01
背景
在《SRE: Google运维解密》一书中作者指出,监控系统需要能够有效的支持白盒监控和黑盒监控。黑盒监控只在某个问题目前正在发生,并且造成了某个现象时才会发出紧急警报。“白盒监控则大量依赖对系统内部信息的检测,如系统日志、抓取提供指标信息的 HTTP 节点等。白盒监控系统因此可以检测到即将发生的问题及那些重试所掩盖的问题等”。为了完善系统的白盒监控,会员团队基于 Prometheus + Grafana 开源组件构建了监控告警平台。最近一段时间在查询监控指标时遇到了性能瓶颈,表现为一些监控页面的图表加载特别慢,查询近7天的监控数据就会失败,极大的降低了开发人员的工作效率。
02
排查
初步排查
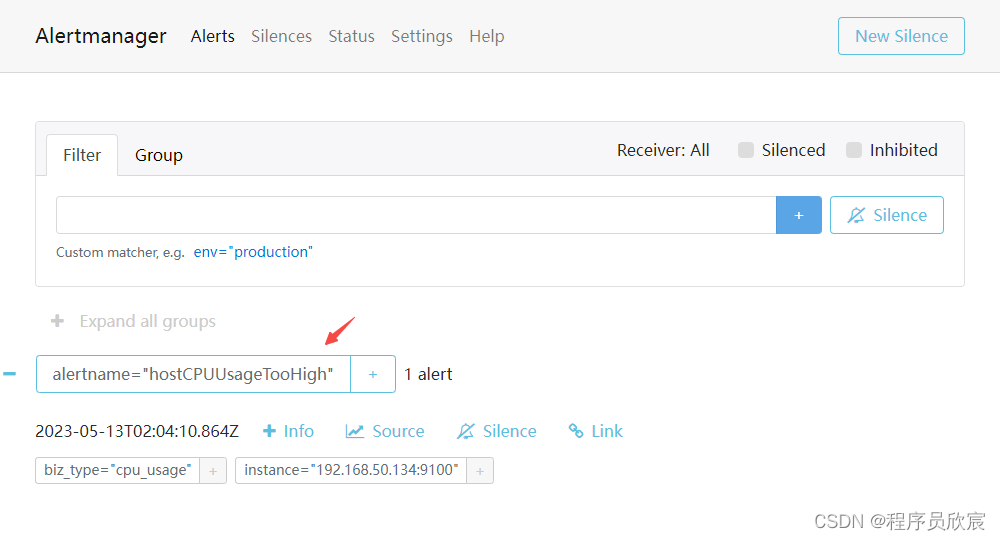
选取其中一个加载失败的监控页面,查询近7天的监控数据,通过浏览器的开发者工具观察到的指标数据查询接口响应耗时如下图所示:
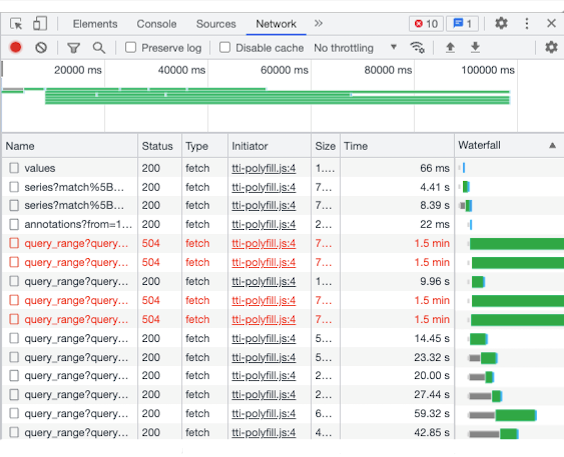
分析指标数据查询接口和监控图表的对应关系后发现,监控图表加载失败是查询接口超时所导致的。使用超时的指标查询语句直接查询 Prometheus,即便将采样步长调高到40分钟,查询响应耗时依然有48秒之多。说明查询的主要耗时都用在 Prometheus 的查询处理上。
Prometheus查询处理流程分析
想要继续弄清楚 Prometheus 的查询处理为什么需要耗时这么久,我们需要简单了解一下 Prometheus 的查询处理流程。Prometheus 使用了一个基于标签(label)、值和时间戳的简单数据模型,这些标签和样本一起构成了数据序列(series),每个样本都是由时间戳和值组成。
 Prometheus 将这些数据存储在其内部的时间序列数据库中(Prometheus 也支持外部存储系统)。Prometheus 的数据库被划分为基本的存储单元,称为 block,其中包含一定时间范围(默认2小时)的数据。block 的结构如下图所示:
Prometheus 将这些数据存储在其内部的时间序列数据库中(Prometheus 也支持外部存储系统)。Prometheus 的数据库被划分为基本的存储单元,称为 block,其中包含一定时间范围(默认2小时)的数据。block 的结构如下图所示:
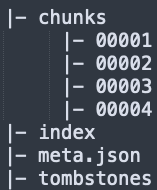
block 中最重要的两个组成部分是 chunks 和 index。chunks 中保存的是特定序列在一定时间范围内的采样集合,一个 chunk 只包含一个序列的数据。index 中保存的是 Prometheus 访问数据使用的索引信息。在 index 中保存着两种类的索引:postings index 和 series index。
postings index:保存着标签与包含该标签的序列之间的对应关系。例如,标签 __name__ ="logback_events_total" 可以被包含在两个序列中,logback_events_total {job="app1", level="error"}和 logback_events_total {job="app2", level="error"}。
series index:保存着序列和 chunk 之间的对应关系。例如,序列 {__name__=”logback_events_total”, job=”app1”, level="error"} 可能保存在00001和00002两个 chunk 里。
block 中还包含了一个 meta.json 文件(保存 block 的元数据信息)和 一个 tombstones 文件(保存已经删除的序列以及关于它们的信息)。
Prometheus 的查询处理通常包含以下五个基本步骤:
1、通过查询的时间范围确定对应的 block。
2、通过 postings index 确定与标签匹配的序列。
3、通过 series index 确定这些序列对应的 chunk。
4、从这些 chunk 中检索样本数据。
5、如果查询中包含操作符、聚合操作或内置函数,还需要基于样本数据进行二次计算。
详细排查
了解了 Prometheus 的查询处理流程后,我们可以得出以下结论:
1、查询的时间范围越大则耗时也就会越多,因为查询时间范围越大则涉及的 block 也会越多。
2、标签的值越多则查询耗时也就会越多,因为标签每增加一个值就会生成一个新的序列。
3、查询中使用了操作符、聚合操作或内置函数也会增加耗时,因为需要基于样本数据进行二次计算。
为了后面描述方便,我们先引入一个定义:基数(cardinality)。基数的基本定义是指一个给定集合中的元素的数量。以logback_events_total 这个指标为例,我们来理解下Prometheus 中标签基数和指标基数。
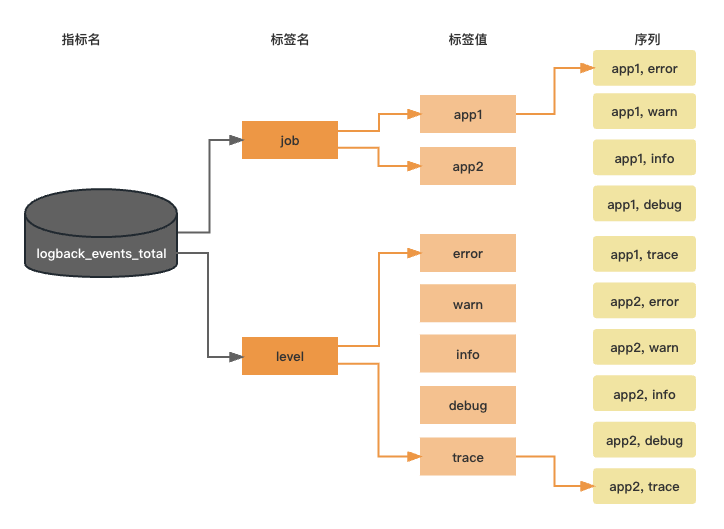 logback_events_total 指标有两个标签,其中标签 job 有两个值,那么它的基数为2,同理 level 标签的基数为5,logback_events_total 指标的基数为10。指标基数越高查询耗时也就会越多。
logback_events_total 指标有两个标签,其中标签 job 有两个值,那么它的基数为2,同理 level 标签的基数为5,logback_events_total 指标的基数为10。指标基数越高查询耗时也就会越多。
理解了基数的定义后,我们选取一个查询超时的监控指标来进行基数分析。先看下这个指标的一条标签数据:
http_server_requests_seconds_count{application="app1", cluster="cluster1", exception="xxxException", instance="xxx", job="app1", method="GET", returnCode="A0000", status="200", uri="/xxx"}
执行如下 PromQL(Prometheus自定义的数据查询语言) 来查询该指标每个标签的基数(用实际标签名替换下面语句中的 label_name):
count(count by (label_name) (http_server_requests_seconds_count))
该指标的标签基数汇总如下:
 可以看到,instance 和uri 这两个标签的基数都很高。执行如下 PromQL 查询该指标的基数,发现该指标的基数达到了147610。
可以看到,instance 和uri 这两个标签的基数都很高。执行如下 PromQL 查询该指标的基数,发现该指标的基数达到了147610。
count({__name__="http_server_requests_seconds_count"})
用同样的方式分析了下其他问题指标,指标基数同样达到了10万以上。作为对比,我们抽样分析了几个加载比较快的指标,指标基数大都在1万以下。因此可以确认,查询耗时高主要是指标基数过高引起的。实际监控图表配置的查询语句中还使用了一些聚合操作(例如 sum)和内置函数(例如 rate),也在一定程度上增加了查询耗时。
03
优化
Prometheus 提供了一种叫做记录规则(Recording Rule)的方式来优化我们的查询语句,记录规则的基本思想是:预先计算经常要用或计算开销较大的表达式,并将其结果保存为一组新的时间序列。以上面提到的 http_server_requests_seconds_count 这个指标为例,优化前的一个监控图表的查询语句如下:
sum(rate(http_server_requests_seconds_count{application="$application", cluster=~"$cluster", uri!~"/actuator/.*|/\\*.*|root|/|/health/check"}[1m])) by (uri)
从查询语句可以看出,该监控图表依赖于 application、cluster 和 uri 这三个标签的聚合数据,因此可以创建如下的记录规则(记录规则的详细创建方式可以参考 Prometheus 官方文档):
record: http_server_requests_seconds_count:rate:1m:acu
expr: sum(rate(http_server_requests_seconds_count{uri !~ "/actuator/.*|/\\*.*|root|/|/health/check"}[1m])) by (application,cluster,uri)
记录规则创建后默认只包含记录规则创建时间之后的数据,并不包含创建之前的历史数据。Prometheus从 v2.27 版本开始支持通过命令行指令来手工回溯历史数据(对于 Prometheus v2.38及以下版本,需要在实例启动时开启--storage.tsdb.allow-overlapping-blocks 参数),通过 promtool tsdb create-blocks-from rules --help 可以了解该指令的使用,这里给出了一个该指令的样例:
promtool tsdb create-blocks-from rules \
--start 1680348042 \
--end 1682421642 \
--url http://mypromserver.com:9090 \
rules.yaml
promtool tsdb create-blocks-from rules 命令的输出是一个目录(默认是 data/ ),其中包含了记录规则文件中所有规则历史数据的 block。为了让新生成的 block 生效,必须将它们手工移动到正在运行的 Prometheus 实例数据目录下。移动后,新产生的 block 将在下一次压缩运行时与现有 block 合并。
在执行完上面的操作后通过 PromQL 查询这个记录规则的基数,发现指标基数下降到了4878。原来监控图表的查询语句可以调整为:
sum(http_server_requests_seconds_count:rate:1m:acu{application="$application", cluster=~"$cluster"}) by (uri)
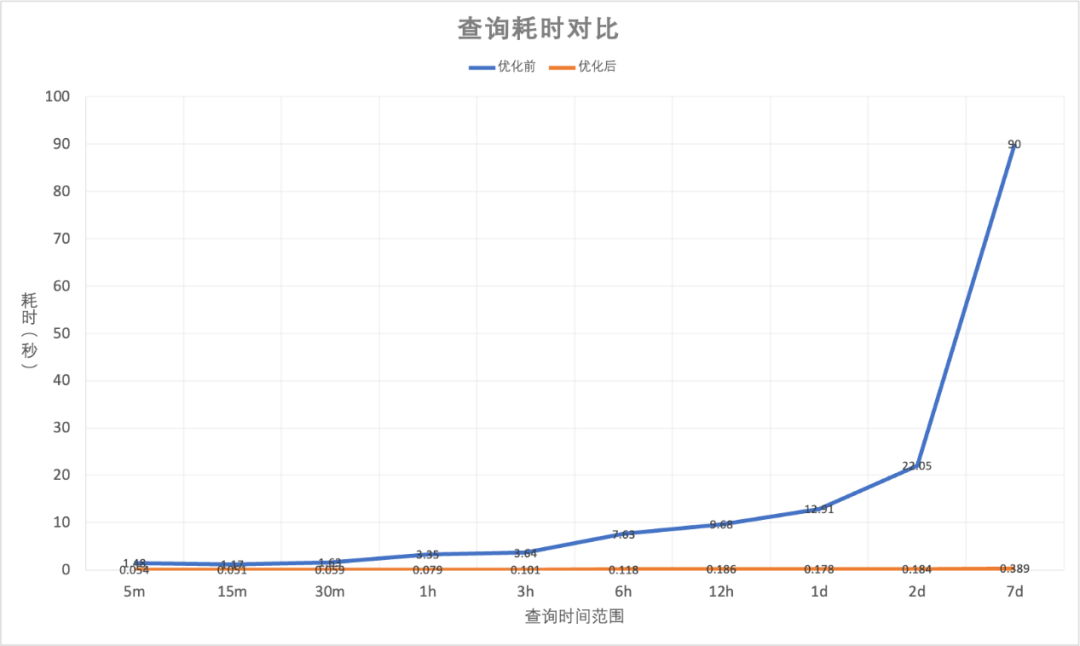
对优化后的监控图表进行测试,效果对比如下图所示,可以看到查询的时间范围越长,效果提升越明显。这主要得益于记录规则带来的指标基数大幅降低以及函数计算的预先处理。
 在实际场景中,如果有多个监控图表都用到了同一个监控指标,可以整体评估一下记录规则应该怎么创建。因为一个记录规则也是一组时间序列,在满足查询需求的前提下尽量避免创建过多的记录规则。
在实际场景中,如果有多个监控图表都用到了同一个监控指标,可以整体评估一下记录规则应该怎么创建。因为一个记录规则也是一组时间序列,在满足查询需求的前提下尽量避免创建过多的记录规则。
04
小结
当 Prometheus 指标基数过高时,就会出现监控图表加载很慢甚至加载失败。通过 Prometheus 提供的记录规则,我们可以对查询语句进行优化从而减少查询耗时。除了记录规则外,还有一些技巧可以优化查询性能,例如增加 Prometheus 指标采集间隔,删除不用的指标序列等。实际上,在监控指标设计阶段就应该对指标基数进行评估,必要时对标签取值进行取舍。例如,一个标签对应 HTTP 响应码,可以将它的取值定义为 1XX、2XX、3XX、4XX、5XX,相比详细的响应码可以大大降低指标基数。

也许你还想看
会员接口治理的探索与实践
组件化设计在会员业务的应用和实践
会员测试环境治理之路