介绍
在本文中,我将探讨表征学习中常见的一种做法——使用预训练神经网络的冻结状态作为学习特征提取器。
具体而言,我感兴趣的是研究使用这些提取的神经网络特征训练的简单模型的性能与使用迁移学习初始化的微调神经网络的性能的比较。预期受众主要是数据科学家,以及对计算机视觉和机器学习感兴趣的任何人。
稍微跳过一点......下面的结果表明,使用提取的神经网络特征训练的 scikit-learn 模型的表现几乎与使用相同的预训练权重微调的完整网络相当(平衡准确度下降了 3% 至 6%)。
背景
如今,微软等公司每年发布数千个预训练神经网络模型。这些模型越来越强大和易于使用。
由于有这么多的模型检查点开源,神经网络作为人工智能/机器学习中的核心关注点的演变并不令人意外。想想人们都听说过能够将文本提示转换成图像/艺术品的 DALL-E-2 和 Stable Diffusion - 神经网络。
据报道,Stable Diffusion 已经被超过 1000 万个用户下载。许多人不知道的是,这些技术今天之所以存在很大程度上是因为统计学子领域表征学习的进步。
“2020 年代看起来是表征学习在机器学习中实现其承诺的时代。使用在特定域(有监督或无监督)上训练的模型,我们可以使用它们的后期激活在处理输入时作为其输入的表征。
表征可以以各种方式使用,最常见的是直接用作下游模型的输入,或用作共同训练具有多种模型类型的共享潜在空间的目标(文本和视觉,GNN 和文本等)。”—Kyle Kranen[1]
让我们来检验一下这些说法......
数据集详情
下面使用的图像数据集源自2013/2014年的Chesapeake Conservancy土地覆盖项目[2]。
它由国家农业图像计划(NAIP)卫星图像组成,以1米平方分辨率提供4个信息通道(红、绿、蓝和近红外)。最初的地理空间数据跨越6个州,总面积达100,000平方英里:弗吉尼亚州、西弗吉尼亚州、马里兰州、特拉华州、宾夕法尼亚州和纽约州。
为了获得n = 15,809个唯一的大小为128 x 128像素的补丁和相同数量的土地覆盖标签,它首先被子采样。检查示例补丁(参见图1),1米平方分辨率似乎相当细致,因为图像中的结构和物体可以以相当高的清晰度解释。
注:原始的Chesapeake Conservancy土地覆盖数据集包括标签掩码,旨在进行分割而不是分类。为了改变这一点,我只保存了出现单一类别且在采样地理空间数据时至少出现85%频率的补丁。
这里实验使用的5个土地覆盖类别定义如下:
水域:包括池塘、河流和湖泊等开放水域
树冠和灌木:包括树木和灌木等木本植物
低植被:高度小于2米的植物材料,包括草坪
贫瘠:不生长植被的天然土壤区域
不透水表面:人造表面
经过检查,数据集似乎具有许多有趣的特征,包括季节变化(例如叶片)、噪声和跨6个州的分布偏移。少量的“自然”噪声有助于使这个有些简化的分类任务变得更加困难,这是有益的,因为我们不希望监督任务过于轻松。
使用美国各州作为划分机制,生成了训练集、验证集和测试集。测试集选取来自宾夕法尼亚州的补丁(n=2,586,占数据的16.4%),验证集选取来自特拉华州的补丁(n=2,088,占数据的13.2%),其余则用于训练集(n=11,135,占数据的70.4%)。
总的来说,该数据集存在显著的类别不平衡问题:荒地(49/15,809)和不透水表面(124/15,809)的表示不足,而树冠和灌木(9,514/15,809)的表示则超过了预期。相比之下,低植被(3,672/15,809)和水(2,450/15,809)的表示则更加平衡。
由于标签不平衡,我们在下面的实验中使用平衡准确度。该指标将每个类别的单独准确度的平均值作为统计值,因此无论类别大小如何,每个类别都被赋予相同的权重。
see: torchgeo.datasets学习特征
通常,学习特征可以定义为源自黑匣子算法的特征。通过提取图像表示的学习特征,你通常会信任计算机视觉社区中的其他团队,他们在首次训练黑匣子时对算法进行了优化。
例如,可以使用诸如keras、pytorch和transformers等包从经过大型基准数据集(如ImageNet)进行预训练的神经网络中提取学习特征。
学习特征通常是下游任务的出色表示,无论是无监督还是有监督任务。假设做出的假设是,模型的权重以稳健的方式进行了预训练。幸运的是,你可以信任Google / Microsoft / Facebook的这一点。
为了提供一些背景,当原始图像被输入到神经网络中时,它经历了几个连续的转换层,其中每个隐藏状态层从原始图像中提取新的信息。在将图像输入到网络后,可以直接提取隐藏状态或嵌入作为特征。通常惯例是使用最后一个隐藏状态嵌入作为提取的特征,即前面的有监督任务头之前的层。
在这个项目中,我们将研究两个预训练模型:Microsoft的双向编码图像变换器(BEiT)[3]和Facebook的ConvNext模型[4]。
BEiT-base和ConvNext-base是Hugging Face上用于图像分类的两个最流行的检查点,它们在初步测试中表现良好,胜过其他选项。由于提取的隐藏状态通常比1 x n的维数要高,常见做法是沿较小的维度取平均值,以得到每个图像的1 x n嵌入。
下面,我们从基础BEiT中得到了1 x 768大小的嵌入,从基础ConvNext中得到了1 x 1024维的嵌入。这些嵌入被任意调整为矩形形状以进行可视化,从而揭示出一些不同的模式。
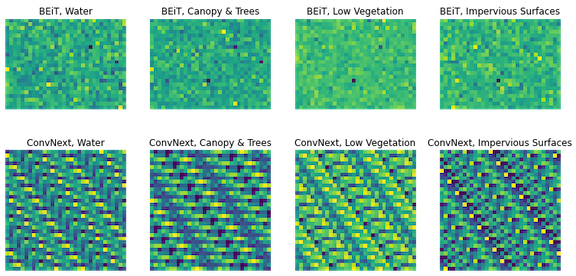
图2展示了数据集中四个随机示例的两个学习特征表示。顶部一行对应于BEiT Vision Transformer嵌入,底部一行对应于ConvNext模型嵌入。四个补丁来自Water(左)、Tree Canopy和Shrubs(左中)、Low Vegetation(右中)和Impervious Surfaces(右)。请注意,这些嵌入已经从原始的1 x n嵌入中调整大小,以便将它们可视化为矩形补丁。
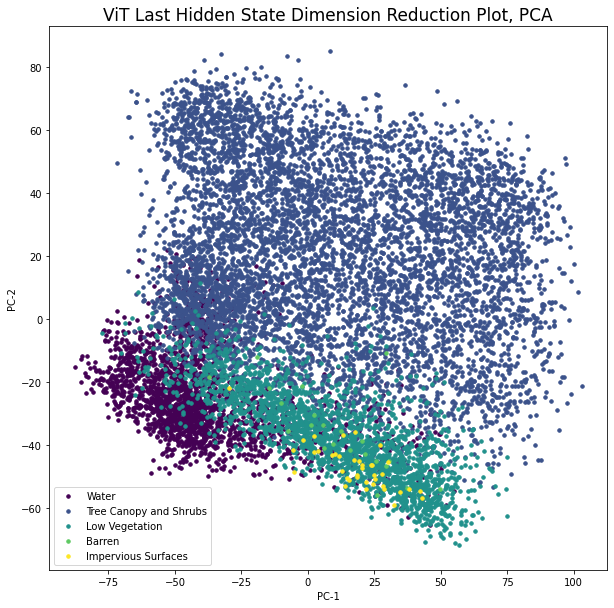
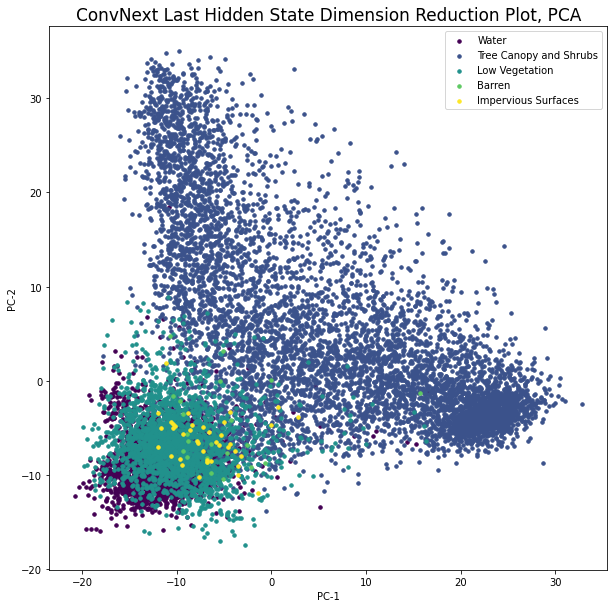
接下来,我们将查看数据在学习特征空间中的可视化呈现方式。为此,我们将对n个图像嵌入进行PCA,以将它们转换为2D空间。然后将它们与类标签一起作为颜色绘制出来。
see: transformers.BeitModel/ConvNextModel建模
如果你去 Kaggle 竞赛的笔记本,你会发现在图像分类中,使用预训练神经网络进行迁移学习和微调是目前最常见的做法。
在这种情况下,首先将权重加载到网络中(迁移学习),然后在新的感兴趣数据集上进行更新(微调)。后一步通常在几个epoch 内运行,并采用较小的学习权重,以便不偏离原始权重太远。
然而,与使用相同的模型作为特征提取器相比,迁移学习和微调过程通常需要更多的时间和计算。
下面的模型的前半部分是使用学习特征和 scikit-learn 模型进行训练的。我使用以下软件包来实现完整的流程:从特征提取(transformers)到模型训练(sklearn)到超参数优化(optuna)。
对于超参数优化,我在 10 个随机试验中搜索了各种逻辑回归器和前馈神经网络 (FFNN),结果显示具有维度为 175-200 的一个隐状态的 FFNN 通常是最佳选择。
转移学习和微调的神经网络随后被训练以与这些学习特征模型进行比较,这构成了模型的第二部分。我使用transformers包来微调BEiT和ConvNext基础模型,这些模型与上面的模型完全相同。为了更好地进行比较,使用了相同的预训练权重。
请参阅Hugging Face的优秀的图像分类教程:https://colab.research.google.com/github/nateraw/huggingface-hub-examples/blob/main/vit_image_classification_explained.ipynb
see: optuna, sklearn, transformers模型评估
为了评估模型,我选择在保留的测试集上检查平衡准确性、各个类别的准确性和混淆矩阵。混淆矩阵显示模型犯错误的地方,有助于解释。每一行代表存在于给定类别中的已知样本(实际值),而每一列代表模型分类出的样本(预测值)。每行总和等于实际值的数量,每列总和等于预测值的数量。
模型1,BEiT嵌入+sklearn FFNN:
平衡准确率……79.6%
+============+=======+========+============+========+=========+
| | Water | Trees | Vegetation | Barren | Manmade |
+============+=======+========+============+========+=========+
| Water | 64 | 0 | 2 | 0 | 0 |
+------------+-------+--------+------------+--------+---------+
| Trees | 1 | 1987 | 3 | 1 | 0 |
+------------+-------+--------+------------+--------+---------+
| Vegetation | 1 | 3 | 457 | 0 | 0 |
+------------+-------+--------+------------+--------+---------+
| Barren | 2 | 0 | 14 | 5 | 3 |
+------------+-------+--------+------------+--------+---------+
| Manmade | 0 | 0 | 6 | 2 | 35 |
+------------+-------+--------+------------+--------+---------+各类别准确率 … 水:97.0%,树冠和树木:99.7%,低植被:99.1%,贫瘠地区:20.8%,不透水表面:81.4%。
Beit embeddings 模型总体上表现第三。
模型2,ConvNext embeddings + sklearn FFNN:
平衡精度… 78.1%
+============+=======+========+============+========+=========+
| | Water | Trees | Vegetation | Barren | Manmade |
+============+=======+========+============+========+=========+
| Water | 62 | 0 | 4 | 0 | 0 |
+------------+-------+--------+------------+--------+---------+
| Trees | 2 | 1982 | 6 | 2 | 0 |
+------------+-------+--------+------------+--------+---------+
| Vegetation | 1 | 3 | 457 | 0 | 0 |
+------------+-------+--------+------------+--------+---------+
| Barren | 1 | 1 | 17 | 4 | 1 |
+------------+-------+--------+------------+--------+---------+
| Manmade | 0 | 0 | 8 | 0 | 35 |
+------------+-------+--------+------------+--------+---------+分类精度... 水域:93.9%,树冠和树木:99.5%,低植被:99.1%,裸露地面:16.6%,不透水表面:81.4%。
ConvNext嵌入模型总体表现最差
模型3,经过微调的BEiT神经网络:
平衡精度... 82.9%
+============+=======+========+============+========+=========+
| | Water | Trees | Vegetation | Barren | Manmade |
+============+=======+========+============+========+=========+
| Water | 64 | 0 | 2 | 0 | 0 |
+------------+-------+--------+------------+--------+---------+
| Trees | 0 | 1986 | 5 | 1 | 0 |
+------------+-------+--------+------------+--------+---------+
| Vegetation | 2 | 3 | 455 | 0 | 1 |
+------------+-------+--------+------------+--------+---------+
| Barren | 0 | 0 | 13 | 9 | 2 |
+------------+-------+--------+------------+--------+---------+
| Manmade | 1 | 0 | 6 | 1 | 35 |
+------------+-------+--------+------------+--------+---------+分类精度... 水域:97.0%,树冠和树木:99.7%,低植被:98.7%,裸露地面:37.5%,不透水表面:81.4%。
经过微调的BEiT模型在总体表现中排名第二
模型4,经过微调的ConvNext神经网络:
平衡精度... 84.4%
+============+=======+========+============+========+=========+
| | Water | Trees | Vegetation | Barren | Manmade |
+============+=======+========+============+========+=========+
| Water | 65 | 0 | 1 | 0 | 0 |
+------------+-------+--------+------------+--------+---------+
| Trees | 0 | 1978 | 12 | 2 | 0 |
+------------+-------+--------+------------+--------+---------+
| Vegetation | 1 | 2 | 457 | 0 | 1 |
+------------+-------+--------+------------+--------+---------+
| Barren | 0 | 0 | 13 | 11 | 0 |
+------------+-------+--------+------------+--------+---------+
| Manmade | 0 | 0 | 7 | 2 | 34 |
+------------+-------+--------+------------+--------+---------+分类精度... 水域:98.5%,树冠和树木:99.3%,低植被:99.1%,裸露地面:45.8%,不透水表面:79.1%。
经过微调的ConvNext模型在总体表现中表现最佳
模型过程中的改进/限制:
模型流程可以在多个方面得到改进,包括接下来讨论的这些方面。这些模型在裸露地面的分类上表现最差,因此如果能进行单一更改,我会首先添加更多这种类型的分类。
目前,这些模型实际上更像4分类器,因为裸露地面的性能非常差。另一种改进是在超参数优化中使用交叉验证;但是,交叉验证需要更长的运行时间,对于这个实验来说可能有点过度。
输出模型的泛化局限性包括在其他类别类型、不同分辨率和其他条件(新对象、新结构、新类别等)的图像上表现更差。我已经将经过微调的ConvNext和BEiT推送到Hugging Face进行托管推理,在其中可以通过加载图像和/或运行每个模型中配置的默认值来测试模型的泛化性能。
学习到的知识
掌握Python包的知识是至关重要的。请参见本文的代码块,其中列出了使用的各种库。
可视化图像特征的变化可以更深入地理解数据集中的信号。
预训练的嵌入配合较简单的模型可以表现得几乎与微调的神经网络一样好。
Hugging Face不仅在自然语言处理方面表现出色,也在计算机视觉方面表现出色!
结论:
这些结果和学习对于当今计算机视觉领域的神经网络有何启示?让我们回顾一下。
2017年,特斯拉自动驾驶部门前主管Andrej Karpath在一篇著名的博客文章中谈到了从旧式工程到深度学习的转变,他称之为“软件2.0”[5]。
从这个观点来看,神经网络不是“机器学习工具箱中的另一个工具”。相反,它们代表了我们可以开发软件的方式的转变。
感谢阅读!
参考
[1] K. Kranen (2022), The 2020s are looking like the age of representation learning’s promise being realized in ML, LinkedIn.
[2] Chesapeake Bay Program Office (2022). One-meter Resolution Land Cover Dataset for the Chesapeake Bay Watershed, 2017/18. Developed by the University of Vermont Spatial Analysis Lab, Chesapeake Conservancy, and U.S. Geological Survey. [Nov 15, 2022], [URL],
Dataset License: The dataset used herein is publicly available to all without restriction.
[3] Bao, H., Dong, L., & Wei, F. (2021). BEiT: BERT Pre-Training of Image Transformers. CoRR, abs/2106.08254. https://arxiv.org/abs/2106.08254
[4] Liu, Z., Mao, H., Wu, C.-Y., Feichtenhofer, C., Darrell, T., & Xie, S. (2022). A ConvNet for the 2020s. CoRR, abs/2201.03545. https://arxiv.org/abs/2201.03545
[5] A. Karpath (2017), Software 2.0, Medium.
[6] Nanni, L., Ghidoni, S., & Brahnam, S. (2017). Handcrafted vs. non-handcrafted features for computer vision classification. Pattern Recognition, 71, 158–172. doi:10.1016/j.patcog.2017.05.025
附录
在计算机视觉中,非学习特征可以被认为是从图像中手工制作的特征 [6]。针对给定问题的最佳非学习特征通常依赖于了解数据集中不同信号的位置。在提取非学习特征之前,让我们先在 RGB 空间中绘制一些随机图像块。

我们将首先探讨主成分分析(PCA)作为第一个非学习特征。PCA是一种降维技术,我们在这里使用它将128 x 128 x 4图像转换为1 x n向量。PCA转换数据集的大小n是用户指定的,并且可以是小于数据的原始维度的任何数字。
在算法的内部,使用特征向量(数据中的扩展方向)和特征值(方向的相对重要性)来找到保留原始图像中最大方差的一组基础。计算完成后,PCA可以用于将新图像转换为低维空间和/或将图像可视化为二维或三维(见图3和图4)。
在下面的示例中,当n = 3000时,PCA结果保留了95%的维数并保存了几乎所有来自原始图像的信号。为了可视化PCA,我逆转了操作并将示例绘制为128 x 128像素的图像。

让我们再看一下另一个老派的特征:梯度直方图(HOG)。为了计算HOG,首先在图像上计算梯度(变化强度)和方向。然后,将图像分割成若干个单元格,在其中方向被分层到直方图柱中。然后,在单元格中的每个像素处,我们查找其方向,找到直方图中相应的柱,并将给定值添加到其中。然后,这个过程在图像的单元格上重复执行。完成!
看看HOG在这里的酷炫表现:

虽然这些手工特征作为首次对数据集进行可视化的工具很有趣,但是它们并不适合我们的监督建模目的。在这里,最初的测试表明,使用HOG和PCA特征构建的模型相对于下面探讨的学习特征训练的模型,其平衡准确率显著下降(PCA下降了35%,HOG下降了50%)。
see: skimage.feature.hog, sklearn.decomposition.PCA☆ END ☆
如果看到这里,说明你喜欢这篇文章,请转发、点赞。微信搜索「uncle_pn」,欢迎添加小编微信「 woshicver」,每日朋友圈更新一篇高质量博文。
↓扫描二维码添加小编↓