学习视频561-JavaSE进阶-IO流概述_哔哩哔哩_bilibili
目录
IO流概述
IO流的分类
IO流四大家族
FileInputStream初步(并非最终方法)
FileInputStream循环读(并非最终方法)
往byte数组中读
FileInputStream最终版
FileInputStream的其他常用方法
FileOutputStream的使用
文件复制
FileReader的使用
FileWriter的使用
复制普通文本文件
带有缓冲区的字符流
节点流和包装流
带有缓冲区的字符输出流
编辑
数据流
标准输出流
日志记录工具:
File类的理解
File类的常用方法
目录拷贝
序列化和反序列化的理解
序列化的实现
反序列化的实现
序列化多个对象
transient关键字
关于序列化版本号
编辑
IDEA快捷键生成序列化版本号
IO和Properties联合使用
IO流概述
什么是IO流?=文件的输入和输出
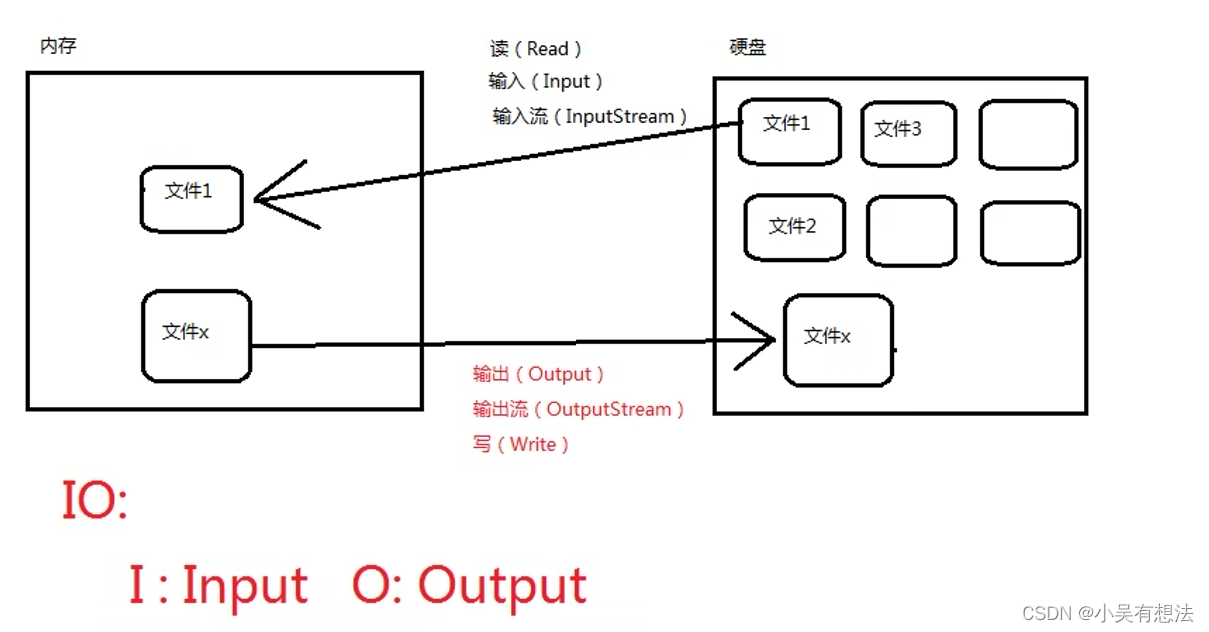
I:Input
O:Output
通过IO可以完成硬盘文件的读和写
IO流的分类
有多种分类方式:
- 一种方式是按照流的方向进行分类
以内存作为参照物,
往内存中去,叫做输入,或者叫做读
从内存中出来,叫做输出,或者叫做写
- 另一种方式是按照读取数据方式不同进行分类
有的流是按照字节的方式读取数据,一次读取1个字节byte,等同于一次读取8个二进制位,这种流是万能的,什么类型的文件都可以读取。包括:文本文件,图片,声音文件,视频文件等。
假设file1.txt,采用字节流的话是这样读的:
a中国bc张三f
第一次读:一个字节,正好读到'a'
第二次读:一个字节,正好读到'中'字符的一半
第三次读:一个字节,正好读到'中'字符的另外一半
有的流是按照字符的方式读取数据的,一次读取一个字符,这种流是为了方便读取普通文本文件而存在的,这种流不能读取:图片、声音、视频等文件。只能读取纯文本文件,连word文件都无法读取。
假设文件file1.txt,采用字符流的话是这样读的:
a中国bc张三f
第一次读:'a'字符('a'字符在windows系统中占用1个字节)
第二次读:'中'字符('中'字符在windows系统占用2个字节)
综上所述:流的分类
输入流、输出流
字节流、字符流
注意:‘a’英文字母,在windows操作系统中是一个字节。但是'a'字符在java中占用2个字节
字节流直接读取的是8个二进制位,字符流可以一个字符一个字符检测出来。
Java中的IO流都已经写好了,我们程序员不需要关心,我们最主要还是要掌握在java中已经提供了哪些流,每个流的特点是什么,每个流对象上的常用方法有哪些?
java中所有的流都是在: java. io.*;下
java中主要还是研究:
怎么new流对象
调用流对象的哪个方法是读,哪个方法是写
IO流四大家族
四大家族的首领:
java.io.InputStream;//字节输入流
java.io.OutputStream;//字节输出流
java.io.Reader;//字符输入流
java.io.Writer;//字符输出流四大家族的首领都是抽象类。(abstract class)
所有的流都实现了:
java.io.Closeable接口,都是可关闭的,都有close()方法。
流毕竟是一个管道,这个是内存和硬盘之间的通道,用完之后一定要关闭,
不然会耗费(占用)很多资源,养成好习惯,用完即关闭。
所有的输出流都实现了:
java.io.Flushable接口,都是可刷新的,都有flush()方法。养成一个好习惯,输出
流在最终输出之后,一定要记得flush()刷新一下,这个刷新表示将管道/通道当中剩余未输出
的数据强行输出完(清空管道!) 刷新的作用就是清空管道。
注意:如果没有flush()可能会导致丢失数据
注意:在java中只要"类名"以stream结尾的都是字节流.以"Reader/Writer"结尾的都是字符流。
java.io包下需要掌握的16个流
- 文件专属
java.io.FileInputStream
java.io.FileOutputStream
java.io.FileReader
java.io.FileWriter
- 转换流 (将字节流转换成字符流)
java.io.InputStreamReader
java.io.OutputStreamWriter
- 缓冲流专属
java.io.BufferedReader
java.io.BufferedWriter
java.io.BufferedInputStream
java.io.BufferedOutputStream
- 数据流专属
java.io.DataInputStream
java.io.DataOutputStream
- 标准输出流
java.io.PrintWriter
java.io.PrintStream
- 对象专属流
java.io.ObjectInputStream
java.io.ObjectOutputStream
FileInputStream初步(并非最终方法)
创建一个文本,内容写为abcdef
初步代码:
/*
java.io.FileInputStream:
1.文件字节输入流,万能的,任何类型的文件都可以采用这个流来读
2.字节的方式,完成输入的操作,完成读的操作(硬盘---->内存)
3.
*/
import java.io.FileInputStream;
import java.io.FileNotFoundException;
import java.io.IOException;
public class FileInputStreamTest01 {
public static void main(String[] args) {
//创建文件字节输入流对象
FileInputStream fis=null;
try {
/*
文件路径D:\JAVA\atmp (IDEA会自动把\编程\\,因为java中\表示转义
写成下面这种形式也是可以的
*/
fis=new FileInputStream("D:/JAVA/atmp");
//开始读
int readData=fis.read();//这个方法的返回值是:读取到的"字节"本身
System.out.println(readData);//文件里是abcdef 先得到的是97
readData=fis.read();
System.out.println(readData);//得到98,每调用一次read()往下读一个字节
readData=fis.read();
System.out.println(readData);
readData=fis.read();
System.out.println(readData);
readData=fis.read();
System.out.println(readData);
readData=fis.read();
System.out.println(readData);
readData=fis.read();
System.out.println(readData);
readData=fis.read();
System.out.println(readData);//已经读到文件的末尾了,再读的是读取不到任何数据,返回-1
} catch (FileNotFoundException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
} finally {
//在finally语句块中确保流一定关闭
if(fis!=null)
{
//关闭的前提是,流不为空,空没必要关(避免空指针异常)
try {
fis.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
}

FileInputStream循环读(并非最终方法)
import java.io.FileInputStream;
import java.io.FileNotFoundException;
import java.io.IOException;
/*
对第一个程序进行改进,循环方式。
*/
public class FileInputStreamTest02 {
public static void main(String[] args) {
FileInputStream fis=null;
try {
fis=new FileInputStream("D:/JAVA/atmp");
while (true)
{
int readData= fis.read();
if(readData==-1)
{
break;
}
System.out.println(readData);
}
//改造while循环
int readData=0;
while ((readData=fis.read())!=-1)
{
System.out.println(readData);
}
} catch (FileNotFoundException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
} finally {
if (fis != null) {
try {
fis.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
}分析这个程序的缺点:
一次读取一个字节byte,这样内存和硬盘交互太频繁,基本上时间/资源都耗费在交互上面了
往byte数组中读

import java.io.FileInputStream;
import java.io.FileNotFoundException;
import java.io.IOException;
/*
int read(byte[] b)
一次最多读取b.length个字节
减少硬盘和内存的交互,提高程序的执行效率
往byte[] 数组当中读.
*/
public class FileInputStreamTest03 {
public static void main(String[] args) {
FileInputStream fis=null;
try {
//如果用相对路径的话请注意:工程project的根就是IDEA的默认当前路径(这里我是在days2点进去创建的一个ssa,编译才没报错)
fis=new FileInputStream("D:/JAVA/atmp");
//开始读,采用byte数组,一次读取多个字节,最多读取"数组.length"个字节
byte[] bytes=new byte[4];//一次读取4个字节
// 这个方法的返回值是:读取到的字节数量.(不是字节本身)
int readCount=fis.read(bytes);
System.out.println(readCount);//4,第一次读到了4个字节,返回4
//System.out.println(new String(bytes));//abcd
//不应该全部都转换,应该是读取了多少个字节,转换多少个.
System.out.println(new String(bytes,0,readCount));
readCount=fis.read(bytes);
System.out.println(readCount);//2,第二次只能读取到2个字节
// System.out.println(new String(bytes));//efcd
System.out.println(new String(bytes,0,readCount));
readCount=fis.read(bytes);
System.out.println(readCount);//-1,1个字节都没有读到返回-1
// System.out.println(new String(bytes));//efcd
} catch (FileNotFoundException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
} finally {
if (fis!=null)
{
try {
fis.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
} 
FileInputStream最终版
import java.io.FileInputStream;
import java.io.FileNotFoundException;
import java.io.IOException;
public class FileInputStreamTest04 {
public static void main(String[] args) {
FileInputStream fis=null;
try {
fis=new FileInputStream("hello");
//准备一个byte数组
byte []bytes=new byte[4];
// while (true)
// {
// int readCount=fis.read(bytes);
// if(readCount==-1)
// {
// break;
// }
// //把byte数组转换成字符串,读到多少个转换多少个.
// System.out.print(new String(bytes,0,readCount));
// }
int readCount=0;
while ((readCount=fis.read(bytes))!=-1)
{
System.out.print(new String(bytes,0,readCount));
}
} catch (FileNotFoundException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
} finally {
if(fis!=null)
{
try {
fis.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
}

相对路径的话是这样:
FileInputStream的其他常用方法
available()
import java.io.FileInputStream;
import java.io.FileNotFoundException;
import java.io.IOException;
/*
FileInputStream类的其它常用方法:
int available():返回流当中剩余的没有读到的字节数量
long skip(long n):跳过几个字节不读
*/
public class FileInputSreamTest05 {
public static void main(String[] args) {
FileInputStream fis=null;
try {
fis=new FileInputStream("D:/JAVA/atmp");
System.out.println("总字节数量:"+fis.available());
// //读一个字节
// int readbyte=fis.read();
// //还剩下可以读的字节数量 5
// System.out.println("还剩下多少个字节可以读:"+fis.available());
// //该方法的用处
byte[] bytes=new byte[fis.available()];//这种方式不太适合太大的文件,因为byte[]数组不能太大。
//不需要循环了
//直接读一次就可以了
int readCount=fis.read(bytes);//6
System.out.println(new String(bytes));//abcdef
} catch (FileNotFoundException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
} finally {
if(fis!=null)
{
try {
fis.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
}

skip()
import java.io.FileInputStream;
import java.io.FileNotFoundException;
import java.io.IOException;
/*
FileInputStream类的其它常用方法:
int available():返回流当中剩余的没有读到的字节数量
long skip(long n):跳过几个字节不读
*/
public class FileInputSreamTest05 {
public static void main(String[] args) {
FileInputStream fis=null;
try {
fis=new FileInputStream("D:/JAVA/atmp");
System.out.println("总字节数量:"+fis.available());
// //读一个字节
// int readbyte=fis.read();
// //还剩下可以读的字节数量 5
// System.out.println("还剩下多少个字节可以读:"+fis.available());
// //该方法的用处
byte[] bytes=new byte[fis.available()];//这种方式不太适合太大的文件,因为byte[]数组不能太大。
//不需要循环了
//直接读一次就可以了
// int readCount=fis.read(bytes);//6
// System.out.println(new String(bytes));//abcdef
//skip跳过几个字节不读取,这个方法可能以后会用
fis.skip(3);
System.out.println(fis.read());//d=100
} catch (FileNotFoundException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
} finally {
if(fis!=null)
{
try {
fis.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
}
这里读取的是 d 所对应的字节->100

FileOutputStream的使用
package io;
/*
文件字节输出流,负责写。
从内存到硬盘
*/
import java.io.FileNotFoundException;
import java.io.FileOutputStream;
import java.io.IOException;
public class FileOutputStreamTest01 {
public static void main(String[] args) {
FileOutputStream fos=null;
try {
//开始写,写完之后刷新,这种方式谨慎使用,因为使用过后会将原文件清空
// fos=new FileOutputStream("myfile");
// 以追加的方式在文件末尾写入。不会清空原文件内容。
fos=new FileOutputStream("myfile",true);
byte [] bytes={97,98,99,100};
//将byte数组全部写出
fos.write(bytes);
//将byte数组的一部分写出
fos.write(bytes,0,2);//再写出ab
String s="我白小纯弹指间IO灰飞烟灭";
//将字符串转换成byte数组
byte [] bs=s.getBytes();
fos.write(bs);
fos.flush();
} catch (FileNotFoundException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
} finally {
if (fos!=null)
{
try {
fos.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
}
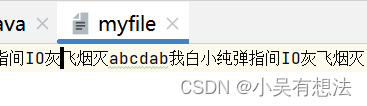
文件复制
package io;
import java.io.FileInputStream;
import java.io.FileNotFoundException;
import java.io.FileOutputStream;
import java.io.IOException;
public class Copy01 {
public static void main(String[] args) {
FileInputStream fis=null;
FileOutputStream fos=null;
try {
//输入流对象
fis=new FileInputStream("myfile");
//输出流对象
fos=new FileOutputStream("hello");
//一边读,一边写
byte[] bytes=new byte[1024 * 1024];//1MB
int readCount=0;
while ((readCount=fis.read(bytes))!=-1)
{
fos.write(bytes,0,readCount);
}
//刷新,输出流最后要刷新
fos.flush();
} catch (FileNotFoundException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
finally {
if (fis!=null)
{
try {
fis.close();
} catch (IOException e) {
e.printStackTrace();
}
}
if (fos!=null)
{
try {
fos.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
}
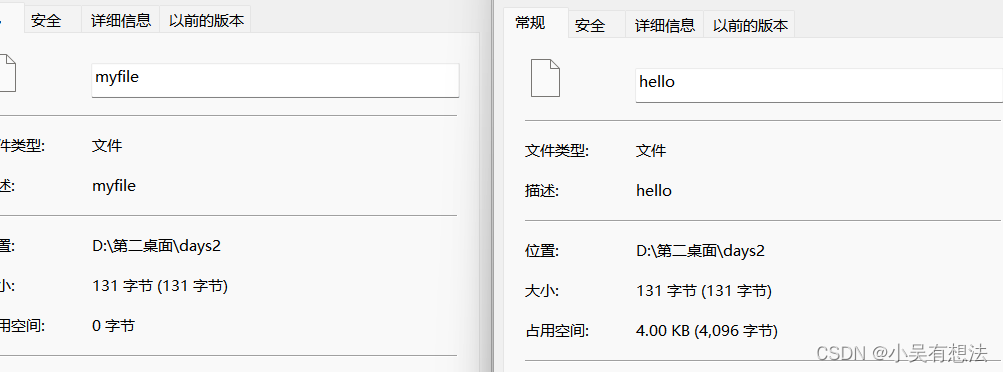
FileReader的使用
package io;
import java.io.FileNotFoundException;
import java.io.FileReader;
import java.io.IOException;
public class FileReaderTest {
public static void main(String[] args) {
FileReader reader=null;
try {
//创建文件字符输入流
reader=new FileReader("myfile");
//开始读
char [] chars=new char[4];
int readCount=0;
while ((readCount=reader.read(chars))!=-1)
{
System.out.print(new String(chars,0,readCount));
}
} catch (FileNotFoundException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
} finally {
if (reader!=null)
{
try {
reader.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
}

FileWriter的使用
package io;
/*
FileWriterTest:
文件字符输出流,写
只能输出普通文本
*/
import java.io.FileWriter;
import java.io.IOException;
public class FileWriterTest {
public static void main(String[] args) {
FileWriter out=null;
try {
//创建文件字符输出流对象
out=new FileWriter("hello");
//开始写
char[] chars={'我','面','壁','者','罗','辑','现','在','对','三','体','世','界','说','话'};
out.write(chars);
out.write(chars,1,5);
out.write('\n');
out.write("hello,world");
out.flush();
} catch (IOException e) {
e.printStackTrace();
}
finally {
if(out!=null)
{
try {
out.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
}
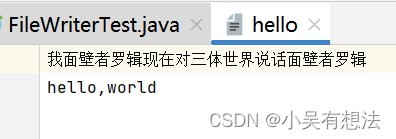
复制普通文本文件
.java文件也属于普通文本文件,java执行的是class文件
package io;
/*
使用FileReader FileWriter进行拷贝的话,只能拷贝"普通文本文件"
*/
import java.io.FileNotFoundException;
import java.io.FileReader;
import java.io.FileWriter;
import java.io.IOException;
public class Copy02 {
public static void main(String[] args) {
FileReader in=null;
FileWriter out=null;
try {
// 读
in=new FileReader("hello");
// 写
out=new FileWriter("myfile");
// 一边读一边写:
char[] chars=new char[1024 * 512];
int readCount=0;
while ((readCount=in.read(chars))!=-1)
{
out.write(chars,0,readCount);
}
out.flush();
} catch (FileNotFoundException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
finally {
if(in!=null)
{
try {
in.close();
} catch (IOException e) {
e.printStackTrace();
}
}
if(out!=null)
{
try {
out.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
}
带有缓冲区的字符流
package io;
import java.io.BufferedReader;
import java.io.FileNotFoundException;
import java.io.FileReader;
import java.io.IOException;
/*
BufferedReader:
带有缓冲区的字符输入流。
使用这个流的时候不需要自定义char数组,或者说不需要自定义byte数组,自带缓冲。
*/
public class BufferedReaderTest01 {
public static void main(String[] args) {
FileReader reader = null;
BufferedReader br =null;
try {
reader = new FileReader("hello");
//当一个流的构造方法中需要一个流的时候,这个被传进来的流叫做:节点流
//外部负责包装的这个流,叫做: 包装流,还有一个名字叫做:处理流
//像当前这个程序来说:FileReader就是一个节点流,BufferedReader就是包装流/处理流
br = new BufferedReader(reader);
// // 读一行
// String firstLine=br.readLine();
// System.out.println(firstLine);
//
// String SecondLine=br.readLine();
// System.out.println(SecondLine);
//
// String lin3=br.readLine();
// System.out.println(lin3);
String s=null;
while ((s=br.readLine())!=null)
{
System.out.print(s);
}
} catch (FileNotFoundException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
} finally {
if(br!=null)
{
try {
br.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
}

节点流和包装流
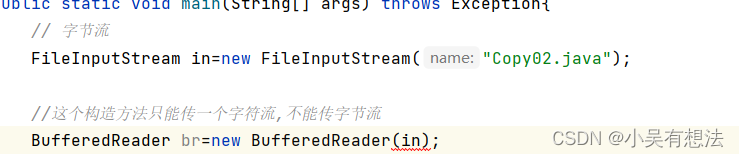
这种情况下需要通过转换流转换
package io;
import java.io.BufferedReader;
import java.io.FileInputStream;
import java.io.InputStream;
import java.io.InputStreamReader;
public class BufferedReaderTest02 {
public static void main(String[] args) throws Exception{
// // 字节流
// FileInputStream in=new FileInputStream("hello");
// // 通过转换流转换(将字节流转换成字符流)
// //in 是节点流 reader是包装流
// InputStreamReader reader=new InputStreamReader(in);
//
// //这个构造方法只能传一个字符流,不能传字节流
// // reader是节点流,br是包装流
// BufferedReader br=new BufferedReader(reader);
//
//
// 合并
BufferedReader br=new BufferedReader(new InputStreamReader(new FileInputStream("hello")));
String line=null;
while ((line=br.readLine())!=null)
{
System.out.println(line);
}
//关闭最外层
br.close();
}
}

带有缓冲区的字符输出流
package io;
/*
BufferedWriter:带有缓冲的字符输出流.
*/
import java.io.*;
public class BufferedWriterTest01 {
public static void main(String[] args) throws IOException {
//带有缓冲区的字符输出流
// BufferedWriter out=new BufferedWriter(new FileWriter("copy"));
BufferedWriter out=new BufferedWriter(new OutputStreamWriter(new FileOutputStream("copy",true)));
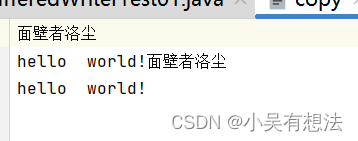
out.write("面壁者洛尘");
out.write("\n");
out.write("hello world!");
//刷新
out.flush();
//关闭最外层
out.close();
}
}
数据流
写:
package io;
import java.io.DataOutputStream;
import java.io.FileNotFoundException;
import java.io.FileOutputStream;
public class DataOutputStreamTest {
public static void main(String[] args) throws Exception {
//创建数据专属的字节输出流
DataOutputStream dos=new DataOutputStream(new FileOutputStream("data"));
//写数据
byte b=100;
short s=200;
int i=300;
long l=400L;
float f=3.0F;
double d=3.14;
boolean sex=false;
char c='a';
//写
dos.writeByte(b);// 把数据以及数据类型一并写入到文件当中。
dos.writeShort(s);
dos.writeInt(i);
dos.writeLong(l);
dos.writeFloat(f);
dos.writeDouble(d);
dos.writeBoolean(sex);
dos.writeChar(c);
//刷新
dos.flush();
//关闭最外层
dos.close();
}
}
读:
package io;
import java.io.DataInputStream;
import java.io.FileInputStream;
/*
DataInputStream:数据字节输入流
DataOutputStream写的文件,只能使用DataInputStream去读.并且读的时候你需要提前知道写入的顺序.
读的顺序需要和写的顺序一致。才可以正常取出数据。
*/
public class DataInputStreamTest01 {
public static void main(String[] args) throws Exception{
DataInputStream dis=new DataInputStream(new FileInputStream("data"));
//开始读
byte b=dis.readByte();
short s=dis.readShort();
int i=dis.readInt();
long l=dis.readLong();
float f=dis.readFloat();
double d=dis.readDouble();
boolean sex=dis.readBoolean();
char c=dis.readChar();
System.out.println(b);
System.out.println(s);
System.out.println(i+100);
System.out.println(l);
System.out.println(f);
System.out.println(d);
System.out.println(sex);
System.out.println(c);
dis.close();
}
}

标准输出流
package io;
/*
java.io.PrintStream:标准的字节输出流,默认输出到控制台
*/
import java.io.FileNotFoundException;
import java.io.FileOutputStream;
import java.io.PrintStream;
public class PrintStreamTest {
public static void main(String[] args) throws FileNotFoundException {
System.out.println("hello,world!");
PrintStream ps=System.out;
ps.println("hello zhangsan");
ps.println("hello lisi");
ps.println("hello wangwu");
// 标准输出流不需要手动close()关闭.
// 可以修改标准输出流的输出方向
/*
// 这些是之前system类使用过的方法和属性
System.gc();
System.currentTimeMillis();
PrintStream ps2=System.out;
System.exit(0);
System.arraycopy(...);
*/
// 标准输出流不再指向控制台,指向"log"文件
PrintStream ps2=new PrintStream(new FileOutputStream("log"));
// 修改输出方向,将输出方向改到"log"文件
System.setOut(ps2);
// 再输出
System.out.println("面壁者");
System.out.println("罗辑");
}
}

日志记录工具:
package io;
import java.io.FileNotFoundException;
import java.io.FileOutputStream;
import java.io.PrintStream;
import java.text.SimpleDateFormat;
import java.util.Date;
public class Logger {
/*
记录日志的方法
*/
public static void log(String msg) {
try {
//指向一个日志文件
PrintStream out=new PrintStream(new FileOutputStream("log.txt",true));
//改变输出方向
System.setOut(out);
//日期当前时间
Date nowTime=new Date();
SimpleDateFormat sdf=new SimpleDateFormat("yyyy-MM-dd HH:mm:ss SSS");
String strTime=sdf.format(nowTime);
System.out.println(strTime+":"+msg);
} catch (FileNotFoundException e) {
e.printStackTrace();
}
}
}
package io;
public class LogTest {
public static void main(String[] args) {
//测试工具类是否好用
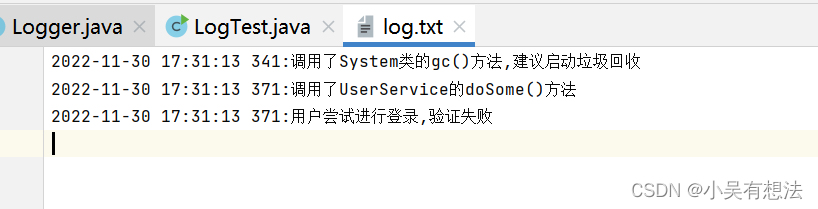
Logger.log("调用了System类的gc()方法,建议启动垃圾回收");
Logger.log("调用了UserService的doSome()方法");
Logger.log("用户尝试进行登录,验证失败");
}
}
File类的理解

File是文件和目录路径名的抽象表示形式。
package io;
import java.io.File;
import java.io.IOException;
/*
1.File类和四大家族么有关系,所以File类不能完成文件的读和写
2.File对象代表什么?
文件和目录路径名的抽象表示形式
一个File对象有可能对应的是目录,也有可能是文件
3.File类中的常用方法
*/
public class FileTest01 {
public static void main(String[] args) throws IOException {
File f1=new File("D:\\file");
//判断是否存在
System.out.println(f1.exists());
//如果D:\file 不存在,则以文件的形式创建出来
// if(!f1.exists())
// {
// //以文件形式新建
// f1.createNewFile();
// }
//如果D:\file不存在,则以目录的形式创建出来
// if(!f1.exists())
// {
// f1.mkdir();
// }
//可以创建多重目录吗?
File f2=new File("D:/a/b/c/d/e/f");
// if(!f2.exists())
// {
// //以 多重目录的形式新建
// f2.mkdirs();
// }
File f3=new File("D:\\course\\开课\\学习方法.txt");
//获取该文件的父路径
String parentPath=f3.getParent();
System.out.println(parentPath); //D:\course\开课
File parentFile=f3.getParentFile();
System.out.println("获取绝对路径:"+parentFile.getAbsolutePath());
File f4=new File("copy");
System.out.println("绝对路径"+f4.getAbsolutePath());
}
}


File类的常用方法
package io;
import java.io.File;
import java.text.SimpleDateFormat;
import java.util.Date;
/*
File类的常用方法
*/
public class FileTest02 {
public static void main(String[] args) {
File f1=new File("D:\\第二桌面\\days2\\copy");
// 获取文件名
System.out.println("文件名:"+f1.getName());
// 判断是否是一个目录
System.out.println(f1.isDirectory());// false
// 判断是否是一个文件
System.out.println(f1.isFile());//true
// 获取文件的最后一次修改时间
long haomiao= f1.lastModified();//这个毫秒是从1970年到现在的总毫秒数
// 把总毫秒数转换为日期
Date time=new Date(haomiao);
SimpleDateFormat sdf=new SimpleDateFormat("yyyy-MM-dd HH:mm:ss SSS");
String strtime=sdf.format(time);
System.out.println(strtime);
// 获取文件大小
System.out.println(f1.length());//58字节
}
}

package io;
/*
File中的listFiles方法
*/
import java.io.File;
public class FileTest03 {
public static void main(String[] args) {
// File[] listFiles()
// 获取当前目录下所有的子文件
File f=new File("D:\\QQ音乐");
File [] files=f.listFiles();
//foreach
for (File file:files)
{
System.out.println(file.getAbsolutePath());
System.out.println(file.getName());//文件名
}
}
}

目录拷贝
package io;
/*
拷贝目录
*/
import java.io.*;
public class CopyAll {
public static void main(String[] args) {
//拷贝源
File sf=new File("D:\\java练习");
//拷贝目标
File df=new File("C:\\");
//调用方法拷贝
copyDir(sf,df);
}
/**
* 拷贝目录
* @param sf 拷贝源
* @param df 拷贝目标
*/
private static void copyDir(File sf, File df) {
if (sf.isFile())
{
//如果sf是一个文件的话,递归结束
//是文件的话需要拷贝
//...一边读一边写
FileInputStream in=null;
FileOutputStream out=null;
try {
in=new FileInputStream(sf);//读这个文件
//写到这个文件中
String path=(df.getAbsolutePath().endsWith("\\")?df.getAbsolutePath():df.getAbsolutePath()+"\\")+sf.getAbsolutePath().substring(3);
out=new FileOutputStream(path);
byte[] bytes=new byte[1024 * 1024];//一次复制1MB
int readCount=0;
while ((readCount=in.read(bytes))!=-1)
{
out.write(bytes,0,readCount);
}
out.flush();
} catch (FileNotFoundException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
} finally {
if(in!=null)
{
try {
in.close();
} catch (IOException e) {
e.printStackTrace();
}
}
if(out!=null)
{
try {
out.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
return;
}
//获取源下面的子目录
File [] files=sf.listFiles();
//测试一下看看
// System.out.println(files.length);
for (File file:files)
{
// 这个file可能是文件,也可能是目录
// 获取所有文件的(包括目录和文件)绝对路径
// System.out.println(file.getAbsolutePath());
if(file.isDirectory())
{
//新建对应的目录
String srcDir=file.getAbsolutePath();//源目录
String destDir=(df.getAbsolutePath().endsWith("\\")?df.getAbsolutePath():df.getAbsolutePath()+"\\")+srcDir.substring(3);
File newFile=new File(destDir);
if(!newFile.exists())
{
newFile.mkdirs();
}
}
//递归调用
copyDir(file,df);
}
}
}
序列化和反序列化的理解
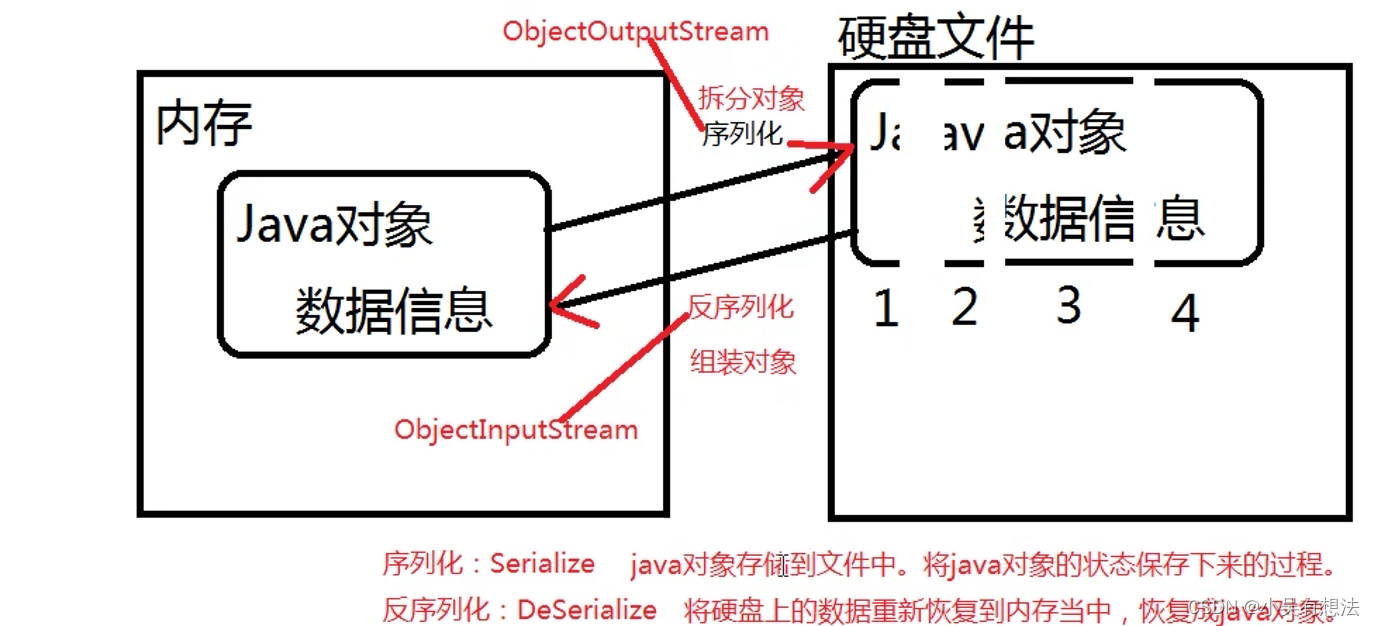
序列化的实现
package bean;
import java.io.Serializable;
public class Student implements Serializable {
//java虚拟机看到Serializable接口之后,会自动生产一个序列化版本号。
// 这里没有手动写出来,java虚拟机会默认提供这个序列化版本号
private int no;
private String name;
public Student()
{
}
public Student(int no,String name)
{
this.no=no;
this.name=name;
}
public int getNo() {
return no;
}
public void setNo(int no) {
this.no = no;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
@Override
public String toString() {
return "Student{" +
"no=" + no +
", name='" + name + '\'' +
'}';
}
}
package io;
import bean.Student;
import java.io.FileNotFoundException;
import java.io.FileOutputStream;
import java.io.ObjectOutputStream;
/*
1.java.io.NotSerializableException:
Student对象不支持序列化
2.参与序列化和反序列化的对象,必须实现Serializable接口//标志接口
public interface Serializable
{
}
这个接口当中什么代码都没有
那么它起到什么作用:标识、标志的作用,java虚拟机看到这个类实现了这个接口,可能会对这个类进行特殊待遇。
java虚拟机看到Serializable接口之后,会自动生产一个序列化版本号。
这里没有手动写出来,java虚拟机会默认提供这个序列化版本号
*/
public class ObjectOutputStreamTest01 {
public static void main(String[] args) throws Exception {
//创建java对象
Student s=new Student(1111,"zhangsan");
//序列化
ObjectOutputStream oos=new ObjectOutputStream(new FileOutputStream("students"));
//序列化对象
oos.writeObject(s);
//刷新
oos.flush();
//关闭
oos.close();
}
}
反序列化的实现
package io;
import java.io.FileInputStream;
import java.io.ObjectInputStream;
public class ObjectInputStreamTest01 {
public static void main(String[] args) throws Exception{
ObjectInputStream ois=new ObjectInputStream(new FileInputStream("students"));
//开始反序列化,读
Object obj=ois.readObject();
//反序列化回来是一个学生对象,所以会调用学生对象的toString方法
System.out.println(obj);
ois.close();
}
}

序列化多个对象
package bean;
import java.io.Serializable;
public class User implements Serializable {
private int no;
private String name;
public User()
{
}
public User(int no, String name) {
this.no = no;
this.name = name;
}
@Override
public String toString() {
return "User{" +
"no=" + no +
", name='" + name + '\'' +
'}';
}
public int getNo() {
return no;
}
public void setNo(int no) {
this.no = no;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
}
package io;
import bean.User;
import java.io.FileOutputStream;
import java.io.ObjectOutputStream;
import java.util.ArrayList;
import java.util.List;
// 一次序列化多个对象,将对象放在集合中,序列化集合
// 参与序列化的ArrayList集合以及集合中的元素User都需要实现 java.io.Serializable 接口
public class ObjectOutputStreamTest02 {
public static void main(String[] args) throws Exception{
List<User> userList=new ArrayList<>();
userList.add(new User(1,"zhangsan"));
userList.add(new User(2,"白小纯"));
userList.add(new User(3,"罗峰"));
ObjectOutputStream oos=new ObjectOutputStream(new FileOutputStream("users"));
// 序列化一个集合,这个集合对象中放了很多其他对象
oos.writeObject(userList);
oos.flush();
oos.close();
}
}
package io;
import bean.User;
import java.io.FileInputStream;
import java.io.ObjectInputStream;
import java.util.List;
public class ObjectInputStreamTest02 {
public static void main(String[] args) throws Exception {
ObjectInputStream ois=new ObjectInputStream(new FileInputStream("users"));
List<User> userList=(List<User>)ois.readObject();
for (User user:userList)
{
System.out.println(user);
}
ois.close();
}
}

注意: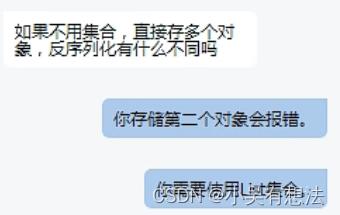
transient关键字
如果希望一个属性不参与序列化,可以使用transient关键字

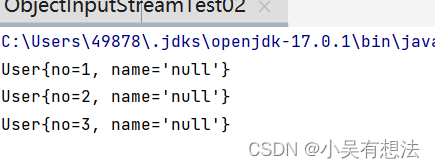
关于序列化版本号

这里在Student类里加个属性在反序列化操作,报错->序列化版本号不一致
解决办法:手动的把序列化版本号写出来
就算把有关name的删了也可以收到信息
package io;
import bean.Student;
import java.io.FileNotFoundException;
import java.io.FileOutputStream;
import java.io.ObjectOutputStream;
/*
1.java.io.NotSerializableException:
Student对象不支持序列化
2.参与序列化和反序列化的对象,必须实现Serializable接口//标志接口
public interface Serializable
{
}
这个接口当中什么代码都没有
那么它起到什么作用:标识、标志的作用,java虚拟机看到这个类实现了这个接口,可能会对这个类进行特殊待遇。
java虚拟机看到Serializable接口之后,会自动生产一个序列化版本号。
这里没有手动写出来,java虚拟机会默认提供这个序列化版本号
java语言中是采用什么机制来区分类的?
第一:首先通过类名进行对比,如果类名不一样,肯定不是同一个类
第二:如果类名一样,再怎么进行类的区别?靠序列化版本号进行区分
小明编写了一个类:java.bean.Student implements Serializable
小红编写了一个类:java.bean.Student implements Serializable
不同的人编写了同一个类,但”这两个类确实不是同一个类“,这个时候序列化版本就起作用了。
对于java虚拟机来说,java虚拟机是可以区分开这两个类的,因为这两个类都实现了Serializable接口,
都有默认的序列化版本号,他们的序列化版本号不一样,所以区分开了
这种自动生产序列化版本号的缺陷:
一旦代码确定后,不能进行后续的修改。因为修改,会重新编译,此时会生产全新的序列化版本号,这个时候java虚拟机就会认为
这是一个全新的类
最终结论:
凡是一个类实现了 Serializable接口,建议给该类提供一个固定不变的序列化版本号。
这样,以后这个类即使代码修改了,但是版本号不变,java虚拟机会认为是同一个类
*/
public class ObjectOutputStreamTest01 {
public static void main(String[] args) throws Exception {
//创建java对象
Student s=new Student(1111,"zhangsan");
//序列化
ObjectOutputStream oos=new ObjectOutputStream(new FileOutputStream("students"));
//序列化对象
oos.writeObject(s);
//刷新
oos.flush();
//关闭
oos.close();
}
}package bean;
import java.io.Serializable;
public class Student implements Serializable {
//java虚拟机看到Serializable接口之后,会自动生产一个序列化版本号。
// 这里没有手动写出来,java虚拟机会默认提供这个序列化版本号
//实际情况:过了很久之后,Student这个类源代码改动了。
//源代码改动之后,需要重新编译,编译之后生成了全新的字节码文件。
//并且class文件再次运行的时候,java虚拟机生产的序列化版本号也会发生相应的改变
//这里我们将序列化版本号手动的写出来
private static final long serialVersionUID=1L;
private int no;
private String name;
private int age;
public Student()
{
}
public Student(int no,String name)
{
this.no=no;
this.name=name;
}
public int getNo() {
return no;
}
public void setNo(int no) {
this.no = no;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
@Override
public String toString() {
return "Student{" +
"no=" + no +
", name='" + name + '\'' +
'}';
}
}
package io;
import java.io.FileInputStream;
import java.io.ObjectInputStream;
public class ObjectInputStreamTest01 {
public static void main(String[] args) throws Exception{
ObjectInputStream ois=new ObjectInputStream(new FileInputStream("students"));
//开始反序列化,读
Object obj=ois.readObject();
//反序列化回来是一个学生对象,所以会调用学生对象的toString方法
System.out.println(obj);
ois.close();
}
}

IDEA快捷键生成序列化版本号
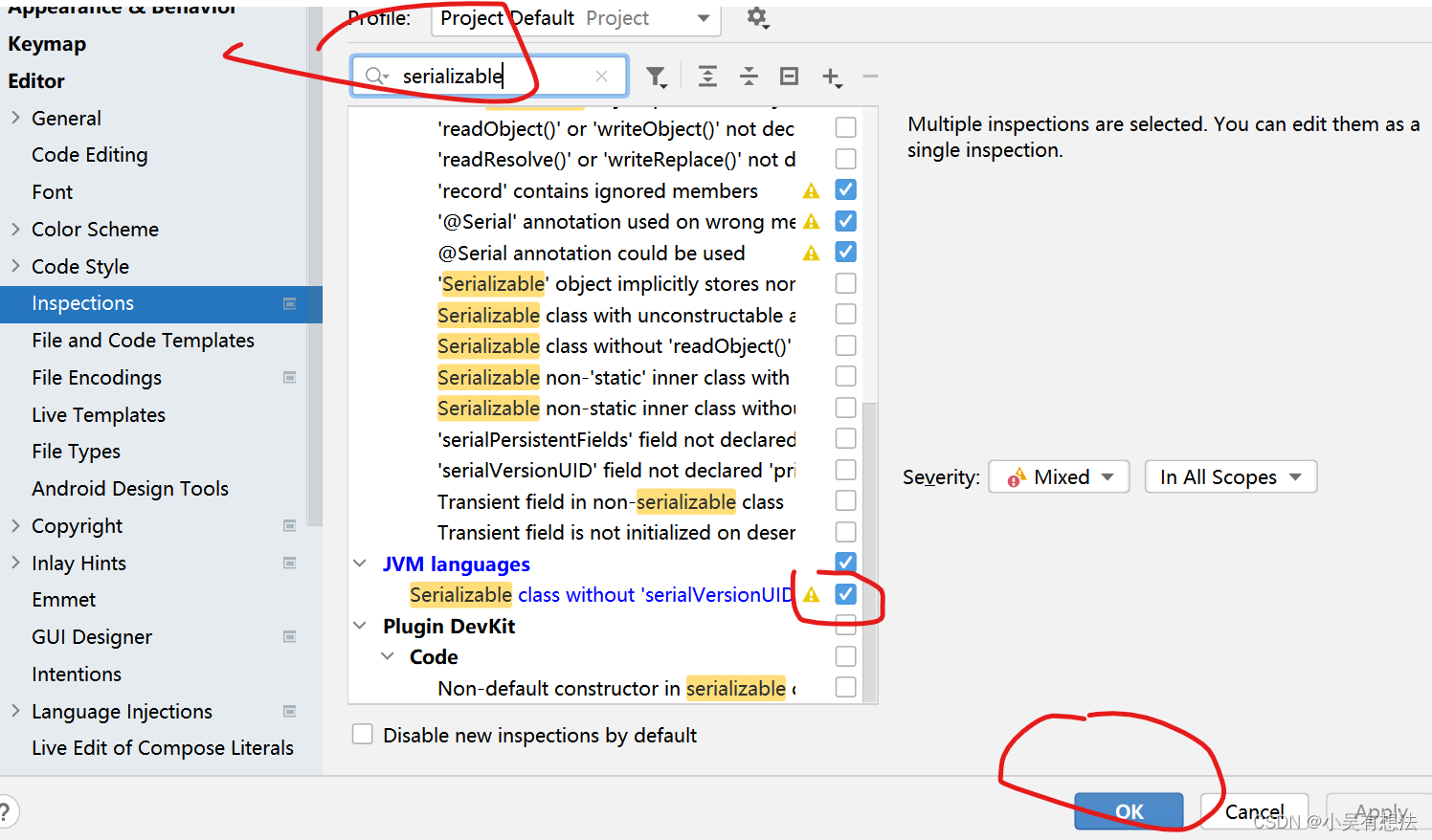 然后点Student按alt+回车
然后点Student按alt+回车


IO和Properties联合使用
IO: 文件的读和写
Properties:是一个Map集合,key和value都是String类型
package io;
import java.io.FileReader;
import java.util.Properties;
/*
IO和Properties的联合应用
非常好的一个设计理念:
以后经常改变的数据,可以单独写到一个文件中,使用程序动态读取
将来只需要修改这个文件的内容,java代码不需要改动,不需要重新编译,
服务器也不需要重启,就可以拿到动态的信息
类似于以上机制的这种文件被称为配置文件
并且当配置文件的内容格式是:
key1=value
key2=value
的时候,我们把这种配置文件叫做属性配置文件
java规范中有要求:属性配置文件建议以.properties结尾,但这不是必须的
这种结尾的文件叫做属性配置文件
其中Properties是专门存放属性配置文件内容的一个类
*/
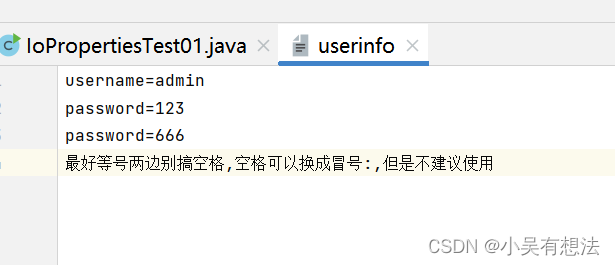
public class IoPropertiesTest01 {
public static void main(String[] args) throws Exception{
/*
Properties是一个Map集合,key和value都是String类型
想将userinfo文件中的数据加载到Properties对象当中.
*/
//新建一个输入流对象
FileReader reader=new FileReader("IO/userinfo");
//新建一个Map集合
Properties pro=new Properties();
//调用Properties对象的load方法将文件中的数据加载到Map集合中
pro.load(reader);// 文件中的数据顺着管道加载到Map集合中,其中等号=左边做key,右边做value
// 通过key来获取value
String username=pro.getProperty("username");
String password=pro.getProperty("password");
System.out.println(username);
System.out.println(password);//属性配置文件key 重复的话,value会覆盖
}
}
学习如逆水行舟,不进则退。和小吴一起冲!
![[附源码]计算机毕业设计springboot校园招聘微信小程序](https://img-blog.csdnimg.cn/270373554f964f5fbd64f3ba4e061226.png)
![[附源码]计算机毕业设计自行车租赁管理系统Springboot程序](https://img-blog.csdnimg.cn/aa9b23adc16440e499713ab513fd5abe.png)

![[附源码]JAVA毕业设计基于vue技术的汽车维修检测系统设计与实现(系统+LW)](https://img-blog.csdnimg.cn/b0c51ef028ad43b59d576b8f9096b92d.png)


![[附源码]Python计算机毕业设计Django贵港高铁站志愿者服务平台](https://img-blog.csdnimg.cn/2afb188f1a7c4f17ae6aa90df5dba9cc.png)

![[附源码]Python计算机毕业设计SSM开小灶线下管理系统(程序+LW)](https://img-blog.csdnimg.cn/c11d602b2d764ae8b86bac766f118997.png)
![[附源码]Python计算机毕业设计Django驾校预约管理系统](https://img-blog.csdnimg.cn/4f950ae72f764dbaa60c06d5c65b83a6.png)