文章目录
- python文档查阅tips
- range
- numpy arange
- numpy arange@python range🎈
- collections@容器的抽象基类
- eg
- sequence🎈@python序列类型
- slice@切片
- slice()内置方法
- itertools.slice()方法
- python@切片slice@sequence@range@arange
python文档查阅tips
preface:想通过搜索引擎搜python官方接口文档,往往是一些个人博客排在前面
- jetbrains IDE
- IDEA/pyCharm都可以通过编写相关语句,查阅文档(跳转到python文档)
- 可以通过配置quick document快捷键快速查询
- IDEA/pyCharm都可以通过编写相关语句,查阅文档(跳转到python文档)
- vscode +python extension:
- 类似的,鼠标悬停于指定接口/函数上
- 一般来说jetbrains的idea可以查到更多的接口
- 搜索引擎限定网站
in site:docs.python.org <你的关键词>in site:docs.python.org是为了再python官方文档内寻找- 例如搜索range()方法的文档:
in site:docs.python.org range method
- chatgpt AI引擎
range
- Built-in Types — Python documentation
numpy arange
-
numpy.arange — NumPy Manual
-
NumPy库中的arange函数是"array range"的缩写。它用于创建一维数组,并按照给定的范围和步长填充数组元素。
这个函数的完整形式为:
其中,参数含义如下:
- start:可选,表示数组的起始值,默认为0。
- stop:必须,表示数组的终止值(不包括该值)。
- step:可选,表示数组元素之间的步长,默认为1。
- dtype:可选,表示数组的数据类型,如果未指定,则根据其他参数自动推断。
举个例子,如果我们要生成一个从0到9(不包括9)的一维数组,可以这样调用arange函数:
import numpy as np a = np.arange(0, 9, 1)执行完毕后,a将得到一个长度为9的一维数组,其中每个元素都是从0开始,每次递增1,直到小于9为止的数字。
numpy arange@python range🎈
-
Python内置函数range()和NumPy中的arange()函数都具有各自的优点,我们可以根据具体需求选择使用。
Python内置函数range()的优点:
- 语法简单易懂,无需导入任何库即可使用。
- 可以生成一个序列对象,节省存储空间。
- 可以处理大规模数字范围,因为它不会一次性将所有数字生成出来,而是按需生成。
NumPy中的arange()函数的优点:
- 可以处理浮点数类型的范围和步长。
- 生成的是NumPy数组,可以直接进行矩阵运算等操作。
- 可以通过指定数据类型来控制生成的数组类型,具有更好的灵活性。
举个例子来说,如果我们只需要生成一个简单的整数序列,并且对内存要求比较高,那么可以使用Python内置函数range();如果需要生成一维浮点数数组,并且需要进行矩阵运算等操作,那么可以使用NumPy中的arange()函数。
collections@容器的抽象基类
-
collections.abc — 容器的抽象基类 — Python 文档
-
collections-abstract-base-classes
-
序列类型 — list, tuple, range|内置类型 — Python 文档
-
参考
<<Fluent Python>>中的额外的介绍 -
-
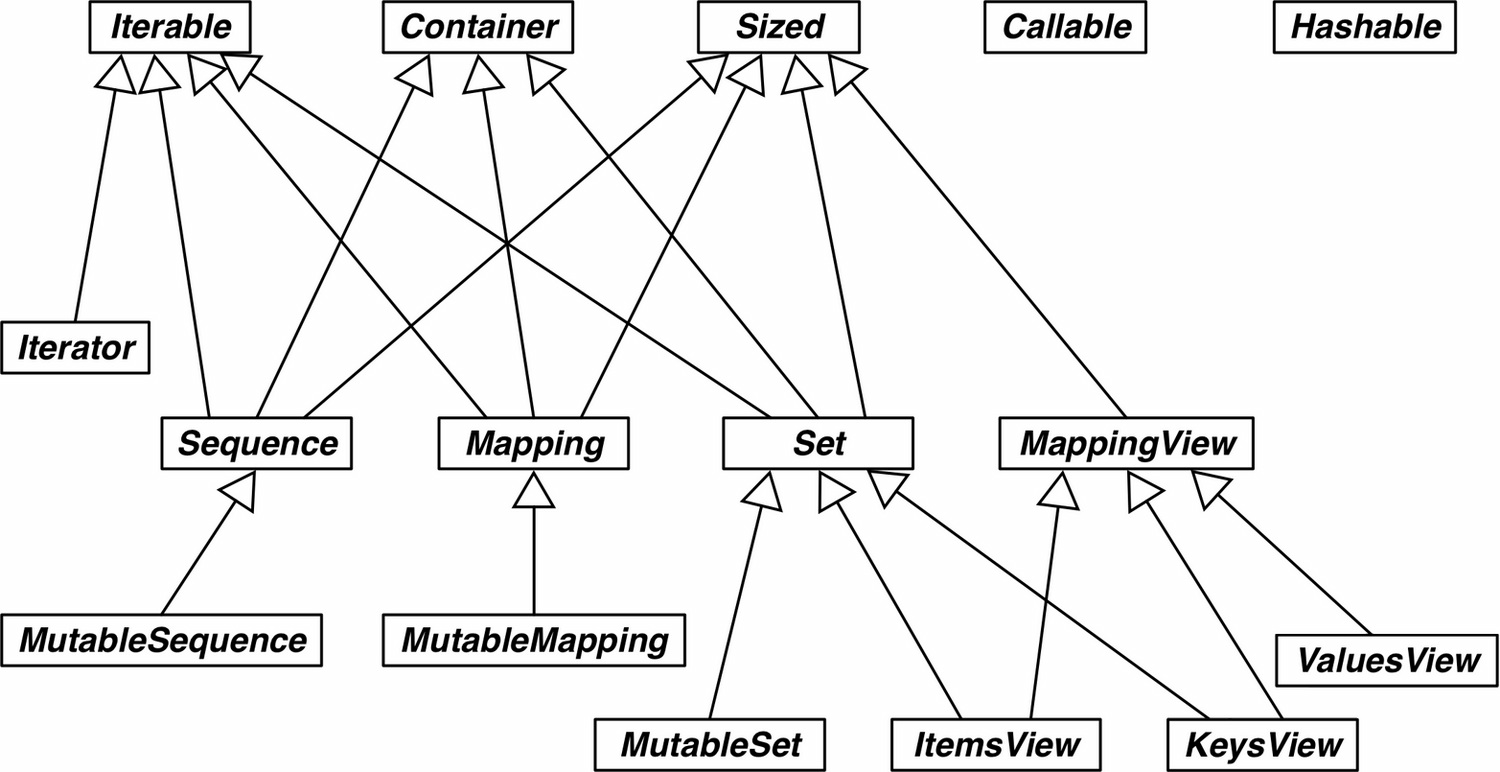
collections.abc模块是 Python 中的一个抽象基类模块,提供了一些抽象基类,用于定义集合类型的接口和行为。开发者可以通过继承这些抽象基类,来实现自己的集合类型,并且可以保证其具有一定的规范和兼容性。 -
下面是
collections.abc模块中一些重要的抽象基类及其作用:-
Container抽象基类Container是一个抽象基类,用于定义包含元素的集合类型应该具有的行为。如果一个对象是Container的子类,那么它应该实现__contains__方法,以支持in操作符的使用。
-
Sized抽象基类Sized是一个抽象基类,用于定义包含元素的集合类型应该具有的行为。如果一个对象是Sized的子类,那么它应该实现__len__方法,以支持len()函数的使用。
-
Iterable抽象基类Iterable是一个抽象基类,用于定义可迭代对象应该具有的行为。如果一个对象是Iterable的子类,那么它应该实现__iter__方法,以支持迭代操作。
-
Sequence抽象基类Sequence是一个抽象基类,用于定义序列类型应该具有的行为。如果一个对象是Sequence的子类,那么它应该实现__getitem__和__len__方法,以支持索引和切片操作。此外,Sequence还提供了一些其他的方法,例如index()、count()等,用于在序列中查找元素和计算元素出现的次数。
-
Mapping抽象基类Mapping是一个抽象基类,用于定义映射类型应该具有的行为。如果一个对象是Mapping的子类,那么它应该实现__getitem__、__len__和keys()方法,以支持键值对的访问和遍历。此外,Mapping还提供了一些其他的方法,例如values()、items()等,用于获取映射中的值和键值对。
-
Set抽象基类Set是一个抽象基类,用于定义集合类型应该具有的行为。如果一个对象是Set的子类,那么它应该实现__contains__、__len__、__iter__和add()方法,以支持集合中元素的访问、迭代和添加等操作。此外,Set还提供了一些其他的方法,例如remove()、discard()、pop()等,用于删除集合中的元素。
总体而言,
collections.abc模块提供了一些抽象基类,用于定义集合类型的接口和行为,可以帮助开发者实现自己的集合类型,并保证其具有一定的规范和兼容性。建议开发者在实际应用中合理使用collections.abc模块,并根据需要选择合适的抽象基类。 -
eg
-
Sequence = collections.abc.Sequence # type:ignore def get_features_tag(f_config): """Returns label corresponding to which features are to be extracted 返回形如('mfcc-chroma-contrast')的特征标签链 params - f_config:list[str]|dict[str,bool]|str 包含情感特征组合的可迭代对象 Examples - eg1 >>> f_config1 = {'mfcc': True, 'chroma': True, 'contrast': False, 'tonnetz': False, 'mel': False} >>> get_label(f_config1) >>> 'mfcc-chroma' >>> f_config2={'mfcc': True, 'chroma': True, 'contrast': True, 'tonnetz': False, 'mel': False} >>> utils.get_label(f_config2) >>> 'mfcc-chroma-contrast' eg2 >>> MCM=['chroma', 'mel', 'mfcc'] >>> get_features_tag(MCM) >>> 'chroma-mel-mfcc' """ res = "" type_error=TypeError("Invalid type of f_config!") if isinstance(f_config, dict): used_features=[] for f in ava_features: if f_config.get(f): used_features.append(f) # used_features.sort() f_config=used_features elif isinstance(f_config, str): f_config = [f_config] # elif isinstance(f_config, Sequence): # pass # else: # raise type_error elif(not isinstance(f_config,Sequence)): raise type_error f_config.sort() res = "-".join(f_config) return res
sequence🎈@python序列类型
-
common-sequence-operations|Built-in Types — Python documentation
-
An iterable which supports efficient element access using integer indices via the
__getitem__()special method and defines a__len__()method that returns the length of the sequence. -
Some built-in sequence types are
list,str,tuple, andbytes. -
Note that
dictalso supports__getitem__()and__len__(), but is considered a mapping rather than a sequence because the lookups use arbitrary immutable keys rather than integers. -
The
collections.abc.Sequenceabstract base class defines a much richer interface that goes beyond just__getitem__()and__len__(), addingcount(),index(),__contains__(), and__reversed__(). -
Types that implement this expanded interface can be registered explicitly using
register().
slice@切片
- An object usually containing a portion of a sequence.
- A slice is created using the subscript notation,
[]with colons between numbers when several are given, such as invariable_name[1:3:5]. - The bracket (subscript) notation uses
sliceobjects internally.
slice()内置方法
-
在Python中,slice()是一个内置函数,用于创建一个切片对象(slice object),用于切片操作。切片(slice)是指从序列中获取一部分元素的操作,可以用于对列表、元组、字符串等序列类型进行操作。切片操作通常使用[start:stop:step]的形式表示,其中start表示起始位置(默认为0),stop表示终止位置(默认为序列长度),step表示步长(默认为1)。 slice()函数的语法如下:
codeslice(stop) slice(start, stop, step)参数说明:
- start:可选参数,表示切片的起始位置。
- stop:必选参数,表示切片的结束位置。
- step:可选参数,表示切片的步长。
- 如果只提供一个参数,则该参数表示切片的结束位置,起始位置默认为0,步长默认为1。
- 如果提供两个参数,则第一个参数表示切片的起始位置,第二个参数表示切片的结束位置,步长默认为1。
- 如果提供三个参数,则分别表示切片的起始位置、结束位置和步长。
-
下面是一些使用slice()函数的示例:
# 列表切片 my_list = [1, 2, 3, 4, 5] s = slice(1, 4) print(my_list[s]) # 输出 [2, 3, 4] # 字符串切片 my_string = "Hello, World!" s = slice(7) print(my_string[s]) # 输出 Hello, # 步长为2的切片 s = slice(1, 7, 2) print(my_string[s]) # 输出 el, # 切片赋值 my_list[s] = [6, 7] print(my_list) # 输出 [1, 6, 3, 7, 5]- 在上述示例中,我们使用slice()函数创建了切片对象s,然后使用s来对列表和字符串进行切片操作。
- 同时,我们也可以使用切片对象进行赋值操作,将切片替换为指定的值。
itertools.slice()方法
-
itertools.islice(iterable, stop) itertools.islice(iterable, start, stop[, step]) -
创建一个迭代器,返回从 iterable 里选中的元素。
-
如果 start 不是0,跳过 iterable 中的(开头)元素,直到到达 start 这个位置。
- 之后迭代器连续返回元素,除非 step 设置的值很高导致被跳过。
-
如果 stop 为
None,迭代器耗光为止;否则,在指定的位置停止。 -
与普通的切片不同,
islice()不支持将 start , stop ,或 step 设为负值。- 可用来从内部数据结构被压平的数据中提取相关字段(例如一个多行报告,它的名称字段出现在每三行上)。大致相当于:
def islice(iterable, *args): # islice('ABCDEFG', 2) --> A B # islice('ABCDEFG', 2, 4) --> C D # islice('ABCDEFG', 2, None) --> C D E F G # islice('ABCDEFG', 0, None, 2) --> A C E G s = slice(*args) start, stop, step = s.start or 0, s.stop or sys.maxsize, s.step or 1 it = iter(range(start, stop, step)) try: nexti = next(it) except StopIteration: # Consume *iterable* up to the *start* position. for i, element in zip(range(start), iterable): pass return try: for i, element in enumerate(iterable): if i == nexti: yield element nexti = next(it) except StopIteration: # Consume to *stop*. for i, element in zip(range(i + 1, stop), iterable): pass -
如果 start 为
None,迭代从0开始。如果 step 为None,步长缺省为1。