Datawhale干货
作者:李薇,上海人工智能实验室
前言
今天,我将向那些希望深入了解大模型的同学们,分享一些关于大模型时代的数据变革的知识。作为上海人工智能实验室OpenDataLab的产品主管,我会介绍我们在开放数据和大模型数据方面的工作,希望这些信息能对你们有所帮助。
大模型的发展与研究方向
首先,我简要介绍一下大模型的发展和研究方向。大模型之所以被称为"大",主要是因为它在参数规模上发生了巨大的变革。在大模型领域,一个重要的研究方向是"scaling law",即模型效果与模型的参数量、数据量和计算量之间存在一个平滑的幂律发展规律。
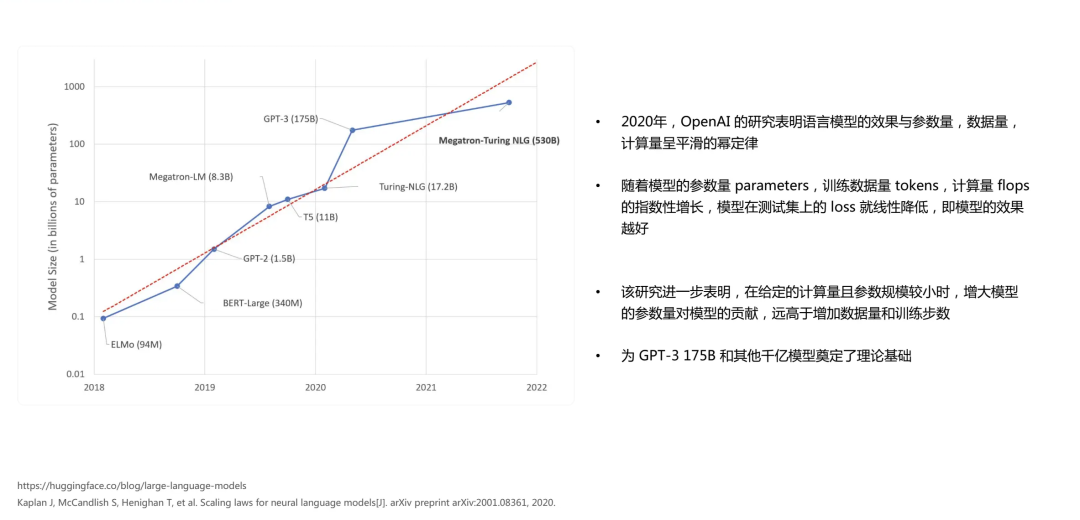
据此规律,随着模型参数量和训练数据量(通过token计算)的指数性增长,以及模型计算量的增加,模型在测试集上的loss会指数性地降低,模型效果就会越好。这个研究也表明,参数规模是模型能力的主要驱动力。在给定的计算量且参数规模较小的情况下,增大模型的参数量对模型的贡献远远高于数据量和训练的步数。这项于2020年由OpenAI进行的研究对后续大模型的训练方向产生了深远影响,包括后来的GPT-3等模型也得到了相应的验证。
随后,更多的研究机构加入到了大模型参数规模的探索中。例如,DeepMind在2022年进行了比OpenAI更加系统性的研究。他们通过定量实验计算出,模型训练的Loss在模型参数量和训练数据量的变化下,存在一个最优的平衡点。与GPT-3等千亿级模型对比,这些模型并没有达到其理论的最优点,可能只达到了百亿级模型的理论效果。
因此,DeepMind推出了Chinchilla模型,其参数规模是Gopher的四分之一,但训练数据量却是Gopher的四倍。在参数规模较小但训练量大的情况下,整个模型的效果优于参数规模大但数据量不足的模型。这也验证了我们应均衡地扩大参数规模和数据量的重要性。
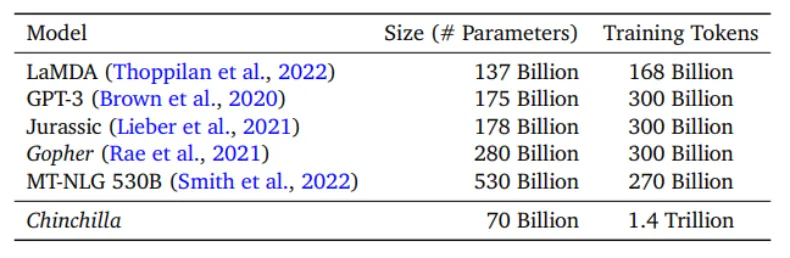 图 Chinchilla、Gopher等语言模型的参数数量,训练数据量 (来源:Deep Mind)
图 Chinchilla、Gopher等语言模型的参数数量,训练数据量 (来源:Deep Mind)
确实,我们可以看到大模型研究的发展趋势是寻求参数规模和数据量的最佳平衡。Meta公司在2023年推出了百亿级别的模型LLaMA,它的训练数据是GPT-3的4.7倍。该模型在各种下游任务上的表现均优于GPT-3。在训练过程中,Meta试验了从70亿到650亿不等的参数量,并发现在训练数据接近或超过万亿token时,下游任务的效果仍在提升。
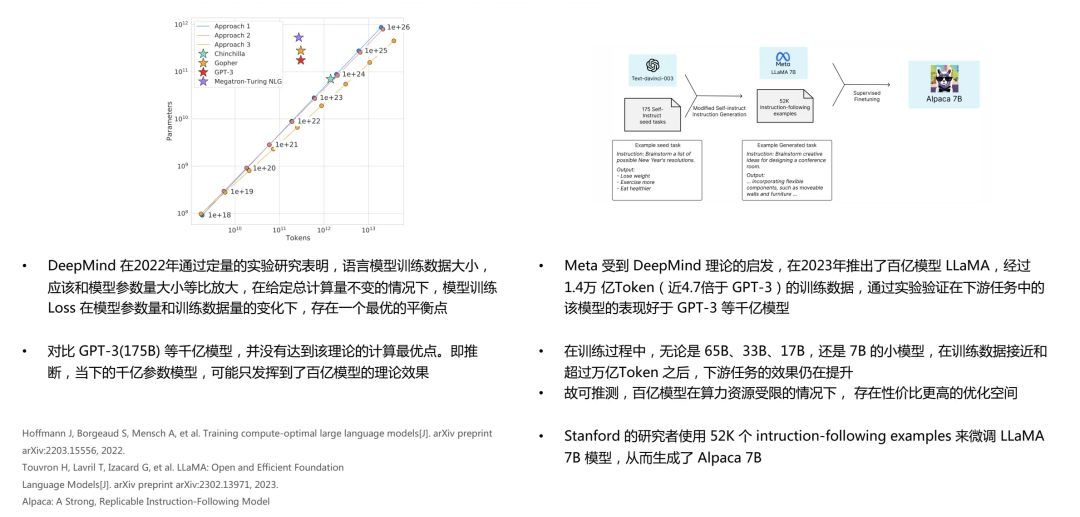
这表明,在有限的算力资源下,百亿级别的模型仍存在优化空间,提升训练数据量可以显著提高模型效果。最近,斯坦福通过增加微调数据的方式,在LLaMA 7B模型的基础上改进出了Alpaca 7B模型,这种新的方法为后续的研究机构提供了新的思路。
总的来说,大模型的研究并不仅仅在于提升模型的参数规模,更多的数据和更好的训练方式也是关键。我们也期待看到更多新的模型和新的研究方法来推动大模型研究的发展。
大模型数据组成
基于模型的参数量,越来越多的研究者开始深入研究大模型数据。其中,大模型的主要研究对象是预训练模型。关于用于预训练的数据,Alan D. Thompson进行了详尽的研究。他研究的对象包括了从2018年到2022年这一阶段中,一些知名的大模型,如GPT系列(从GPT-1到GPT-4),以及Gopher等模型。他详细分析了这些模型的训练数据的配比和组成。
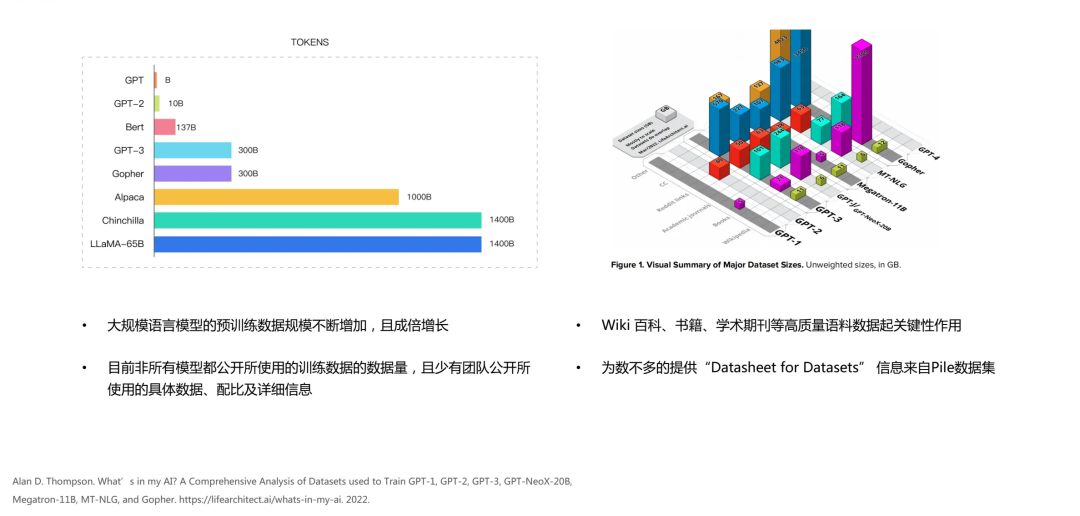
如右图所示,大模型的重要组成部分包括百科数据(如wiki)、书籍数据(如books.)、期刊数据(如general)以及社交新闻等。其中,占比最大的是通过Chrome爬取的网页数据(CC)。
从这些大模型的数据组成中,我们可以发现许多相似性。这为后续的大模型研究奠定了良好的基础。我们也可以看出,在大模型的发展过程中,不断有新的大模型出现,预训练的数据规模也在成倍增长。
尽管这些模型的研究者声称他们使用的训练数据是公开的,但大多数研究机构或团队并未公开声明他们的模型使用的数据来源,包括每个模型使用的token数量,不同数据类型的配比以及内容的细节。只有部分公开的信息可以为我们研究数据提供参考。
基于上述研究,我们发现在GPT系列模型的演进过程中,其数据配方也在变化。GPT-1主要使用的是书籍类语料,如Books等,这些都是人们日常书面语的重要来源,其质量也相对较高。而GPT-2主要使用新闻类数据(如Reddit),整体形式较为正规,但包含了许多社交数据,如人们日常的口语交流方式。然后到了GPT-3,其预训练数据规模翻了数十倍,并且数据配比更为细化和多样化,包括Reddit links、各种books、百科数据、Wiki数据,以及WebText2和Common Crawl等网页数据。其中最大的部分是Common Crawl,它经过一定量的高质量筛选,将网页上的语料基本都输入到了GPT-3中,因此我们才能看到如ChatGPT等惊人的表现。
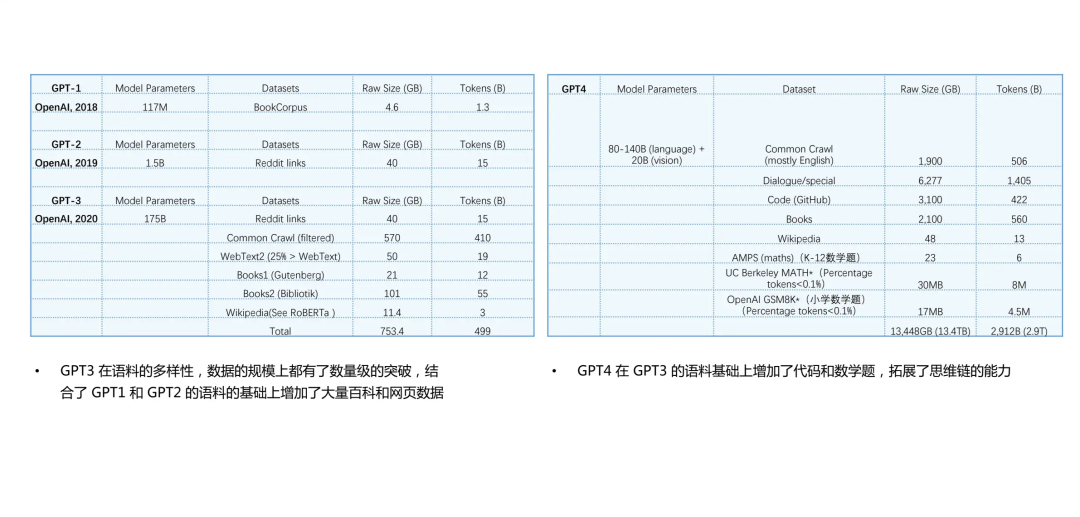
到了GPT-4阶段,我们可以看到它加入了一些GPT-3所没有的数据,例如对话形式的数据,GitHub上的代码形式的数据,以及特别加入的一些小学和大学的数学题。这是GPT-4在GPT-3的大语料库上的突破。
可以看出,通过引入代码和数学题的语料,大大增强了模型的思维链条的能力,使其在推理,包括对数学应用的解答方面都有了高质量的提升。我们也注意到了Pile数据集,它是一个非常知名的用于大模型预训练的数据集。它的整体形式我们可以看到,其实是包含了几十种不同类型的数据的一个数据集合集。

我们对这些数据进行了一些研究和分析,可以通过不同的层次和维度对其进行细分。从ChatGPT的语言能力,包括文本能力来看,这些都与其预训练的数据能力密切相关。在整个预训练的数据中,可以大致分为以下几类语料:
第一类是对话形式,包括用户之间的多轮或单轮对话,以及正式或非正式的问答形式;
第二类是社区论坛,论坛的文本数据多样性很大,因为不同的人发表的内容,包括他们的说话风格都是不同的,这增加了语言能力的多样性;
第三类是学校和机构的课程教材,这些数据可以为ChatGPT提供对知识性领域的文本的深入理解;
第四类是书籍和百科类数据,这是最常见的数据类型;
第五类是公文,这是一种特殊类的文本,但也是大模型语料的一部分;第六类是论文,这也是一种特殊形式的文本语料;
最后一类是新闻和娱乐媒体的新闻报道,这也是一种独立的语料类型,可以作为大语言模型的语料输入。
OpenDataLab介绍
OpendataLab是一个开放的数据平台,致力于从三个方面为大型模型提供数据支持。首先,我们为算法模型提供开放的数据资源。我们的平台上有大量的数据和语料,用户可以在这里找到他们需要的信息。我们提供灵活的数据支持,并优化了下载速度,以便用户在国内更快地获取数据。此外,我们还提供命令行接口,以便用户更快地获取相关的开源数据集。

数据集
目前,我们的平台已经拥有了超过5400个公开的数据集,总容量达到80TB。我们在平台上对数据进行合规性检查,确保所有数据的版权或许可信息清晰明了。此外,我们还对平台上的数据进行分类,包括标注类型、任务类型、数据类型以及适用的应用场景,以便用户更好地找到他们需要的数据。
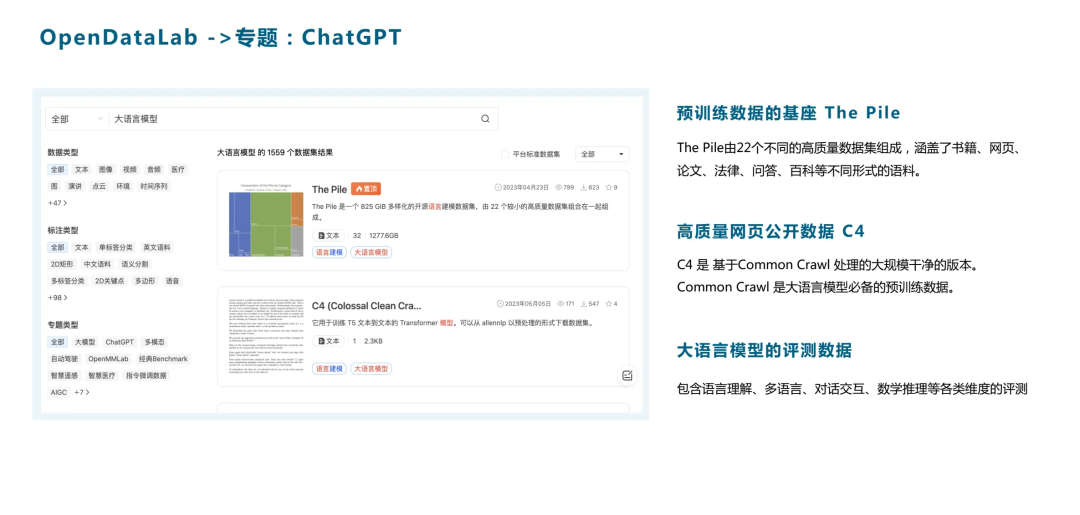
我们希望能够支持国内大模型的训练和微调。为此,我们在OpendataLab上设立了一些专题性的数据板块。我们提供大语言模型预训练的基础语料,并在我们的筛选栏上设置了搜索和筛选功能,用户可以一键查询到所有与大模型ChatGPT相关的语料。
目前,我们已经拥有了超过1000个适用于大模型的文本类语料,包括最知名的The Pile数据集,它涵盖了22个不同领域的高质量数据和语料,以及公开的高质量网页数据。例如C4数据集,这是一个经过Common Crawl处理的高质量大规模数据集,被广大GPT模型用户用作语料基础。此外,我们还收集了大模型相关的评测数据。目前,平台上包含了数十个针对语言维度的评测,用户可以在我们的平台上获取和下载。
多模态预训练和评测数据
我们也正在收集最前沿的多模态预训练和评测数据。这些数据可用于生成场景如AIGC,包括图文、视频文本等多模态大模型的研究。我们的平台上包含了规模最大的公开图文数据集LAION-5B,其包括了80TB的图片数据和58.5亿的图文配对。这些数据已经过Line团队的处理,非常适合科研研究。我们也有SA-1B数据集,这是最近非常知名的Segment Anything模型开放的最大的图像分割数据集,它包含了1100万张图片和11亿个mask数据,非常适合视觉多模态大模型的研究,特别在图像分割领域有广泛应用。
同时,我们也汇集了多模态领域最全的所有Benchmarks相关数据。除了预训练的数据,我们还包含了微调数据。如众所周知,ChatGPT-3大模型的能力在很大程度上是通过指令微调展现出来的。

我们收集了现有的公开的指令微调数据,包括Databricks dolly 15K,以及OpenAIAssistant最近上线的开放数据和Firefly的高质量中文指令数据。我们也对这些微调的指令数据进行了标准化,这样可以通过一键DataLoader将不同的指令合并进行微调训练,极大地方便了数据的获取和处理。
另外,OpendataLab也提供了一系列数据相关的工具。在大模型数据采集上,我们在数据获取过程中开发了一些工具并提供给开发者,以支持更加灵活的数据获取方式。例如,对于大规模数据集如LAION-5B,我们在GitHub上开放了下载工具,用户可以更灵活地分布式下载所有的LAION-5B原图数据。对于Segment Anything数据集,用户也可以通过一行代码更快地获取到数据。
数据采集工具
同时,我们正在研发可以支持大模型相关的数据采集工具。整个平台能够提供更灵活的数据标签和采集形式配置,支持人机实时对话、在线模型评测以及不同工具配置模型输出。我们的工具也可以支持图文采集,通过灵活的配置对图文对进行数据采集并进行审核。在视频工具上,我们可以支持视频截取和视频描述,以支持多模态和生成模型的数据采集和标注需求。

智能标注工具
此外,我们已开源了LabelU,一款智能标注工具,能够满足大部分二维数据标注需求,包括后续微调场景的细分领域数据标注,以及不同形式的图片或文本标注。
数据描述语言
同时,我们正在研究一些通用的数据标准语言,以支持大模型的数据需求。事实上,数据在大模型中有许多痛点,无论是GPT或DeepMind等团队,都需要一个大的数据团队来进行数据采集、处理、清洗等耗时费力的工作。OpendataLab也会在数据研究过程中进行数据标准化,通过统一的格式提供给开放平台,并开源我们的处理工具,包括数据转换、清洗等,使得开放平台的用户可以更快速地进行数据准备。

我们还提出了一种创新的数据描述语言,叫做Dataset Description Language (DSDL)。它具有一定的通用性,通过统一的方式描述整个数据集,能够覆盖不同领域和方式的数据集,使数据更便于互联互通。基于JSON的形式,DSDL能更好地解耦媒体图片,特别在多模态领域,其标注文件可以支持轻量化的标注分发。并且,它具有一定的扩展性,可以更好地支持不同类型的数据。我们最近在OpendataLab上线了近百个标准的数据标注。
平台的标准数据集可以通过筛选方式查找,我们会提供DSDL的标准包,用户下载后可以通过我们的说明和原始的raw data一起使用。通过统一的DataLoader,可以将不同类型的数据集成一起进行大模型的训练。以往大模型的语料来源多样,格式各不相同,通过DSDL的标准化后,可以一键将数十个甚至上百个相关语料进行统一训练。这也能够跨多模态进行多任务数据集规范,更快地支持大模型的训练和推理。
我们也期待有更多的同学能加入到大模型研究的行列中来,共同推动这个领域的发展。如果大家有任何问题或者想要进一步探讨的话题,都可以随时向我们提出。

整理不易,点赞三连↓