- 订阅:新手可以订阅我的其他专栏。免费阶段订阅量1000+
python项目实战
Python编程基础教程系列(零基础小白搬砖逆袭)
- 说明:本专栏持续更新中,目前专栏免费订阅,在转为付费专栏前订阅本专栏的,可以免费订阅付费专栏,可报销(名额有限,先到先得)。
即将转为付费专栏,更多详细请看,五一或有优惠活动哦。
关于专栏〖Python网络爬虫实战〗转为付费专栏的订阅说明
- 作者:爱吃饼干的小白鼠。Python领域优质创作者,2022年度博客新星top100入围,荣获多家平台专家称号。
最近更新
〖Python网络爬虫实战㉖〗- Selenium库和ChromeDriver驱动的安装
🌟上节回顾
我们在前面讲解了正确安装好Chrome 浏览器并配置好ChromeDriver。另外,还教大家如何正确安装好 Python 的 Selenium 库。
⭐️Selenium案例实战(一)
今天,我们就用python爬取商品信息,我们这里使用selenium去模拟获取我们的数据。
🌟环境使用
- python 3.9
- pycharm
🌟模块使用
- requests
- selenium
- time
- 谷歌驱动
🌟说明
✨一、谷歌驱动安装
1.下载网址
CNPM Binaries Mirror
2.文件安装(放置)位置
可以把这个文件理解成一个脚本入口。说它是安装,其实就是把下载的
chromedriver.exe文件复制到相应的位置。将文件复制到两个位置:1.
..\python\Scripts复制一份到安装Python的文件夹中的Scripts文件夹中;2.如果用的是Pycharm,再复制一份到..\python\site-packages\selenium\webdriver\chrome文件中。这个地址可以将鼠标放在Pycharm里面安装库的地方的相应库上就能看到。
✨二、selenium模块
之前,我们爬虫是模拟浏览器,但始终不是用的浏览器,但今天我们要说的是另一种爬虫方式,这次不是模拟浏览器,而是用程序去控制浏览器进行一些列操作,也就是selenium。selenium是python的一个第三方库,对外提供的接口可以操控浏览器,比如说输入、点击,跳转,下拉等动作。
在使用selenium模块之前要做两件事,一是安装selenium模块,可以用终端用pip,也可以在pycharm里的setting安装;二是我们需要下载一款浏览器驱动程序,下载的驱动程序要和浏览器的版本一致。
🌟代码实现
首先,我们模拟打开我们想要的网址,这里是某东的首页。
driver = webdriver.Chrome()
driver.get('https://www.jd.com/')有的大家运行会闪退,大家在调试模式下运行,就把不会闪退,或者加一句input()。接下来,我们模拟键盘输入笔记本。我们看看代码怎么运行。
# 定位搜索框
# input_tag = driver.find_element(By.ID,value="key")
input_tag = driver.find_element(By.ID, "key")
input_tag.send_keys('笔记本') # 模拟键盘输入
driver.implicitly_wait(5) # 隐式等待接下来,就是模拟键盘的回车按键,我们看看selenium是怎么实现的。
input_tag.send_keys(Keys.ENTER) # 模拟回车接下来,就是获取我们商品页的商品信息。
goods = driver.find_elements(By.CLASS_NAME, "gl-item")这个代码片段将会返回网页中所有 "gl-item" 类名的 HTML 元素。后面的就不一样解释了。
for good in goods:
# 名字
name = good.find_element(By.CSS_SELECTOR, ".p-name").text.replace('\n', '')
print(name)
# 价格
price = good.find_element(By.CSS_SELECTOR, ".p-price").text
link = good.find_element(By.TAG_NAME, "a").get_attribute('href')
msg = '''
商品:%s
价格:%s
链接:%s
''' % (name, price, link)
print(msg)
这个代码片段将会打印出商品的名称、价格和链接。您可以根据需要修改代码以满足您的具体需求。
首先,它会找到商品的 HTML 元素,然后使用 find_element 方法找到 ".p-name" 和 ".p-price" 类名的元素,并提取它们的文本。接下来,它会找到所有 "a" 标签,并从它们的 href 属性中提取链接。最后,它会将商品名称、价格和链接格式化为一个字符串,并打印出来。
全部代码如下:
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
import time
driver = webdriver.Chrome()
# r'C:\Users\YY\AppData\Local\Programs\Python\Python39\chromedriver.exe'
driver.get('https://www.jd.com/')
def GetInfo():
input_tag = driver.find_element(By.ID, "key")
input_tag.send_keys('笔记本')
time.sleep(5)
input_tag.send_keys(Keys.ENTER)
spider_jd()
def spider_jd():
goods = driver.find_elements(By.CLASS_NAME,"gl-item")
for good in goods:
name = good.find_element(By.CSS_SELECTOR,".p-name").text.replace('\n','')
price = good.find_element(By.CSS_SELECTOR,".p-price").text
link = good.find_element(By.TAG_NAME,"a").get_attribute('href')
msg = '''
商品:%s
价格:%s
链接:%s
'''%(name,price,link)
print(msg)
# GetInfo()
for page in range(1,11):
print(f'爬取{page}页')
GetInfo()
driver.find_element(By.CSS_SELECTOR,'.pn-next').click()
time.sleep(2)
🌟运行结果
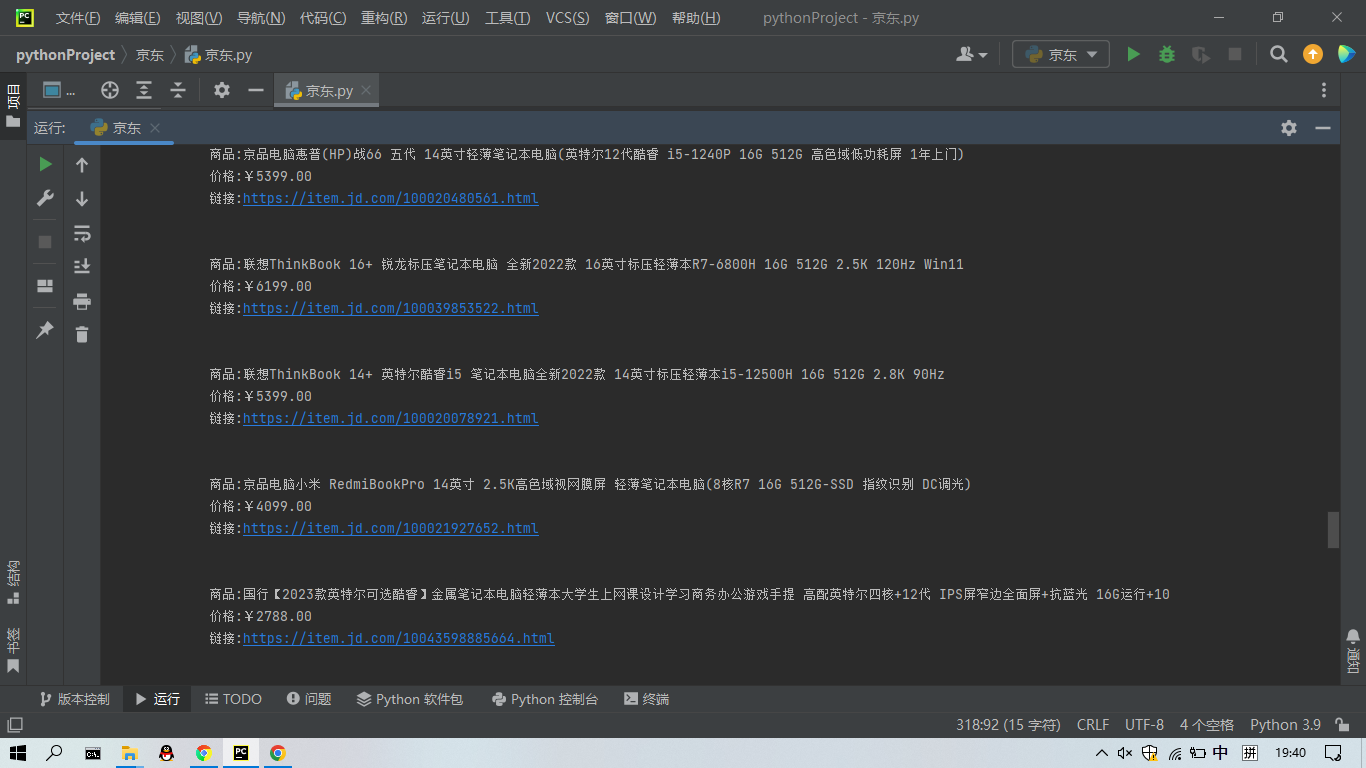
大家注意,这里会有一些语法的问题,博主这里是最新版的selenium。大家如果报错的话,更新自己的selenium库。
替换所有的 ".find_element_by_xpath(" 为
".find_element(By.XPATH,"
替换所有的 ".find_elements_by_xpath(" 为
".find_elements(By.XPATH,"
🌟总结
后面,我还会将两个这样的案例,我们通过实战来了解selenium的好处。这里,我推荐大家使用新版本的selenium,旧版本的不是说不能用,看个人习惯吧。









![[元带你学: eMMC完全解读 7] eMMC 设备与系统概述](https://img-blog.csdnimg.cn/22b0aee764ae4362a717ee114d133dbd.png)
