目录
1、阻塞队列
1.1、概念
1.2、生产者消费者模型
1.3、阻塞队列的模拟实现
2、定时器
2.1、使用标准库中的定时器
2.2、模拟实现定时器
3、线程池
3.1、标准库中的线程池
3.1.1、ThreadPoolExecutor类的构造方法
3.1.2、Java标准库的4种拒绝策略【经典面试题】【重点】
3.1.3、工厂模式
3.2、模拟实现线程池
1、阻塞队列
1.1、概念
就像我们数据结构中说到的优先级队列PriorityQueue(堆),阻塞队列和优先级队列都是特殊的队列,满足先进先出的原则。阻塞队列是一种线程安全的数据结构。
1️⃣阻塞队列的特性:
- 如果队列为空,尝试出队列,就会阻塞等待,等待到队列不为空为止。
- 如果队列已满,尝试入队列,也会阻塞等待,等待到队列不满为止。
在写多线程代码的时候,多个线程之间进行数据交互,可以使用阻塞队列简化代码编写。
💥Java标准库提供的阻塞队列的使用
1️⃣由于BlockingQueue是一个接口,没法直接实现实例,我们可以通过它的实现类来创建对象
//BlockingDeque两种实现方式 //1.基于数组实现阻塞队列 BlockingQueue<String> queue = new ArrayBlockingQueue<>(100);//capacity括号中的100表示的是容量。 //2、基于链表实现阻塞队列 BlockingQueue<String> queue = new LinkedBlockingDeque<>();2️⃣阻塞对列的两个核心方法:
- put:入队列
- take:出队列
由于这两个方法都带有阻塞的效果,上面说到队列空的情况下出队列,会导致阻塞;队列满的情况入队列,会导致阻塞。所以在调用这个两个方法的时候我们需要声明异常或者处理异常。
import java.util.concurrent.BlockingQueue;
import java.util.concurrent.LinkedBlockingDeque;
public class ThreadDemo19 {
public static void main(String[] args) throws InterruptedException {
BlockingQueue<String> queue = new LinkedBlockingDeque<>();
//1.put入队列
queue.put("hello1");
queue.put("hello2");
queue.put("hello3");
queue.put("hello4");
queue.put("hello5");
//2.take出队列
String result = null;
result = queue.take();
System.out.println(result);
result = queue.take();
System.out.println(result);
result = queue.take();
System.out.println(result);
result = queue.take();
System.out.println(result);
result = queue.take();
System.out.println(result);
result = queue.take();
System.out.println(result);
}
}
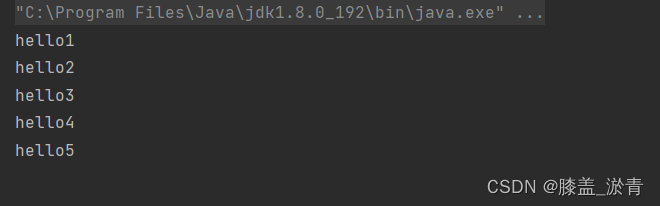
上述代码入队了5次,出队了6次,将队列中所有结果都输出了之后,队列为空,在想要出队列,这个时候就会阻塞等待。
1.2、生产者消费者模型
📕概念:
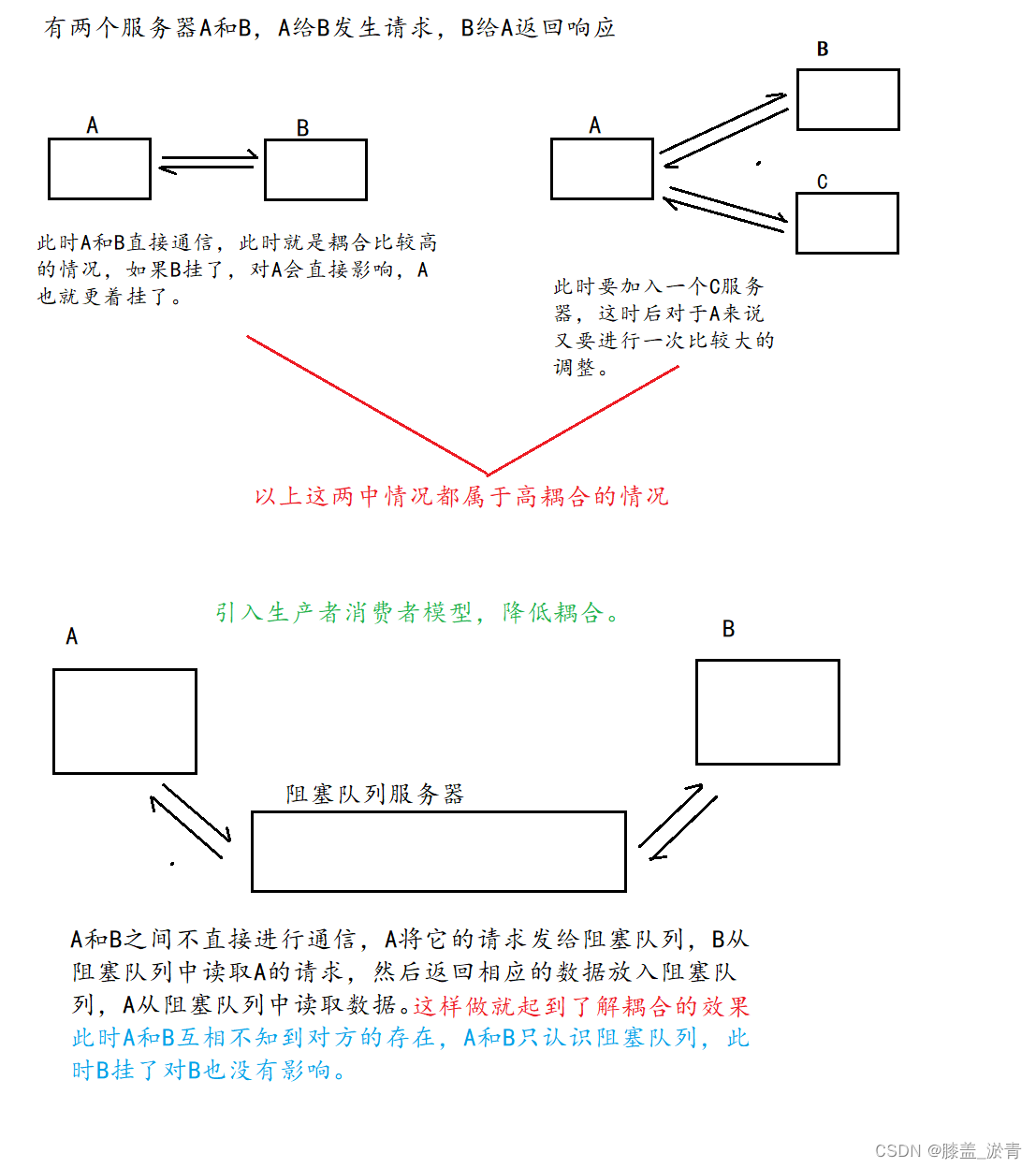
- 生产者消费者模式就是通过一个容器来解决生产者和消费者的强耦合问题。
- 生产者和消费者彼此之间不直接通讯,而通过阻塞队列来进行通信,所以生产者生产完数据之后不用等代消费者处理,直接放入阻塞队列,消费之不找生产者要数据,而是直接从阻塞队列中取。
📗上面的描述中出现了耦合这个概念,我们这里来了解一下耦合和内聚的概念(我们写代码的时候追求的就是高内聚低耦合)
- 耦合:有高耦合和低耦合,举个例子,计算两个数的和与积,如果计算乘积的方法调用了计算和的代码,那么这两个方法(模块)之间的耦合性就比较高,也就是高耦合。如果让两个方法尽可能独立的完成特定的功能。那么他们之间的耦合性就低,也就是低耦合。
- 内聚:有高内聚和低内聚。一个模块的各个元素之间的联系的紧密程度,各个元素(语句)之间的联系程度越高,则内聚性越高,即高内聚。
📙 生产这消费者模型的作用
1️⃣阻塞队列能使生产者和消费者之间解耦合
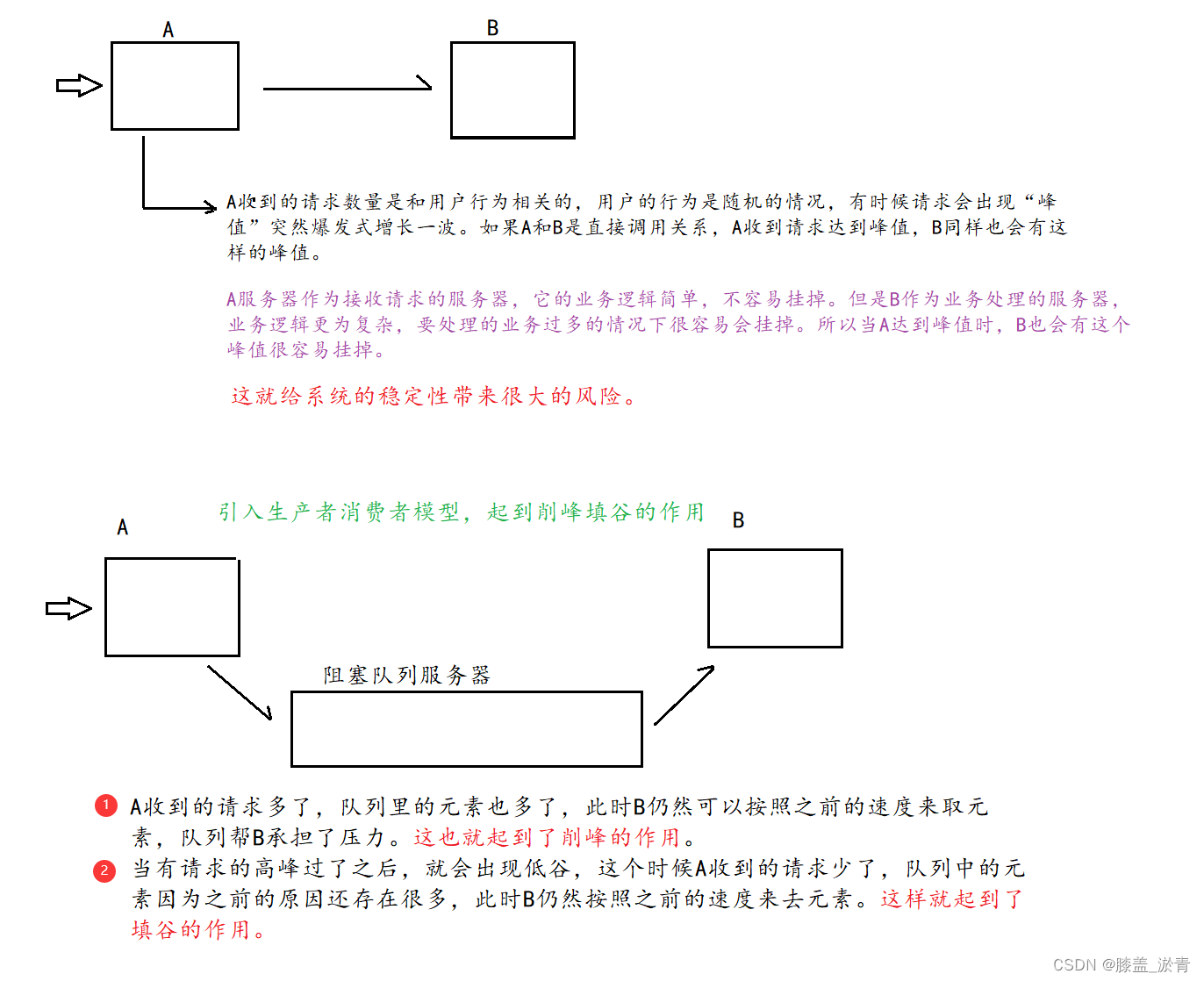
2️⃣阻塞队列起到一个缓冲区的作用,平衡了生产者和消费者的处理能力(削峰填谷)
📘基于阻塞队列,写一个生产者消费者模型的代码。
下面代码,让生产者每隔1s生产一个元素。让消费者则直接消费,不受限制
import java.util.concurrent.BlockingQueue;
import java.util.concurrent.LinkedBlockingQueue;
public class ThreadDemo20 {
public static void main(String[] args) {
//阻塞队列
BlockingQueue<Integer> blockingQueue = new LinkedBlockingQueue<>();
//消费者
Thread t1 = new Thread(()->{
while(true){
try {
int value = blockingQueue.take();//从队列中取元素
System.out.println("消费元素: "+value);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
});
t1.start();
//生产者
Thread t2 = new Thread(()->{
int value = 0;
while(true){
try {
System.out.println("产生元素: "+value);
blockingQueue.put(value);
value++;
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
});
t2.start();
}
}

1.3、阻塞队列的模拟实现
实现阻塞队列分为三步。
- 首先实现一个普通队列
- 加上线程安全
- 加上阻塞功能
我们在设计阻塞队列的时候,内部用一个数组实现存放数据,设置两个指针,一个(head)用来指向数组的开头,一个(tail)指向要插入数据的位置,但是数组容量也有大小,如果tail指向数组的最后一个元素,但是还有数据存入数组,这个时候该怎样做呢?我们可以将队列设置成为循环队列。
这样两个线程一个放入数据,一个读取数据,所以我们需要设置两个方法put(入队列)和take(出队列)。一个线程调用put方法,一个线程调用take方法,这样这个数组的空间就实现了循环。
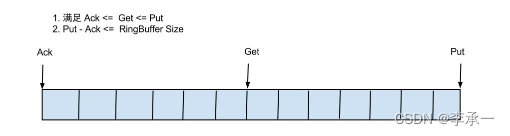
❓❓❓我们将数据放入数组中,如何判断这个数组为空或者这个数组已满?因为循环队列满的时候head和tail两个指针指向同一个位置。队列为空的时候指针head和tail也指向同一个位置。
- 第一种方法:牺牲一个空间,如上图,当rear走到7下标位置,判断rear的下一个位置是否为front,若是,则判断队列已满,若不是队列没满。
- 第二种方法:在实现循环对列的时候,定义一个size,用来记录数组中元素的个数,想要判断循环对列是否已满,可以直接输出size的值,进行判断。这种方法不浪费空间。
由于第二种方法更加简单,可读性更高所以我们在这里使用第二种方法实现循环队列。
1️⃣先来看一个不太成熟的代码,存在潜在问题的代码。主要来了解一下入队列(put)和出队列(take)两个方法。
//基于数组来实现队列
class MyBlockingQueue{
private int[] items = new int[1000];
//约定队列的有效元素[head,tail)前闭后开
//这里添加上volatile,防止这三个变量在读操作的时候,出现线程安全问题
volatile private int head = 0;
volatile private int tail = 0;
volatile private int size = 0;
//入队列
//给入队列方法加锁,这个方法内部不是原子的,存在读操作,写操作,在多线程情况下保证原子性
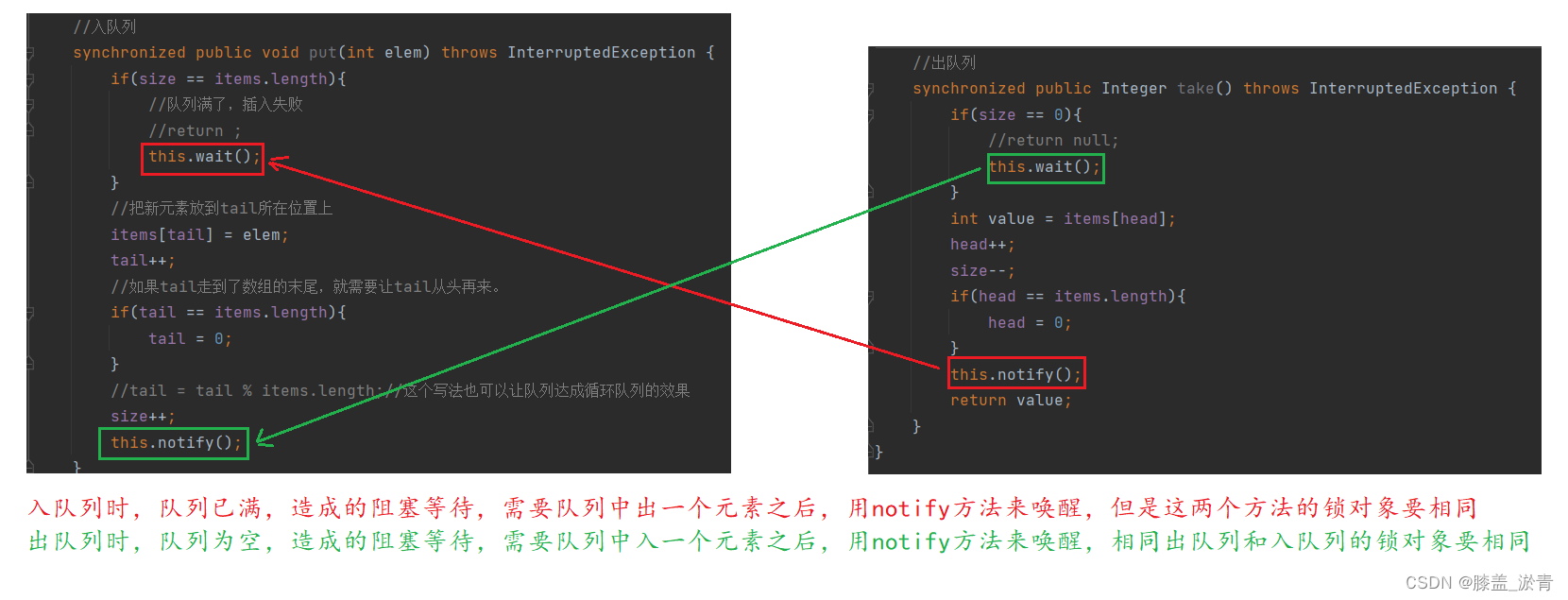
synchronized public void put(int elem) throws InterruptedException {
if(size == items.length){
//队列满了,插入失败
this.wait();//队列满阻塞等待,需要出队列的方法中的notify方法来唤醒。
}
//把新元素放到tail所在位置上
items[tail] = elem;
tail++;
//如果tail走到了数组的末尾,就需要让tail从头再来。
if(tail == items.length){
tail = 0;//当tail将数组走完,则回到数组的0下标位置
}
//tail = tail % items.length;//这个写法也可以让队列达成循环队列的效果
size++;
this.notify();//用来唤醒出队列时,队列为空引起的阻塞等待
}
//出队列
//这里添加锁的目的和入队列方法添加锁的目的一样。这里的锁对象就是主方法中的myBlockingQueue对象
synchronized public Integer take() throws InterruptedException {
if(size == 0){
this.wait();//出队列的时候,如果队列为空,就需要入队列中的notify方法来唤醒。
}
int value = items[head];
head++;
size--;
if(head == items.length){
head = 0;//head表示出队列,先进先出,当head将数组遍历完,则回到0下标位置,形成循环。
}
this.notify();//用来唤醒入队列时,队列已满引起的阻塞等待。
return value;
}
}
public class ThreadDemo21 {
public static void main(String[] args) {
MyBlockingQueue myBlockingQueue = new MyBlockingQueue();
}
}
✨ 上面为什么说这个代码是不太成熟,存在潜在问题的代码。主要原因还是在于wait方法。
❗❗Java官方并不太建议这么使用wait,wait是可能被其他方法给中断的比如(interrupt方法),此时就造成了wait等待的时机还没到,就被提前唤醒了,因此代码就可能不符合预期了。
if(size == 0){ this.wait(); }像上述的操作在上面的代码中没有出错,并不代表在其他复杂的代码中不会出错。很有可能在别的代码里暗中使用了interrupt,就会把wait给提前唤醒了,明明条件还没有满足(队列还为空),但是将wait唤醒之后代码就继续向下走了,但是队列中没有数据,这个时候得到的数据就会是一个非法的数据。
❗❗❗更稳妥的做法就是,在wait唤醒之后,在判定一次条件。也就是wait之前,发现条件不满足,开始wait,等到wait被唤醒了之后,在确认一下条件是不是满足,如果不满足,还可以继续wait.
所以我们更为稳妥的做法就是将条件if改为while。
while(size == 0){ this.wait(); }
2️⃣最后我们来看一下正确的阻塞队列的实现,并且和它的使用。
//基于数组来实现队列
class MyBlockingQueue{
private int[] items = new int[1000];
//约定队列的有效元素[head,tail)前闭后开
volatile private int head = 0;
volatile private int tail = 0;
volatile private int size = 0;
//入队列
synchronized public void put(int elem) throws InterruptedException {
while(size == items.length){
//队列满了,插入失败
//return ;
this.wait();
}
//把新元素放到tail所在位置上
items[tail] = elem;
tail++;
//如果tail走到了数组的末尾,就需要让tail从头再来。
if(tail == items.length){
tail = 0;
}
//tail = tail % items.length;//这个写法也可以让队列达成循环队列的效果
size++;
this.notify();
}
//出队列
synchronized public Integer take() throws InterruptedException {
while(size == 0){
//return null;
this.wait();
}
int value = items[head];
head++;
size--;
if(head == items.length){
head = 0;
}
this.notify();
return value;
}
}
public class ThreadDemo21 {
public static void main(String[] args) {
MyBlockingQueue myBlockingQueue = new MyBlockingQueue();
//消费者
Thread t1 = new Thread(()->{
while(true){
try {
int value = myBlockingQueue.take();
System.out.println("消费者:"+value);
Thread.sleep(1000);//可以让消费者等1s
} catch (InterruptedException e) {
e.printStackTrace();
}
}
});
t1.start();
//生产者
Thread t2 = new Thread(()->{
int value = 0;
while(true){
try {
System.out.println("生产者:"+value);
myBlockingQueue.put(value);
value++;
//Thread.sleep(1000);//也可以让生产者等1s
} catch (InterruptedException e) {
e.printStackTrace();
}
}
});
t2.start();
}
}

2、定时器
定时器是软件开发中的一个重要组件,类似于一个闹钟。达到一个 设定的时间之后,就执行某个指定好的代码。在开发过程中,经常需要一些定时或者周期性的操作。而在Java中则使用Timer对象完成定时任务功能。
2.1、使用标准库中的定时器
- 标准库中提供了一个Timer类,Timer类的核心方法为schedule.
- schedule包含两个参数。第一个参数指定即将要执行的任务代码,第二个参数指定多长时间之后执行(单位为ms)
public class ThreadDemo22 {
public static void main(String[] args) {
Timer timer = new Timer();
//schedule的两个参数,TimerTask表示将要执行的任务是什么,2000:表示过多长时间执行
timer.schedule(new TimerTask() {//没调用一次schedule表示安排一个任务。
@Override
public void run() {
System.out.println("hello2");
}
},2000);
System.out.println("hello1");
}
} 
1️⃣其中schedule方法的第一个参数是一个抽象类TimerTask实例的对象,继承了Runnable接口,所以我们需要将Runnable接口当中的run方法重写,在TimerTask类当中实现,这个run方法中是这个任务具体要完成的工作是什么
2️⃣ 观察代码的执行结果发现,两次打印执行完成之后,很显然代码并没有执行结束,为什么会这样?
Timer里面内置了线程(是前台线程)会阻止进程结束,Timer是基于多线程来实现的,所以run方法内部要被执行的代码是靠Timer内部的线程在时间到了之后执行的。

❗❗在使用Timer类的时候,没调用一次schedule表示安排一个任务。虽然任务可能有很多,由于他们的触发时间不同,所以只需要一个工作线程,每次都找到这些任务中,最先到达执行时间的任务。(多个任务可以在一个线程中执行)
import java.util.Timer;
import java.util.TimerTask;
public class ThreadDemo22 {
public static void main(String[] args) {
Timer timer = new Timer();
//schedule的两个参数,TimerTask表示将要执行的任务是什么,2000:表示过多长时间执行
timer.schedule(new TimerTask() {
@Override
public void run() {
System.out.println("hello4");
}
},4000);
timer.schedule(new TimerTask() {
@Override
public void run() {
System.out.println("hello3");
}
},3000);
timer.schedule(new TimerTask() {
@Override
public void run() {
System.out.println("hello2");
}
},2000);
timer.schedule(new TimerTask() {
@Override
public void run() {
System.out.println("hello1");
}
},1000);
System.out.println("hello0");
}
}
2.2、模拟实现定时器
根据上面的描述,一个线程可以执行多个任务,最先执行的任务一定是delay最小的,想要找到delay最小的任务,那么使用小根堆就可以实现,在Java库中PriorityQueue(优先级队列)就是堆,但是定时器可能有多个线程在执行schedule方法,为了确保多线程的安全,Java标准库中提供了一个带优先级的阻塞队列PriorityBlockingQueue.
1️⃣创建一个类(MyTask)用来描述一个要执行的任务,包含Runnable表示要做什么,time表示啥时候执行。由于任务这个对象要存放在带有优先级的阻塞队列当中,所以要继承Comparable接口,重写compareTo方法,用来这些任务对象在带有优先级的阻塞队列当中进行比较建堆。
class MyTask implements Comparable<MyTask>{
public Runnable runnable;
//为了方便后续的判定,使用绝对的时间戳
public long time;
public MyTask(Runnable runnable,long delay){
this.runnable = runnable;
//取当前时刻的时间戳+delay,作为该任务实际执行的时间戳
this.time = System.currentTimeMillis() + delay;
}
//使用compareTo 方法 对 优先级队列当中的元素(任务)按照执行时间的大小进行建堆(小根堆)
@Override
public int compareTo(MyTask o) {
//这样写意味着每次取出的是时间最小的元素。
return (int)(this.time - o.time);
}
}上面说到的绝对时间戳表示的是形如这样的(1684483844859)数字,他是毫秒级别的时间戳,也就当前时刻和基准时刻的ms数之差,(基准时刻:1970年01月01日 00:00:00.000)
2️⃣ MyTimer类中,构建带有优先级的阻塞队列,通过PriorityBlockingQueue来组织若干个MyTask对象,通过schedule来往队列中一个一个插入MyTask对象。
class MyTimer{
//这个结构,带有优先级的阻塞队列,核心数据结构
private PriorityBlockingQueue<MyTask> queue = new PriorityBlockingQueue<>();
//此处的delay是一个形如3000这样的数字(多长时间之后,执行该任务)
public void schedule(Runnable runnable,long delay){
//根据参数,构造MyTask,插入队列即可。
MyTask myTask = new MyTask(runnable,delay);
//向队列中插入任务
queue.put(myTask);
}
}3️⃣在MyTimer类中的构造方法中设置一个t线程,一直不停的扫描队首元素,看看是否能执行这个任务。
class MyTimer{
//这个结构,带有优先级的阻塞队列,核心数据结构
private PriorityBlockingQueue<MyTask> queue = new PriorityBlockingQueue<>();
//此处的delay是一个形如3000这样的数字(多长时间之后,执行该任务)
public void schedule(Runnable runnable,long delay){
//根据参数,构造MyTask,插入队列即可。
MyTask myTask = new MyTask(runnable,delay);
//向队列中插入任务
queue.put(myTask);
}
//在这里构造线程,负责执行具体任务了
public MyTimer(){
Thread t = new Thread(()->{
while(true){
try {
MyTask myTask = queue.take();
//获取当前系统时间
long curTime = System.currentTimeMillis();
if(myTask.time <= curTime){
//时间到了,可以执行任务了
myTask.runnable.run();
}else{
//时间还没到
//把刚才取出的任务,重新塞回队列中
queue.put(myTask);
}
} catch (InterruptedException e) {
e.printStackTrace();
}
}
});
}
}✨ 问题一:忙等
❓❓❓这个代码中在执行任务的时候出现了一个问题,就是在任务的执行时间还没有到时,线程处于等待的状态,但是上述代码中效果并不是这样。先将队首元素取出来,然后得到当前系统时间与任务执行的时间对比,在当前时间小于任务执行时间时,又将取出的元素放入队列中,由于while循环,上述的操作一直被执行,直到当前系统时间等于任务执行时间。这样就导致线程并没有真正的停下来,等待的过程中一直占用着CPU资源。这就形成了忙等的问题。
❗❗❗ 所以在使用的过程中我们需要释放CPU资源。要解决忙等这个问题,我们可以使用wait()方法,但是也有老铁想到了使用sleep()方法了吧!!! 但是很遗憾sleep方法并不行。
- sleep它的时间是固定的,不能随时唤醒,就比如我们2:30上课,现在2:00,队列当中的上课这个任务时间还没有到,线程可以先等待30分钟,但是在休息的时候,我们想着时间还早,有创建了一个任务,去打水。这个时候使用sleep,线程可能无法即使唤醒。
- 但是使用wait方法,在创建了一个新的任务之后,加入队列当中,之后使用notify方法就可以将线程唤醒。执行打水这个任务。
使用wait和notify对代码进行修改
class MyTimer{
//这个结构,带有优先级的阻塞队列,核心数据结构
private PriorityBlockingQueue<MyTask> queue = new PriorityBlockingQueue<>();
//创建一个锁对象
private Object locker = new Object();
//此处的delay是一个形如3000这样的数字(多长时间之后,执行该任务)
public void schedule(Runnable runnable,long delay){
//根据参数,构造MyTask,插入队列即可。
MyTask myTask = new MyTask(runnable,delay);
//向队列中插入任务
queue.put(myTask);
synchronized (locker){
locker.notify();
}
}
//在这里构造线程,负责执行具体任务了
public MyTimer(){
Thread t = new Thread(()->{
while(true){
try {
synchronized(locker){
MyTask myTask = queue.take();
//获取当前系统时间
long curTime = System.currentTimeMillis();
if(myTask.time <= curTime){
//时间到了,可以执行任务了
myTask.runnable.run();
}else{
//时间还没到
//把刚才取出的任务,重新塞回队列中
queue.put(myTask);
//等待的时长为任务执行时间-当前系统时间
locker.wait(myTask.time - curTime);
}
}
} catch (InterruptedException e) {
e.printStackTrace();
}
}
});
}
}✨问题二:
在上面的修改中,由于wait和notify方法要搭配synochronized进行使用,所以直接使用synochronized代码块将try中的代码全部包了起来。但是如果使用synochronized只对wait方法进行包裹,两种写法产生的结果有什么不同?或者是第二种写法可行吗?
synochronized(locker){ locker.wait(myTask.time - curTime); }
而如果对try中的程序全部加锁,就不会产生上面的空打一炮的问题,由于原子性,所以t1线程将锁释放之后,系统才会调度产生锁竞争的其他线程。这样就保证了t1线程已经产生阻塞等待。这个时候t2线程创建了新的任务,即使执行时间在t1线程之前,也不会让t2线程的任务不能及时执行,因为在添加新的任务到队列当中之后,对t1线程的等待进行了唤醒,t1线程就会将锁中代码执行完成,也就释放了锁,这个时候t2线程就可以获取锁,执行t2线程的任务。

4️⃣完整代码:模拟实现+使用
import java.util.concurrent.PriorityBlockingQueue;
class MyTask implements Comparable<MyTask>{
public Runnable runnable;
//为了方便后续的判定,使用绝对的时间戳
public long time;
public MyTask(Runnable runnable,long delay){
this.runnable = runnable;
//取当前时刻的时间戳+delay,作为该任务实际执行的时间戳
this.time = System.currentTimeMillis() + delay;
}
@Override
public int compareTo(MyTask o) {
//这样写意味着每次取出的是时间最小的元素。
return (int)(this.time - o.time);
}
}
class MyTimer{
//这个结构,带有优先级的阻塞队列,核心数据结构
private PriorityBlockingQueue<MyTask> queue = new PriorityBlockingQueue<>();
//创建一个锁对象
private Object locker = new Object();
//此处的delay是一个形如3000这样的数字(多长时间之后,执行该任务)
public void schedule(Runnable runnable,long delay){
//根据参数,构造MyTask,插入队列即可。
MyTask myTask = new MyTask(runnable,delay);
//向队列中插入任务
queue.put(myTask);
synchronized (locker){
locker.notify();
}
}
//在这里构造线程,负责执行具体任务了
public MyTimer(){
Thread t = new Thread(()->{
while(true){
try {
synchronized(locker){
MyTask myTask = queue.take();
//获取当前系统时间
long curTime = System.currentTimeMillis();
if(myTask.time <= curTime){
//时间到了,可以执行任务了
myTask.runnable.run();
}else{
//时间还没到
//把刚才取出的任务,重新塞回队列中
queue.put(myTask);
//等待的时长为任务执行时间-当前系统时间
locker.wait(myTask.time - curTime);
}
}
} catch (InterruptedException e) {
e.printStackTrace();
}
}
});
t.start();
}
}
public class ThreadDemo23 {
public static void main(String[] args) {
MyTimer myTimer = new MyTimer();
myTimer.schedule(new Runnable(){
@Override
public void run() {
System.out.println("hello3");
}
},3000);
myTimer.schedule(new Runnable(){
@Override
public void run() {
System.out.println("hello2");
}
},2000);
myTimer.schedule(new Runnable(){
@Override
public void run() {
System.out.println("hello1");
}
},1000);
System.out.println("hello0");
}
}
3、线程池
线程池:提前把线程准备好,创建线程不是直接从系统申请,而是从池子里获取,线程不适用之后,还给线程池(池的目的是为了提高效率)
线程的创建相比于进程虽然更加的轻量,但是频繁的创建的情况下,开销也是不可忽略的。希望还能进一步的提高效率,存在两种方式
- 协程(轻量级线程)Java标准库还不支持
- 线程池
从线程池中拿线程,是纯粹的用户态操作
从系统创建线程,涉及到用户态和内核态之间的切换,真正的创建是要在内核态完成的
✨了解用户态和内核态。
❗❗❗结论:纯用户态操作,时间是可控的,涉及到内核态操作,时间就是不太可控的了。

3.1、标准库中的线程池
我们通过这个代码向下了解
public class ThreadDemo24 {
public static void main(String[] args) {
//创建出固定包含10个线程的线程池
ExecutorService pool = Executors.newFixedThreadPool(10);
//添加任务到线程中
pool.submit(new Runnable(){
@Override
public void run() {
System.out.println("hello");
}
});
}
}
- 使用Executors.newFixedThreadPool(10)能够创建出固定10个线程的线程池。
- 返回值类型为ExecutorService(翻译:执行服务)
- 通过ExecutorService.submit可以注册一个任务到线程池中。
我们看到这里创建线程池对象的时候我们并没有直接new一个ExecutorService接口的实现类,而是通过Executors类内部的静态方法完成了对象的构造。这就是我们说的设计模式中的工厂模式。
Executors类调用方法创建线程池的几种方式:
- newFixedThreadPool:创建固定线程数的线程池
- newCachedThreadPool:创建线程数目动态增长的线程池
- newSingleThreadExecutor:创建只包含单个线程的线程池
- newScheduledThreadPool:设定延迟时间后执行命令,或者定期执行命令,是进阶版的Timer
Executor本质上是ThreadPoolExecutor类的封装,ThreadPoolExecutor提供了更多的可选参数,可以进一步细化线程池行为的设定。
3.1.1、ThreadPoolExecutor类的构造方法
我们可以通过Java的官方文档来了解Java标准库当中的一些类和方法,就如ThreadPoolExecutor类,他是存在于java.util.concurrent包当中的。
它的构造方法有4个,我们只了解最后一个,因为它的参数是最全的。
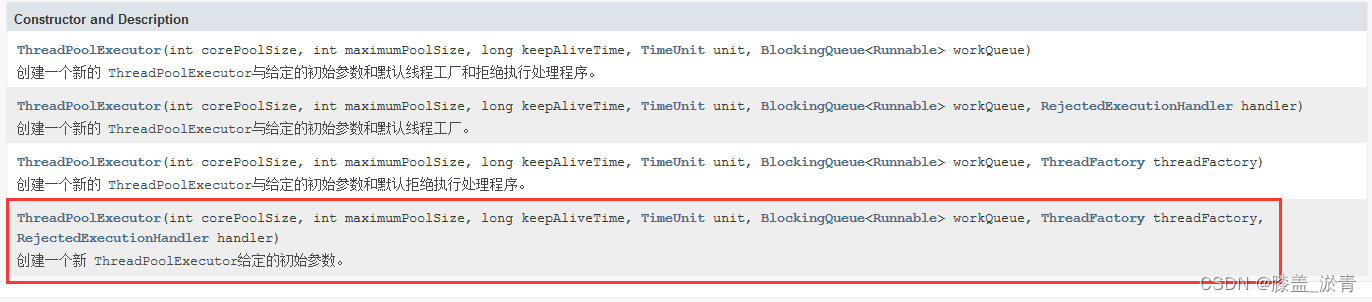
- corePoolSize:核心线程数(即使空闲时人保留在池中的线程数,除非设置allowCoreThreadTimeOut).
- maximumPoolSize:最大线程数
(举例理解corePoolSize和maximumPoolSize这两个参数,我们将线程池比作公司,公司中存在两类员工,一类时正式员工,一类时实习生,corePoolSize[核心线程数]:就是正式员工,maximumPoolSize[最大线程数]:就是正式员工+实习生。正式员工签了劳动合同,不能随便辞退,而实习生只是实习合同,随时可以辞退,一个公司,可能有的时候比较忙,有的时候比较空闲,比较忙的时候,就可以多招聘一些实习生来增加生产力,不忙的时候,大家都比较空闲,就可以把实习生给裁掉。这样就保证忙的时候,生产力时充裕的,闲的时候,也不会浪费资源。线程池就和这个同理,当前任务比较多,线程池就会多创建一些"临时线程",但是不会超过最大线程数;如果当前任务少,比较空闲了,线程池就会把多出来的临时线程销毁掉(核心线程还是会保留的))。
- Long keepAliveTime:当线程数大于CPU核心数(逻辑核心)时,这时临时的线程在终止前等待任务的最大时间。描述了临时线程允许的最大摸鱼时间
- TimeUnit unit:keepAliveTime是一个表示时间的数值,unit表示的时这个时间的单位(ms,s...).
(举例理解keepAliveTime和unit这两个参数。当任务比较少,大家都比较空闲的时候,实习生不是立即被辞退的,可能在今天没有很多任务,实习生可以摸一下鱼,但是保不齐明天可能会有很多活,所以实习生先不辞退,等到连着好几天都没有太多的任务,然后把实习生辞退了,keepAliveTime描述了临时线程允许的最大摸鱼时间)
- BlockingQueue<Runnable> workQueue:用于执行任务之前使用的队列。这个队列将仅保存execute方法提交的Runnable任务。(线程池需要管理很多的任务,这些任务也是通过阻塞队列来组织的,程序员可以手动给线程池指定一个队列,此时程序员就很方便的获取队列中的信息)
- ThreadFactory threadFactory:执行程序创建新线程时使用的工厂。
- RejectedExecutionHandler handler: 线程池的拒绝策略(如果线程池满了,继续往里面添加任务,如何进行拒绝)
3.1.2、Java标准库的4种拒绝策略【经典面试题】【重点】
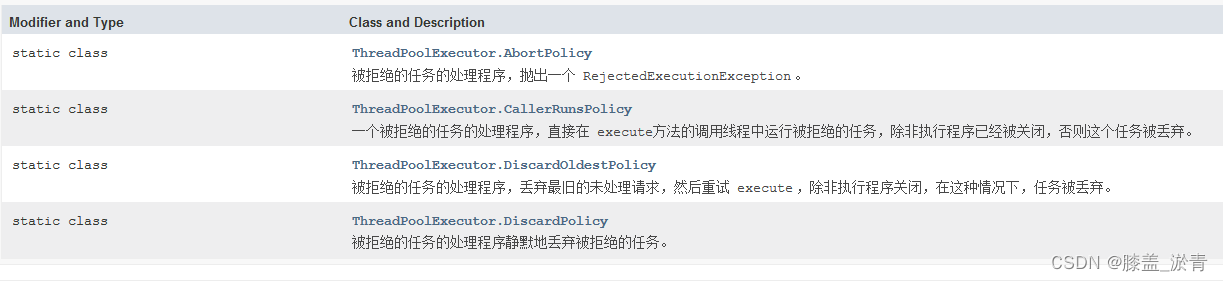
- ThreadPoolExecutor.AbortPolicy:终止策略,(这时ThreadPoolExecutor线程池默认的拒绝策略)如果队列满了,继续添加任务,添加操作直接抛出异常。队列当中的原本任务和这个要添加的任务都不处理了。
- ThreadPoolExecutor.CallerRunsPolicy:提交任务的线程自己负责执行这个任务(调用者运行策略)。再通俗一点理解就是我们给自己规定时间做卷子,这个时候你的同学叫你去玩,这个时候你说"我不去,你自己去吧",我们还时按照计划做自己的事情。这里的你就是一个线程,而写卷子和出去玩是两个任务。谁添加的出去玩这个任务,谁去执行。我这个线程不执行出去玩这个任务。,线程池中没办法运行,那么就由提交任务的这个线程运行
- ThreadPoolExcutor.DiscardOldestPolicy:丢弃最早未处理请求策略,丢弃最先进入阻塞队列的任务以腾出空间让新的任务入队列。
- ThreadPoolExcutor.DiscardPolicy:丢弃最新的任务(丢弃策略),什么都不做,即丢弃新提交的任务。
❓❓❓说到这里很多老铁就会说,阻塞队列不是满了之后添加元素不是会产生阻塞吗?还需要这些拒绝策略干啥?
❗❗❗这里有两个原因,一种是阻塞不是用在什么地方都好,产生了阻塞就会拖慢程序的运行速度。另外一种原因,我们举例来说明,就比如老师叫我们干个什么事情,这个时候我们的任务安排满了没有时间,我们不可能再这个任务来了之后阻塞等待吧,这件事能不能干,老师需要你一个回复,老师不可能傻都不干等你,这个不科学的,所以我们使用拒绝策略,立即给老师一个回复,老师知道你干不了,就会去找其他人。
线程池中,不依赖满了就阻塞这个特性,其实主要利用,队列空了就阻塞这个特性。如果队列满了还是使用拒绝策略是比较合适的。
3.1.3、工厂模式
在创建对象的时候,不在使用new,而是使用一些其他的方法(通常是静态方法)协助我们把对象创建出来
🎉 工厂模式的使用场景:
工厂模式是用来填构造方法的坑的。(如果想要提供多种不同的构造对象的方式,就得基于重载。)
举例:我们创建一个点(point)类,就是数学中,平面上的点。那么就有两种方式
一种是使用平面直接坐标确定一个点,一种是极坐标的方式确定一个点。
class Point{ //在平面直角坐标系中 可以使用x和y确定一个点 public Point(double x,double y){}; //使用极坐标的方式用一个半径r和角度a确定一个点 public Point(double r,double a){}; }可以看到这两个构造方法的参数是相同的,不能构成重载。
这就是构造方法的局限性。
3.2、模拟实现线程池
- 使用BlockingQueue组织任务
- 使用Runnable描述一个任务
- 创建构造方法,含有工作线程
class MyThreadPool{
//阻塞队列用来存放任务,BlockingQueue中指定的元素类型Runnable,也就是任务类型
private BlockingQueue<Runnable> queue = new LinkedBlockingQueue<>();
//给队列当中添加任务
public void submit(Runnable runnable) throws InterruptedException {
queue.put(runnable);
}
//此处实现一个固定的线程数的线程池
public MyThreadPool(int n){
//通过这个for循环创建出n个线程
for (int i = 0; i < n; i++) {
Thread t = new Thread(()->{
try {
//此处需要让每个线程内部有个while循环,不停的取任务。
while(true){
Runnable runnable = queue.take();
//执行任务
runnable.run();
}
} catch (InterruptedException e) {
e.printStackTrace();
}
});
t.start();
}
}
}
public class ThreadDemo25 {
public static void main(String[] args) throws InterruptedException {
//创建有10个线程的线程池。
MyThreadPool pool = new MyThreadPool(10);
//通过循环给阻塞队列当中添加1000个任务
for (int i = 0; i < 1000; i++) {
//这里给申请变量记录i,是因为匿名内部类要捕获外部的变量,变量捕获要求这个变量是final的,但是i已经再修改了(i++),所以我们要使用一个变量表示实时的final
int number = i;
pool.submit(new Runnable(){
//run表示执行任务(添加任务)
@Override
public void run() {
System.out.println("hello "+number);
}
});
}
}
}
上述代码中main方法中线程池对象调用的submit方法相当于是生产者,而MyThreadPool类的构造方法内部的每个线程相当于消费者。每个线程在被系统调用的时候,就会通过循环不停的读取任务,并执行。
❓❓❓上述代码中,创建的线程池中创建出了10个线程,那么在实际开发中,一个线程池的线程数量,该怎样设计,设置成几个比较合适?
❗❗❗因为线程是在CPU上调度的,所以线程池中的线程并不是越多越好,而是根据你的CPU逻辑核心数来确定的。CPU调度也是有成本的,如果线程数太多,也会消耗很大的资源。
✨正确的做法:要通过性能测试的方式,找到合适的值。
比如构造一个请求,发送给服务器,要测试性能,这里的请求就需要构造很多。比如每秒发送500/1000个请求这样的场景,需要构造一个合适的值。
根据不同线程池不同的线程数量,来观察,程序处理任务的速度,程序持有的CPU占有率。
当线程数多了,整体的速度快了,但是CPU占有率也变高了。
线程少了,整体的速度变慢了,但是CPU占有率也就下降了。因此我们就需要找到一个程序速度能够接收,并且CPU占有率合理这样的平衡点。
不同类型的程序,因为单个任务里面CPU上计算的时间和阻塞的时间是分布不相同的,因此我们编一个数字是不靠谱的。