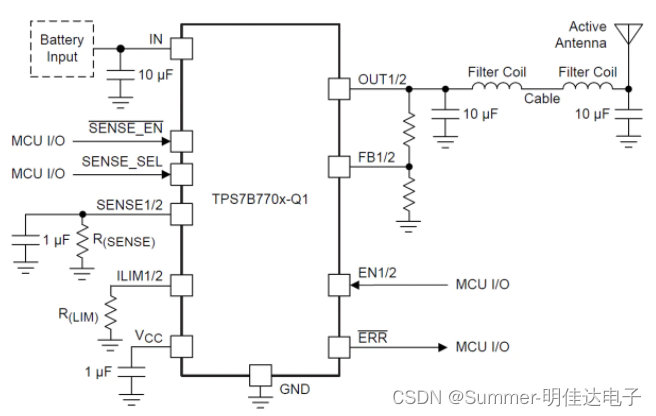
文章目录
- 概述
- 一、Approaches And Challenges
- 生成的声音是什么类型
- 训练模型使用的是什么特征
- 原始音频Raw Audio
- 频谱图Spectrograms
- 声音生成模型常用的结构
- 生成模型的输入
- 二、Autoencoders Explained Easily
- 自动编码器的通俗解释
- PCA和编码器的区别
- 如何训练一个编码器
- Deep Autoencoder
- 使用自动编码生成的过程
- 三、Generation with AutoEncoders: Results and Limitations使用自动编码器生成声音的结果和限制
- 四、From Autoencoders to Variational Autoencoders:The Encoder
- 改变了编码器的的组件
- 改变了损失函数
- 五、Sound Generations with VAEs
- 对于音频数据集的预处理
- 使用的数据集
- 训练
- 具体代码
概述
- 这部分是学习网课的具体内容,国外的网站,有时间可以二创一下。
- 下述为课堂笔记
一、Approaches And Challenges
- 这一节主要是介绍声音生成系统,常见的一些方法,以及他们所面对的一些挑战,主要是围绕着几个问题展开
- 生成的声音是什么类型的
- 训练模型使用的特征是什么
- 所采用而深度学习模型是什么
- 生成的模型的输入是什么
生成的声音是什么类型
- 给你一段文字,自动生成相对应的语音
- 给你一段音乐,你可以将之生成为不同风格的另一种音乐
- Foley 声音设计,这就是类似电影用的配乐,根据需求生成汽车发动的声音,大雷声
- 。。。
训练模型使用的是什么特征
原始音频Raw Audio
- 比较有名的文章推荐
- WaveNet:A Generative Model For Raw Audio
- Jukebox:A generative model for music
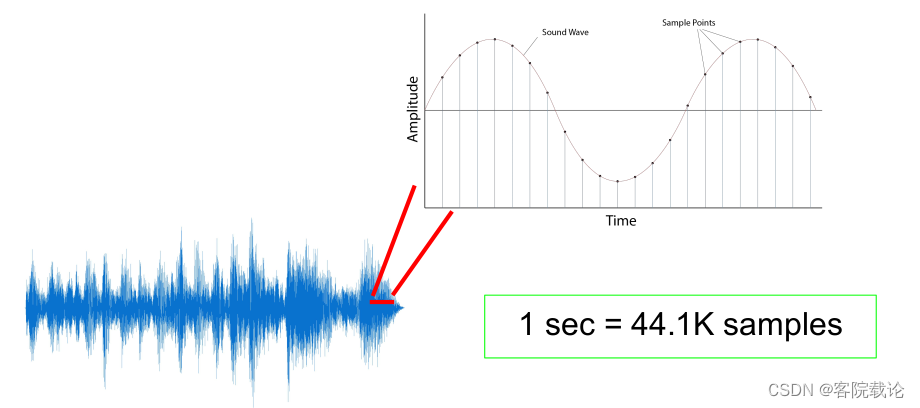
- 该类型的生成模型具有如下的特点
- 需要处理的数据量大
- 无法提取复杂结构特征
- 这里指的是long range dependency feature
- 比如说音色,旋律、和弦之类的,可能要处理好几秒钟才能学会的东西
- 数据量大,会导致模型很复杂,是的计算量很大
- 生成过程很慢,原始数据量很大,模型很复杂
频谱图Spectrograms
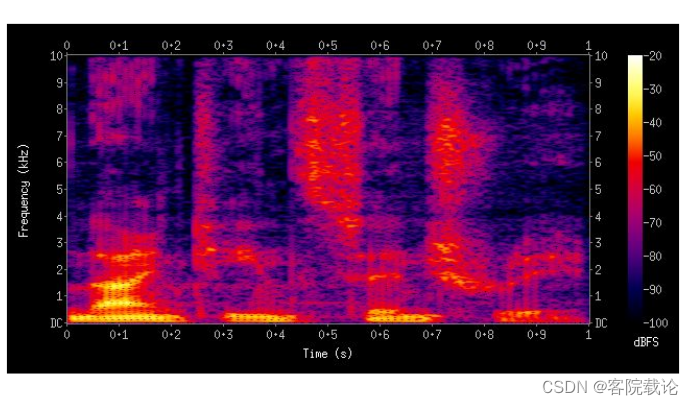
- 使用频谱图代替波形图,横坐标是时间,总坐标是对应的频率,然后颜色表示声音的强度。
具体步骤如下
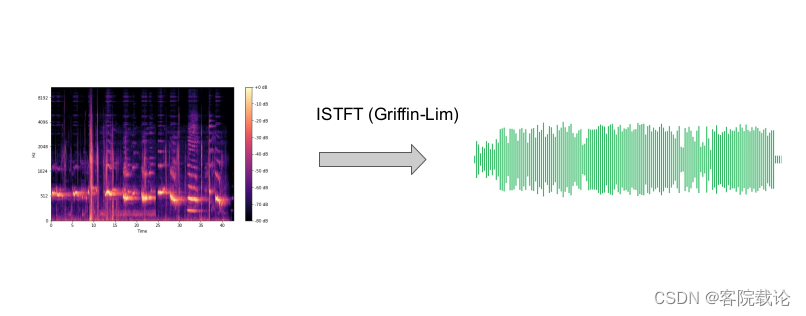
- 首先使用短时傅立叶变换(short time Fourier Transformation)将波形图转变为时频域的频谱图
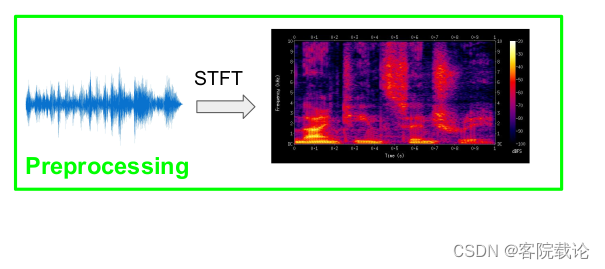
- 然后以频谱图作为输入,放到神经网络上进行训练
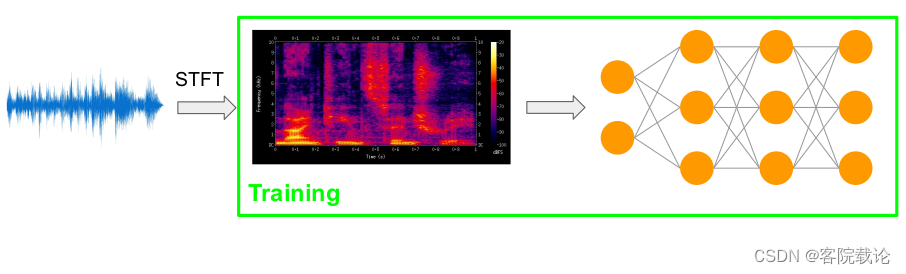
- 经过训练的网络在生成新的频谱图
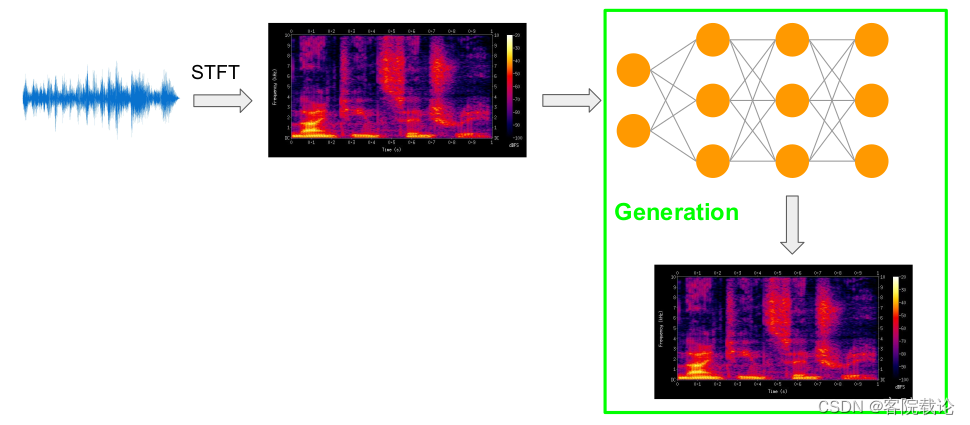
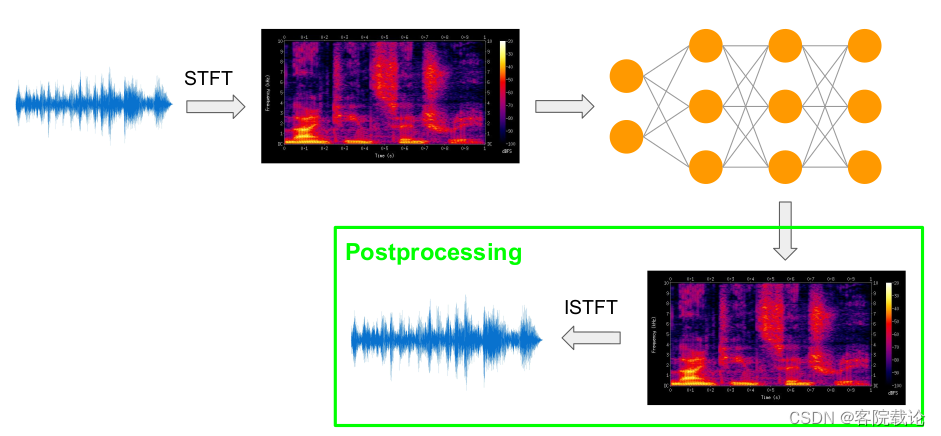
- 然后在使用ISTFT(inverse short time Fourier Transformation 逆短时傅立叶变换)将频谱图转变为波形图
频谱图生成声音的优点
- 比起波形图,频谱图的时间轴更加紧凑完整,因为他并没有像时域图一样,保存那么多的节点
- 能够获取比较复杂的特征(long-range dependency)
- 音色、音节、曲风
- 在保证了完整的信息的同时,确保了计算量比较小
频谱图生成声音的缺点
- 难以提取出图片中的局部特征(保真度),因为直接转换成频谱图,类似一种由細颗粒度转成粗颗粒度的过程,所以保真度一般
声音生成模型常用的结构
- 常见的结构有如下的几种
- GAN
- Autoencoder
- Variational Autoencoder(VAE)
- VQ-VAE
生成模型的输入
Conditioning Generations
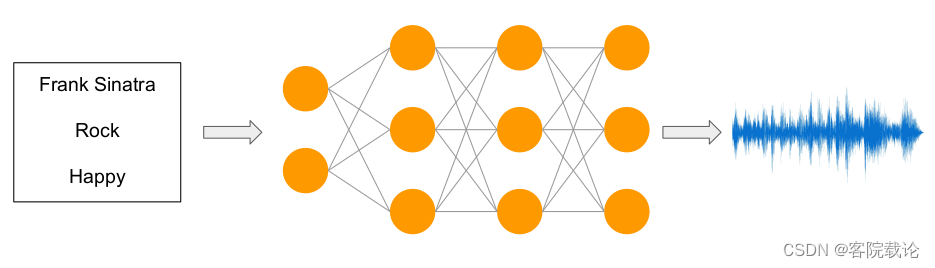
- 根据输入的语音信息,生成生成符合特定条件的声音
Autonomous Generations
- 模型生成任意的声音,这主要是和训练集相关的
Continuation Generations
- 根据输入的seed生成特定的音频,一般是某一个没有完成的音乐片段
二、Autoencoders Explained Easily
自动编码器的通俗解释
-
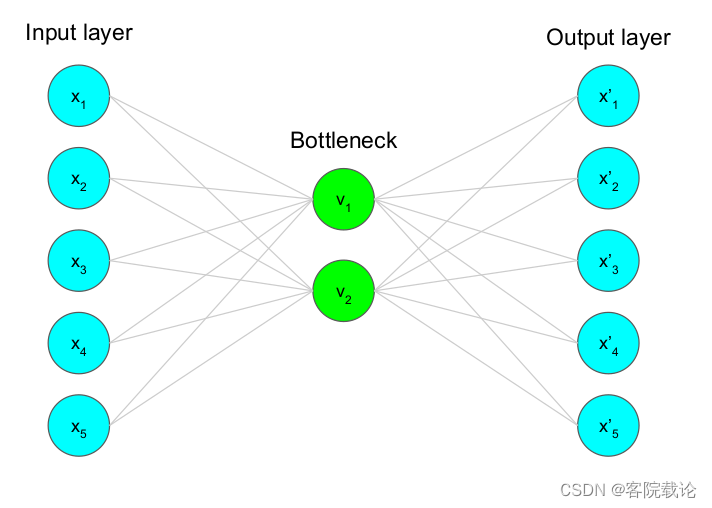
自动编码器是一种无监督学习,学习数据中的一些结构和模式
-
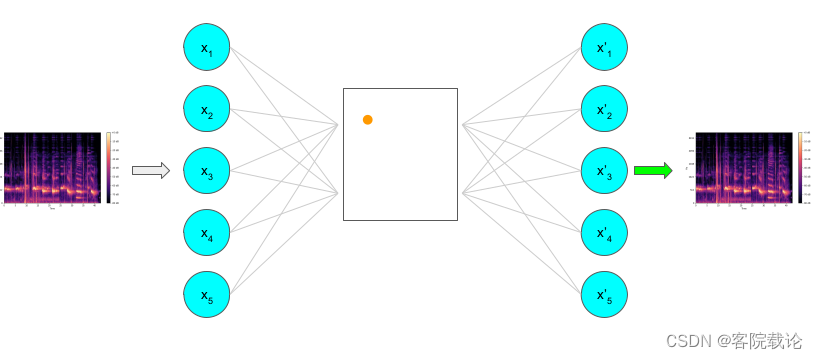
自动编码器是一种bottleneck structure 就是上图中间绿色的两个节点,类似一个瓶口的结构,两边宽,中间窄
-
实现的功能就是:
- 将输入数据压缩到编码器中,然后能通过编码器还原出原来的数据
- 确保了原始数据的低维表示
-
构成
- 编码:从宽的结构到窄的结构
- 将原始数据压缩为低维度表示,主要是包含了最重要的属性或者特征
- 解码:从窄的结构到宽的结构
- 将压缩之后的数据,重新恢复到原来的维度,重建原始数据
- 编码:从宽的结构到窄的结构
-
条件
- 需要确保,输入数据的不同维度之间要有依赖关系,如果相互独立,没有办法进行降维
PCA和编码器的区别
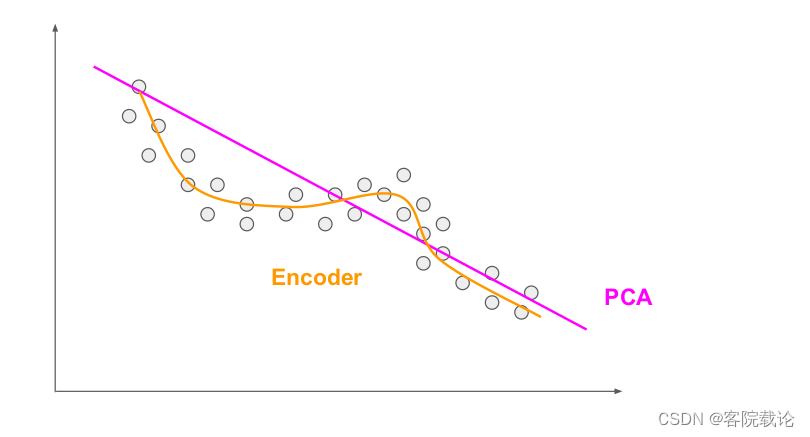
- 在上述图中,一个点表示一个数据分布,
- PCA只能在直线上对数据的分布进行拟合
- 编码器可以你和数据分布的非线性关系
- PCA和编码器都是用来降维的,都能减少数据的维度
- PCA只能学习线性关系,只能提取简单的特征
- 编码器能够学习非线性关系,较之于上者,可以提取更加复杂的特征
如何训练一个编码器
- 使用反向传播
- 最小化重建损失函数,直接比较解码器还原的输出和原始的输入之间的差别
- 一般来说用的是平方差,或者根平方差
 * 关于损失函数
* 关于损失函数 - 上述重建损失函数,只能确保输出尽可能的利用输入数据的有效特征
- 为了防止过拟合,还需要加上对应的正则化项,具体如下
- 一般来说用的是平方差,或者根平方差
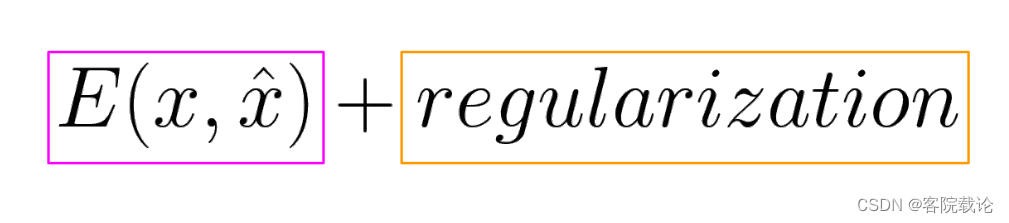
Deep Autoencoder
- 这里参考一下,常见的编码解码器,相关的链接
- 还有一篇国外的链接,讲得也不错,链接
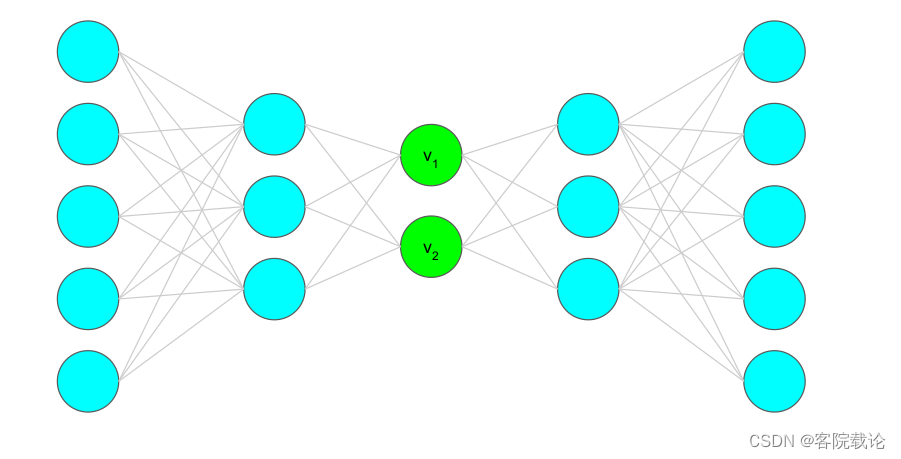
- Encoder编码器
- 卷积层
- Leaky Relu
- Batch normalization
- Decoder解码器
- 卷积层的转置Convolution traspose,不同于卷积的下采样,这里是对卷积进行一个上采样,实现数据的扩充
- Leaky Relu
- Batch normalization
使用自动编码生成的过程
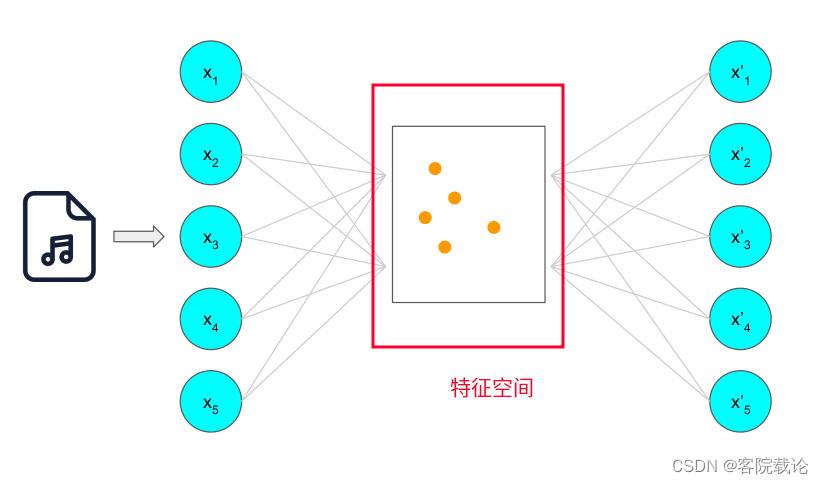
- 每一次输入一个样本之后,都会对特征空间进行改变,具体表现为新增加一个特征点
- 在通过编码器训练特征空间的同时,也会训练解码器,并且通过输出和输入数据的重构损失函数来调整参数
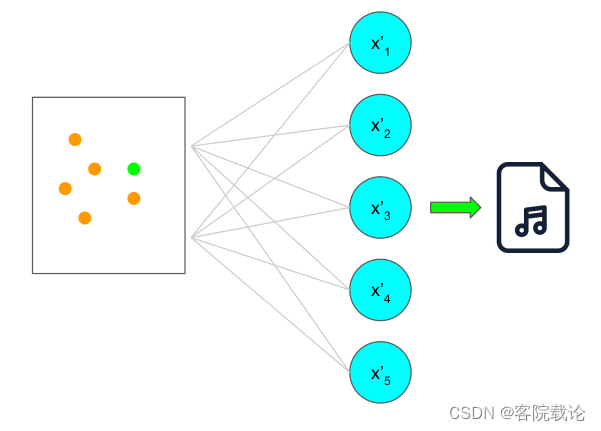
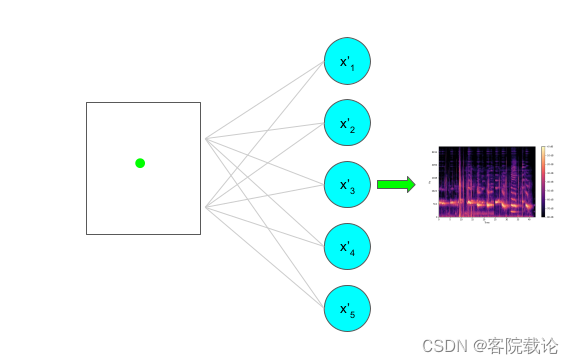
- 声音生成过程,就是在调整之后的特征空间中,随机选择一个点,然后对这个点进行解码,生成新的样本
三、Generation with AutoEncoders: Results and Limitations使用自动编码器生成声音的结果和限制
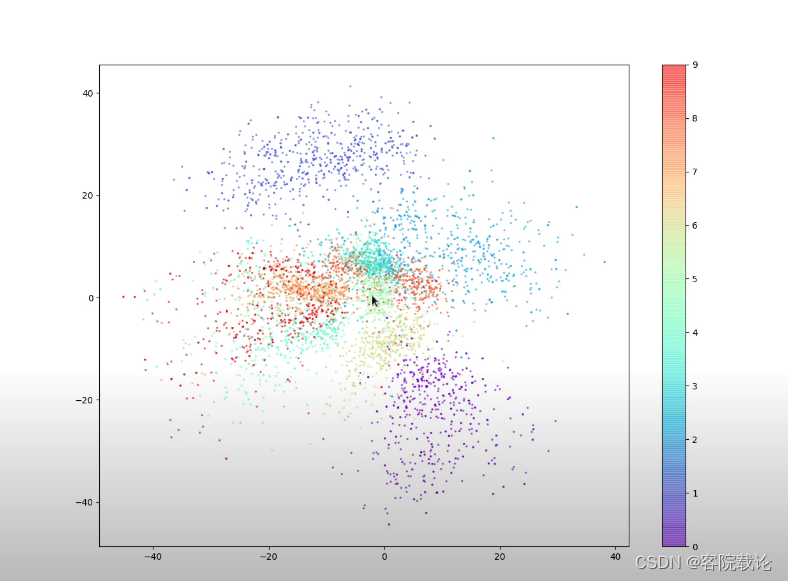
-
训练过程:
- 上数为编码器中的潜在特征空间,由于一开始设置为二维空间,所以可以直接画出来。不同颜色的点,表示不同类别的样例的特征在二维空间中的映射。
-
生成过程
- 通过对潜在空间进行随机采样,获取任意的点,并通过解码程序,生成对应的新的样例
-
通过观察上述特征图可以看到,自动编码器具有如下的缺点
- 特征空间并不是完全关于原点对称,很多特征点很密集,很多特征点很稀疏
- 特征空间中存在地方并没有任何的颜色,这部分的采样点,并不能生成有效的数字,因为分不清到底属于哪一块
- 特征空间缺少多样性,对于这个特空空间进行采样,可以发现,对于所占面积比较大的区间,选中的概率更大。
四、From Autoencoders to Variational Autoencoders:The Encoder
- 针对上述的三个问题,提出了使用变分自动编码器进行训练
改变了编码器的的组件
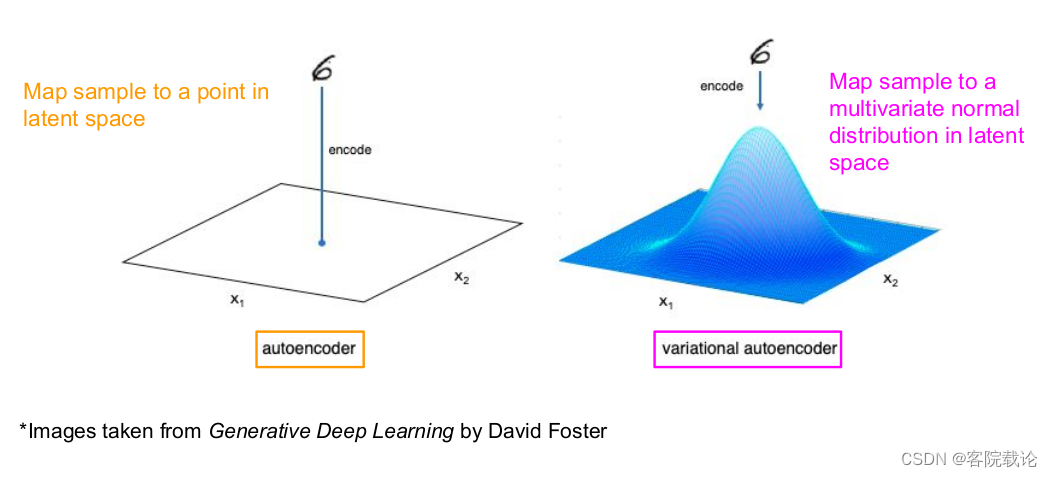
- 二者映射关系的对比
- 左侧是自动编码器的映射关系,是将样例映射为潜在特征空间的特征点
- 右侧是变分自动编码器的映射关系,是将样例映射为多元正态分布
首先从一维的正态分布入手
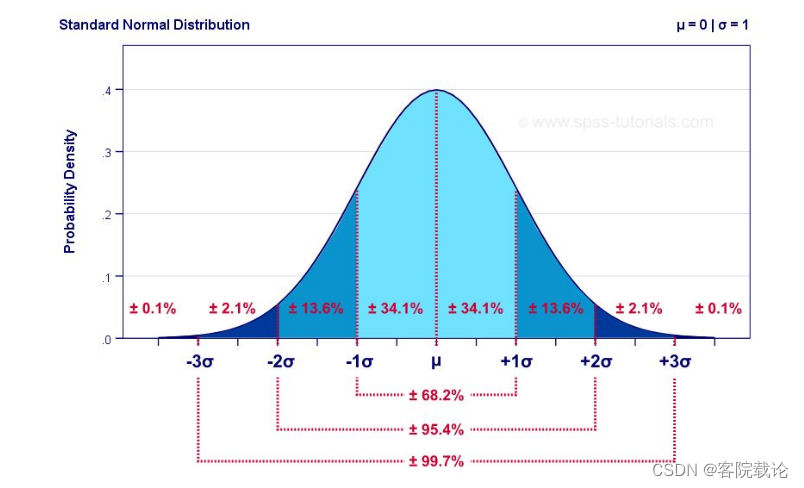
- 标准正态分布的图片
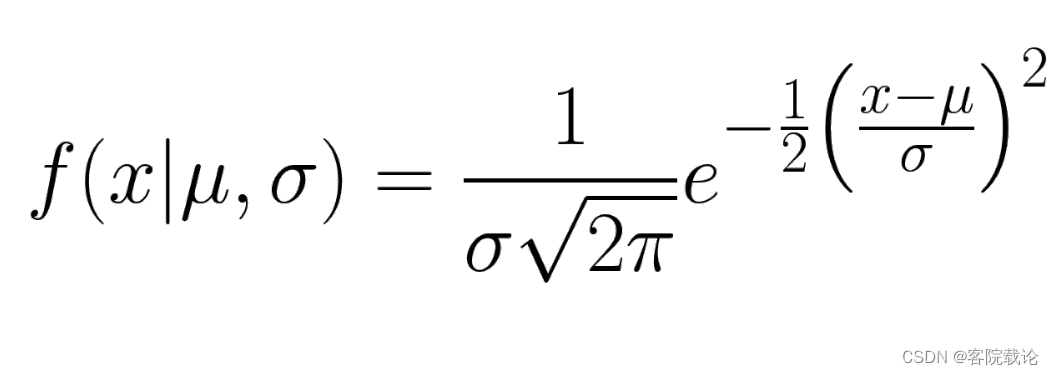
- 标准正态分布的公式
- 参数说明
- σ \sigma σ表示这个正态分布的宽度
- μ \mu μ表示正态分布的中心
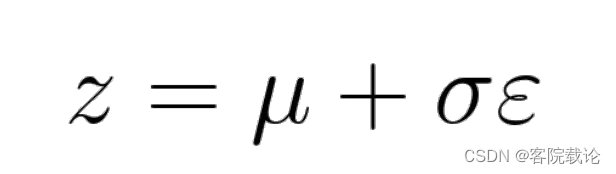
- 在标准正态分布中进行采样,使用上述公式,其中 ε \varepsilon ε是从正态分布中抽样的点
多元正态分布的形式化
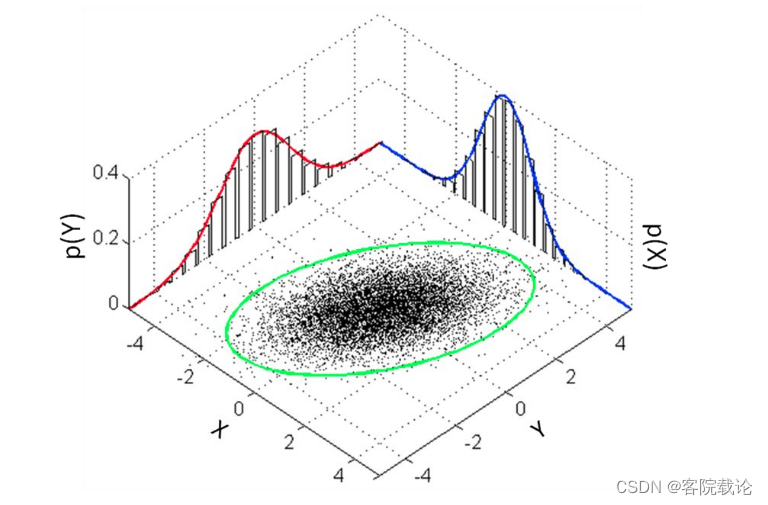
- 以二维的正态分布为例子
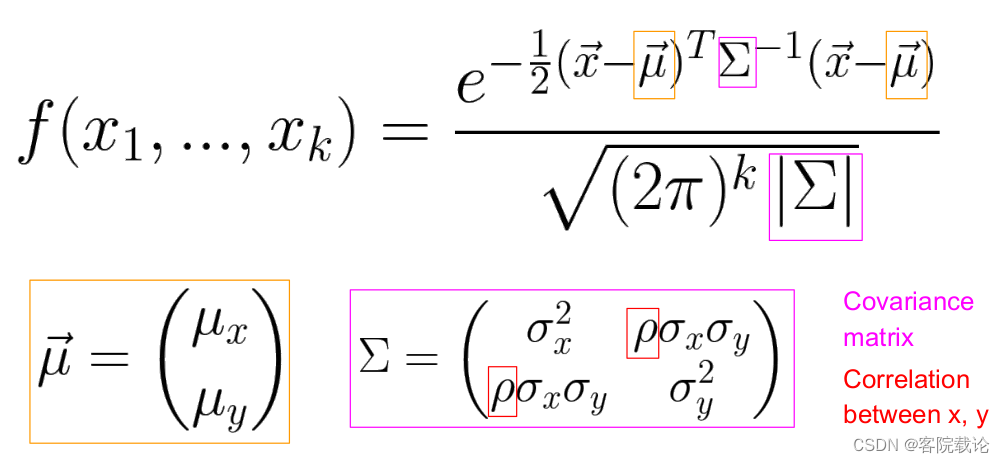
- 这是多个维度下的正态分布公式
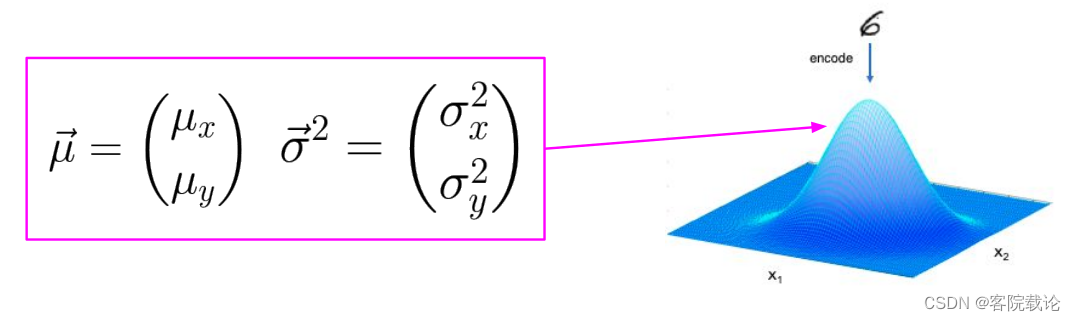
- 可以看到,在这里是将样例映射为一个对应二维的分布
多元正态分布的的修正(主要是针对自动变分器的缺点)
- 由于是将样例映射为二维空间中的分布,所以潜在特征空间是连续的,不会存在空白区域
- 距离同一个平均值也就是正态分布的中心比较近的两个点,生成的样例也是比较相似的
改变了损失函数
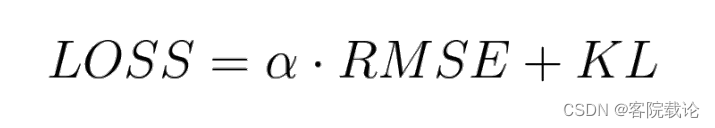
- KL散度,用来标准正态分布和正态分布之间的差异
- 对于那种方差和标准分布参数完全不同的分布进行矫正
-
α
\alpha
α是重建损失函数的权重,
- 太大,最终的效果和自动编码器的效果相同
- 太小,重建的图片和原图一点关系都没有
五、Sound Generations with VAEs
对于音频数据集的预处理
使用的数据集
训练