目录
简介
实现方法
效果及局限
参考资料
简介
MiniGPT-4 是前段时间由KAUST(沙特阿卜杜拉国王科技大学)开源的多模态大模型,去网站上体验了一下功能,把论文粗略的看了一遍,也做个记录。
论文摘要翻译:最近发布的GPT-4展示了非凡的多模态能力,例如直接从手写文本生成网站,识别图像中的幽默元素。这些特性在以前的视觉语言模型中很少被观察到。我们认为GPT-4先进的多模态生成功能的主要原因在于使用了更先进的大型语言模型(LLM)。为了验证这一现象,我们提出了MiniGPT-4,它只使用一个投影层将冻结的视觉编码器与冻结的LLM Vicuna对齐。我们的研究结果表明,MiniGPT-4具有许多与GPT-4类似的功能,如生成详细的图像描述以及通过手写草稿来创建网站。此外,我们还观察到MiniGPT-4中的其他涌现能力,包括用给定的图像创作故事和诗歌,为图像中显示的问题提供解决方案,根据食物照片教用户如何烹饪等。在我们的实验中,我们发现只使用原始图像-文本对进行预训练,会产生缺乏连贯性的包括重复和碎片句子的不自然的输出。为了解决这个问题,我们在第二阶段创建了一个高质量、对齐良好的数据集,以使用对话模板微调我们的模型。事实证明,这一步骤对于增强模型的生成可靠性和整体可用性至关重要。值得注意的是,我们的模型计算效率很高,因为我们只使用大约500万对对齐的图像-文本对来训练一个投影层。我们的代码、预训练模型和收集的数据集可在Minigpt-4 获取。
实现方法
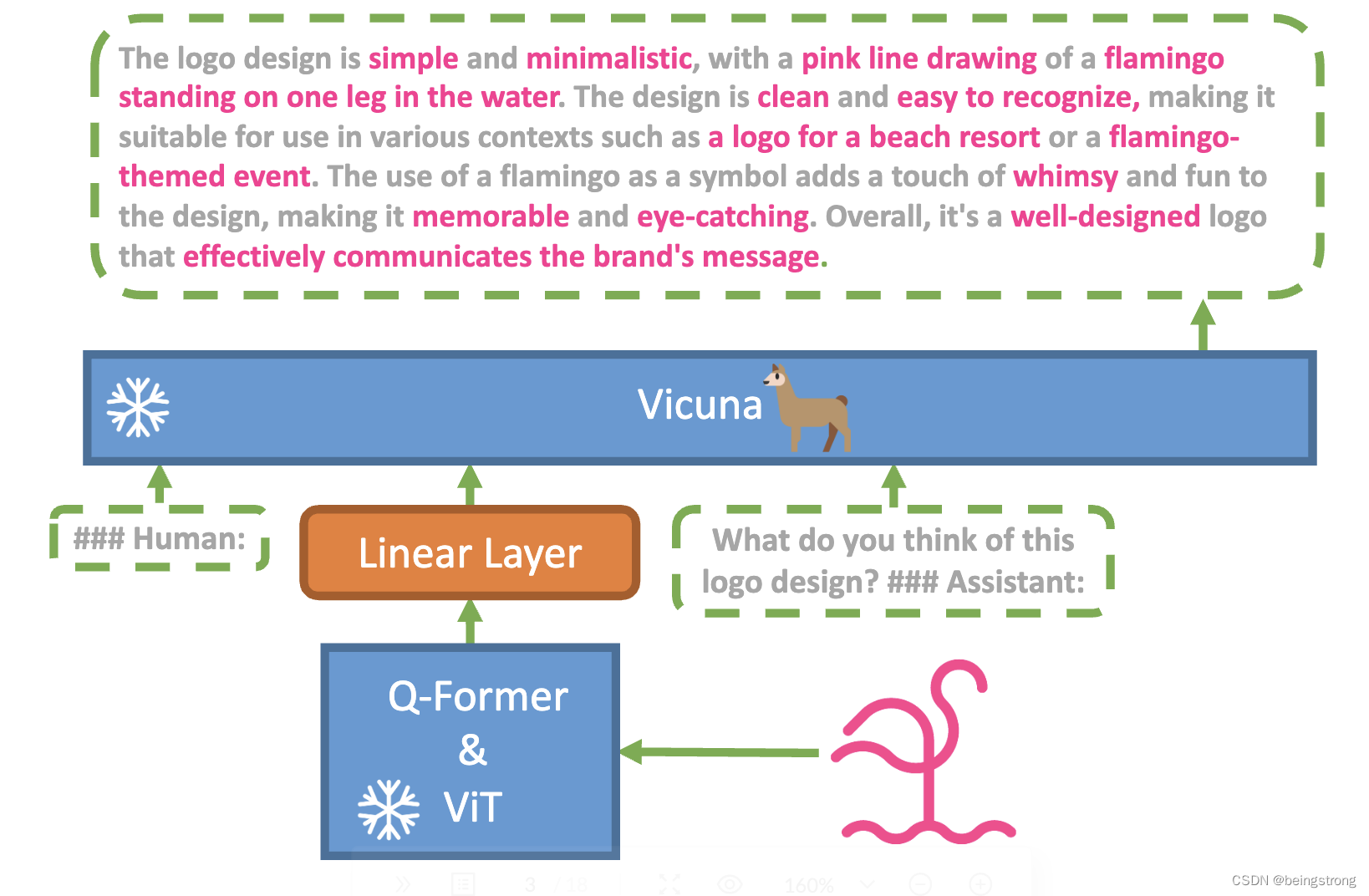
Minigpt-4的框架如上图,它的主要目的是为了对齐预训练的视觉编码器和先进的大语言模型(LLM)。 使用大语言模型Vicuna来做语言编码器,视觉感知使用BLIP-2一样的视觉编码器:ViT + 预训练Q-Former。使用一个线性投影层将视觉编码器和LLM关联起来,也就是视觉编码器的结果经过线性投影层之后作为Vicuna的输入。Minigpt-4的训练有两个阶段:
阶段一:
- 预训练视觉编码器和LLM的权重都是冻结的,只有线性投影层被训练
- 使用组合数据集来训练,数据集由Conceptual Caption、SBU、LAION 构成,共约500万的图像-文本对。
- batch size 为256,共训练了20000步, 整个过程使用4个 A100(80GB) GPU,共花了10个小时
- 阶段一训练完的模型能够理解图像的含义,但是生成的连贯的描述文本有困难,会出现重复单词或句子,不相关的内容等。
因为经过阶段一的训练后模型生成效果不好,所以作者们构建了一个数据集:
- 从Conceptual Caption 数据集中随机选择了5000张图片,首先使用阶段一的模型来对这些给定的图片生成详细描述,设计了如下与Vicuna对话形式一致的prompt,prompt 中的<ImageFeature>是由前面提到的线性投影层生成的。
###Human: <Img><ImageFeature></Img> Describe this image in detail. Give as many details as possible. Say everything you see. ###Assistant:
-
为了识别到不完整的句子,会检查模型生成的句子的token数是否超过80,如果没有超过80,会使用额外的prompt: "###Human: Continue ###Assistant:" 让模型扩展生成的内容,将两部分prompt得到的结果拼成一个更详细的图像描述。
-
前面也提到阶段一后的模型效果不理想,为了去掉错误信息,使用ChatGPT来对生成的描述进行完善,对ChatGPT使用的prompt 如下:
Fix the error in the given paragraph. Remove any repeating sentences, meaningless characters, not English sentences, and so on. Remove unnecessary repetition. Rewrite any incomplete sentences. Return directly the results without explanation. Return directly the input paragraph if it is already correct without explanation.
-
执行上面的后处理步骤后,再通过人工确认每个图像描述的正确性以保证质量。主要是检查生成图像描述是否是想要的格式,也将chatGPT没有检测到的冗余单词和句子给去掉,最终生成了3500个满足要求的图像-句子对。
阶段二:
-
使用创建的数据集来finetune 阶段一的模型,使用了如下模板的prompt, 里面的<instruction>是从定义好的指令集里随机选择的,指令集是类似于“ Describe this image in detail”的 “Could you describe the contents of this image for me” 的变化形式。
###Human: <Img><ImageFeature></Img> <Instruction> ###Assistant:
- 作者强调对上述text-image prompt 没有计算回归损失 (do not calculate the regression loss for this specific text-image prompt)
- 经过阶段二后,MiniGPT-4可以生成更自然和可靠的回应,并且这个finetune 过程非常高效,batch size 为12, 训练400 步,使用一个A100 GPU 只需要训练7分钟
效果及局限
miniGPT-4 可以达到的效果(论文图2-图13展示了案例):
- 生成详细的图片描述
- 识别图片中有趣的点,比如猫穿了衣服躺着的照片
- 识别图片中不寻常的点,比如仙人掌不会出现在冰川之类
- 从手写文字生成网站
- 识别图片中的问题并给出解决方案
- 根据图片内容创造诗歌和rap歌曲
- 为图片写故事
- 为图片中的产品打广告
- 识别出图片中的名人
- 提供有洞察的图片评论
- 抽取跟图片相关的事实
- 根据给定的照片,教用户如何做菜
局限性:
- 语言幻想,这个主要是由于LLM模型的局限性导致的,可能通过在更高质量的图像文本对或者对齐更好的LLM来减轻。
- 不充足的感知能力,对识别图像中的文字、空间定位等有困难。可能因为这几个因素:1. 缺少充足的对齐的关于空间信息和文本注释的图像-文本对,通过更多数据集来减轻; 2. 视觉编码器中的Q-former可能会丢失一些关键特征,替换更强的视觉感知模型来提高效果; 3. 只使用一个投影层可能没有足够的空间来学习视觉-文本对齐信息。
参考资料
1. 论文链接 https://arxiv.org/abs/2304.10592
2. github: GitHub - Vision-CAIR/MiniGPT-4: MiniGPT-4: Enhancing Vision-language Understanding with Advanced Large Language Models