MIT 6824 关于lab2的实现,由于开源许可的问题,代码暂时不开源,下面是自己在实现过程中的思路,遇到的问题,以及总结
1 总结
1.1 raft整个流程
- 应用程序:kv数据库
- 启动raft库,选举leader,对应领导人选举 RequestVote RPC
- 客户端发送请求给kv数据库,kv数据库将请求给到leader Start(),由leader将其添加到自己的log,并通知raft节点添加log,对应日志复制 AppendEntires RPC
- 如果leader收到了过半raft节点日志复制成功的消息,将会通知kv数据库执行该log指令。 applyCh管道
- 当kv数据库累计执行了一定数量的log,会在一个快照点生成一个快照,然后通知leader将快照点之前的log都删除 Snapshot(),leader再通知其他raft节点安装快照 InstallSnapshot RPC,其他raft节点安装完快照后,就通知其上面的kv数据库执行快照 applyCh管道,kv数据库执行快照后,再通知这个raft节点调整log CondInstallSnapshot()。
1.2 领导人选举
-
raft节点会有三种状态,Follower,Candidate,Leader
const ( StateFollower = 1 StateCandidate = 2 StateLeader = 3 ) -
什么时候会发生选举?
- raft中有个随机定时器,当定时器超时,该节点还未收到leader发来的消息,就认为leader宕机,此时raft成为Candidate,并开始选举
-
心跳包的时间和随机定时器
- 这里心跳包设置的是100ms,每隔100ms,leader都会和其他raft节点进行通信。
const ( HEART_BEAT_TIMEOUT = 100 )- 随机定时器必须要>HEART_BEAT_TIMEOUT ,这样raft节点才是正常进入选举的时候,这里将其设置为[200ms, 300ms]
// 随机选举定时器 心跳包时间*2 + rand(心跳包) = [200, 300] electionTimeout := time.Duration( HEART_BEAT_TIMEOUT*2+rand.Intn(HEART_BEAT_TIMEOUT), ) * time.Millisecond -
Candidate如何进行选举?
- 将自己的状态设置为Candidate,投自己一票,当前任期++
if rf.state != StateLeader && time.Since(rf.lastHeartBeatTime) >= electionTimeout { rf.ChangeState(StateCandidate) rf.currentTerm += 1 // 当前任期号+1 rf.votedFor = rf.me // 投自己一票 rf.voteCount = 1 rf.lastHeartBeatTime = time.Now() // 刷新心跳包,每次开始选举,重新计时 ... }-
通知其他raft节点,并统计投票,如果过半,就成为Leader。这里通知其他raft节点使用**ReqeustVote()**方法,我们使用了并行的方式进行,这样不会出现每次请求都需要等待其他raft节点的回复。
// 给其他raft节点发送RequestVote RPC请求 for peer := range rf.peers { if peer == rf.me { continue } go rf.sendRequestVote(peer) } -
raft节点收到消息,需要判断是否给出投票,这里论文中给出了两条限制,必须要满足其一,才给出投票
- 第一,Candidate最后一个日志条目的Term > Follower最后一个日志条目的Term
- 第二,候选人最后一个日志条目的Term == Follower最后一个日志条目的Term && len(候选人log) ≥ len(Follower的log)
// 判断Follower是否投票 // 有两个限制 func (rf *Raft) isLogUpToDate(candidateLastLogTerm int, candidateLastLogIdx int) bool { followerLastLogTerm := rf.GetLogEntry(-1).Term followerLastLogIdx := rf.GetLogEntry(-1).Index if candidateLastLogTerm > followerLastLogTerm { return true } else if candidateLastLogTerm == followerLastLogTerm && candidateLastLogIdx >= followerLastLogIdx { return true } return false } func (rf *Raft) RequestVote(args *RequestVoteArgs, reply *RequestVoteReply) { // Your code here (2A, 2B). rf.mu.Lock() defer rf.mu.Unlock() defer rf.persist() //defer DPrintf("{Node %v}'s state is {state %v,term %v,commitIndex %v,lastApplied %v,firstLog %v,lastLog %v} before processing requestVoteRequest %v and reply requestVoteResponse %v", rf.me, rf.state, rf.currentTerm, rf.commitIndex, rf.lastApplied, rf.GetLogEntry(0), rf.GetLogEntry(-1), args, reply) // 论文中的figure 2 // 1. 候选人的currentTerm < Follower的currentTerm,拒绝投票 if args.Term < rf.currentTerm { reply.Term, reply.VoteGranted = rf.currentTerm, false return } // 候选者的currentTerm > Follower的currentTerm,需要更新Follower的currentTerm if args.Term > rf.currentTerm { rf.ChangeState(StateFollower) rf.currentTerm = args.Term rf.votedFor = -1 } // 选举限制,满足Follower才投票 // 1. Follower还没投过票 || 已经给该候选人投过票了 // +2. 候选人最后一个日志条目的Term > Follower最后一个日志条目的Term // +3. 候选人最后一个日志条目的Term == Follower最后一个日志条目的Term && len(候选人log) >= len(Follower的log) //DPrintf("rf.isLogUpToDate(args.LastLogTerm, args.LastLogIndex) == %v", rf.isLogUpToDate(args.LastLogTerm, args.LastLogIndex)) if (rf.votedFor == -1 || rf.votedFor == args.CandidatedId) && rf.isLogUpToDate(args.LastLogTerm, args.LastLogIndex) { // 给候选人投票 rf.votedFor = args.CandidatedId // 每次完成投完票,应该重新设置随机选举定时器 rf.lastHeartBeatTime = time.Now() reply.Term, reply.VoteGranted = rf.currentTerm, true return } reply.Term, reply.VoteGranted = rf.currentTerm, false return } -
Candidate统计投票,当有过半票同意当选,Candidate成为Leader,然后再通过心跳包通知其他raft节点。
// 有一票 if voteGranted { rf.voteCount += 1 } // 过半票决 //DPrintf("投票:%v", grantedVotes) if rf.voteCount >= len(rf.peers)/2+1 { //DPrintf("{Node %v} receives majority votes in term %v", rf.me, rf.currentTerm) rf.ChangeState(StateLeader) // 成为Leader后,需要发送心跳包(AppendEntries)通知其他Follower // rf.mu.Unlock() // rf.BroadcastAppendEntries() for i := 0; i < len(rf.peers); i++ { rf.nextIndex[i] = rf.GetLogEntry(-1).Index + 1 rf.matchIndex[i] = 0 } rf.mu.Unlock() // 解锁完,replicateRountine就可以发送添加请求了 for peer := range rf.peers { if peer == rf.me { continue } go rf.sendAppendEntries(peer) } }
1.2 日志复制
-
日志复制的流程
- 客户端→kv数据库→leader,leader需要在log中添加这个请求,并通知其他raft节点添加。
func (rf *Raft) Start(command interface{}) (int, int, bool) { rf.mu.Lock() defer rf.mu.Unlock() index := rf.GetLogEntry(-1).Index + 1 term := rf.currentTerm isLeader := rf.state == StateLeader // leader每增加一个日志,就需要发送一次AppendEntries请求 if isLeader { rf.logs = append(rf.logs, LogEntry{ Command: command, Term: term, Index: index, }) rf.matchIndex[rf.me] = index rf.nextIndex[rf.me] = index + 1 rf.persist() rf.mu.Unlock() for peer := range rf.peers { if peer == rf.me { continue } go rf.sendAppendEntries(peer) } rf.mu.Lock() } return index, term, isLeader } -
Leader需要保证Follower和自己保持一样的log,这样kv数据库的状态才能保证一致性。
- 这里有几个变量需要注意
- nextIndex[peer]:leader应该和哪个peer的log槽位比
- preLogIndex:nextIndex - 1
- preLogTerm:preLogIndex对应的term
- entries:leader的preLogIndex后面的log
- commitedIndex:已经提交给kv数据库的log槽位号
- Follower中,必须要保证preLogTerm == Follower在preLogIndex的term,因为RAFT规定,如果Leader.log[i].term == Follower.log[i].term,则i之前的log一定是一致的。因此,如果preLogTerm != Follower在preLogIndex的term,则可能导致之前的log不一致性。
- 当满足上面的条件
- Follower会将preLogIndex后面的log复制为entries。
- 同时,根据commitedIndex,Follower会通知kv数据库执行log
- 如果不满足以上条件,Follower会返回一些信息,加速日志恢复
- ConflictTerm:Follower在preLogIndex的term,没有就是-1
- ConflictIndex:Follower在preLogIndex的term,第一次出现的槽位号
- Leader再根据这些信息进行调整,其实包含了三种情况
-
case1


-
case 2


-
case 3


-
- 这里有几个变量需要注意
-
Leader得到过半票的日志复制成功消息时,通知kv数据库执行自己term的log
1.3 持久化
-
RAFT规定了对三种数据的持久化
- 每次对这些数据进行了改变都应当做持久化
// 持久化存储 currentTerm int // 最新的任期服务器 votedFor int // 已经为谁投过票 logs []LogEntry // 日志
1.4 快照
- 长时间来看,日志要的存储量比kv数据的状态大。另外,每次宕机后,服务器都从头开始执行log,那效率一定很低。
- 快照就是kv数据的状态,当kv数据库可以在一定时间确认一个快照点,生成一个快照,leader就可以在log中删除该快照点之前的log。
- leader需要将快照发给follower,follower再把快照给kv数据库,如果kv数据库接受了这个快照,会通知follower调整log
2 问题
2.1 领导人选举
- 为什么要用过半票决?
- 防止脑裂问题,导致的不一致性
- 当有一半的raft节点还在工作时,集群就可以使用,这是一种容错机制
- 新leader和旧leader一定有交集的raft节点,出现网络分区时,新leader会通过这些交集的raft节点告诉旧leader他不在是leader了。
- 这里为什么使用的是随机定时器?
- 为了防止raft节点同时进行选举,每个节点都给自己投票,拒绝其他节点,投票分离,所有节点都不可能得到过半投票。
- 如果选举失败会怎么办?
- 会开始新的一轮选举,这个过程中,客户端的请求会无法得到响应。
2.2 日志复制
- 如果日志复制过程中,Leader宕机了怎么办?如何保证Follower的log一致性?
- 这个时候raft集群一定有节点的log已经不一致了。
- 需要重新进行选举,新选举出来的Leader会保证过半节点的log一致性
2.3 持久化
- 为什么要对这三种数据做持久化?
-
currentTerm:保证集群只有一个leader。需要知道自己当前的任期。这有一个反例

-
votedFor:保证集群只有一个leader。如果r1已经给leader投过票,但之后r1宕机,之后r1又重启,r2此时也发来一个选举请求,如果此时没有读取votedFor,r1又会给r2投一票,此时集群可能就有两个leader.
-
logs:保存了kv数据库的状态,保存下来,下次重启才能恢复宕机时的状态
-
2.4 快照
- Leader为什么还要给Follower发送快照?
- 因为网络,Leader在发送AppendEntires的过程中出现宕机,导致Follower的log比较短(短于快照点),这样,如果leader此时删除了快照点之前的log,那Follower就再也无法得到少的那段log。因此为了保证一致性,Leader需要给Follower发送快照。
2.5 其他问题
- raft宕机重启后加入集群,如何恢复自己的状态。
- 此时raft会读取自己的log,然后leader会和它通信,通过AppendEntires,保证日志一致性
- 当leader和副本都关机,重启后,如何恢复服务器状态
- 都会立即读取log,但不执行。此时需要先选举leader,之后leader再和副本进行沟通,找到过半副本中最近的log点,然后leader从头执行,之后给副本发送commited号,副本再接着恢复。
- RAFT是如何保证一致性的?
- 日志复制保证日志的一致性
3 实验中遇到的困难
3.1 处理如何发数据的问题
- 刚开始使用的时候,没考虑那么多,直接就是一整个业务逻辑放在一起,顺序执行。比如选举领导人需要给其他的节点的发送RequestVote请求,每次发完统计一次票数,当票数过半时,再确定Leader。这种方式很慢,后一次RPC请求都要等前一次请求返回。后面针对于每次发请求,我们都开一个协程来,这样并行的方式效率更高。
3.2 使用锁的一些问题
- 因为项目中遇到了多线程,因此会涉及到对一些共享数据加锁。在实际的过程中,我习惯用defer去释放锁,这就导致每次发送RPC请求的时候,还拿着这把锁,这就导致其他的线程无法立即给其他的raft节点发送RPC请求,这样我们的并行就失效了,这就导致了超时。后面发现需要在发RPC请求之前就应该先把锁放掉。
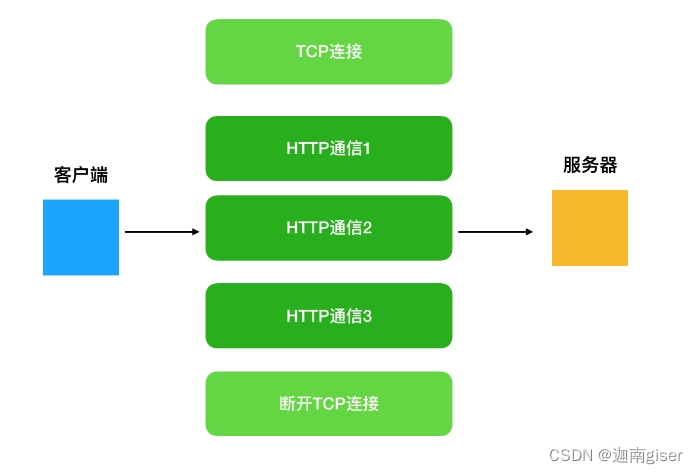
3.2 针对很大的快照包,如何实现发送
- Leader每次给raft的快照包可能比较大,很显然一次性传给Follower很慢。所以这里采用了分包的方式,然后开了3个线程去发送这些包,这里主要参考了TCP的分包的思路。。。。。后面再补充