面部表情是人类之间交流的重要方式。
在人工智能研究中,深度学习技术已成为增强人机交互的强大工具。心理学中面部表情和情绪的分析和评估涉及评估预测个人或群体情绪的决定。
本研究旨在开发一种能够使用卷积神经网络(CNN)算法和特征提取技术预测和分类面部情绪的系统。
该过程包括三个主要阶段:数据预处理、面部特征提取和面部情绪分类。通过采用卷积神经网络(CNN)算法,系统准确预测面部表情,成功率为62.66%。
该算法的性能使用FER2013数据库进行评估,该数据库是一个公开可用的数据集,包含35,887张48x48灰度面部图像,每张图像代表一种不同的情绪。
现在让我们从编码开始。
!pip install scikit-plot此代码使用 pip 安装 scikit-plot 包,pip 是一个 Python 包,提供了一系列有用的工具来可视化机器学习模型的性能。
具体来说,scikit-plot提供了多种函数来生成模型评估中使用的常见图,例如ROC曲线,精度召回率曲线,混淆矩阵等。
在Python环境中执行命令“!pip install scikit-plot”后,你应该能够在代码中导入和使用scikit-plot函数。
import pandas as pd
import numpy as np
import scikitplot
import random
import seaborn as sns
import keras
import os
from matplotlib import pyplot
import matplotlib.pyplot as plt
import tensorflow as tf
from tensorflow.keras.utils import to_categorical
import warnings
from tensorflow.keras.models import Sequential
from keras.callbacks import EarlyStopping
from keras import regularizers
from keras.callbacks import ModelCheckpoint,EarlyStopping
from tensorflow.keras.optimizers import Adam,RMSprop,SGD,Adamax
from keras.preprocessing.image import ImageDataGenerator,load_img
from keras.utils.vis_utils import plot_model
from keras.layers import Conv2D, MaxPool2D, Flatten,Dense,Dropout,BatchNormalization,MaxPooling2D,Activation,Input
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
warnings.simplefilter("ignore")
from keras.models import Model
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
from keras.regularizers import l1, l2
import plotly.express as px
from matplotlib import pyplot as plt
from sklearn.metrics import confusion_matrix
from sklearn.metrics import classification_report该代码导入机器学习和深度学习任务中常用的各种 Python 库和模块。
这些库包括pandas,numpy,scikit-plot,random,seaborn,keras,os,matplotlib,tensorflow和scikit-learn。
每个 import 语句导入一组执行机器学习或深度学习任务所需的特定工具或函数,例如数据操作、数据可视化、模型构建和性能评估。
总体而言,此代码准备了执行各种机器学习和深度学习任务(如数据预处理、模型训练和模型评估)所需的必要工具和模块。
从这里下载代码:http://onepagecode.s3-website-us-east-1.amazonaws.com/
加载数据集
data = pd.read_csv("../input/fer2013/fer2013.csv")
data.shape
此代码使用 pandas 的read_csv()函数读取名为“fer2013.csv”的 CSV 文件,该文件位于“../input/fer2013/“ 目录,并将生成的数据帧分配给名为data的变量。
然后,在数据帧上调用shape属性以检索其维度,这将返回表单的元组。这行代码将输出数据帧data中的行数和列数(rows, columns)。
data.isnull().sum()
此代码将返回数据帧data的每一列中所有缺失值的总和。
数据帧的isnull()方法返回一个布尔数据帧,该帧指示原始数据帧中的每个元素是否丢失。然后将sum()方法应用于此布尔数据帧,该帧返回每列中缺失值的总和。
这是检查数据帧中是否存在任何缺失值的快速方法。如果存在缺失值,则可能需要在将数据用于建模之前插补或删除这些值。
data.head()此代码将返回数据帧data的前 5 行。
数据帧的head()方法返回数据帧的前n行(默认情况下为n=5 )。这是快速浏览数据帧中的数据的有用方法,尤其是在处理大型数据集时。
输出将显示数据帧data的前 5 行,其中可能包括列名称和前几行数据,具体取决于数据帧的结构。

数据头的输出
数据预处理
CLASS_LABELS = ['Anger', 'Disgust', 'Fear', 'Happy', 'Neutral', 'Sadness', "Surprise"]
fig = px.bar(x = CLASS_LABELS,
y = [list(data['emotion']).count(i) for i in np.unique(data['emotion'])] ,
color = np.unique(data['emotion']) ,
color_continuous_scale="Emrld")
fig.update_xaxes(title="Emotions")
fig.update_yaxes(title = "Number of Images")
fig.update_layout(showlegend = True,
title = {
'text': 'Train Data Distribution ',
'y':0.95,
'x':0.5,
'xanchor': 'center',
'yanchor': 'top'})
fig.show()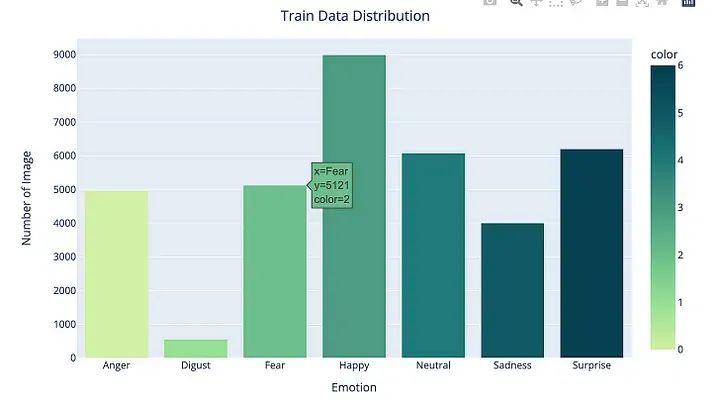
此代码使用 Plotly Express 库创建条形图,该条形图显示数据帧data中情绪的分布。
首先,在CLASS_LABELS中定义一个类标签列表,它对应于数据集中的不同情绪。
然后,调用px.bar()函数,其中 x 轴表示类标签,y 轴表示每个情绪的图像数量。颜色参数设置为不同的情感类,color_continuous_scale参数设置为“Emrld”,这是 Plotly Express 中预定义的色阶。
接下来,调用各种update_方法来修改绘图的布局和外观。例如,update_xaxes()和update_yaxes()用于分别设置 x 轴和 y 轴标题。 update_layout()用于设置打印标题及其位置。
最后,在图形对象上调用show()方法以显示绘图。
输出将显示一个条形图,该条形图显示数据帧data中每个情绪的图像数,每个情绪根据指定的色阶进行颜色编码。
随机打乱数据
data = data.sample(frac=1)DataFrame 的sample()方法用于随机采样数据帧中行的一小部分,并指定frac要返回的行部分(在本例中为 frac=1,这意味着将返回所有行)。当frac=1时,sample()方法有效地对数据帧中的行进行洗牌。
这是机器学习和深度学习任务中的常见操作,随机打乱数据以防止在数据具有任何固有顺序或结构时可能引入的任何偏差非常重要。
One Hot编码
labels = to_categorical(data[['emotion']], num_classes=7)输出是一个形状为(n_samples, n_classes)的 numpy 数组,其中:
n_samples是数据帧中的样本数n_classes是数据中唯一类的数量(在本例中为 7)数组
data的每一行表示数据帧中单个样本的One Hot编码标签。
train_pixels = data["pixels"].astype(str).str.split(" ").tolist()
train_pixels = np.uint8(train_pixels)此代码对数据DataFrame的像素列中的像素值进行预处理。
首先,astype()方法用于将pixels列转换为字符串数据类型,这允许在列的每一行上调用split()方法。
接下来,对pixels列的每一行调用split()方法,以将像素值拆分为字符串列表。然后使用tolist()将生成的列表转换为 numpy 数组。
最后,对 numpy 数组调用np.uint8(),将像素值从字符串转换为无符号 8 位整数,这是通常用于表示图像像素值的数据类型。
输出是一个形状为(n_samples, n_pixels)的 numpy 数组,其中n_samples是数据帧中的样本数,n_pixels是数据中每个图像的像素数。数组data的每一行表示数据帧中单个图像的像素值。
标准化
pixels = train_pixels.reshape((35887*2304,1))此代码将train_pixels numpy数组从形状的三维数组(n_samples,n_rows,n_columns)重新整形为形状的二维数组(n_samples*n_row,1)。
numpy数组的reshape()方法用于更改其形状。在这种情况下,train_pixels阵列通过将其重塑为具有一列的2D阵列而被展平。
得到的像素阵列的形状为(n_samples*n_rows,1),其中n_samples是DataFrame中的样本数,n_rows是每个图像的行数,1 表示DataFrame中每个图像的展平像素值。阵列的每一行表示DataFrame中单个图像的单个像素值。
scaler = StandardScaler()
pixels = scaler.fit_transform(pixels)此代码使用scikit learn的StandardScaler()函数将标准化应用于像素numpy数组。
StandardScaler()函数是一个预处理步骤,用于缩放数据的每个特征(在本例中为每个像素值),使其均值为 0,方差为 1。这是机器学习和深度学习任务中常用的技术,可确保每个特征对模型的贡献相同。
然后在像素numpy数组上调用StandardScaler()对象的fit_transform()方法,该方法计算数据的平均值和标准偏差,并相应地缩放数据。然后将得到的缩放数据分配回像素numpy数组。
输出是一个与原始pixels数组形状相同的 numpy 数组,但每个像素值都已标准化。
重塑数据 (48,48)
pixels = train_pixels.reshape((35887, 48, 48,1))此代码将train_pixels numpy数组从2维形状数组(n_samples*n_rows,1)重新整形为4维形状阵列(n_samples,n_rows、n_columns、n_channels)。
numpy数组的reshape()方法用于更改其形状。在这种情况下,train_pixels阵列被重塑为具有1个通道的4D阵列。
得到的像素阵列的形状为(n_samples,n_rows,n_columns,n_channels),其中n_samples是DataFrame中的样本数量,n_row是每个图像的行数,n_column是每个图像中的列数,n_channel表示每个图像中颜色通道的数量。
由于原始数据集是灰度级的,因此n_channels设置为1。像素阵列的每个元素表示DataFrame中单个灰度图像的像素值。
训练测试验证拆分
现在,我们有 35887 张图像,每张图像包含 48x48 像素。我们将数据拆分为训练、测试和验证数据,以 10% 的比例提供、评估和验证我们的数据。
X_train, X_test, y_train, y_test = train_test_split(pixels, labels, test_size=0.1, shuffle=False)
X_train, X_val, y_train, y_val = train_test_split(X_train, y_train, test_size=0.1, shuffle=False)该代码使用scikit-learn的train_test_split()函数将经过预处理的图像数据像素和一个热编码的标签标签拆分为训练集、验证集和测试集。
函数train_test_split()根据test_size参数将数据随机拆分为训练和测试子集,test_size指定应用于测试的数据部分。在这种情况下,test_size=0.1,这意味着10%的数据将用于测试。
shuffle参数设置为False以保留DataFrame中样本的原始顺序。
生成的X_train、X_val和X_test数组分别包含训练集、验证集和测试集的像素值。y_train、y_val和y_test数组包含对应集合的one hot编码标签。
再次使用train_test_split()将训练集进一步拆分为训练集和验证集,test_size=0.1。这将数据分成80%用于训练,10%用于验证,10%用于测试。
print(X_train.shape)
print(X_test.shape)
print(X_val.shape)
在将数据拆分为训练集、验证集和测试集之后,这些代码行打印X_train、X_test和X_val数组的形状。
numpy数组的shape属性返回数组维度的元组。在这种情况下,X_train、X_test和X_val数组的形状将取决于每个集合中的样本数量和每个样本的维度。
输出将以格式(n_samples、n_rows、n_columns、n_channel)显示阵列的形状,其中n_samples是集合中的样本数,n_rows是每个图像的行数,n_columns是每个图像中的列数,n_channel表示每个图像中颜色通道的数量。
在这个绘图代码的帮助下,我们可以看到一些包含每个类的一个样本的训练数据。
plt.figure(figsize=(15,23))
label_dict = {0 : 'Angry', 1 : 'Disgust', 2 : 'Fear', 3 : 'Happiness', 4 : 'Sad', 5 : 'Surprise', 6 : 'Neutral'}
i = 1
for i in range (7):
img = np.squeeze(X_train[i])
plt.subplot(1,7,i+1)
plt.imshow(img)
index = np.argmax(y_train[i])
plt.title(label_dict[index])
plt.axis('off')
i += 1
plt.show()
此代码使用 matplotlib 的plt.subplots()函数从训练集中创建图像的 7x1 子图网格。
numpy数组的scruze()方法用于从数组的形状中删除任何一维条目,有效地将4D数组转换为3D数组。
对于每个子图,imshow()函数用于显示相应的图像,title()函数用来显示相应的标签。
axis()函数用于关闭每个子图的轴。
输出是训练集中的前 7 个图像的可视化,以及它们对应的标签。
使用图像数据生成器进行数据增强
我们可以进行数据增强,以获得更多数据来训练和验证我们的模型,以防止过度拟合。数据增强可以在训练集和验证集上完成,因为它有助于模型变得更加通用和健壮。
datagen = ImageDataGenerator( width_shift_range = 0.1,
height_shift_range = 0.1,
horizontal_flip = True,
zoom_range = 0.2)
valgen = ImageDataGenerator( width_shift_range = 0.1,
height_shift_range = 0.1,
horizontal_flip = True,
zoom_range = 0.2)此代码创建两个ImageDataGenerator对象,datagen和valgen,它们将用于训练和验证期间的数据扩充。
ImageDataGenerator类是一个Keras预处理实用程序,可以实时执行各种类型的图像增强,如移位、翻转、旋转和缩放。
datagen对象包括许多增强技术:
width_shift_range和height_shift_range分别将图像在水平和垂直方向上随机移动图像宽度和高度的最大10%。
horizontal_flip随机水平翻转图像。
zoom_range将图像随机缩放高达20%的倍数。
valgen对象包含与datagen相同的扩充技术,但仅在训练期间应用于验证集。
通过在训练过程中应用数据扩充,模型将暴露于更大、更多样的训练数据集,这有助于防止过度拟合,并提高模型泛化到新数据的能力。
datagen.fit(X_train)
valgen.fit(X_val)这几行代码分别将ImageDataGenerator对象datagen和valgen与训练数据和验证数据相匹配。
ImageDataGenerator对象的fit()方法计算执行数据扩充所需的任何内部统计信息,例如像素值的平均值和方差。在这种情况下,在datagen和valgen上调用fit()方法,并将训练集和验证集作为输入来计算这些统计数据。
将ImageDataGenerator对象拟合到数据后,可以使用它们在训练和验证期间实时应用数据增强。
train_generator = datagen.flow(X_train, y_train, batch_size=64)
val_generator = datagen.flow(X_val, y_val, batch_size=64)这些代码行创建了两个ImageDataGenerator迭代器,train_generator和val_generator,可用于在训练和验证期间生成一批增强数据。
ImageDataGenerator对象的flow()方法接收输入数据和标签的numpy数组,并动态生成一批增强数据。
在这种情况下,使用datagen上的flow()方法创建train_generator,输入训练数据X_train和y_train,批量大小为64。val_generator在valgen上使用相同的方法创建,输入验证数据X_val和y_val,批量大小为64。
在训练期间,train_generator(迭代器)将用于为每个训练时期动态生成一批增强数据。类似地,val_generator迭代器将用于为每个验证epoch生成一批增强数据。
代码下载
http://onepagecode.s3-website-us-east-1.amazonaws.com/
设计模型
卷积神经网络(CNN)模型
CNN模型有许多层,具有不同的单元,例如卷积层,最大池化层,批量归一化和退出层,以规范模型。
def cnn_model():
model= tf.keras.models.Sequential()
model.add(Conv2D(32, kernel_size=(3, 3), padding='same', activation='relu', input_shape=(48, 48,1)))
model.add(Conv2D(64,(3,3), padding='same', activation='relu' ))
model.add(BatchNormalization())
model.add(MaxPool2D(pool_size=(2, 2)))
model.add(Dropout(0.25))
model.add(Conv2D(128,(5,5), padding='same', activation='relu'))
model.add(BatchNormalization())
model.add(MaxPool2D(pool_size=(2, 2)))
model.add(Dropout(0.25))
model.add(Conv2D(512,(3,3), padding='same', activation='relu', kernel_regularizer=regularizers.l2(0.01)))
model.add(BatchNormalization())
model.add(MaxPool2D(pool_size=(2, 2)))
model.add(Dropout(0.25))
model.add(Conv2D(512,(3,3), padding='same', activation='relu', kernel_regularizer=regularizers.l2(0.01)))
model.add(BatchNormalization())
model.add(MaxPool2D(pool_size=(2, 2)))
model.add(Dropout(0.25))
model.add(Conv2D(512,(3,3), padding='same', activation='relu', kernel_regularizer=regularizers.l2(0.01)))
model.add(BatchNormalization())
model.add(MaxPool2D(pool_size=(2, 2)))
model.add(Dropout(0.25))
model.add(Flatten())
model.add(Dense(256,activation = 'relu'))
model.add(BatchNormalization())
model.add(Dropout(0.25))
model.add(Dense(512,activation = 'relu'))
model.add(BatchNormalization())
model.add(Dropout(0.25))
model.add(Dense(7, activation='softmax'))
model.compile(
optimizer = Adam(lr=0.0001),
loss='categorical_crossentropy',
metrics=['accuracy'])
return model该代码使用Keras Sequential API定义了卷积神经网络(CNN)模型。
CNN体系结构由几个具有批量归一化、最大池化和丢弃正则化的卷积层组成,然后是几个具有批量规范化和丢弃的全连接(密集)层。最后一层使用softmax激活函数来输出7个可能的情绪类别上的概率分布。
Conv2D层创建了一个卷积核,该卷积核与层输入进行卷积,以产生输出张量。
BatchNormalization层应用一个变换,将平均激活保持在接近0的水平,将激活标准偏差保持在接近1的水平。
MaxPooling2D层沿着空间维度对输入进行下采样。
Dropout层在训练过程中随机丢弃一些单元,以防止过度拟合。
Dense层展平输入,然后将其输入到完全连接的层中。
模型的compile()方法指定了要在训练过程中使用的优化器、损失函数和评估度量。在这种情况下,优化器是Adam,学习率为0.0001,损失函数是分类交叉熵,评估指标是准确性。
该函数返回已编译的模型对象。
model = cnn_model()这行代码通过调用前面定义的CNN_model()函数来创建CNN模型的一个新实例。
模型对象表示可以在数据上训练的神经网络模型,以预测面部图像的情绪标签。
然后,我们使用Adam优化器以0.0001的学习率编译我们的模型,并选择度量作为准确性,然后选择损失作为分类交叉熵
model.compile(
optimizer = Adam(lr=0.0001),
loss='categorical_crossentropy',
metrics=['accuracy'])这行代码通过指定要在训练期间使用的优化器、损失函数和评估指标来编译 CNN 模型。
Keras 模型的compile()方法用于在训练前配置学习过程。在这种情况下,优化器是学习率为0.0001的Adam,损失函数是分类交叉熵,评估指标是准确性。
优化器负责在训练过程中更新模型参数,Adam 是一种流行的优化算法,它根据损失函数的梯度调整学习率。
损失函数用于计算预测标签和实际标签之间的差异,分类交叉熵是多类分类问题的标准损失函数。准确性指标用于在训练和验证期间评估模型的性能。
model.summary()Model: "sequential_1"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
conv2d_6 (Conv2D) (None, 48, 48, 32) 320
_________________________________________________________________
conv2d_7 (Conv2D) (None, 48, 48, 64) 18496
_________________________________________________________________
batch_normalization_7 (Batch (None, 48, 48, 64) 256
_________________________________________________________________
max_pooling2d_5 (MaxPooling2 (None, 24, 24, 64) 0
_________________________________________________________________
dropout_7 (Dropout) (None, 24, 24, 64) 0
_________________________________________________________________
conv2d_8 (Conv2D) (None, 24, 24, 128) 204928
_________________________________________________________________
batch_normalization_8 (Batch (None, 24, 24, 128) 512
_________________________________________________________________
max_pooling2d_6 (MaxPooling2 (None, 12, 12, 128) 0
_________________________________________________________________
dropout_8 (Dropout) (None, 12, 12, 128) 0
_________________________________________________________________
conv2d_9 (Conv2D) (None, 12, 12, 512) 590336
_________________________________________________________________
batch_normalization_9 (Batch (None, 12, 12, 512) 2048
_________________________________________________________________
max_pooling2d_7 (MaxPooling2 (None, 6, 6, 512) 0
_________________________________________________________________
dropout_9 (Dropout) (None, 6, 6, 512) 0
_________________________________________________________________
conv2d_10 (Conv2D) (None, 6, 6, 512) 2359808
_________________________________________________________________
batch_normalization_10 (Batc (None, 6, 6, 512) 2048
_________________________________________________________________
max_pooling2d_8 (MaxPooling2 (None, 3, 3, 512) 0
_________________________________________________________________
dropout_10 (Dropout) (None, 3, 3, 512) 0
_________________________________________________________________
conv2d_11 (Conv2D) (None, 3, 3, 512) 2359808
_________________________________________________________________
batch_normalization_11 (Batc (None, 3, 3, 512) 2048
_________________________________________________________________
max_pooling2d_9 (MaxPooling2 (None, 1, 1, 512) 0
_________________________________________________________________
dropout_11 (Dropout) (None, 1, 1, 512) 0
_________________________________________________________________
flatten_1 (Flatten) (None, 512) 0
_________________________________________________________________
dense_3 (Dense) (None, 256) 131328
_________________________________________________________________
batch_normalization_12 (Batc (None, 256) 1024
_________________________________________________________________
dropout_12 (Dropout) (None, 256) 0
_________________________________________________________________
dense_4 (Dense) (None, 512) 131584
_________________________________________________________________
batch_normalization_13 (Batc (None, 512) 2048
_________________________________________________________________
dropout_13 (Dropout) (None, 512) 0
_________________________________________________________________
dense_5 (Dense) (None, 7) 3591
=================================================================
Total params: 5,810,183
Trainable params: 5,805,191
Non-trainable params: 4,992
_________________________________________________________________这行代码打印了 CNN 模型体系结构的摘要。
Keras 模型的summary()方法打印模型架构的摘要,包括每层中的参数、每层的输出形状以及模型中的参数总数。
摘要包括有关模型中每个层的信息,包括层类型、输出形状、参数数和激活函数(如果适用)。摘要还包括有关模型中可训练参数总数的信息,这对于了解模型复杂性和过度拟合的可能性非常有用。
提前停止
添加检查指针以实现提前停止以防止过度拟合。
checkpointer = [EarlyStopping(monitor = 'val_accuracy', verbose = 1,
restore_best_weights=True,mode="max",patience = 5),
ModelCheckpoint('best_model.h5',monitor="val_accuracy",verbose=1,
save_best_only=True,mode="max")]此代码定义将在 CNN 模型训练期间使用的 Keras 回调列表。
回调是可以在训练过程中的各个阶段应用的函数,例如在每个epoch结束时或验证精度达到特定阈值时。它们可用于执行操作,例如保存最佳模型权重、提前停止以防止过度拟合或在模型未改进时降低学习率。
在这种情况下,checkpointer列表包含两个回调:
EarlyStopping:此回调监控验证精度,如果精度在一定数量的 epoch(由patience参数指定)后没有提高,则停止训练过程。restore_best_weights参数设置为 True 以在停止训练后恢复最佳模型的权重。ModelCheckpoint:此回调将训练期间最佳模型的权重保存到名为best_model.h5的文件中。save_best_only参数设置为 True 以仅保存导致最高验证精度的权重。
history = model.fit(train_generator,
epochs=30,
batch_size=64,
verbose=1,
callbacks=[checkpointer],
validation_data=val_generator)此代码使用 fit() 方法在训练数据上训练 CNN 模型。
Keras 模型的fit()方法在指定数量的 epoch 的输入数据上训练模型。在这种情况下,模型一次使用 30 个图像的批次训练 64 个 epoch。
train_generator和val_generator对象分别用于生成用于训练和验证的一批增强图像。回调参数设置为前面定义的检查指针列表,该列表指定在训练期间要使用的早期停止和模型检查点回调。
fit()该方法返回的history对象包含有关训练过程的信息,包括每个时期的训练和验证损失和准确性。此信息可用于可视化模型随时间推移的性能,并做出有关进一步训练或模型调整的决策。
可视化结果
plt.plot(history.history["loss"],'r', label="Training Loss")
plt.plot(history.history["val_loss"],'b', label="Validation Loss")
plt.legend()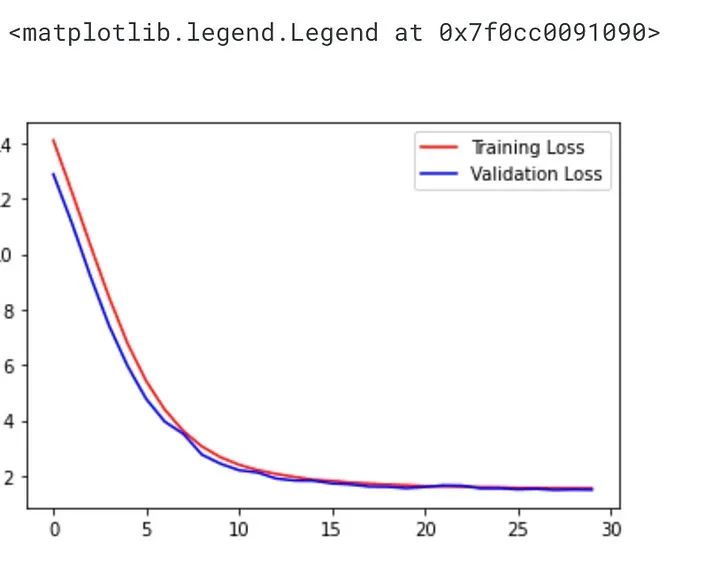
此代码绘制 CNN 模型在训练过程中的训练和验证损失。
fit()方法返回的history对象包含有关训练过程的信息,包括每个时期的训练和验证损失和准确性。此信息可用于可视化模型随时间推移的性能。
plt.plot()函数用于绘制红色的训练损失和蓝色的验证损失,标签参数指定每行的图例标签。调用legend()函数是为了在绘图上显示图例。
这段代码允许我们查看模型的学习情况,以及它是否过度拟合到训练数据。如果验证损失开始增加,而训练损失继续减少,则表明过度拟合,这意味着模型正在记忆训练数据,而不是很好地泛化到新数据。
plt.plot(history.history["accuracy"],'r',label="Training Accuracy")
plt.plot(history.history["val_accuracy"],'b',label="Validation Accuracy")
plt.legend()
此代码绘制 CNN 模型在训练过程中的训练和验证准确性。
fit()方法返回的history对象包含有关训练过程的信息,包括每个时期的训练和验证损失和准确性。此信息可用于可视化模型随时间推移的性能。
plt.plot()函数用于绘制红色的训练精度和蓝色的验证精度,标签参数指定每行的图例标签。调用legend()函数是为了在绘图上显示图例。
这段代码允许我们查看模型的学习情况,以及它是否过度拟合到训练数据。如果验证精度开始下降,而训练精度继续增加,则表明过度拟合,这意味着模型正在记忆训练数据,而不是很好地推广到新数据。
loss = model.evaluate(X_test,y_test)
print("Test Acc: " + str(loss[1]))此代码评估测试集上经过训练的 CNN 模型的性能。
Keras 模型的evaluate()方法计算给定测试集上的损失和指标(在模型编译期间指定)。
X_test和y_test数组分别包含测试图像及其相应的标签。model.evaluate()方法用于计算模型在测试集上的损失和准确性。evaluate()方法将损失值和精度值作为数组返回。
测试精度是使用model.eevaluate()返回的loss对象打印的。测试精度让我们了解了模型在新的、看不见的数据上的表现。

preds = model.predict(X_test)
y_pred = np.argmax(preds , axis = 1 )此代码使用经过训练的 CNN 模型生成测试集的预测。
Keras 模型的predict()方法为给定的输入数据集X_test生成预测。在这种情况下,数组包含我们要对其进行预测的测试图像。
preds数组包含每个测试图像的每个类的预测概率,数组的每一行对应于一个测试图像,每列对应于一个类。
np.argmax()函数用于提取每个测试图像具有最高预测概率的类的索引。这为我们提供了测试集的预测类标签。
可以将预测的类标签与真实的类标签y_test进行比较,以评估模型在测试集上的性能。
label_dict = {0 : 'Angry', 1 : 'Disgust', 2 : 'Fear', 3 : 'Happiness', 4 : 'Sad', 5 : 'Surprise', 6 : 'Neutral'}
figure = plt.figure(figsize=(20, 8))
for i, index in enumerate(np.random.choice(X_test.shape[0], size=24, replace=False)):
ax = figure.add_subplot(4, 6, i + 1, xticks=[], yticks=[])
ax.imshow(np.squeeze(X_test[index]))
predict_index = label_dict[(y_pred[index])]
true_index = label_dict[np.argmax(y_test,axis=1)[index]]
ax.set_title("{} ({})".format((predict_index),
(true_index)),
color=("green" if predict_index == true_index else "red"))
此代码生成测试图像的随机子集及其真实和预测标签的可视化。
label_dict字典将整数类标签映射到它们对应的字符串标签。
然后,该代码生成一个包含24个子图(4行6列)的图形,每个子图显示一个随机测试图像及其预测和真实标签。函数的作用是从X_test数组中随机选择24个索引。
对于每个子图,使用imshow()显示测试图像,并使用set_title()在子图的标题中显示预测标签和真实标签。如果预测标签与真实标签匹配,则以绿色突出显示,否则以红色突出显示。
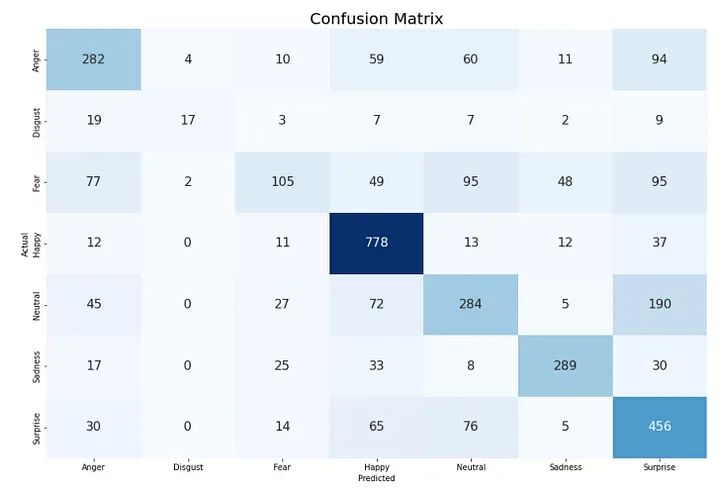
CLASS_LABELS = ['Anger', 'Disgust', 'Fear', 'Happy', 'Neutral', 'Sadness', "Surprise"]
cm_data = confusion_matrix(np.argmax(y_test, axis = 1 ), y_pred)
cm = pd.DataFrame(cm_data, columns=CLASS_LABELS, index = CLASS_LABELS)
cm.index.name = 'Actual'
cm.columns.name = 'Predicted'
plt.figure(figsize = (15,10))
plt.title('Confusion Matrix', fontsize = 20)
sns.set(font_scale=1.2)
ax = sns.heatmap(cm, cbar=False, cmap="Blues", annot=True, annot_kws={"size": 16}, fmt='g')此代码生成测试集上模型预测的混淆矩阵的热图。
CLASS_LABELS列表包含七个情感类的名称。
scikit learn的metrics模块中的confusion_matrix()函数用于计算模型在测试集上的预测的混淆矩阵。函数np.argmax()用于将one hot编码的真实标签和预测标签转换为整数标签。
生成的混淆矩阵存储在pandas DataFrame cm中,类名作为行和列标签。然后使用seaborn的heatmap()函数将DataFrame显示为热图。热图使用混淆矩阵的值进行注释,并使用sns.set(font_scale=1.2)增加字体大小。
from sklearn.metrics import classification_report
print(classification_report(np.argmax(y_test, axis = 1 ),y_pred,digits=3))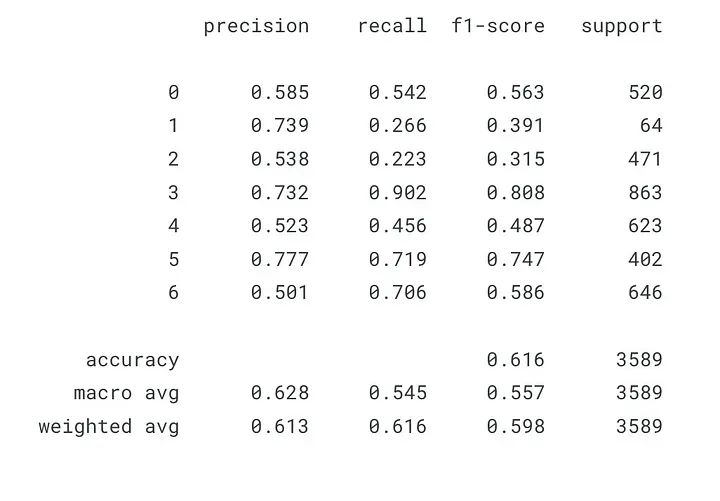
classification_report()的输出含义如下:
Precision:预测的阳性病例与实际阳性病例的比例。在数学上,它是TP /(TP + FP),其中TP是真阳性的数量,FP是误报的数量。高精度分数表示模型在预测正类时是准确的。
Recall:模型正确预测为阳性的实际阳性事例的比例。在数学上,它是TP / (TP + FN),其中FN是假阴性的数量。较高的召回率分数表示模型能够正确识别阳性病例。
F1 分数:精度和召回率的调和平均值。它同时考虑了精度和召回率,并提供平衡两者的单一分数。在数学上,它是 2 * (precision * recall) / (precision + recall).
Support:类在测试数据中实际出现的次数。
下面是分类报告中不同行的说明:
Precision:第一行显示每个类的精度分数。
Recall:第二行显示每个班级的召回分数。
F1 分数:第三行显示每个类的 F1 分数。
Support:最后一行显示测试数据中每个类的出现次数。
请注意,宏观平均值和加权平均值也位于报告底部。
微调模型
model = cnn_model()
model.compile(optimizer=tf.keras.optimizers.SGD(0.001),
loss='categorical_crossentropy',
metrics = ['accuracy'])该模型的优化器已从Adam更改为SGD,学习率为0.001。损失函数保持不变,即类别交叉熵。精度度量也是相同的。
history = model.fit(train_generator,
epochs=30,
batch_size=64,
verbose=1,
callbacks=[checkpointer],
validation_data=val_generator)使用train_generator和val_generator分别作为训练和验证数据,再次对模型进行 30 个时期的训练,批量大小为64。
检查指针回调还用于保存基于验证准确性的最佳模型。
loss = model.evaluate(X_test,y_test)
print("Test Acc: " + str(loss[1]))
打印使用SGD优化器微调模型后的测试精度,学习率为0.001。
plt.plot(history.history["loss"],'r', label="Training Loss")
plt.plot(history.history["val_loss"],'b', label="Validation Loss")
plt.legend()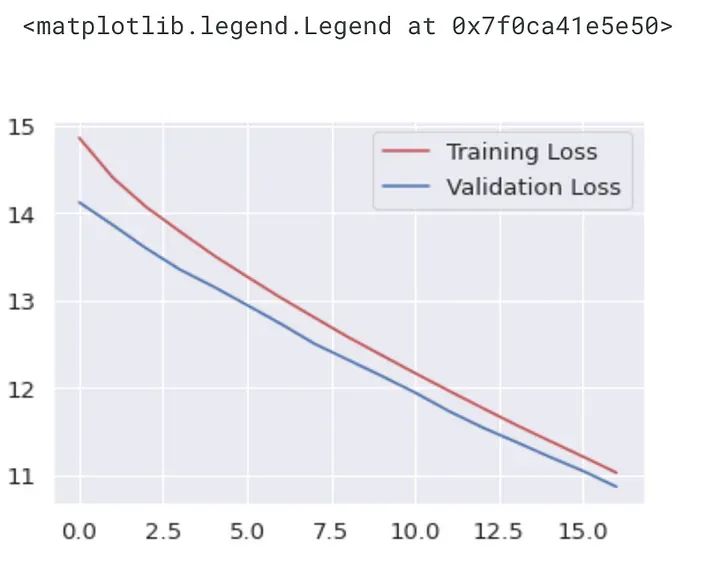
该图显示了模型训练期间各个时期的训练损失(红色)和验证损失(蓝色)。x 轴表示周期数,y 轴表示损失。它有助于确定模型是过度拟合还是拟合不足。
如果训练损失在减少,但验证损失在增加或不减少,则意味着模型过度拟合。如果训练和验证损失都很高,则意味着模型拟合不足。
从图中看,训练和验证损失似乎在减少,这意味着模型正在从数据中学习。
更改epoch编号
model.compile(
optimizer = Adam(lr=0.0001),
loss='categorical_crossentropy',
metrics=['accuracy'])
checkpointer = [EarlyStopping(monitor = 'val_accuracy', verbose = 1,
restore_best_weights=True,mode="max",patience = 10),
ModelCheckpoint('best_model.h5',monitor="val_accuracy",verbose=1,
save_best_only=True,mode="max")]
history = model.fit(train_generator,
epochs=50,
batch_size=64,
verbose=1,
callbacks=[checkpointer],
validation_data=val_generator)更新后的代码再次训练模型 50 个epoch,并提前停止回调,耐心等待 10 个epoch。最佳模型将保存为“best_model.h5”,具有最大的验证精度。
该模型将使用 Adam 优化器进行编译,学习率为 0.0001,分类交叉熵损失和准确性作为指标。训练生成器和验证生成器是之前使用数据增强技术定义的。
loss = model.evaluate(X_test,y_test)
print("Test Acc: " + str(loss[1]))
CLASS_LABELS = ['Anger', 'Disgust', 'Fear', 'Happy', 'Neutral', 'Sadness', "Surprise"]
cm_data = confusion_matrix(np.argmax(y_test, axis = 1 ), y_pred)
cm = pd.DataFrame(cm_data, columns=CLASS_LABELS, index = CLASS_LABELS)
cm.index.name = 'Actual'
cm.columns.name = 'Predicted'
plt.figure(figsize = (20,10))
plt.title('Confusion Matrix', fontsize = 20)
sns.set(font_scale=1.2)
ax = sns.heatmap(cm, cbar=False, cmap="Blues", annot=True, annot_kws={"size": 16}, fmt='g')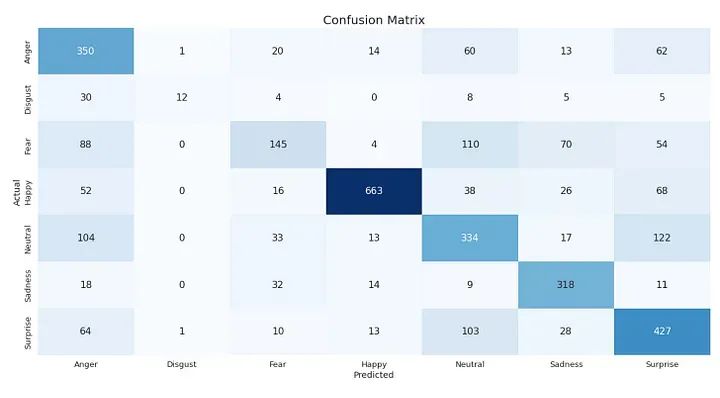
☆ END ☆
如果看到这里,说明你喜欢这篇文章,请转发、点赞。微信搜索「uncle_pn」,欢迎添加小编微信「 woshicver」,每日朋友圈更新一篇高质量博文。
↓扫描二维码添加小编↓