【样品】《谜影之夜》文生图全自动版SD一键成片
操作步骤&环境配置地址:
【NovelAI】月产10000+全自动批量原创小说短视频支持文生图和视频克隆
该文章面向购买脚本的付费用户,提供所有问题以及解决办法。使用 notepad++ 打开对应的文件即可,软件自行百度下载。
使用出现问题查看这里【NovelAI 小说SD批量生成 文生图/视频克隆】问题汇总&解决办法
数据文件配置
任务文件
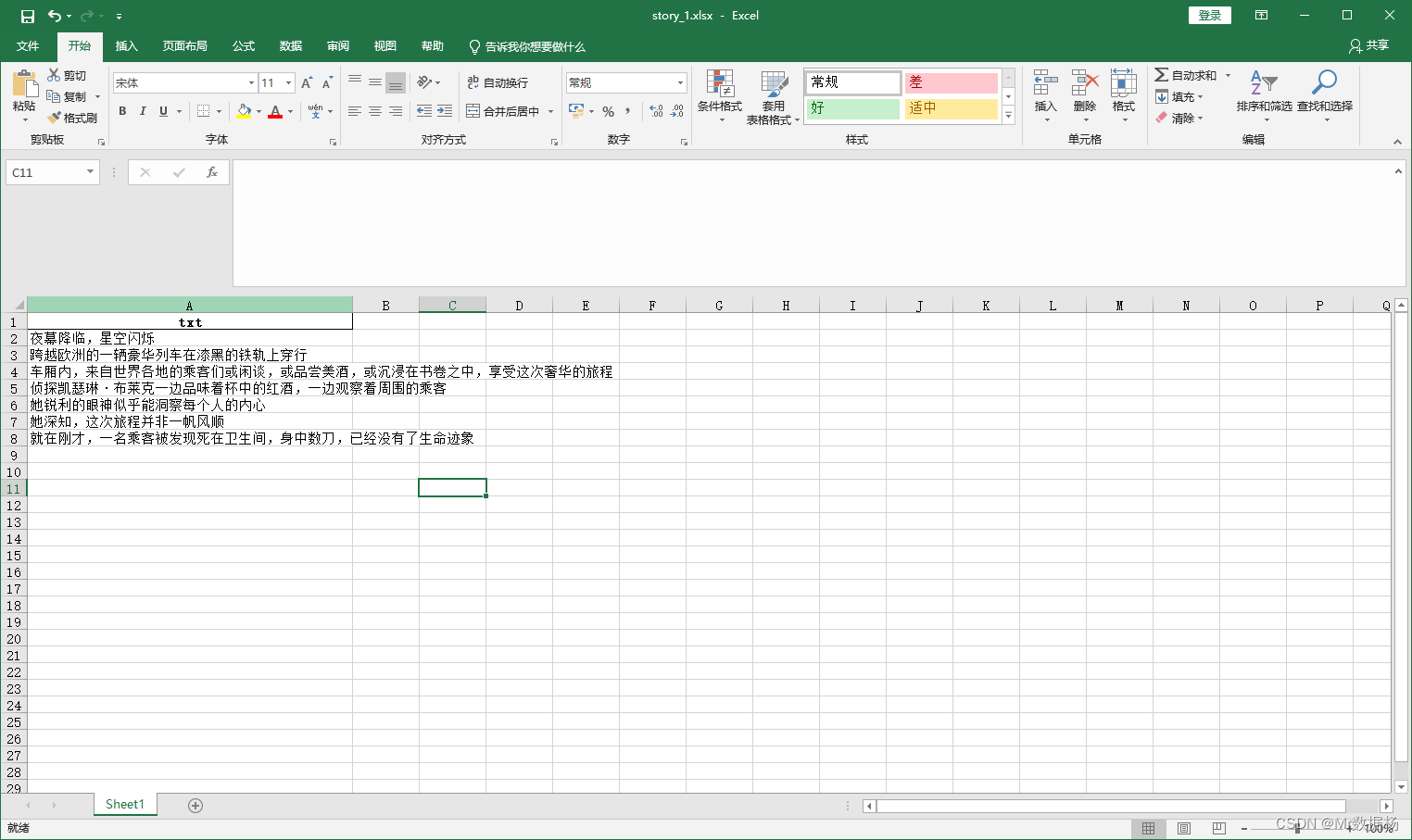
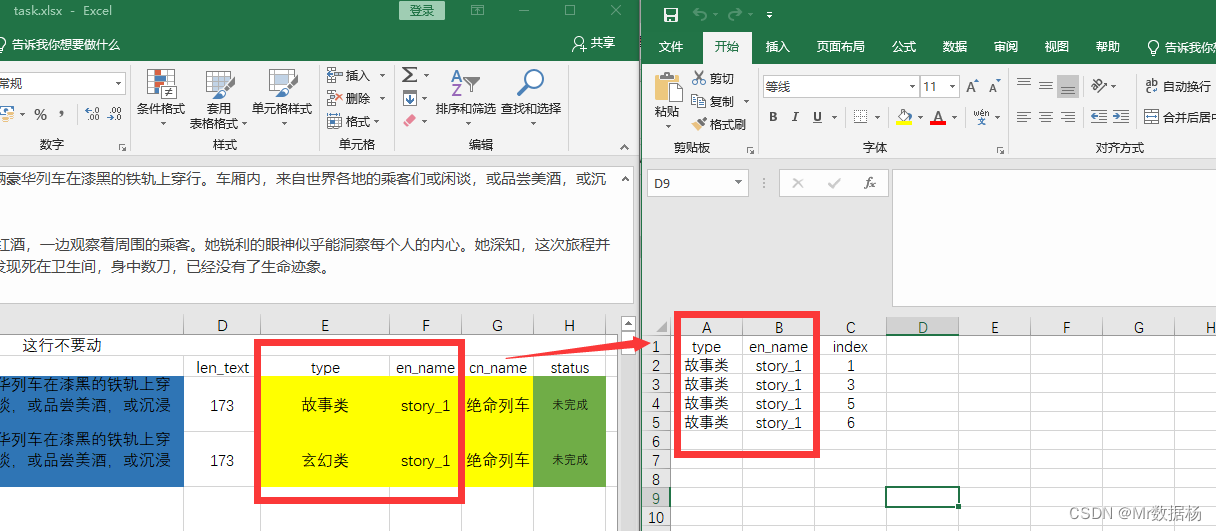
整个项目包中的路径 不能有中文,不能有中文,不能有中文, 文件位置 task_menu/task.xlsx。
数据格式如下

- content列,蓝色部分 是你要一键生成视频的稿件,建议用GPT4洗一遍,如果自己写的稿建议添加断句,断句以
。优先级最高。不然会出现很多句子特别长生成画面的情况,影响视频效果。字数控制建议在3000字一下,如果一个稿件字数很多建议拆分。 - type、en_name、cn_name,黄色部分 是你的项目文件目录
type为故事的类别,en_name是每个故事的文件夹,所有生成的数据会在这下面,cn_name是你这个文章的标题,用于生成word文档和视频结果用。 - status,绿色部分 用于管理任务,是一个下拉选项,如果这里选择已完成,则该行数据不会出现在生成任务重。
前期不会操作的建议一个一个来熟练之后批量操作。
前期不会操作的建议一个一个来熟练之后批量操作。
前期不会操作的建议一个一个来熟练之后批量操作。
SD重绘文件
整个项目包中的路径 不能有中文,不能有中文,不能有中文, 文件位置 task_menu/redraw.xlsx。

- type、en_name,部分是你已经生成好AI绘画的图片的路径。
- index 是你要重新绘制的图片的编号。
重绘需要执行对应的脚本,如果绘制满意的图片在这里吧对应的数据删行删除就可以了。
系统环境配置
整个项目包中的路径 不能有中文,不能有中文,不能有中文, 文件位置 config/authenticate.py。
用户名和密码
用户名和密码是购买脚本后管理员发放的,直接填写替换掉对应你的用户名和你的密码部分的内容就好。
UserData = {
'username': '你的用户名', # 填写你的用户名
'password': '你的密码', # 填写你的密码
}
ChatGPT3.5 API
请自行购买购买地址 ,这个是国内镜像,基本上调用1次2分钱还算比较合适。获取好API之后填写即可。
# 定义GPT接口
# 请自行购买购买地址 https://data.zhishuyun.com
GPT35_Token = "你的API"
SD绘画关键词
关键词分前缀和负面,用于控制你的画面风格和不想要的画面。自行在SD中测试好即可,前缀的意思是通过GPT35生成的关键词会加在tag_prefix后面,进行AI绘画。
# 绘画关键词前缀
tag_prefix = "best quality ,masterpiece, illustration, an extremely delicate and beautiful, extremely detailed ,CG ,unity ,8k wallpaper, "
# 绘画负面通用词
negative = "NSFW,sketches, (worst quality:2), (low quality:2), (normal quality:2), lowres, normal quality, ((monochrome)), ((grayscale)), skin spots, acnes, skin blemishes, bad anatomy,(long hair:1.4),DeepNegative,(fat:1.2),facing away, looking away,tilted head, {Multiple people}, lowres,bad anatomy,bad hands, text, error, missing fingers,extra digit, fewer digits, cropped, worstquality, low quality, normal quality,jpegartifacts,signature, watermark, username,blurry,bad feet,cropped,poorly drawn hands,poorly drawn face,mutation,deformed,worst quality,low quality,normal quality,jpeg artifacts,signature,watermark,extra fingers,fewer digits,extra limbs,extra arms,extra legs,malformed limbs,fused fingers,too many fingers,long neck,cross-eyed,mutated hands,polar lowres,bad body,bad proportions,gross proportions,text,error,missing fingers,missing arms,missing legs,extra digit, extra arms, extra leg, extra foot,"
微软TTS文本转语音
需要自己有一张VISA,不明白是啥自行百度,微软申请账号需要。
微软TTS文本转语音,这里必须选择eastus服务器,申请好API之后填写即可。
# 微软TTS APIkey
# 申请地址 https://azure.microsoft.com/zh-cn/products/cognitive-services/text-to-speech/
apiKey = "你的API" # 这里换成你的API
AccessTokenHost = "eastus.api.cognitive.microsoft.com" # 必须选择 eastus 服务器
如果自己没有办法申请自己的API,可有偿提供封装API,这里就无视即可。
微软语音选择
这部分代码不要动。
# 声音配置
name_dict = {'HiuGaai': 'zh-HK, HiuGaaiNeural', 'HiuMaan': 'zh-HK, HiuMaanNeural', 'WanLung': 'zh-HK, WanLungNeural',
'Xiaoxiao': 'zh-CN, XiaoxiaoNeural', 'Xiaoyou': 'zh-CN, XiaoyouNeural', 'Xiaomo': 'zh-CN, XiaomoNeural',
'Xiaoxuan': 'zh-CN, XiaoxuanNeural', 'Xiaohan': 'zh-CN, XiaohanNeural', 'Xiaorui': 'zh-CN, XiaoruiNeural',
'Yunyang': 'zh-CN, YunyangNeural', 'Yunye': 'zh-CN, YunyeNeural', 'Yunxi': 'zh-CN, YunxiNeural',
'HsiaoChen': 'zh-TW, HsiaoChenNeural', 'HsiaoYu': 'zh-TW, HsiaoYuNeural', 'YunJhe': 'zh-TW, YunJheNeural'}
# 语气
style_dict = {'兴奋': 'advertisement_upbeat', '高音调': 'affectionate', '厌恶': 'angry', '热情': 'customerservice', '冷静': 'calm',
'轻松': 'chat', '愉快': 'cheerful', '忧郁': 'depressed', '轻蔑': 'disgruntled', '纪录片': 'documentary-narration',
'犹豫': 'embarrassed', '关切': 'empathetic', '钦佩': 'envious', '希望': 'excited', '紧张': 'fearful',
'愉悦': 'friendly', '温和': 'hopeful', '优美': 'lyrical', '朗读': 'narration-professional',
'阅读': 'narration-relaxed', '新闻': 'newscast', '通用': 'newscast-casual', '权威': 'newscast-formal',
'快节奏': 'poetry-reading', '悲伤': 'sad', '严肃': 'serious', '高声': 'shouting', '赛事': 'sports_commentary',
'精彩': 'sports_commentary_excited', '柔和': 'whispering', '疯狂': 'terrified', '无情': 'unfriendly'}
role_dict = {'女孩': 'Girl', '男孩': 'Boy', '年轻的成年女性': 'YoungAdultFemale', '年轻的成年男性': 'YoungAdultMale',
'年长的成年女性': 'OlderAdultFemale', '年长的成年男性': 'OlderAdultMale', '年老女性': 'SeniorFemale', '年老男性': 'SeniorMale'}
gender_dict = {'男': 'Male', '女': 'Female'}
上面的格式是这样的,大括号{ }中以每个,断开来看,: 前面是你要复制的信息,后面是对应这个信息的解释。
例如想使用云希的声音在name_dict中复制

到下面如何修改在这里这里,其他的依次类推,目前支持自定义修改,但是有的声音配置可能不支持,比如云希不会有女人声音这样,具体慢慢尝试或者百度即可。
# 设置配置,这里自行选择,有的可能无法生成,尽量选择通用方法是
# 发音人声音
name = name_dict["Yunxi"]
# 说话风格
style = style_dict["纪录片"]
# 性别
gender = gender_dict["男"]
audio_rate = '1.4' # 生成音频的速度 1.4 表示1.4倍,修改''中间的数字
剪映配置路径
例如我的路径是这样的

# 剪映需要的完整路径
full_path = "H:\\NovelAI\\User Edition\\sell_NovelAI_txt2video"
这个配置不对,剪映的配置文件会出错。
使用方法
【通用】step1_切分文本生成excel数据.bat
执行该脚本是将task_menu/task.xlsx下的未完成的文章进行断句操作。
会在data_story/下生成你表格中定义的type和cn_name文件夹,在该项目下会自动生成一个txt_excel文件夹,里面有个excel文件打开,之后只有一列数据,应该是这样的。
如果已经执行完后面几步误点了第一步这个脚本的话,会把原来的数据覆盖掉,意味着就要重新来一遍。
【通用】step2_ChatGPT35生成需要SD绘画需要的关键词.bat
需要用自己申请的API执行,次数不够请及时充值。
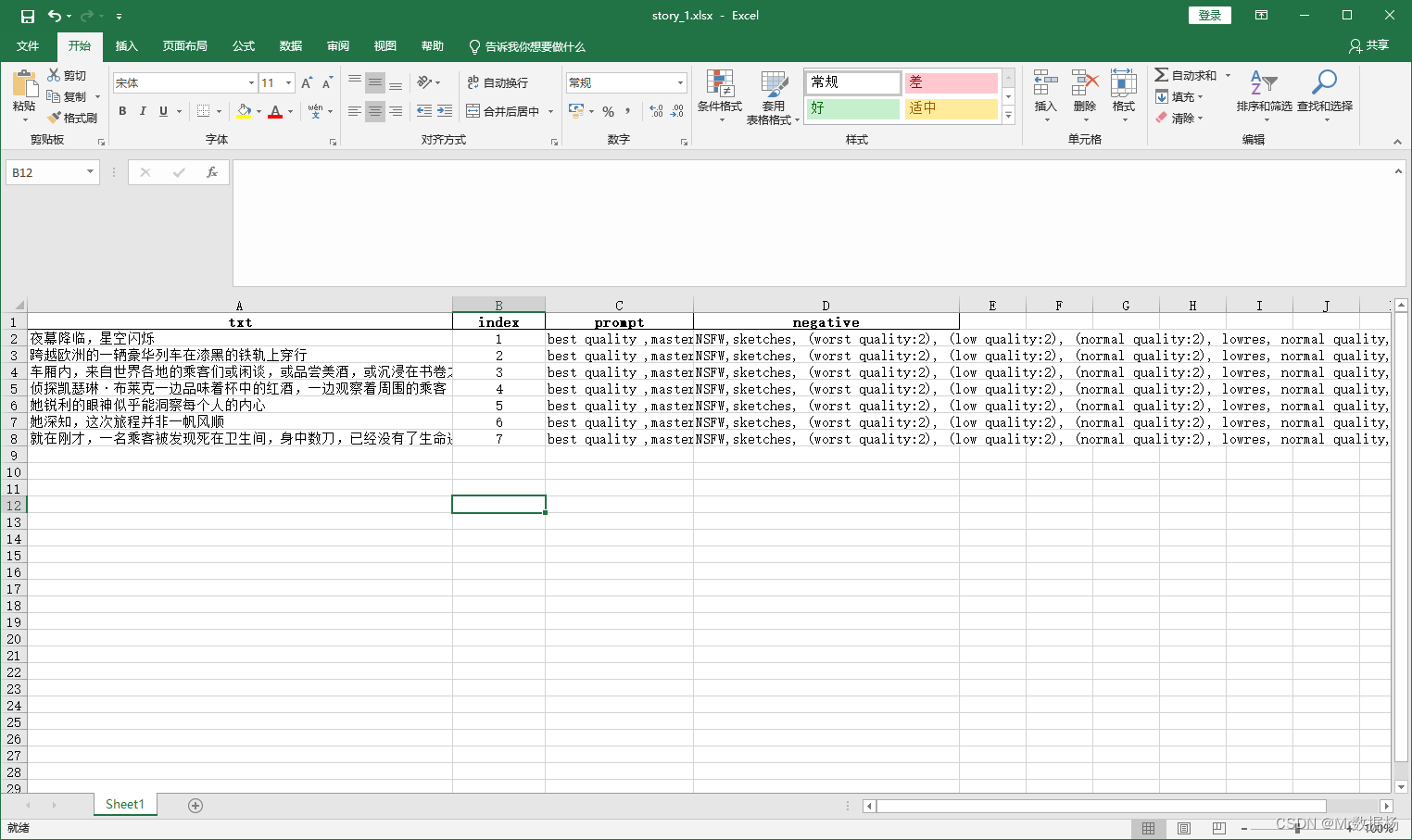
执行该脚本是将你生成项目也就是故事的文件夹每句话通过GPT生成关键词,正面和负面以及索引,其中正面词自行设置前缀,负面词是通用的一个,如果生成不满意可以自行在表格里修改。
生成完的数据表单是这样的就可以执行下一步。
【通用】step3_使用TTS生成语音.bat
需要在配置文件中使用你的微软文字转语音API,使用微软的API生成语音文件。
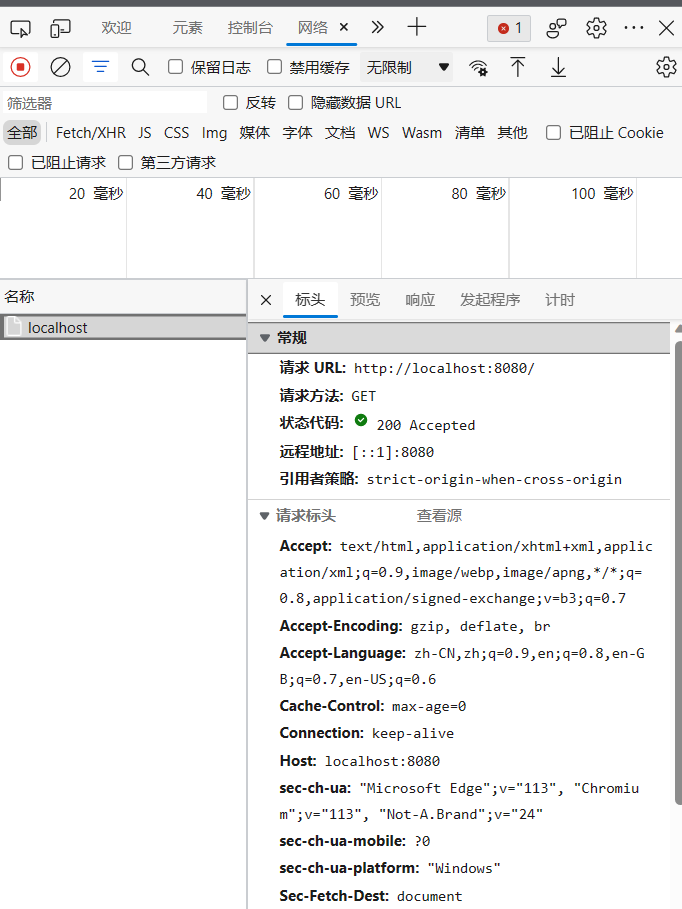
会在你生成项目也就是故事的文件夹生成2个目录audio_wav,each_audio_wav,确保里面的音频文件都有声音即可,在生成界面会看到返回结果为200,即可。
在文件夹下会生成对应的音频文件,脚本设置的已经生成的会跳过,如果音频文件没有声音请删除重新执行脚本。


【定制】step3_1_使用TTS生成语音.bat
使用方法同 【通用】step3_使用TTS生成语音.bat 。
【通用】step4_SD绘画,开启SD端口默认7680.bat
需要提前打开Stable Diffusion环境,并开启API模型。启动命令行显示这样就表示可以了。
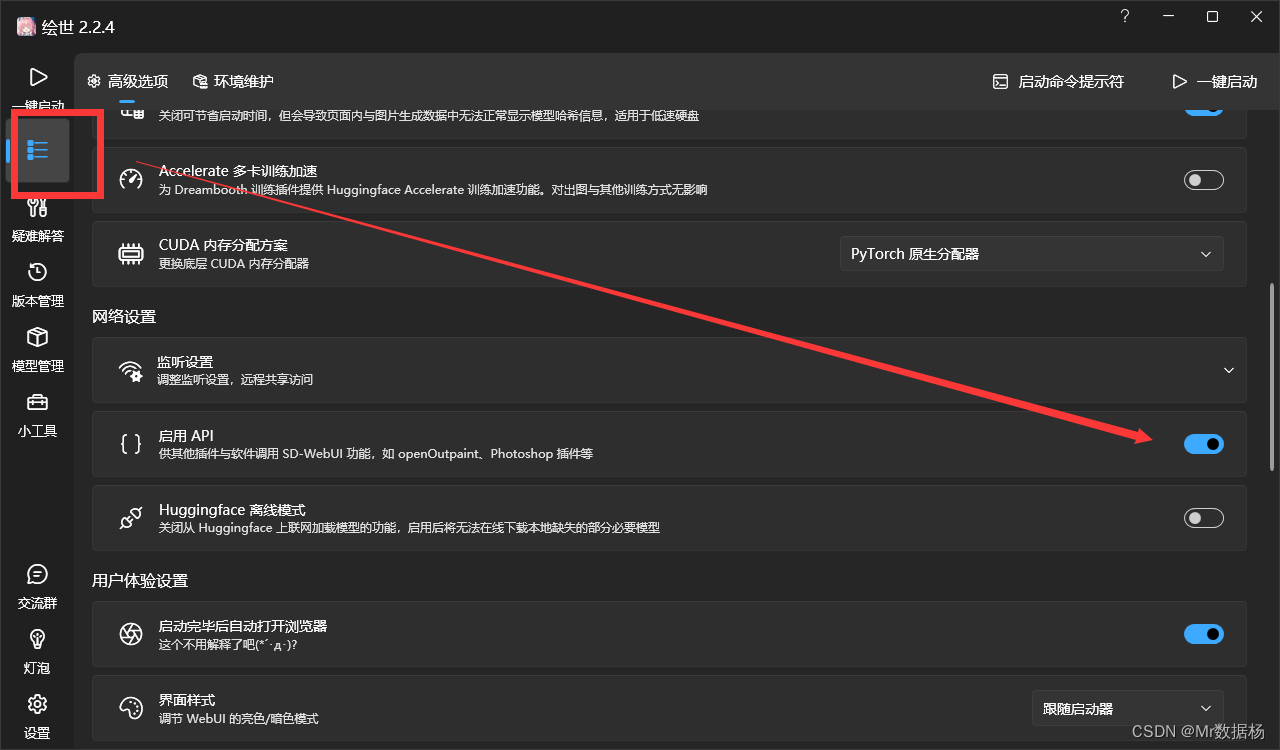

在网页上选择你需要的模型,之后页面就可以关掉了。

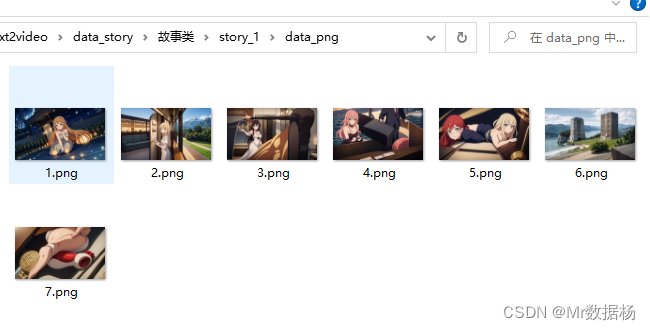
启动脚本即可,会自动的进行绘画,基于前面API生成的关键词。生成图片在data_story/下生成你表格中定义的type和cn_name文件夹下生成data_png图片文件。
【通用】step4_1_SD重绘,开启SD端口默认7680
打开文件位置 task_menu/redraw.xlsx,这里的数据要和task_menu/task.xlsx对应。
重画那个写那个,后面的index值是图片的编号,也就是是你要重新绘制的图片。
【通用】step5_批量合并视频,依次合成.bat
以上图片和音频都生成好了直接点击该脚本合成视频。
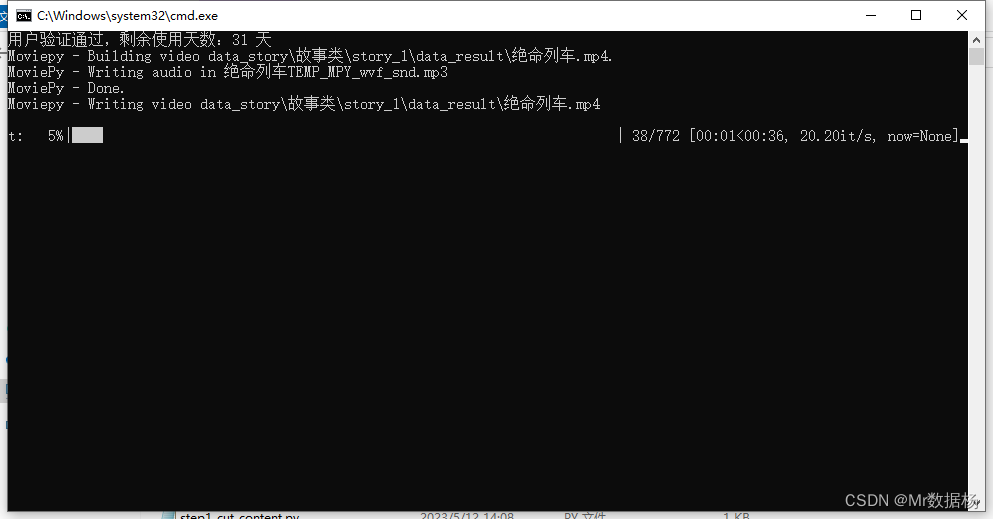
【定制】step5_1_批量合并视频,机器不好一次少弄几个.bat
这个脚本属于付费,批量合成,机器不好的不要选,用于一次合成N个视频,不需要一个一个等待合成。
回头补个图。
【通用】step6_随机挑选图片成视频封面.bat
执行该脚本会在data_story/下生成你表格中定义的type和cn_name文件夹下生成data_png图片文件中随机挑选一张作为视频封面,保存在data_result中。
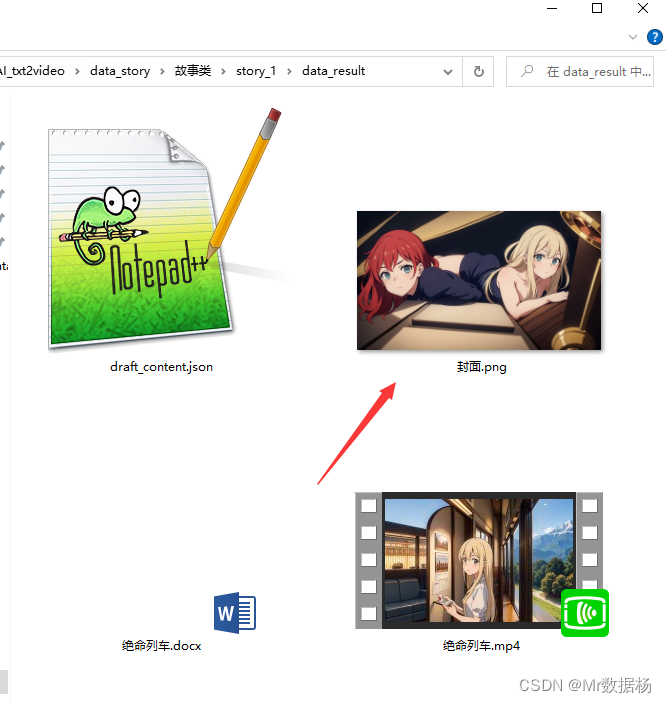
【通用】step7_生成图文word文件.bat
执行该脚本会在data_story/下生成你表格中定义的type和cn_name文件夹下生成data_result生成一个 图文适配的word文档,自动化生成,如果不满意手动调整。
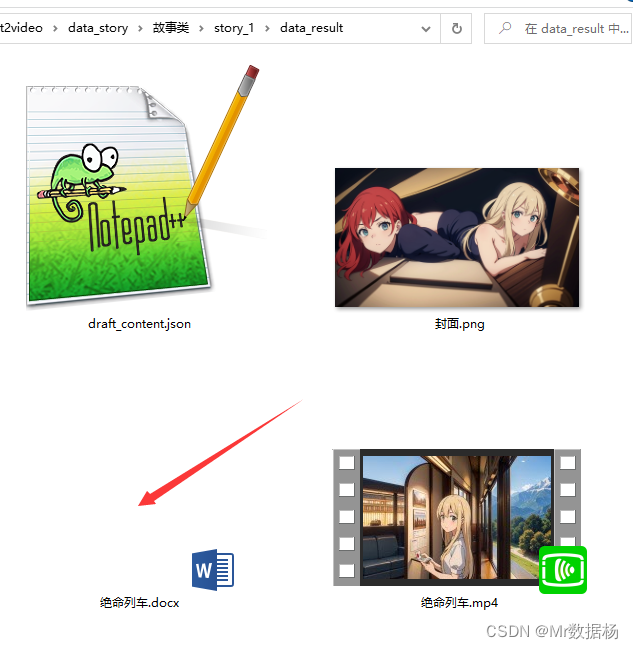
【通用】step8_生成剪映可编辑文件.bat
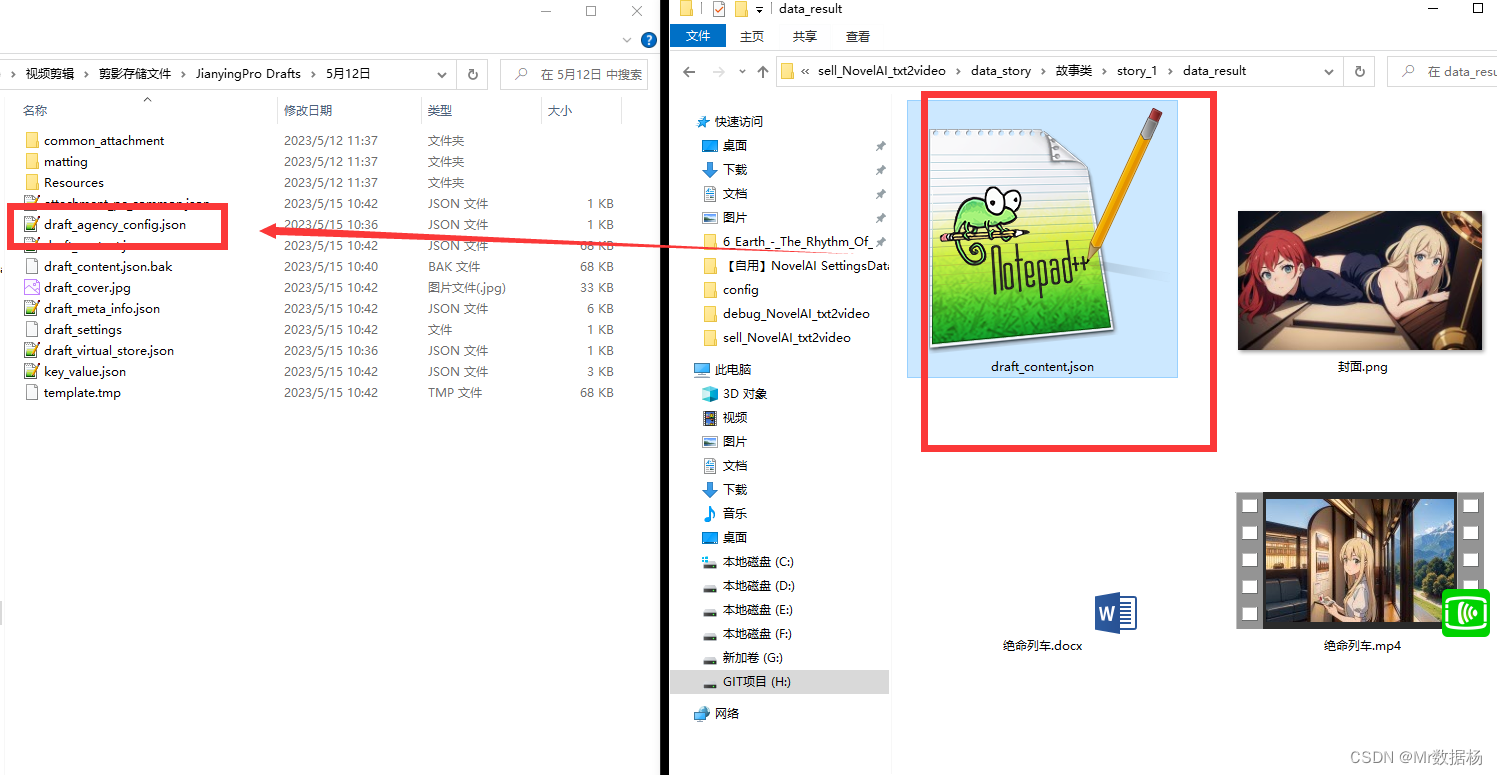
执行该脚本会在data_story/下生成你表格中定义的type和cn_name文件夹下生成data_result生成一个剪映的配置文件draft_content.json,这个文件仍到你剪映的项目中打开就会看到图文适配音频的工程时间轴,方便后期二次加工。