目录
14.1 分布式数据库
14.2 Web与数据库
14.3 XML与数据库
14.4 面向对象数据库
14.5 大数据与数据库
14.6 NewSQL
前言:
笔记来自《文老师软考数据库》教材精讲,精讲视频在b站,某宝都可以找到,个人感觉通俗易懂。
14.1 分布式数据库
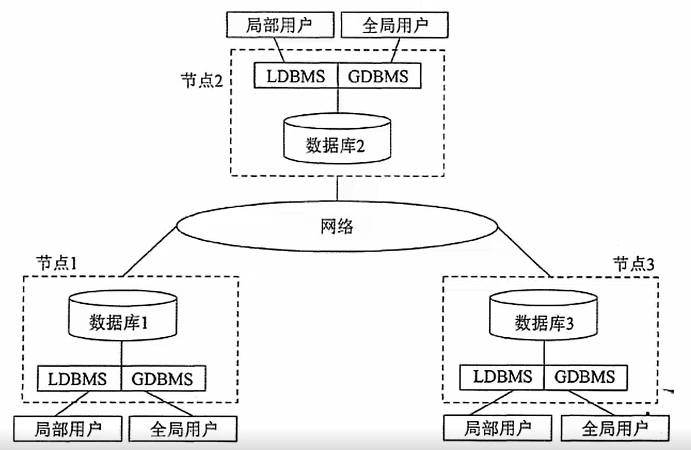
- 分布式数据库是一个物理上分布在计算机网络的不同地点,而逻辑上又属于同一系统的数据集合。网络的每个站点的数据库都有自治能力,能够完成局部应用,同时每个站点的数据库又属于整个系统,通过网络也可以完成全局应用。其组成如下图:
满足下面条件的数据库系统被称为完全分布式数据库系统:
(1)分布性:即数据存储在多个不同的节点上。
(2)逻辑相关性:即数据库系统内的数据在逻辑上具有相互关联的特性。
(3)场地透明性:即使用分布式数据库中的数据时不需指明数据所在的位置。
(4)场地自治性:即每一个单独的节点能够执行局部的应用请求。
- 分布式数据库的特点:数据的集中控制性数据独立性;数据几余可控性;场地自治性存取的有效性。
- 局部数据库位于不同的物理位置,使用一个全局DBMS将所有局部数据库联网管理。其四层体系结构如下图所示:
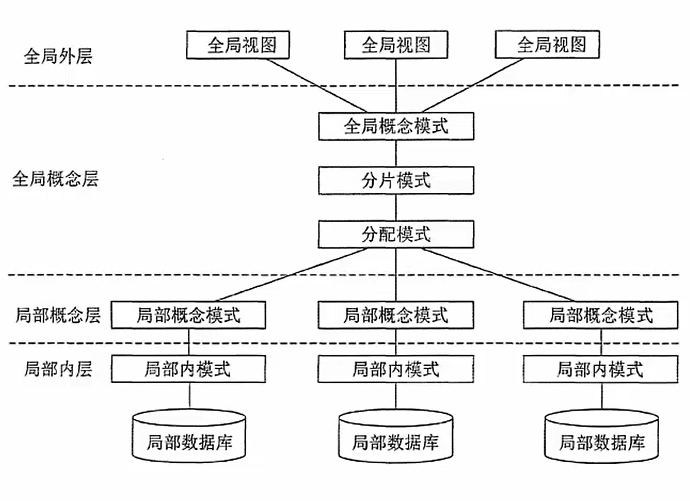
- 从分布透明特性来说,分布式数据库的全局概念层应具有三种模式描述信息:
(1)全局概念模式:
(2)分片模式:描述全局数据逻辑划分的视图它是全局数据的逻辑结构根据某种条件的划分每一个逻辑划分即一个片段,或称为分片。
(3)分配模式:描述局部逻辑的局部物理结构,是划分后的片段(或分片)的物理分配视图它与集中式数据库物理存储结构的概念不同,是全局概念层的内容。 - 分片模式:
水平分片:将表中水平的记录分别存放在不同的地方。
垂直分片:将表中的垂直的列值分别存放在不同的地方。
水平和垂直结合的分片:以上两种的混合。 - 分布透明性:
分片透明性:用户或应用程序不需要知道逻辑上访问的表具体是如何分块存储的。
位置透明性:应用程序不关心数据存储物理位置的改变。
逻辑透明性:用户或应用程序无需知道局部使用的是哪种数据模型。
复制透明性:用户或应用程序不关心复制的数据从何而来。 - 分布式数据库的查询和优化与集中式数据库相比,分布式数据库查询还要考虑以下两方面:
(1)数据和信息均要通过通信线路进行传输,存在的延迟问题将减慢整个查询的执行过程。(2)网络中多处理器的存在提供了并行数据处理和传输的机会,应充分利用以加快查询速度.查询优化:查询执行代价的优化、查询响应时间的优化。 - 分布式数据库管理系统DDBMS包括综合型和联合型两种体系结构:
(1)综合型体系结构:是指在分布式数据库建立之前,还没有建立独立的集中式数据库管理系统,设计人员根据用户的需求,设计出一个全新的完整的数据库管理系统。
(2)联合型体系结构:是指每个节点的数据库管理系统已经存在,在此基础上建立的分布式数据库系统。同时,联合型体系结构又分为同构系统和异构系统。 - 分布式数据库管理系统由四部分组成:LDBMS(局部数据库管理系统)、GDBMS(全局数据).、库管理系统)、全局数据字典 (GDD)、通信管理(CM)。
- 分布式事务特性:原子性、可串行性或一致性、隔离性、持久性。与集中式数据库事务区别:
(1)执行特性:创建一个控制进程协调各子事务的操作。
(2)操作特性:需要加入大量通信原语负责协调进程和代理进程之间的数据传送等。
(3)控制制板文“事务操作进行协调。 - 分布式数据库故障:介质故障、系统故障、事务故障、网络分割故障、报文故障分布式数据库的恢复原则:
1)孤立和逐步退出事务的原则: 对于不影响其他事务的可排除性局部故障,例如事务操作的删除超时、违反完整性规则、资源、限制、死锁等,应令某个事务孤立地和逐步地退出,将其所做过的修改复原,即做UNDO。
2)成功结束事务原则:成功结束事务所做过的修改应超越各种故障,当故障发生时,应该重做(REDO) 事务的所有操作。
3)天折事务的原则:若发生了非局部性的不可排除的故障,例如系统崩愤,则撤销全部事务,恢复到初态。这有两种做法:一种是利用数据库的备份实现:另一种是按反向顺序操作,复原其启动以来所做过的一切修改。 - 两阶段提交2PC:保证分布式事务的原子性。由于数据库分布在不同的地址位置,其事务可能涉及到不同数据库的操作,需要二阶段提交来保证原子性。
- 第一阶段是表决阶段,目的是形成一个共同的决定,由协调者发起开始提交的记录,所有参与者决定是否能提交本地事务,只要有一个参与者做出建议撤销的提议,为了保证原子性,协调者就必须整体上撤销这个提交。
- 第二阶段是执行阶段,协调者依据第一阶段的决定执行撤销或提交该事务。
14.2 Web与数据库
- 数据与资源共享这两种技术的结合即成为今天广泛应用的Web 数据库(也叫网络数据库)个Web 数据库就是用户利用浏览器作为输入接口,输入所需要的数据,浏览器将这些数据传送给网站,由网站对这些数据进行处理。网站上的后台数据库就是Web 数据库。
- 连接数据库的常用方法: ODBC、DAO、RDO、ADO。
- Web和数据库的运行模式:

14.3 XML与数据库
- XML,意为可扩展的标记语言。XML是一套定义语义标记的规则,这些标记将文档分成许多部件并对这些部件加以标识。
- 采用文件存储XML,那么会受到文件系统的限制,出现如下问题: 大小、并发性、工具选择.版本、安全、综合性(集中和重复)。
- XML文档中的数据视图模型:
(1)表格模型:许多中间件软件包都采用表格模型在XML和关系型数据库之间进行转换。它把XML的模型看成是一个单独的表格或者是一系列的表格。
(2)特定数据对象模型:在该模型中,元素类型通常对应对象,而XML 中的内容模型、属性和PCDATA则对应对象的属性。这种模型直接映射成面向对象的数据库和层次型数据库,当然借助于传统的对象-关系映射技术和SOL对象视图也可以映射成关系数据库。
14.4 面向对象数据库
- 数据库技术与面向对象程序设计方法相结合形成了面向对象数据库系统(OODBS),它是支持将数据当作对象来模拟和创造的一种数据库管理系统。通常认为,对象数据库必须满足两项标准:它必须是一个数据库管理系统,并且必须是面向对象的系统。
- 面向对象数据库系统的特征:
(1)面向对象数据库系统应该具有表达和管理对象的能力。
(2)面向对象数据库系统中的对象可以具有任意复杂度的对象结构。
(3)面向对象数据库系统必须具有与面向对象编程语言交互的接口。
(4)面向对象数据库应具有表达和管理数据库变化的能力。 - 面向对象数据模型的基本概念有对象、类、继承、对象标识、对象嵌套等。
1.对象结构我们可以认为一个对象对应着E-R 模型中的一个实体。对象中封装的属性和方法对外界是不可见的,对象之间的相互作用要通过消息来实现。一般来讲,一个对象包括:属性集合方法集合、消息集合。
2.对象类:在面向对象数据库中,类是一系列相似对象的集合,对应于E-R 模型中的实体集概念3.继承与多重继承。
4.对象标识:每个对象有一个唯一的、由系统生成的对象标识。
5.对象嵌套:对象的一个属性可以是一个单一值,也可以是一个来自于值域的值集,即一个对象的属性可以是一个对象,形成了嵌套关系。一个对象被称为复杂对象,如果它的某个属性的值是另一个对象。 - 面向对象数据库语言主要包括对象定义语言和对象操纵语言。对象查询语言是对象操纵语言的个重要子集。面向对象数据库语言一般应具备功能:类的定义和操纵、操作/方法的定义、对象的操纵。
- 对象关系数据模型扩展关系数据模型的方式是通过提供一个包括复杂数据类型和面向对象的更丰富的类型系统。有如下手段:
(1)嵌套关系
(2)复杂类型
(3)继承、引用类型
(4)与复杂类型有关的查询
(5)函数与过程。
(6)面向对象与对象关系
14.5 大数据与数据库
- 大数据是一种具有海量的数据规模,在获取、存储、管理和分析等方面都远远超过传统数据库处理范围的数据集合。
- 工业界便用三大特征作为大数据的分类标准。第一个维度是体量大,第二个维度是速度快,第个维度是多样性。
- 大数据之数据仓库设计:数据仓库相关内容在数据库技术基础已经阐述过,这里不再整述。
- 数据转移,也称为数据转换或数据变换,就是把多种传统资源或外部资源信息中不完善的数据自动转换为商务中准确可靠的数据。在数据仓库环境中进行数据转移的目的应该有两个:
第一,改进数据仓库中数据的质量;
第二,提高数据仓库中数据的可用性。 - 包括四种转移类型:
(1)简单转移。简单转移是所有数据转移的基本构成单元。
(2)清洗。清洗的目的是保证前后一致地格式化和使用某--字段或相关的字段群。
(3)集成。集成是指将业务数据从一个或几个来源中取出,并逐字段地将数据映射到数据仓库的新数据结构上。
(4)聚集和概括。聚集和概括是把业务环境中找到的零星数据压缩成仓库环境中的较少数据块.。
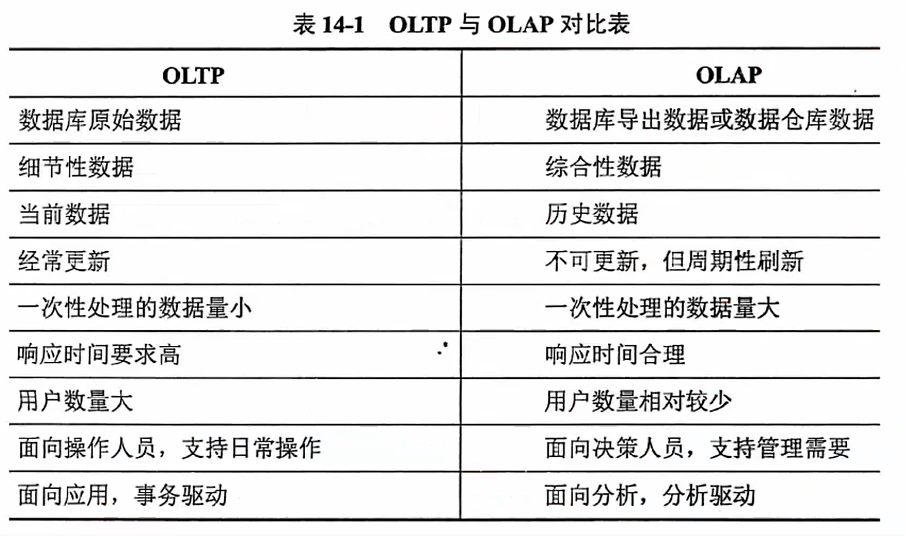
14.6 NewSQL
- NewSQL 是一种新型关系数据库管理系统是对各种新的可扩展和高性能数据库的简称,这类数据库不仅具有NoSQL 对海量数据的存储管理力,试图为联机事务处理(OLTP)读写工作负载提供与NOSQL系统相同的可伸缩性能,还保持了传统数据库支持ACID 和SQL等特性。
- NewSQL 系统虽然在的内部结构变化很大,但是它们有两个显著的共同特点: 支持关系数据模型和使用SQL 作为其主要的接口。目前NewSQL 系统可通过架构、SQL引擎和数据分片分成三类:
(1)新架构:采用新架构的NewSQL 系统是全新的数据库平台,使用两种不同的设计方法:
第一种设计的数据库工作在一个分布式集群的节点上,其中每个节点拥有一个数据子集。SQI查询被分成查询片段发送给自己所在的数据的节点上执行。
第二种设计的数据库系统通常有一个单一的主节点的数据源。它们有一组节点用来做事务处理这些节点接到特定的SQL 查询后,会把它所需的所有数据从主节点上取回来后执行SQL查询,再返回结果。
(2)SQL引擎:第二类是高度优化的SQL 存储引警。这些系统提供了MySQL 相同的编程接口,但扩展性比MySQL内置的引警更好。
(3)数据分片:关系型数据库不能满足每秒大量的数据操作和写入率。为了解决这个问题,提供了分片的中间件层,数据库自动分割在多个节点运行。
【软考数据库】第一章 计算机系统基础知识
【软考数据库】第二章 程序语言基础知识
【软考数据库】第三章 数据结构与算法
【软考数据库】第四章 操作系统知识
【软考数据库】第六章 数据库技术基础
【软考数据库】第五章 计算机网络
【软考数据库】第六章 数据库技术基础
【软考数据库】第七章 关系数据库
【软考数据库】第八章 数据库SQL语言
【软考数据库】第九章 非关系型数据库NOSQL
【软考数据库】第十章 系统开发与运行
【软考数据库】第十一章 数据库设计
【软考数据库】第十二章 事务管理
【软考数据库】第十三章 云计算与大数据处理








![学习open62541 --- [76] 使用智能指针处理内存释放问题](https://img-blog.csdnimg.cn/9e4908a8eb5d4a3b97ab33163835bcc2.png)