【自然语言处理概述】百度百科数据爬取

作者简介:在校大学生一枚,华为云享专家,阿里云专家博主,腾云先锋(TDP)成员,云曦智划项目总负责人,全国高等学校计算机教学与产业实践资源建设专家委员会(TIPCC)志愿者,以及编程爱好者,期待和大家一起学习,一起进步~
.
博客主页:ぃ灵彧が的学习日志
.
本文专栏:人工智能
.
专栏寄语:若你决定灿烂,山无遮,海无拦
.

文章目录
- 【自然语言处理概述】百度百科数据爬取
- 一、前沿
- (一)、任务描述
- (二)、环境配置
- 二、代码部分
- (一)、定义爬取信息
- (二)、数据解析并保存
- (三)、爬取每个选手的信息
- 三、总结
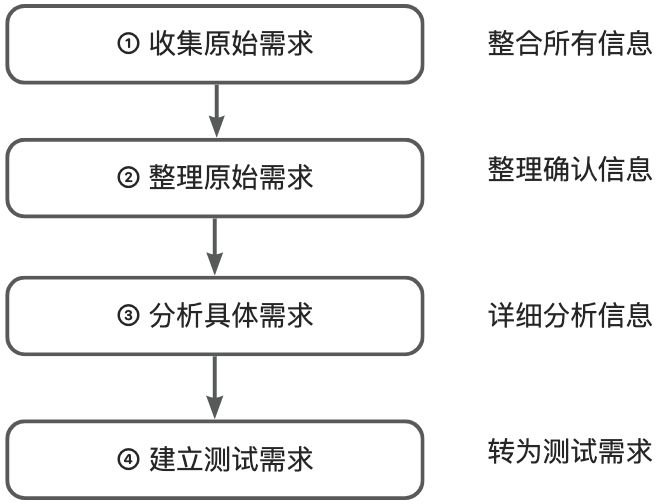
一、前沿
(一)、任务描述
本实践使用Python来爬取百度百科中《乘风破浪的姐姐第二季》所有选手的信息,并进行可视化分析。其难点在于如何准确获取数据并进行处理获得可视化的结果。
数据爬取可以应用于自己收集网络已有数据,是一种较为普遍的方式。本案例通过获取百度百科的信息获得嘉宾的一系列数据,然后对数据进行处理与分析。
(二)、环境配置
本次实验平台为百度AI Studio,Python版本为Python3.7,下面介绍如何通过Python编程方式实现“海量”文件的遍历。
二、代码部分
(一)、定义爬取信息
import json
import re
import requests
import datetime
from bs4 import BeautifulSoup
import os
def crawl_wiki_data():
headers={
'User-Agent': 'Mozilla/5.0(Windows NT 10.0;WOW64) AppleWebkit/537.36(KHTML,like Gecko) Chrome/67.0.3396.99 Safari/537.36'
}
url = 'https://baike.baidu.com/item/乘风破浪的姐姐第二季'
try:
response = requests.get(url,headers=headers)
soup = BeautifulSoup(response.text,'lxml')
tables = soup.find_all('table')
crawl_table_title = "按姓氏首字母排序"
for table in tables:
table_titles = table.find_previous('div')
for title in table_titles:
if(crawl_table_title in title):
return table
except Exception as e:
print(e)
(二)、数据解析并保存
使用上述定义好的函数,进行指定url页面的爬取,然后解析返回的页面源码,获取其中的选手姓名和个人百度百科页面链接,并保存:
def parse_wiki_data(table_html):
bs = BeautifulSoup(str(table_html),'lxml')
all_trs = bs.find_all('tr')
stars = []
for tr in all_trs:
all_tds = tr.find_all('td')
for td in all_tds:
star = {}
if td.find('a'):
if(td.find_next('a').text.isspace() == False):
star["name"] = td.find_next('a').text
star['link'] = 'https://baike.baidu.com'+td.find_next('a').get('href')
stars.append(star)
json_data = json.loads(str(stars).replace("\'","\""))
with open('work/'+'stars.json','w',encoding='UTF-8') as f:
json.dump(json_data,f,ensure_ascii=False)
(三)、爬取每个选手的信息
- 根据图片链接列表pic_urls,下载所有图片,保存在以name命名的文件夹中。
def down_save_pic(name,pic_urls):
path = 'work/'+'pics/'+name+'/'
if not os.path.exists(path):
os.makedirs(path)
for i,pic_url in enumerate(pic_urls):
try:
pic = requests.get(pic_url,timeout=15)
string = str(i+1) + '.jpg'
with open(path+string,'wb') as f:
f.write(pic.content)
except Exception as e:
print(e)
continue
- 爬取每个选手的百度百科个人信息,并保存:
def crawl_everyone_wiki_urls():
with open('work/'+'stars.json','r',encoding='UTF-8') as file:
json_array = json.loads(file.read())
headers = {
'User-Agent':'Mozilla/5.0(Windows NT 10.0; WOW64) AppleWebkit/537.36(KHTML,like Gecko) Chrome/67.0.3396.99 Safari/537.36'
}
star_infos = []
for star in json_array:
star_info = {}
name = star['name']
link = star['link']
star_info['name'] = name
response = requests.get(link,headers=headers)
bs = BeautifulSoup(response.text,'lxml')
base_info_div = bs.find('div',{'class':'basic-info cmn-clearfix'})
dls = base_info_div.find_all('dl')
for dl in dls:
dts = dl.find_all('dt')
for dt in dts:
if "".join(str(dt.text).split()) == '民族':
star_info['nation'] = dt.find_next('dd').text
if "".join(str(dt.text).split()) == '星座':
star_info['constellation'] = dt.find_next('dd').text
if "".join(str(dt.text).split()) == '血型':
star_info['blood_type'] = dt.find_next('dd').text
if "".join(str(dt.text).split()) == '身高':
height_str = str(dt.find_next('dd').text)
star_info['height'] = str(height_str[0:height_str.rfind('cm')]).replace("\n","")
if "".join(str(dt.text).split()) == '体重':
star_infor['weight'] = str(dt.find_next('dd').text).replace("\n","")
if "".join(str(dt.text).split()) == '出生日期':
birth_day_str = str(dt.find_next('dd').text).replace("\n","")
if '年' in birth_day_str:
star_info['birth_day'] = birth_day_str[0:birth_day_str.rfind('年')]
star_infos.append(star_info)
if bs.select('.summary-pic a'):
pic_list_url = bs.select('.summary-pic a')[0].get('href')
pic_list_url = 'https://baike.baidu.com' + pic_list_url
pic_list_reponse = requests.get(pic_list_url,headers=headers)
bs = BeautifulSoup(pic_list_response.text,'lxml')
pic_list_html = bs.select('.pic-list img')
pic_urls = []
for pic_html in pic_list_html:
pic_url = pic_html_get('src')
pic_urls.append(pic_url)
down_save_pic(name,pic_urls)
json_data = json.loads(str(star_infos).replace("\'","\"").replace("\\xa0",""))
with open('work/'+'stars_info.json','w',encoding='UTF-8') as f:
json.dump(json_data,f,ensure_ascii=False)
- 调用主程序main函数,执行上面所有的爬取过程:
if __name__ == '__main__':
html = crawl_wiki_data()
parse_wiki_data(html)
print("所有信息爬取完成!")
三、总结
本系列文章内容为根据清华社出版的《自然语言处理实践》所作的相关笔记和感悟,其中代码均为基于百度飞桨开发,若有任何侵权和不妥之处,请私信于我,定积极配合处理,看到必回!!!
最后,引用本次活动的一句话,来作为文章的结语~( ̄▽ ̄~)~:
【学习的最大理由是想摆脱平庸,早一天就多一份人生的精彩;迟一天就多一天平庸的困扰。】
ps:更多精彩内容还请进入本文专栏:人工智能,进行查看,欢迎大家支持与指教啊~( ̄▽ ̄~)~