centos7.5离线安装部署TiDB-6.5.0分布式系统
一、需求,为什么要部署TiDB-6.5.0分布式系统
当前绝大部分企业的业务数据都分散在不同的系统中,没有一个统一的汇总,随着业务的发展,企业的决策层需要了解整个公司的业务状况以便及时做出决策,故需要将分散在各个系统的数据汇聚在同一个系统并进行二次加工处理生成 T+0 或 T+1 的报表。传统常见的解决方案是采用 ETL + Hadoop 来完成,但 Hadoop 体系太复杂,运维、存储成本太高无法满足用户的需求。与 Hadoop 相比,TiDB 就简单得多,业务通过 ETL 工具或者 TiDB 的同步工具将数据同步到 TiDB,在 TiDB 中可通过 SQL 直接生成报表。
二、TIDB基本概念
2.1 什么是 TiDB
TiDB 是 PingCAP 公司自主设计、研发的开源分布式关系型数据库,是一款同时支持在线事务处理与在线分析处理 (Hybrid Transactional and Analytical Processing, HTAP)的融合型分布式数据库产品,具备水平扩容或者缩容、金融级高可用、实时 HTAP、云原生的分布式数据库、兼容 MySQL 5.7 协议和 MySQL 生态等重要特性。目标是为用户提供一站式 OLTP (Online Transactional Processing)、OLAP (Online Analytical Processing)、HTAP 解决方案。TiDB 适合高可用、强一致要求较高、数据规模较大等各种应用场景。
2.2 TiDB 整体架构
要深入了解 TiDB 的水平扩展和高可用特点,首先需要了解 TiDB 的整体架构。TiDB 集群主要包括三个核心组件:TiDB Server,PD Server 和 TiKV Server。此外,还有用于解决用户复杂 OLAP 需求的 TiSpark 组件和简化云上部署管理的 TiDB Operator 组件。
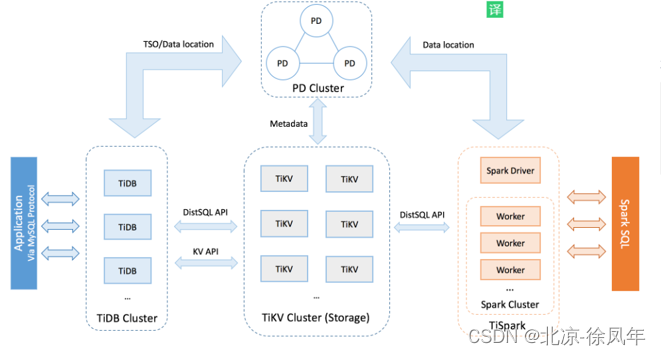
2.3 TiDB Server
TiDB Server 负责接收 SQL 请求,处理 SQL 相关的逻辑,并通过 PD 找到存储计算所需数据的 TiKV 地址,与 TiKV 交互获取数据,最终返回结果。TiDB Server 是无状态的,其本身并不存储数据,只负责计算,可以无限水平扩展,可以通过负载均衡组件(如LVS、HAProxy 或 F5)对外提供统一的接入地址。
2.4 PD Server
Placement Driver (简称 PD) 是整个集群的管理模块,其主要工作有三个:一是存储集群的元信息(某个 Key 存储在哪个 TiKV 节点);二是对 TiKV 集群进行调度和负载均衡(如数据的迁移、Raft group leader 的迁移等);三是分配全局唯一且递增的事务 ID。
PD 通过 Raft 协议保证数据的安全性。Raft 的 leader server 负责处理所有操作,其余的 PD server 仅用于保证高可用。建议部署奇数个 PD 节点。
2.5 TiKV Server
TiKV Server 负责存储数据,从外部看 TiKV 是一个分布式的提供事务的 Key-Value 存储引擎。存储数据的基本单位是 Region,每个 Region 负责存储一个 Key Range(从 StartKey 到 EndKey 的左闭右开区间)的数据,每个 TiKV 节点会负责多个 Region。TiKV 使用 Raft 协议做复制,保持数据的一致性和容灾。副本以 Region 为单位进行管理,不同节点上的多个 Region 构成一个 Raft Group,互为副本。数据在多个 TiKV 之间的负载均衡由 PD 调度,这里也是以 Region 为单位进行调度。
2.6 TiSpark
TiSpark 作为 TiDB 中解决用户复杂 OLAP 需求的主要组件,将 Spark SQL 直接运行在 TiDB 存储层上,同时融合 TiKV 分布式集群的优势,并融入大数据社区生态。至此,TiDB 可以通过一套系统,同时支持 OLTP 与 OLAP,免除用户数据同步的烦恼。
2.7 TiDB Operator
TiDB Operator 提供在主流云基础设施(Kubernetes)上部署管理 TiDB 集群的能力。它结合云原生社区的容器编排最佳实践与 TiDB 的专业运维知识,集成一键部署、多集群混部、自动运维、故障自愈等能力,极大地降低了用户使用和管理 TiDB 的门槛与成本。
2.8 与 MySQL 兼容性对比
TiDB 支持 MySQL 传输协议及其绝大多数的语法。这意味着您现有的 MySQL 连接器和客户端都可以继续使用。大多数情况下您现有的应用都可以迁移至 TiDB,无需任何代码修改。
当前 TiDB 服务器官方支持的版本为 MySQL 5.7。大部分 MySQL 运维工具(如 PHPMyAdmin, Navicat, MySQL Workbench 等),以及备份恢复工具(如 mysqldump, Mydumper/myloader)等都可以直接使用。
不过一些特性由于在分布式环境下没法很好的实现,目前暂时不支持或者是表现与 MySQL 有差异。一些 MySQL 语法在 TiDB 中可以解析通过,但是不会做任何后续的处理,例如 Create Table 语句中 Engine,是解析并忽略。
https://pingcap.com/docs-cn/v6.5.0/reference/mysql-compatibility/
等着急了吧,这就开始安装部署了,部署完成后可以再看上面。
三、TiDB-6.5.0分布式系统安装和部署
3.1 下载二进制安装包
进入官方下载地址,选择社区版下载,以及选择对应的版本
https://cn.pingcap.com/product-community/
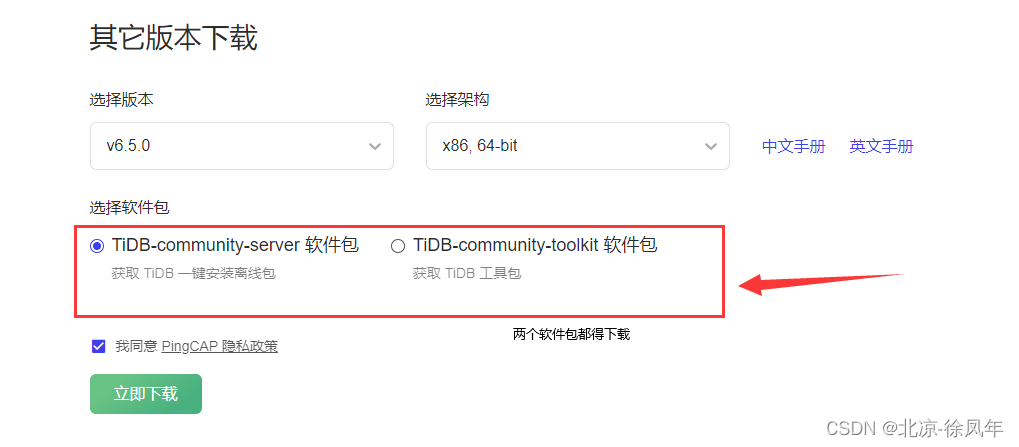
3.2 进行基本环境的配置
#创建tidb用户
adduser tidb
passwd tidb
vim /etc/sudoers
tidb ALL=(ALL) NOPASSWD:ALL
#进行相互之间免密操作
su - tidb
ssh-keygen -t rsa
ssh-copy-id -i ~/.ssh/id_rsa.pub tidb@192.168.2.223
ssh-copy-id -i ~/.ssh/id_rsa.pub root@192.168.2.223
以下我都是在tidb用户下操作的,权限不足就加sudo
3.3 部署离线环境 TiUP 组件
将离线包发送到服务器后,执行以下命令安装 TiUP 组件:
#对压缩包的一些处理,其实也无所吊谓,处不处理都可以,想来诸位都是有linux一定基础的
sudo chmod +x tidb-community-server-v6.5.0-linux-amd64.tar.gz
sudo chown tidb:tidb tidb-community-server-v6.5.0-linux-amd64.tar.gz
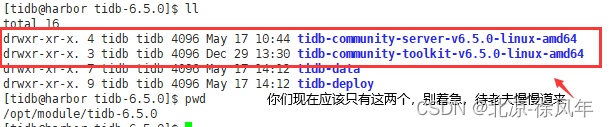
#创建 tidb-6.5.0文件夹,以后所有关于tidb的数据都放到了这个文件夹里面
mkdir /opt/module/tidb-6.5.0
sudo tar -zxvf tidb-community-server-v6.5.0-linux-amd64.tar.gz -C /opt/module/tidb-6.5.0
sudo chown -R tidb:tidb ./tidb-6.5.0/
sh ./local_install.sh
source /home/tidb/.bash_profile
tiup playground
local_install.sh 脚本会自动执行 tiup mirror set tidb-community-server-
v
e
r
s
i
o
n
−
l
i
n
u
x
−
a
m
d
64
命令将当前镜像地址设置为
t
i
d
b
−
c
o
m
m
u
n
i
t
y
−
s
e
r
v
e
r
−
{version}-linux-amd64 命令将当前镜像地址设置为 tidb-community-server-
version−linux−amd64命令将当前镜像地址设置为tidb−community−server−{version}-linux-amd64。
3.4 合并离线包
如果是通过官方下载页面下载的离线软件包,需要将 TiDB-community-server 软件包和 TiDB-community-toolkit 软件包合并到离线镜像中。如果是通过 tiup mirror clone 命令手动打包的离线组件包,不需要执行此步骤。
执行以下命令合并离线组件到 server 目录下。
tar xf tidb-community-toolkit-${version}-linux-amd64.tar.gz
ls -ld tidb-community-server-${version}-linux-amd64 tidb-community-toolkit-${version}-linux-amd64
cd tidb-community-server-${version}-linux-amd64/
cp -rp keys ~/.tiup/
tiup mirror merge ../tidb-community-toolkit-${version}-linux-amd64
若需将镜像切换到其他目录,可以通过手动执行 tiup mirror set 进行切换。如果需要切换到在线环境,可执行 tiup mirror set https://tiup-mirrors.pingcap.com。
3.5初始化集群拓扑文件
针对两种常用的部署场景,也可以通过以下命令生成建议的拓扑模板:
混合部署场景:单台机器部署多个实例
tiup cluster template --full > topology.yaml
跨机房部署场景:跨机房部署 TiDB 集群
tiup cluster template --multi-dc > topology.yaml
执行 vim topology.yaml,查看配置文件的内容(我的得单节点做测试,单节点会部署,集群应该也会部署吧,不会评论我后面给咱copy别人的教程。):
global:
user: "tidb"
ssh_port: 22
deploy_dir: "/opt/module/tidb-6.5.0/tidb-deploy"
data_dir: "/opt/module/tidb-6.5.0/tidb-data"
server_configs: {}
pd_servers:
- host: 192.168.2.223
tidb_servers:
- host: 192.168.2.223
tikv_servers:
- host: 192.168.2.223
monitoring_servers:
- host: 192.168.2.223
grafana_servers:
- host: 192.168.2.223
alertmanager_servers:
- host: 192.168.2.223
3.6 执行部署命令
注意
通过 TiUP 进行集群部署可以使用密钥或者交互密码方式来进行安全认证:
如果是密钥方式,可以通过 -i 或者 --identity_file 来指定密钥的路径。
如果是密码方式,可以通过 -p 进入密码交互窗口。
如果已经配置免密登录目标机,则不需填写认证。
一般情况下 TiUP 会在目标机器上创建 topology.yaml 中约定的用户和组,以下情况例外:
topology.yaml 中设置的用户名在目标机器上已存在。
在命令行上使用了参数 --skip-create-user 明确指定跳过创建用户的步骤。
执行部署命令前,先使用 check 及 check --apply 命令检查和自动修复集群存在的潜在风险:
1.检查集群存在的潜在风险:
tiup cluster check ./topology.yaml --user root
2.自动修复集群存在的潜在风险:
tiup cluster check ./topology.yaml --apply --user root
3.6.1.1 以下是检查集群存在的潜在风险出现问题的解决方法
检查集群命令
tiup cluster check ./topology.yaml --user tidb
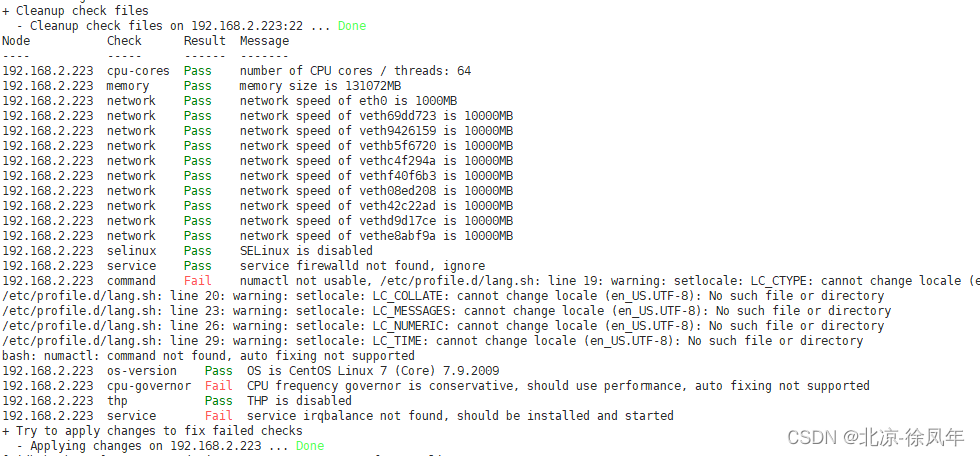
问题一:CPU frequency governor is conservative, should use performance, auto fixing not supported
为调整 CPU 频率的 cpufreq 模块选用 performance 模式。将 CPU 频率固定在其支持的最高运行频率上,不进行动态调节,可获取最佳的性能。
解决方法;即看即用
Linux 内部共有五种对频率的管理策略 userspace , conservative , ondemand , powersave(省电模式) 和 performance(性能模式)。
查看当前CPU模式:
查看cpu0
cat /sys/devices/system/cpu/cpu0/cpufreq/scaling_governor
查看所有cpu
cat /sys/devices/system/cpu/cpu*/cpufreq/scaling_governor
查看所有CPU频率:
cpupower -c all frequency-info
设置CPU模式:
cpupower frequency-set -g performance #设置成性能模式
cpupower frequency-set -g powersave #设置成省电模式
linux报错:-bash: cpupower: command not found
这个错误提示表明系统中没有安装cpupower命令。可以通过以下命令安装cpupower:
在Debian/Ubuntu上:
sudo apt-get update
sudo apt-get install linux-tools-common linux-tools-$(uname -r)
在CentOS/RHEL上:
sudo yum install kernel-tools
安装完成后,再次尝试运行cpupower命令即可。
问题二: service irqbalance not found, should be installed and started
这个错误提示表明系统中没有安装irqbalance服务。可以通过以下命令安装irqbalance:
#在Debian/Ubuntu上:
sudo apt-get update
sudo apt-get install irqbalance
#在CentOS/RHEL上:
sudo yum install irqbalance
#安装完成后,启动irqbalance服务:
sudo service irqbalance start
#或者:
sudo systemctl start irqbalance
如果需要开机自启动irqbalance服务,可以执行以下命令:
#在Debian/Ubuntu上:
sudo update-rc.d irqbalance defaults
#在CentOS/RHEL上:
sudo systemctl enable irqbalance
安装和启动完成后,再次尝试运行irqbalance服务即可。
问题三: Fail numactl not usable, /etc/profile.d/lang.sh: line 19: warning: setlocale: LC_CTYPE: cannot change locale (en_US.UTF-8): No such file or directory
/etc/profile.d/lang.sh: line 20: warning: setlocale: LC_COLLATE: cannot change locale (en_US.UTF-8): No such file or directory
/etc/profile.d/lang.sh: line 23: warning: setlocale: LC_MESSAGES: cannot change locale (en_US.UTF-8): No such file or directory
/etc/profile.d/lang.sh: line 26: warning: setlocale: LC_NUMERIC: cannot change locale (en_US.UTF-8): No such file or directory
/etc/profile.d/lang.sh: line 29: warning: setlocale: LC_TIME: cannot change locale (en_US.UTF-8): No such file or directory
解决方法:
sudo yum -y install numactl
如果numactl能够使用,那么第一个问题就不存在了。可能只是语言环境设置的问题。在命令行中使用以下命令来安装缺少的语言包:
#安装glibc-common包:
sudo yum install -y glibc-common
#生成en_US.UTF-8 locale:
sudo localedef -c -i en_US -f UTF-8 en_US.UTF-8
#编辑/etc/locale.conf文件,并添加以下内容:
LANG=en_US.utf8
LC_ALL=en_US.utf8
#编辑/etc/profile文件,并添加以下内容:
export LANG=en_US.UTF-8
export LC_ALL=en_US.UTF-8
#重新启动以使更改生效。
source /etc/profile
3.7 重新执行检查命令
tiup cluster check ./topology.yaml --user tidb
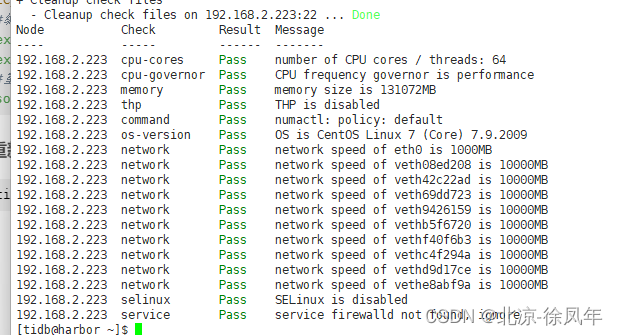
发现全部没有问题,ok
3.8 部署 TiDB 集群:
tiup cluster deploy harbor-tidb1 v6.5.0 ./topology.yaml --user tidb -p
以上部署示例中:
harbor-tidb1 为部署的集群名称。
v6.5.0 为部署的集群版本,可以通过执行 tiup list tidb 来查看 TiUP 支持的最新可用版本。
初始化配置文件为 topology.yaml。
–user root 表示通过 root 用户登录到目标主机完成集群部署,该用户需要有 ssh 到目标机器的权限,并且在目标机器有 sudo 权限。也可以用其他有 ssh 和 sudo 权限的用户完成部署。
[-i] 及 [-p] 为可选项,如果已经配置免密登录目标机,则不需填写。否则选择其一即可,[-i] 为可登录到目标机的 root 用户(或 --user 指定的其他用户)的私钥,也可使用 [-p] 交互式输入该用户的密码。
预期日志结尾输出 Deployed cluster harbor-tidb1 successfully 关键词,表示部署成功。
3.9 查看 TiUP 管理的集群情况
tiup cluster list
TiUP 支持管理多个 TiDB 集群,该命令会输出当前通过 TiUP cluster 管理的所有集群信息,包括集群名称、部署用户、版本、密钥信息等。
3.10 检查部署的 TiDB 集群情况
例如,执行如下命令检查 harbor-tidb1 集群情况:
tiup cluster display harbor-tidb1
预期输出包括 tidb-test 集群中实例 ID、角色、主机、监听端口和状态(由于还未启动,所以状态为 Down/inactive)、目录信息。
3.11 启动集群
安全启动是 TiUP cluster 从 v1.9.0 起引入的一种新的启动方式,采用该方式启动数据库可以提高数据库安全性。推荐使用安全启动。
安全启动后,TiUP 会自动生成 TiDB root 用户的密码,并在命令行界面返回密码。
注意
使用安全启动方式后,不能通过无密码的 root 用户登录数据库,你需要记录命令行返回的密码进行后续操作。
该自动生成的密码只会返回一次,如果没有记录或者忘记该密码,请参照忘记 root 密码修改密码。
方式一:安全启动
tiup cluster start harbor-tidb1 --init
预期结果如下,表示启动成功。
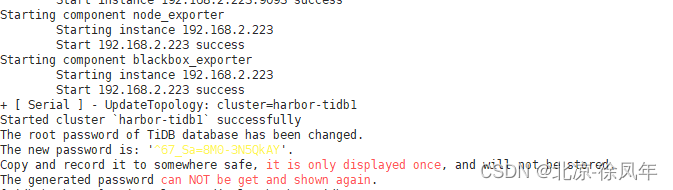
方式二:普通启动
tiup cluster start harbor-tidb1
预期结果输出 Started cluster harbor-tidb1 successfully,表示启动成功。使用普通启动方式后,可通过无密码的 root 用户登录数据库。
3.12 验证集群运行状态
tiup cluster display harbor-tidb1
预期结果输出:各节点 Status 状态信息为 Up 说明集群状态正常。
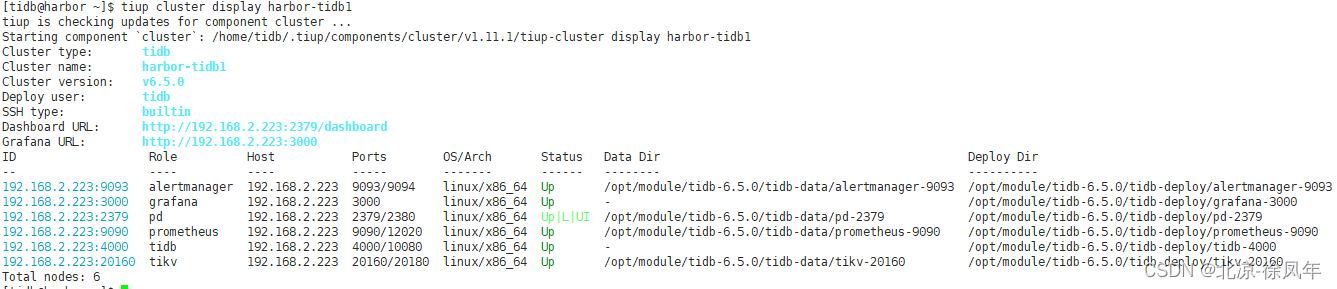
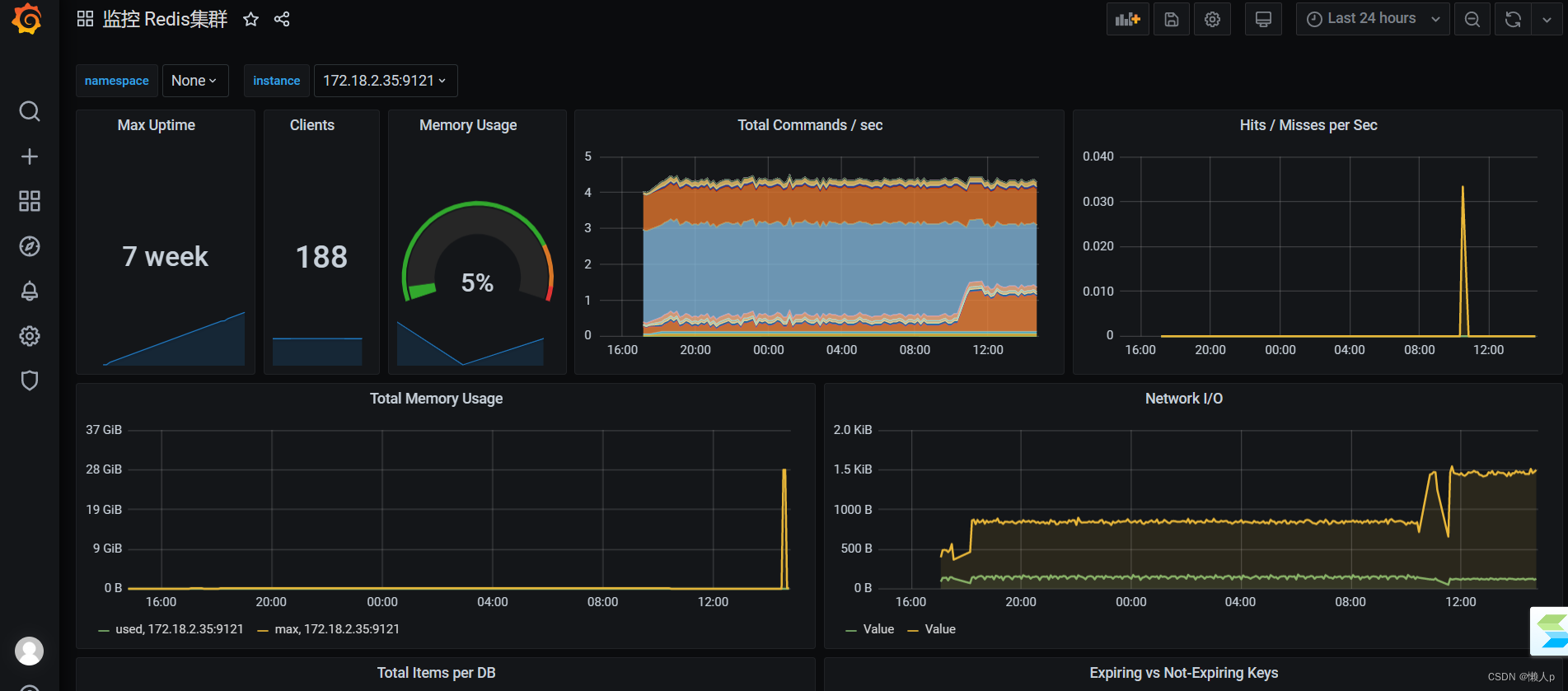
3.13 使用navicat连接
可以看到 tidb 的端口号是 4000,pd 运维端口是 2379。我们通过 Navicat 这种工具连接数据库是使用 4000 端口
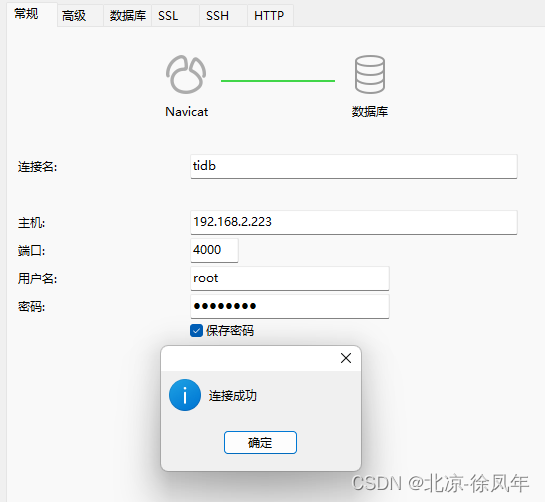
3.14 访问general
http://IP:3000/login 账号密码 都为admin
3.15 Dashboard
Dashboard URL: http://IP:2379/dashboard
3.16 关键组件
几个关键组件信息:
Pd: 元数据及控制调度组件
Tikv:存储组件
Tidb:数据库实例组件
Tiflash:闪存组件
Tidb 虽然和 mysql 类似,但是它厉害在分布式,如果要使用 mysql,数据库变大后,要思考虑分库分表、使用 mycat 等数据路由工具,Tidb 设计从底层一开始分布式,类似 hdfs 的存储架构,将分布式做成一种原生的架构。
官网部署地址
https://docs.pingcap.com/zh/tidb/stable/production-deployment-using-tiup