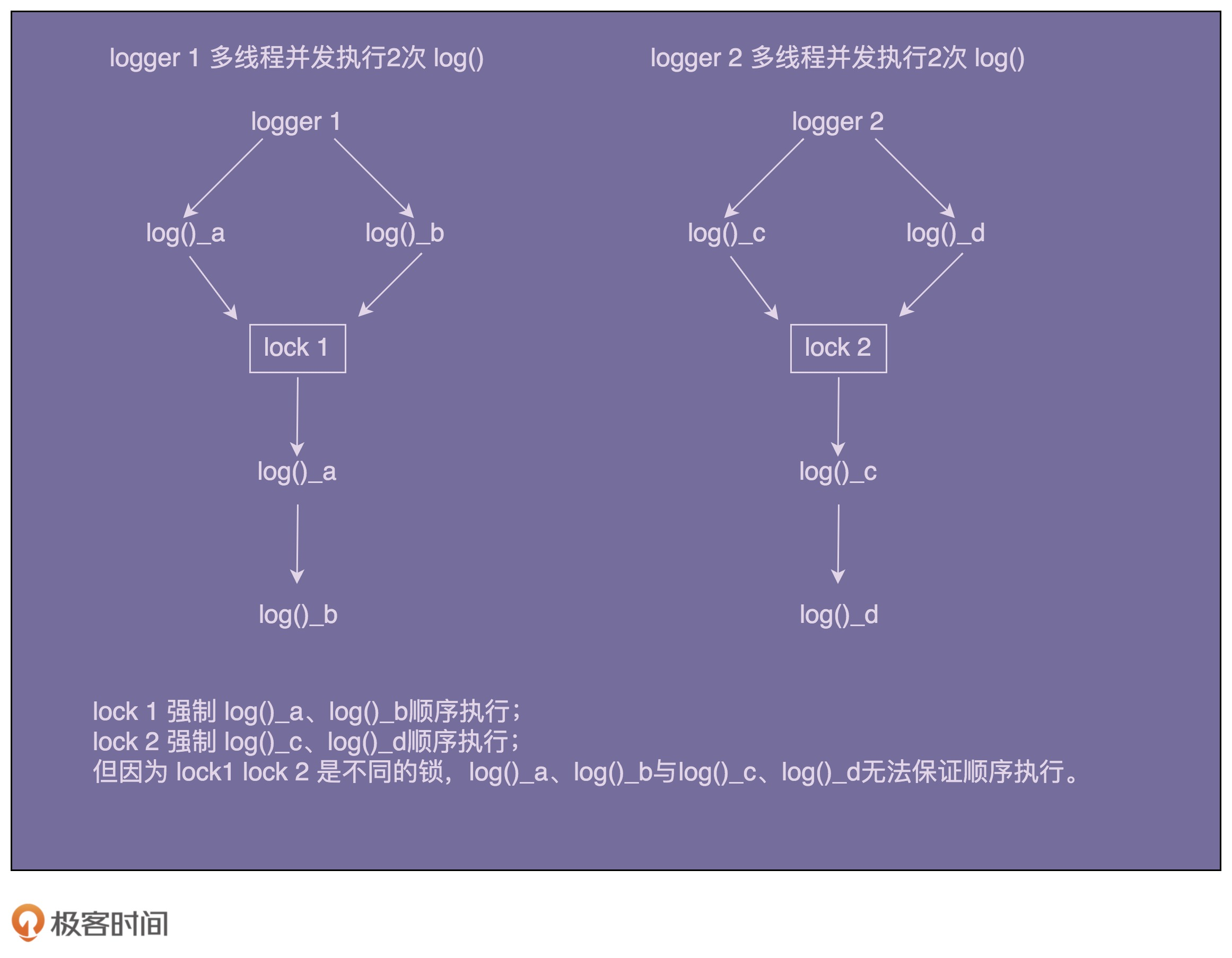
一、C++内存管理
C++中内存基本形式与C语言类似,可以参考下图。
X64环境下总共大小为8G,X86环境下为4G。
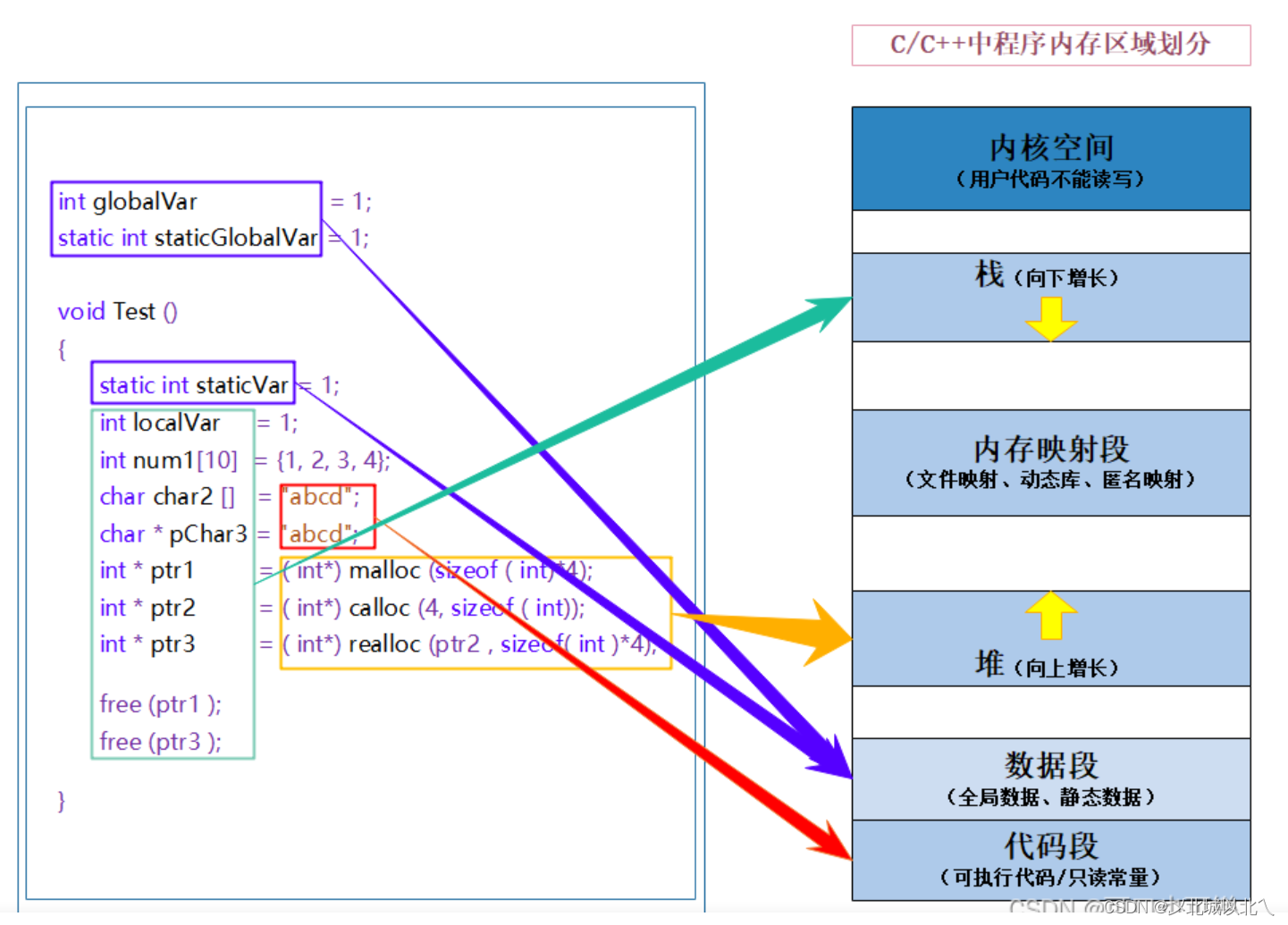
1、内核空间:用户不能读写,但要占用一定空间。
2、栈区:以开辟、销毁栈帧形式运行,主要应用于局部变量和函数栈帧。以及在函数递归中,反复多次开辟、销毁栈帧,使得空间有能够重复利用的可能(死递归时栈溢出)。
向下增长。

但这种向下增长在具体情景下也会受到编译器优化的制约。
3、堆区:用来动态内存分配的,所占空间较大。VS的X86环境下大约为2G,占一半左右。
4、数据段:存储 静态/全局变量
5、代码段:存储全局函数,类的成员函数。一些常量/字符串,且不能被修改。
二、new/delete
与C的区别
malloc/free和new/delete的共同点是:都是从堆上申请空间,并且需要用户手动释放。不同的地
方是:
1. malloc和free是函数,new和delete是操作符
2. malloc申请的空间不会初始化,new可以初始化
3. malloc申请空间时,需要手动计算空间大小并传递,new只需在其后跟上空间的类型即可,
如果是多个对象,[]中指定对象个数即可
4. malloc的返回值为void*, 在使用时必须强转,new不需要,因为new后跟的是空间的类型
5. malloc申请空间失败时,返回的是NULL,因此使用时必须判空,new不需要,但是new需
要捕获异常
6. 申请自定义类型对象时,malloc/free只会开辟空间,不会调用构造函数与析构函数,而new
在申请空间后会调用构造函数完成对象的初始化,delete在释放空间前会调用析构函数完成
空间中资源的清理
用法:
new/delete均是操作符,不再是malloc和free这样的函数。
直接用 new+类型即可,直接定义出对象,这个类型可以是内置类型也可以是自定义类型,可以传参()/使用缺省值,还可以直接定义出多个对象[]。
new可以直接得到调用构造函数初始化了的对象,使用起来更加方便。

这里我使用了缺省值创建了10个A类型的对象,会分别调用10次构造函数,每一个对象里的_a都会被初始化为10.

传参/匿名对象时同样涉及编译器优化的问题,连续的拷贝构造/构造会被优化为直接构造。
底层:
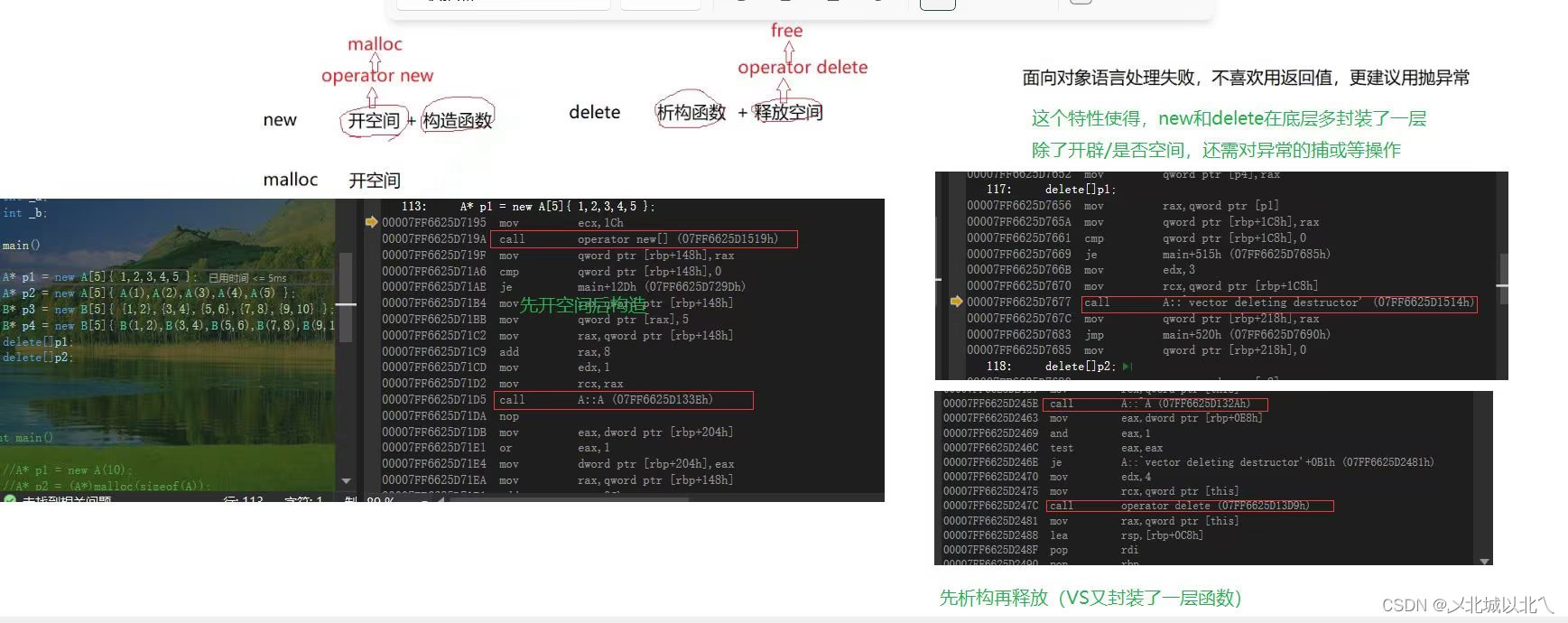
new是开空间+调用构造函数对对象进行初始化,由于面向对象语言特性,需要抛异常,又封装了一层operator new(为全局函数,不是运算符重载)
operator new 实际也是通过malloc来申请空间,如果malloc申请空间成功就直接返回,否则执行用户提供的空间不足应对措施,如果用户提供该措施就继续申请,否则就抛异常。operator delete 最终是通过free来释放空间的。
应用在自定义类型:
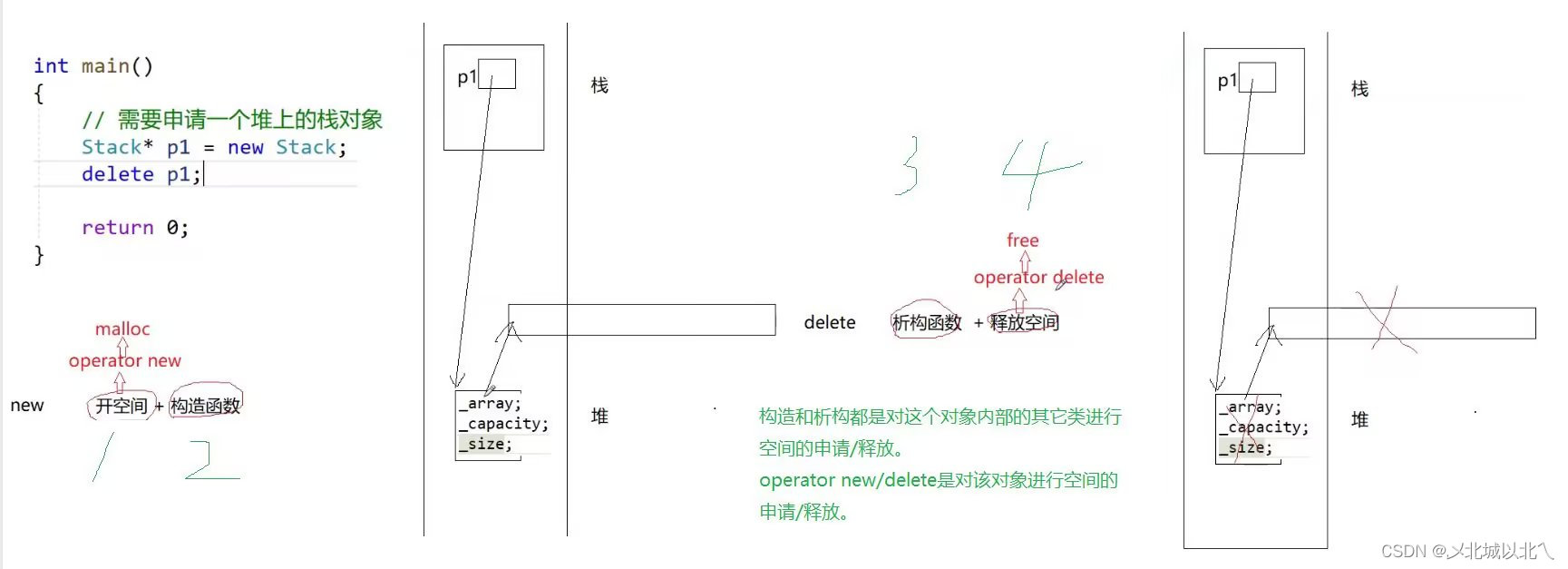
new一个Stack类型时,先开空间,然后调用构造函数,对于Stack的成员变量进行初始化,如果有深拷贝,这个深拷贝也可以被完成。
delete一个Stack类型时,先调用析构函数,进行资源清理,其中深拷贝的部分在析构函数中完成清理,最后再将这个Stack对象的空间给释放。
三、函数模板
C++中类class的引入,使得类型不仅仅是内置类型,更多的是自定义类型。
而由于自定义类型的不确定性,会出现无数多个自定义类型,我们就需要一套通用于所有类型的规则,只需要用一个参数/变量来区分这个类型即可。
例如Swap函数,可以交换内置类型,在C++中,我们希望它也可以做到自定义类型的交换。通过之前函数重载的学习,我们可以通过多次函数重载来实现,但是会有下面2个问题。
1. 重载的函数仅仅是类型不同,代码复用率比较低,只要有新类型出现时,就需要用户自己增加对应的函数。
2. 代码的可维护性比较低,一个出错可能所有的重载均出错。(且如果涉及函数功能的变化,每个类型的重载函数都需要修改)
因此,在C++中,我们升级了编译器。可以完成泛型编程。
泛型编程:编写与类型无关的通用代码,是代码复用的一种手段。模板是泛型编程的基础。
即指定某些参数(来替代类型)交给编译器,使得编译器得到一个模板,用户只要再通过传参等方式,使得编译器确定这个参数,就能自动生成相应的模板函数或模板类。(函数模板和类模板是模板,模板函数/模板类是编译器生成的具体的函数/类)
函数模板的实例化:

通过反汇编可以看出,编译器确实 实例化出了2个不同的函数。
编译器必须确定模板参数:
隐式实例化:
隐式即不指定模板参数T的类型,通过编译器自动推导而得出T的类型(无歧义)。

只有1个模板参数T,传入int类型的a1,和double类型的d1,因此编译器推导不出模板参数T的具体类型,就会报错。
显示实例化:

这里通过<int>和<double>指定了模板参数T的类型,就会使编译器相应的生成并调用对应的Add函数。

也可以定义2个模板参数T1和T2,这样就不用管传入的2个参数类型是否相同的。
不过,如果要返回T1或者T2,实参的顺序还是有影响的。

最后这种情况,由于模板参数T不是通过传参来确定的,就必须通过<>中提前确定T的类型。
模板参数的匹配原则:
1. 一个非模板函数可以和一个同名的函数模板同时存在,而且该函数模板还可以被实例化为这个非模板函数。
2. 对于非模板函数和同名函数模板,如果其他条件都相同,在调动时会优先调用非模板函数而不会从该模板产生出一个实例。如果模板可以产生一个具有更好匹配的函数, 那么将选择模板。
3. 模板函数不允许自动类型转换,但普通函数可以进行自动类型转换。

四、类模板
定义:
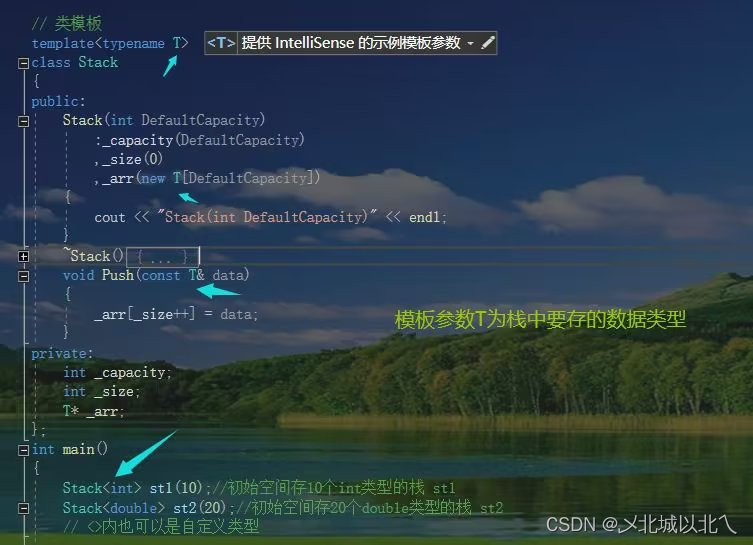
在类的前面,加上template<>,<>内加上这个类中需要用到的模板参数,可以有多个,如下。

栈本身的实现是相同的,但栈中要存储什么元素是事先不知道的。
C语言中需要使用typedef定义同样的类型datatype,但是当我们需要同时使用int栈和double栈时,就必须定义StackInt和StackDouble了。
而在C++中,可以直接用一个模板参数T,来表示要存储的元素类型。
定义声明分离:

定义内,如果要用到模板参数,需要在前面使用template<T,P,Q>指定,它们的作用范围就是这个函数的实现范围。
对于类模板,类名和类型是不同的。类模板名字不是真正的类,而实例化的结果才是真正的类
Stack不为类型,仅为类名,Stack<int>和Stack<double>实例化出的类才是真正的类型。
因此在类外定义成员函数,指定类域时,必须使用class的类型。(类同名时无法区分,必须要通过模板参数T区分,因此指定类域必须通过T)