn/59115e29f79344f6a06c3ac7446547c9.png)