目录
01 第一章
1.1 GIS空间分析的概念
1.2 GIS空间分析的研究对象、研究目标
1.3 研究目标是:认知、解释、预报、调控。
1.4 道路拓宽案例分析
1.5 GIS空间分析的核心问题
02 第二章
2.1 空间查询的概念、空间量算的概念
2.2 函数距离的概念
2.3 空间查询分类、空间相互关系查询
2.4 空间量算主要内容;空间量算的应用(如求取面积、长度;比如各县沟壑密度中的面积计算)
2.5 欧拉数的概念、弯曲度的概念、简单图形概括的概念、平均最近邻分析的概念、空间自相关的概念、离散区域和连续区域的概念;
2.6 空间自相关概念:反应地理单元某一属性与邻近区域同一属性值的相关程度。如果某一区域属性值均大于或小于平均值,则相关性(Moran’s Index)程度高
2.7 离散区域和连续区域的概念
2.8 高程曲线的制作
03 第三章
3.1 什么是Grid,Grid的行、列数与Cell Size和空间范围、离散型和连续型Grid的区别,Grid的No Data数据
3.2 离散型和连续型Grid的区别
3.3 空间分析的基本参数设置方法与意义,如掩膜的应用、空间分析范围、尺寸设置的作用、Cell Size的概念
3.3 Raster Caculator原理与应用(注意该知识甚至可能和遥感知识相结合,如在GIS中利用遥感TM影像获取植被指数;、种子点扩散算法的实现)、重分类原理与应用(注意重分类可将Nodata变为有值,重分类的结果为离散型栅格数据)
3.4 直线距离的原理与应用(请结合实验三复习)、区域分配的原理与应用(如泰森多边形插值的实现)
3.5 栅格数据转换为矢量多边形(如将分析的栅格图层转换为矢量多边形),特别地,给你一个流域DEM,流域外为无数据,如何自动获取流域矢量面?
3.6 密度功能的概念;密度功能的原理与应用(如提供人口点数据,获取人口密度大于1000的区域)、点密度和核密度区别于联系、人口密度与空间插值的差异
3.7 邻域分析的概念,邻域分析的原理与应用(如根据建筑面图层如何求取建筑密度;求取在2km直线距离内居民点人口总数大于2万人的银行网点);
3.8 表面功能的原理与应用,山顶点提取的关键方法和步骤;
3.9 空间插值的概念;单点移面插值方法的概念;自然邻点插值的概念;趋势面插值的概念;泰森多边形插值的概念;克里格插值的概念
3.10 地面曲率、平面曲率、剖面曲率的区别与联系;山体阴影的概念
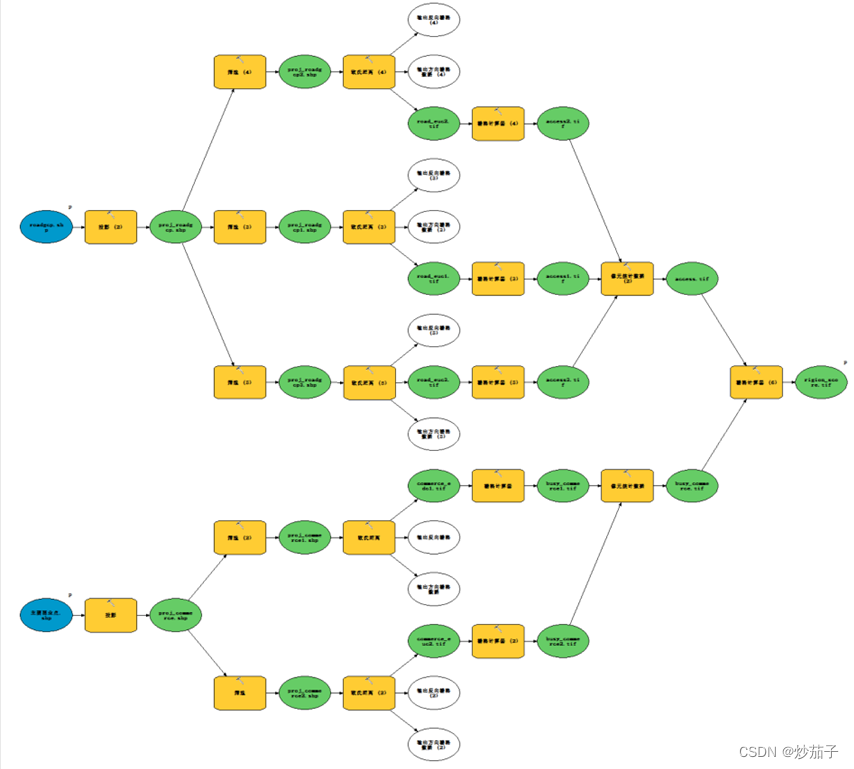
3.11 分区功能的原理与应用(请与教案第2章的思考题获取高程曲线、第3章思考题统计不同坡向的平均建筑密度并做直方图等结合复习);
3.12 统计分析:分区汇总统计的概念;统计分析的应用(结合PPT解决的问题);依据河流等级矢量线,提取每一级河流的平均高程。
3.13 水流方向矩阵、流水蓄积量等相关水文分析原理与应用;坡长提取方法;地形起伏度的提取;某市各县的沟壑密度的自动求取;DEM最大洼地的提取;(未写)
3.14 水库流域的提取、及在此基础上获取水库给顶水位高程的淹没范围、水库淹没面积、水库库容;利用流水累积量进行地形下挖;分级沟谷或河道的矢量线提取
3.15 流域高程归一化方法
04 第四章
4.1 空间叠置分析概念、主要的叠置分析
4.2 缓冲区分析的概念、定半径缓冲区与变半径缓冲区的概念、缓冲区分类
4.3 叠置分析的概念;各种叠置分析,如线与多边形的叠置分析应用;线与线叠置分析应用(如Stream Order与二级河流的流域);多边形与多边形叠置分析的应用(如利用点数据求取面要素中点某字段的最大值赋值给多边形字段)
4.4 Spatial Join的原理即应用,如求取行车时间在20分钟内居民点人口总数大于2万人的银行网点;
4.5 缓冲区和叠置分析案例的主要思想,主要侧重于应用,并注意与其他章节的结合,比如地形分析结合(地势北高南低的处理)、与空间量算的结合(可选面积为最大怎样实现?)
4.6 网络分析的概念、网络分析的主要功能、连通分量求解的概念;最佳路径分析的概念、TSP和VRP的概念、中国邮递员问题概念
4.7 两种基本的网络:传输网络和效用网络的概念和主要研究内容
4.8 服务区分析的原理与应用(高级应用的理解:就医方便程度评价;服务区交叠区域的提取、消防站盲区及其中心位置建立新消防站)
05 第五章
5.1 3D Feature Data的概念和创建方法
资料是在word上准备的,时间有限,直接粘贴了。
01 第一章
1.1 GIS空间分析的概念
空间分析是为解答地理空间问题而进行的数据分析与挖掘,是GIS的核心。
1.2 GIS空间分析的研究对象、研究目标
研究对象主要是矢量和栅格;
1.3 研究目标是:认知、解释、预报、调控。
认知:有效获取数据,再现事物本身
解释:理解空间数据的背景过程,揭示本质规律
预报:利用规律,建立模型预报
调控:对地理空间发生的事件进行调控
1.4 道路拓宽案例分析
探讨:某城镇拟对建城区某条道路进行拓宽,其拆迁标准为:
a)道路从原有的20m拓宽至60m;
b)拓宽道路应尽量保持直线;
c)部分位于拆迁区内的10层以上的建筑不拆除。
如何使用GIS进行道路拓宽的路线和费用分析?流程是怎样的?
答:
首先,对道路数据进行缓冲距离为20m的缓冲区分析得到要求拆迁区。(缓冲区工具)
然后,选择在此缓冲区内的建筑物要素(按位置选择工具)。
接着,通过按属性选择工具,筛选出10层以下的建筑物(按属性选择工具)。
在属性表中对选择的建筑基于估值字段进行汇总统计进而估算拆迁费用。(属性表计算几何, excel求和或汇总)(属性表+汇总)
1.5 GIS空间分析的核心问题
位置(Locations)
条件(Conditions)
趋势(Trends)
模式(Patterns)
模型(Models)
02 第二章
2.1 空间查询的概念、空间量算的概念
空间查询概念:从数据库中找出符合属性约束条件或空间约束的空间数据;
空间量算概念:对各种空间目标的几何参数进行量算与分析;(属性表-计算几何工具-周长、面积、坐标等等)
2.2 函数距离的概念
欧式距离(概念/工具)、曼哈顿距离
2.3 空间查询分类、空间相互关系查询
空间查询分类:属性查询、空间相互关系查询(查看ArcGIS按位置选择的诸多空间相互关系)、混合查询
2.4 空间量算主要内容;空间量算的应用(如求取面积、长度;比如各县沟壑密度中的面积计算)
理应大题: 求取面积、长度均可在属性表中右击字段 è 弹出选项框中 à 点击计算几何(calculate geometry) è 选取面积亦或长度计算即可;
若是给定各县面要素,如上操作即可即可。
属性表+添加字段工具+计算几何工具
2.5 欧拉数的概念、弯曲度的概念、简单图形概括的概念、平均最近邻分析的概念、空间自相关的概念、离散区域和连续区域的概念;
- 欧拉数的概念: 面状地物空洞数据量的度量。欧拉数=空洞数-(碎片数-1)=2。欧拉数越大,面状地物的破碎程度越大。
例如: ,对于该面要素类,空洞数为3,碎片数为2,所以欧拉数为3 – (2 - 1) = 2;
,对于该面要素类,空洞数为3,碎片数为2,所以欧拉数为3 – (2 - 1) = 2;
- 弯曲度的概念: 反映平均曲率的度量,(S = L/I),两点之间实际连线的长度与两点间的最短连线的长度的比值即为弯曲度,S越大弯曲程度越大。
- 简单图形概括:最大内切圆、最小外接圆、最小凸包;
- 平均最近邻(ArcGIS-Spatial statistic tools – 分析模式 – 平均最近邻 è 用于了解空间目标的一个分布情况例如聚集分布?/均匀分布?)
概念:根据每一个要素与其最近邻要素之间的平均距离计算其最近邻指数。(ArcGIS Help)
具体原理:测定每一个要素的质心与其最近邻要素的质心位置之间的距离,然后计算所有这些最近邻距离的平均值。如果该平均距离小于假定随机分布中的平均距离。则会将其视为是聚类要素。如果大于随机分布的平均距离,则视其为分散要素。平均最近邻比率通过观测的平均距离除以期望的平均距离计算得出。以下是一个输出范例:

很显然,它属于聚类要素,因为平均观测距离小于预期平均距离,平均最近邻比率 = 平均观测距离 / 预期平均距离.Z得分和p值与随机分布相关,也说明了这结果的一个置信程度。
2.6 空间自相关概念:反应地理单元某一属性与邻近区域同一属性值的相关程度。如果某一区域属性值均大于或小于平均值,则相关性(Moran’s Index)程度高
2.7 离散区域和连续区域的概念
离散区域分布模式:与点模式具有相似性,可利用点模式的研究方法
连续区域:等值线、高程曲线。
2.8 高程曲线的制作
以下等高线的制作,并非高程曲线的制作,高程曲线的制作见后续章节。
答:?加载DEM数据,通过ArcGIS è Spatial Analyst Tools è 表面分析 è 等值线即可完成等高线的制作;(等值线工具)
如何制作精美的明暗等高线呢?-_-‘~’
答:明暗是由于入射光造成的,所以这里还需要使用坡向数据,将栅格化的等高线与重分类的坡向相乘(0/1),最终以DEM作为灰色背景,调整等高线色调即可.以下为范例:

03 第三章
3.1 什么是Grid,Grid的行、列数与Cell Size和空间范围、离散型和连续型Grid的区别,Grid的No Data数据
- 什么是GRID(狗都不用)
GRID是ArcGIS中的一种栅格数据存储格式。它是由Esri开发的专有格式,用于存储和管理栅格数据。GRID格式提供了一种高效、紧凑的存储方式,支持空间索引和属性查询,适用于GIS分析和地理处理任务;
- GRID的行列数、CellSize、空间范围、Nodata
行数和列数:GRID格式的栅格数据由行和列组成,行数表示纵向(Y轴)上的单元数量,列数表示横向(X轴)上的单元数量。行数和列数决定了栅格数据的分辨率。
Cell Size:GRID格式的栅格数据中,每个单元(cell)在地面上表示的实际尺寸,通常为正方形。Cell Size越小,分辨率越高,空间信息的表达更为精细。
空间范围:GRID格式的栅格数据的空间范围是由四个边界坐标值(最小X值、最大X值、最小Y值、最大Y值)定义的矩形区域,表示栅格数据所覆盖的地理空间范围。
No Data值:GRID格式的栅格数据中,No Data值表示某个栅格单元在空间上不存在有效的地理信息。在进行栅格数据的分析和处理时,通常需要考虑No Data值的影响,避免对分析结果产生误导。
3.2 离散型和连续型Grid的区别
离散型栅格数据:每个栅格单元表示一个离散的地理现象或对象,如土地利用类型、行政区划等。离散型栅格数据中的数值表示类别,通常为整数。
连续型栅格数据:每个栅格单元表示一个连续的地理现象或属性,如地形高程、坡度等。连续型栅格数据中的数值表示连续变化的量,通常为实数。
需要注意的是,通常离散型GRID数据在ArcGIS中是具有属性表的,也就是说我们要想对栅格数据计算面积等需要属性表的操作,需要将栅格数据通过重分类等操作转化为离散型GRID格式。
3.3 空间分析的基本参数设置方法与意义,如掩膜的应用、空间分析范围、尺寸设置的作用、Cell Size的概念
以上均可在ArcGIS的环境设置完成.
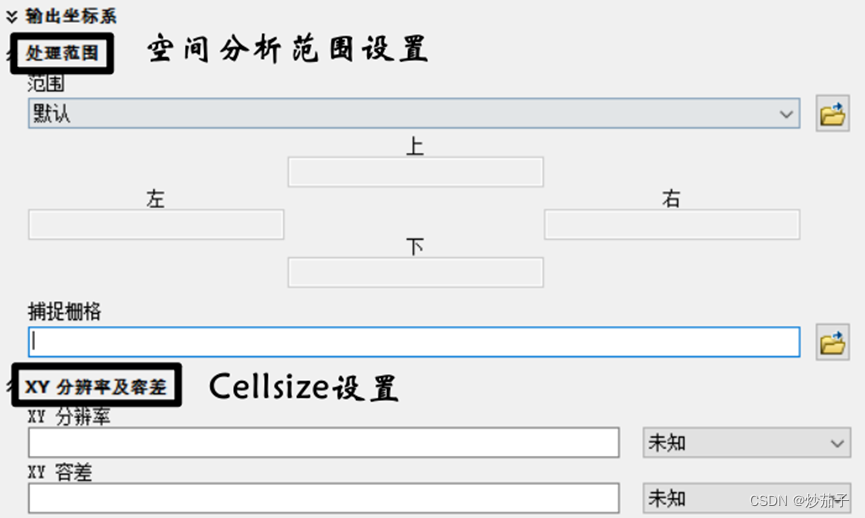

- 掩膜
掩膜是一种用于限定空间分析范围的技术。通过为分析设置掩膜,可以确保结果仅包含感兴趣区域内的数据。在ArcGIS中,可以使用"Environment Settings"中的"Mask"选项来设置掩膜。
- 空间分析范围
空间分析范围是指分析过程中涉及到的地理空间范围。设置空间分析范围可以确保分析结果只包含所需区域的数据。在ArcGIS中,可以通过"Environment Settings"中的"Processing Extent"选项来设置空间分析范围。
- CellSize
Cell Size 是指栅格数据中每个单元 (cell) 在地面上表示的实际尺寸。通常情况下,Cell Size 越小,分辨率越高,空间信息的表达更为精细。在进行空间分析时,需要根据实际需求和数据质量来设置合适的 Cell Size。在ArcGIS中,可以通过"Environment Settings"中的"Raster Analysis"下的"Cell Size"选项来设置。
尺寸设置?不知,或与图单位相关 è 输出坐标?地理投影坐标系?
3.3 Raster Caculator原理与应用(注意该知识甚至可能和遥感知识相结合,如在GIS中利用遥感TM影像获取植被指数;、种子点扩散算法的实现)、重分类原理与应用(注意重分类可将Nodata变为有值,重分类的结果为离散型栅格数据)
- 植被指数的计算
假定L8有两个波段影像: B4.tif, B5.tif.那么NDVI植被指数的计算如下:

- 种子点扩散算法
~~~~~~~~~~~我先讲讲底层如何实现
准备数据:确保已经获取了火点位置和GEMI-B指数栅格数据。
将火点位置转换为栅格数据:首先需要将火点位置数据(矢量)转换为与GEMI-B指数栅格数据具有相同分辨率、空间参考和像元大小的栅格数据。在ArcGIS中,可以使用"Feature to Raster"工具进行转换。
初始化种子点集合:将转换后的火点位置栅格数据中的非零像元作为初始种子点集合。
种子点扩散:编写一个循环,以处理种子点集合中的每个种子点。在每次迭代中:
a. 对每个种子点,检查其周围8个相邻像元。
b. 对于每个相邻像元,计算以该像元为中心的3x3矩形窗口的GEMI-B指数的标准差。
c. 如果相邻像元的标准差小于0.9,则将其标记为火烧迹地,并将该像元添加到种子点集合中以进行下一次迭代。
d. 从种子点集合中移除已处理的种子点。
循环结束:当种子点集合为空时,即没有新的种子点需要处理时,循环结束。
输出结果:将标记为火烧迹地的像元生成一个新的栅格数据,即火烧迹地提取结果。(如果需要,可以将最终的火烧迹地栅格数据转换为矢量数据(如多边形),以便进行进一步的分析和可视化。在ArcGIS中,可以使用"Raster to Polygon"工具进行转换。)
~~~~~~~~~~~但是实际上更简单的方法:
首先,对于GEMI-B指数数据,通过焦点统计计算每一个像元的标准差,然后对焦点统计之后的GEMI-B数据进行重分类,小于0.9赋值为1,大于的设置为Nodata;然后将该数据和种子点数据全部转化为矢量数据,然后进行按位置选择,将包含种子点的面要素选中,这些面要素就是我们要的火迹地。
- 重分类
重分类,老生常谈。就是将像元值按照某种分类标准重新赋值(逐像元)。
工具在 ArcGIS è Spatial Analyst Tools è 重分类 è 重分类工具
3.4 直线距离的原理与应用(请结合实验三复习)、区域分配的原理与应用(如泰森多边形插值的实现)
实验三思路:
- 直线距离的原理和应用
这里以欧式距离(ArcGIS è Spatial Analyst Tools è 距离 è欧式距离 )为例作为说明,输出栅格数据中任一一像元的值表示该像元到最近栅格/要素源的最近欧式距离.
应用:城市土地评价;
例如:商业繁华度指标:
Fi=fi(1-di/d);F=max(Fi)
其中:fi为某级商业中心功能分;d为某级商业中心的服务半径;di为格网中心到该设施直线距离;F为所有商业中心对该格网作用分最大值。现需要计算一级商业中心(fi取100;d取3500)对所有格网的F值?
由于要计算MAX,而由于限制只有一级中心,所以fi和d给定,要是Fi最大,即di最小。 è 求解最小di
又由于一级商业中心点数据给定,通过欧式距离可计算di。最后通过栅格计算器求得Fi。如果存在多个级别的商业就分别求取,然后if(con)判断求取更大的那个。
- 区域分配
我首先还是想到欧式分配,但是欧式分配得到的分配区域与泰森多边形有本质区别虽然他们图形长得像,欧式是各个方向精确的所以边界显得圆滑,而泰森多边形貌似是8个方位所以显得道貌岸然,仪态端庄。
这里说一说泰森多边形的基本原理吧。
泰森多边形的基本原理是,每个区域中的点都比其他区域的生成点更接近该区域的生成点。换句话说,给定平面上的一组点P,对于P中的每个点p,我们可以定义一个泰森多边形区域V(p)。V(p)中的所有点都比其他点集P中的任何其他点更接近p。泰森多边形的边界是两个相邻泰森多边形区域的生成点的垂直平分线。这是基本的思路
3.5 栅格数据转换为矢量多边形(如将分析的栅格图层转换为矢量多边形),特别地,给你一个流域DEM,流域外为无数据,如何自动获取流域矢量面?
栅格转矢量一般就使用ArcGIS è Conversion Tools è 由栅格转出 è 由栅格转面;
而对于给定的流域DEM,应该也是类似的使用该工具,字段选择像元值即GRID_CODE。
这个感觉怪怪的,不明所以这个问题。
3.6 密度功能的概念;密度功能的原理与应用(如提供人口点数据,获取人口密度大于1000的区域)、点密度和核密度区别于联系、人口密度与空间插值的差异
- 密度功能的概念?×密度函数?√
密度函数是一种表示地理空间分布特征的方法,用于描述目标在空间上的分布密度。
- 密度功能的原理和应用:密度函数根据空间目标的分布情况,通过计算目标在某一空间范围内的数量或权重,将其转换为目标的分布密度。
若给定人口点数据,那么通过ArcGIS è Spatial Analyst Tools è 密度分析 è 用核密度吧 è 得到人口密度区域 è 使用栅格计算器(ArcGIS è Spatial Analyst Tools è 地图代数 è 栅格计算器) è 使用Con函数做if判断即可得到人口密度大于1000的区域。
- 点密度和核密度的区别与联系
参考:https://blog.csdn.net/weixin_44380086/article/details/124634837
二者的区别在与获得密度栅格的算法不同,搜索半径内离中心像元的远近具有不同的权重。点密度是把每个像元的周围都定义了一个邻域,将落入邻域内的点的数量相加,然后除以邻域面积,即得到点要素的密度,邻域内个点权重相同;核密度是通过核函数进行密度计算,中心像元获得最高值,在搜索半径内向周围发散,邻域边界的像元值为0,离中心越近权重越高,反之越低。总的来说,核密度分析计算结果较为平滑。
以下是图解释:

- 人口密度和空间差值的差异:
参考:https://blog.csdn.net/weixin_37659245/article/details/105381899
插值分析与密度分析的本质就是完全不一样的。 首先,插值分析的目的是对未知区域的数据进行估算,而密度分析仅表现现有数据的聚集情况。
其次,插值分析并不关注空间尺度的问题,而密度分析对空间尺度关注点特别高。
最后,就是插值分析对用于插值的属性是必须要有的,而密度分析最低仅需要有点的位置即可。
我说说我的简单理解:插值分析是一种基于已知点数据预测未知点数据的方法。空间插值可以用于预测人口、气候、地形等地理特征在空间上的分布。空间插值的结果与已知数据处于同等地位,均是相同单位相同物理意义。例如你用降水数据插值后还是降水数据,只是原来的是少数几个点的降水数据,现在是整个面的栅格降水数据。
对于人口密度而言:人口密度是指在一定地理范围内的人口数量与该范围的面积之比。
3.7 邻域分析的概念,邻域分析的原理与应用(如根据建筑面图层如何求取建筑密度;求取在2km直线距离内居民点人口总数大于2万人的银行网点);
- 邻域分析的原理
以ArcGIS的邻域分析为例说明:以计算像元为中心的窗口范围内计算窗口统计值,并以该统计值作为中心像元的分析结果值。 - 邻域分析的应用
根据建筑面图层如何求取建筑密度;
思路如下(不完全一致仅供参考):

答:建筑面图层 è 栅格化 è 栅格计算器/重分类(将建筑像元设置为1,非建筑像元设置为0) è 对栅格化的重分类结果进行焦点统计(Mean)计算建筑密度;
求取在2km直线距离内居民点人口总数大于2万人的银行网点。
答:第一种方法,非第三章内容了:首先是按属性选取出所有人口数大于2万人的居民点,然后按位置选择出距离银行网点2km内的居民点(勾选选中要素);
第二种方法:只使用第三章内容,稍显啰嗦。首先是利用点统计(注意不是焦点统计, 选取sum),对居民点要素进行统计,字段需要选取人口数字段得到栅格影像,对其进行重分类(是否大于2万人, 不大于的设置为Nodata)并栅格转矢量,然后基于矢量面对银行点进行按位置选取。
3.8 表面功能的原理与应用,山顶点提取的关键方法和步骤;
- 表面功能的原理
这里不大不可能来考名词解释,所以解释一下表面分析常用的功能:
等值线(等高线等的绘制)、坡度坡向(多用于选址分析以及流域分析)、山体阴影(透明度调整叠加显示将绝杀)。
- 山顶点的提取
将DEM进行焦点统计(窗口设置的大一点11、12可以),然后将结果与原始DEM作差并与0作比较二值化。最后目视解译去除不合理山顶点即可。
3.9 空间插值的概念;单点移面插值方法的概念;自然邻点插值的概念;趋势面插值的概念;泰森多边形插值的概念;克里格插值的概念
知道名词就好,到时候直接拿来用就行
3.10 地面曲率、平面曲率、剖面曲率的区别与联系;山体阴影的概念
地面曲率包括:平面曲率和剖面曲率;
平面曲率:平面曲率是指地表在水平方向上的曲率,用于描述地表在地平面上的弯曲程度。
剖面曲率:剖面曲率:剖面曲率是指地表在垂直方向上的曲率,用于描述地表在剖面上的弯曲程度。
山体阴影的概念:山体阴影是指地形表面由于太阳光线照射角度和方向的影响,在一定区域内形成的明暗对比。
3.11 分区功能的原理与应用(请与教案第2章的思考题获取高程曲线、第3章思考题统计不同坡向的平均建筑密度并做直方图等结合复习);
分区功能主要使用到分区统计、
- 高程曲线的获取
结果理应如下:
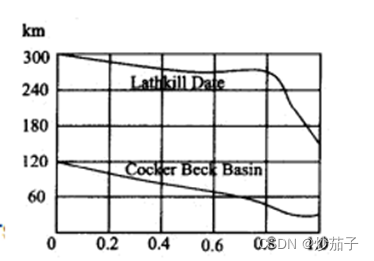
实际操作:首先我们可以观察上高程曲线图,大致分为了0~0.2, 0.2~0.4, 0.4~0.6, 0.6~0.8, 0.8 ~1.0;
因此我们将DEM数据按照上述的分类标准进行重分类,据此对原始DEM进行面积制表(栅格计算中我觉得不鸣则已一鸣惊人的工具),得到dbf转化为excel,然后进行累计求和再除以MAX,查看一下DEM的最大最小值最后出一下图就可以了。
至于,按流域进行类似操作
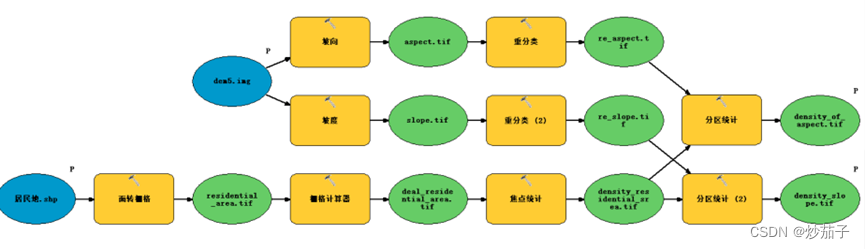
- 平均建筑密度+直方图
此处不仅仅完美解决了上述问题,而且还添加了坡度进去,由于流程图十分详细这里不过多介绍。
3.12 统计分析:分区汇总统计的概念;统计分析的应用(结合PPT解决的问题);依据河流等级矢量线,提取每一级河流的平均高程。
- 分区汇总统计的概念:
以一个离散型Grid作为分区,统计同区域另一个Grid每个区域的Area、Mean等。
- 提取每一级河流的平均高程:
既可以使用分区统计也可以使用以表格显示分区统计工具,这里仅以分区统计演示。首先,将河流等级矢量线(矢量栅格皆可)进行分区统计,字段选择描述河流等级的字段,赋值栅格选择DEM,如此可以获取每一级河流的平均高程。
3.13 水流方向矩阵、流水蓄积量等相关水文分析原理与应用;坡长提取方法;地形起伏度的提取;某市各县的沟壑密度的自动求取;DEM最大洼地的提取;(未写)
水流方向矩阵是基于DEM得到的,具体是水流方向矩阵中每一个像元值表示该像元中的水流向周围8个像元的指向,具体指向哪一个取决于该像元与周围像元的高程差值,差值最大的像元即为指向方向,方向采用8个数表示如下:
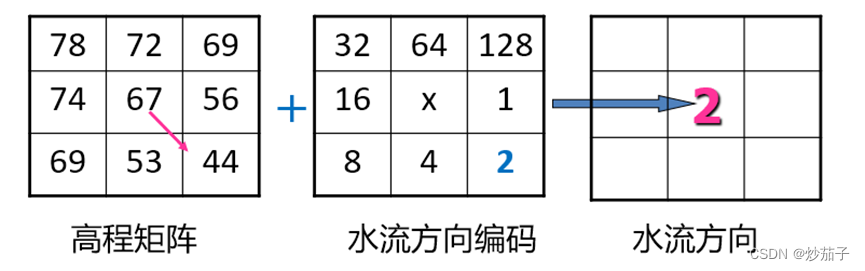
流水累积量矩阵:假设研究区域每个格网有一个单位1的水量,按照水流方向累积计算每个格网的上游来水量。
如何获取流域?
两种方法,两种方法的公共操作都是:基于DEM数据通过填洼处理,再通过流向工具计算水流方向矩阵;
对于第一种方法(这种方法简单但是应该不考):直接使用盆域分析工具(基于水流方向数据)得到流域数据;
第二种方法(但凡提及倾斜点、出口等一律通杀):基于刚刚的水流方向矩阵进行流水累积量矩阵的获取(捕捉倾斜点时需要作为输入数据),通过倾斜点数据(如果没有需要自己创建要素,基于各种途径)使用捕捉倾斜点使得倾斜点数据精确,然后通过集水区工具通过输入流向数据和倾斜点数据计算流域得到流域面数据。
3.14 水库流域的提取、及在此基础上获取水库给顶水位高程的淹没范围、水库淹没面积、水库库容;利用流水累积量进行地形下挖;分级沟谷或河道的矢量线提取
- 水库流域的提取及在此基础上获取水库给顶水位高程的淹没范围、水库淹没面积、水库库容。
我们先来计算水库流域的提取,基于水库所在位置DEM数据进行填洼然后通过流向工具计算水流方向矩阵,基于该流水方向矩阵获取流水累积量矩阵(用于倾斜点捕捉作为输入数据),然后获取该水库的出水口位置(通过创建点要素),由于手动创建具有一定的偏差,因此此处再使用捕捉倾斜点工具将我们创建的倾斜点数据进行偏移校正。然后基于填洼后的DEM数据和倾斜点数据使用集水区工具获取水库的流域区域。
接着假定题目给定水位高程为x,那么首先我们需要基于前面得到的流域数据对原始DEM数据进行掩膜,然后对其掩膜后的DEM数据使用栅格计算器或者重分类,将小于x的部分设置为1,大于x的部分设置为nodata或者其他值得到离散型的GRID数据,如此得到掩膜的范围(栅格值为1表示淹没);
再通过其属性表通过计算几何得到每一个面要素的面积从而得到淹没面积。至于库容的话,我们首先需要对DEM数据进行栅格计算,求解每一个像元位置的库容,主要就是DEM * 像元分辨率的²;然后基于刚刚得到的淹没区域对栅格计算后的DEM进行分区统计(SUM),然后得到库容。
- 利用流水累积量进行地形下挖
这个暂时不明确是什么,百度之后感觉如下操作:
对于得到流水累积量使用栅格计算器对DEM进行地形下挖,例如:
Con("FlowAccumulation" > 1000, "DEM" - 10, "DEM")
当流水累积量大于1000,那么DEM下挖10m,否则不下挖。
- 分级河谷或河道的矢量线提取
前面略 è 对于得到流水累积量进行重分类(大于阈值赋值为1,小于阈值的赋值为Nodata)得到河网,然后使用河网分级工具对前面的河网进行分级,最后使用栅格河网矢量化工具对其进行矢量化即可。
3.15 流域高程归一化方法
这里应该是打算得到各个流域的相对高程,所以基于分区统计得到各个流域的最大最小高程(max.tif, min.tif),然后使用栅格计算器得到归一化的流域高程,公式如下:

04 第四章
4.1 空间叠置分析概念、主要的叠置分析
- 叠置分析概念
将有关主题层组成的各个数据层面进行叠置产生一个新的数据层面,其结果综合了原来两个或多个层面要素所具有的属性,并生成新的空间关系和属性
- 主要的叠置分析
基于栅格的叠置分析
基于矢量的叠置分析:
多边形叠置分析: Union\Intersect\ Symmetrical Difference\ Identity
相交运算: Intersect:空间上求取公共部分,属性字段取并,属性取值依据原有位置上的值。
空间连接:具体查看ArcGIS Help;空间连接是根据空间关系将一个要素类的属性连接到另一个要素类的属性。目标要素和来自连接要素的被连接属性写入到输出要素类。
说人话就是,如果目标要素与连接要素处在同一位置(此处的同一位置不同于平常,后续说明),那么就将连接要素中的你需要的字段复制粘贴(一般如此)到目标要素中。所以空间连接本质上就是字段的匹配,不过和之前我们在属性表中的字段连接和关联不同,原先的连接和关联是基于主关键字段进行匹配,而此处是基于空间位置关系进行字段的匹配。
例如,目标要素为点要素(假定只有一个),连接要素为面要素(假定为两个不一样的面要素,但在其面范围内都包含了那个点要素),空间位置大致为:

那么,按照我们之前的假定,我们应该将所有包含点要素的面要素(因为他们都在同一位置)中的字段全部复制到点要素中去,但是如此,就会产生副本也就是说这一个点要素会变成两个点要素,两个点要素处于同一位置但是具有不同的属性(均包含原始点要素的字段,但是包含来自不同面要素的字段),这种字段的连接方法称之为JOIN_ONE_TO_MANEY;如果我们对两个面要素(如果有更多亦是类似处理)的字段进行聚合,例如面要素中某一字段面要素A是10,面要素B是12,那么聚合之后的字段值为22(默认如此),所以给点要素该字段的值即为22,这种字段的连接方法称之为JOIN_ONE_TO_ONE。
前面我所说的处于同一位置其实是有问题,不过是暂时方便理解,实际上应该说是目标要素与连接要素满足某一种位置关系,之前我都是按照包含关系进行说明,但是实际上这些位置关系用户可自行选择(默认是相交),以下是ArcGIS中空间连接工具(Spatial join)的界面:
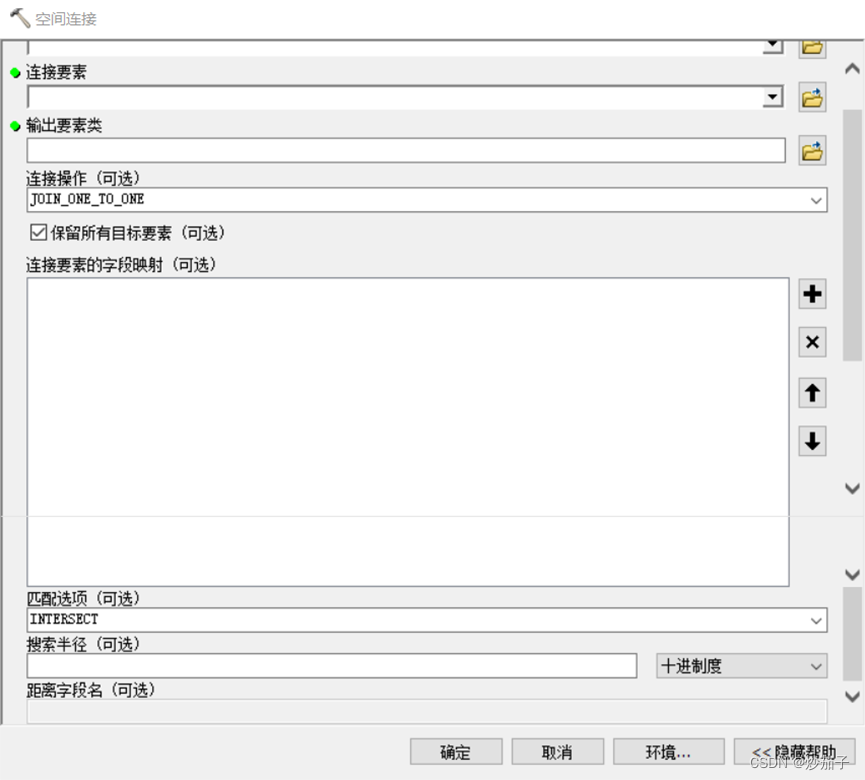
那么我们来解决PPT上的问题:求取满足在500m范围内至少5个顾客点的银行。
首先,为顾客点要素添加新字段one,该字段内所有要素的值均为1;
接着,使用空间连接字段,目标要素选择银行(因为我们要选取的是银行),连接要素选择顾客点要素(因为我们选取银行的基于条件是顾客点数量),字段映射我们选取one字段(即将连接要素中的哪些字段映射到目标要素中),连接操作选取JOIN_ONE_TO_ONE(如此,满足位置关系的所有顾客点要素的one字段值便会进行累加,这样我们可以清楚银行点满足该位置关系(500m范围)的顾客点数量),匹配项我们需要选取WITHIN_A_DISTANCE(ArcGIS Help:如果连接要素在目标要素的指定距离之内,将匹配处于该距离内的要素。在搜索半径参数中指定距离),搜索半径选取500m(注意单位,为了避免出错,最好将当前操作的所有文件全部转化为投影坐标系而不是地理坐标系)。最后对于得到的输出要素类我们只需要进行按属性选择,将one字段中大于5的银行要素点选出即可。<说明,其实为了不出错,最好在字段映射的合并规则中选取sum求和,当然你也可以使用计数我猜测它可以完成上述工作而且无需添加新字段当然手上没有数据无法验证>
似乎我们没有说明,如何使用第三章的知识进行解决?
这里给出第三章的解决方法:其实和前面的类似,首先,为顾客点要素添加新字段one,one字段所有要素的值均为1;接着,对顾客点要素进行点统计,注意参数的选取,字段需要选取one字段,邻域分析选取圆形(按照题目要求理应如此),邻域半径选取500,单位选取地图(这里则必须将你的文件转化为投影坐标系,不转则此处的地图单位将是度),统计类型需要选取SUM求和。对于得到的栅格进行重分类,将像元值大于5的赋值为1,其余赋值为Nodata,然后将其转化为矢量数据,将其与银行点要素进行叠置分析(相交)或者按位置选择等等都可以将满足要求的银行点选出。
4.2 缓冲区分析的概念、定半径缓冲区与变半径缓冲区的概念、缓冲区分类
- 缓冲区分析的概念
缓冲区分析是围绕地理要素一定宽度(缓冲距离)的区域获取,用于分析地理要素与周围要素之间的空间邻近性。缓冲区分析主要基于点、线、面进行。
- 定半径缓冲区
很简单,就是在缓冲距离这里;假定对某要素类进行缓冲区分析,那么对于该要素类中的所有要素,他们的缓冲距离都是相等的,这就是定半径!
- 变半径缓冲区
也很简单,仍然是在缓冲区距离这里;假定对某要素类进行缓冲区分析,那么对于该要素类的所有要素,他们的缓冲距离可能各不相同,可能你会问,缓冲距离不一样怎么进行缓冲区创建?很简单,使用要素的某一字段,这一字段表示缓冲距离,对于不同的要素,他们的字段值可能不一致,这就导致不同的要素的缓冲距离不一样了,这就是变半径!
- 缓冲区分类
按半径:定半径缓冲区、变半径缓冲区、环状缓冲区
按对象影响力特点:均质缓冲区、非均质缓冲区
按分析方法:栅格缓冲区和矢量缓冲区
4.3 叠置分析的概念;各种叠置分析,如线与多边形的叠置分析应用;线与线叠置分析应用(如Stream Order与二级河流的流域);多边形与多边形叠置分析的应用(如利用点数据求取面要素中点某字段的最大值赋值给多边形字段)
- 叠置分析的概念
将有关主题层组成的各个数据层面进行叠置产生一个新的数据层面,其结果综合了原来两个或多个层面要素所具有的属性,并生成新的空间关系和属性。
- 公园选址
说一说题目吧:
选址条件:
1)相对安静(离主要公路0.2公里之外)且交通方便(离主要公路0.8公里之内)
2)公园最好依附在大小适中的天然河流上(大小适中指二级河流)。
3)公园选址要避免沼泽地;
(假定有交通要道数据、土地利用数据、河流数据)这个我的基本思路就是,求取各个部分区域,最后求交。首先,从交通要道数据、土地利用数据、河流数据中分别按属性提取出主要公路、非沼泽地(Not(landovae = ‘沼泽地’),若土地利用数据为矢量数需要先转化为栅格数据再进行按属性选择)、二级河流数据;接着,对主要公路分别进行200m、800m的缓冲区分析(注意坐标系需要为投影坐标系,地理坐标系的单位是度/°),然后对生成的两个缓冲区进行叠置分析(裁剪/擦除…均可),得到0.2km~0.8km的缓冲区;接着,对二级河流、非沼泽地、0.2km~0.8km主要公路缓冲区三者进行叠置分析(相交),最终得到满足要求的公园选址位置。
- 二级流域的获取
问题是这个样子:依据区域DEM数据、河流数据,提取二级河流流域。
思路:既然明确说明了需要二级河流流域,那么获取流域我们只能使用集水区工具而不能使用盆域分析工具进行流域的自动获取。要使用集水区工具进行二级流域的获取,需要输入水流方向数据和倾斜点数据,对于水流方向数据比较简单,但是对于倾斜点数据这里需要注意我们需要的时二级流域的倾斜点或者说是出口,那么二级河流的出口在哪里?是不是就是在二级河流汇流进一级河流时,二级河流就不复存在了,所以二级河流与一级河流的交点即是二级河流的倾斜点或者说出口了。
步骤:首先,对DEM数据进行填洼处理,然后使用流向工具对其进行水流方向数据的获取,在此基础上使用流量工具基于填洼DEM数据、水流方向数据进行流水累积量数据的获取(用于倾斜点的获取),接着我们对河流数据按属性提取分别得到一级河流和二级河流数据并进行相交处理(注意输出要素类型必须指定为点,否则输出线),得到粗的倾斜点数据,使用捕捉倾斜点工具基于流水累积量数据和粗倾斜点数据进行倾斜点的精确捕捉。然后使用集水区工具基于流向数据和倾斜点数据进行二级河流流域的提取。
- 利用点数据求取面要素中点某字段的最大值赋值给多边形字段
我第一时间想到的就是,why not spatial join。很显然这是进行字段的映射,而且从题中面要素中的点 è 要求点要素在面要素 è 包含的位置关系 + 字段连接。
步骤:假定某字段为max字段。使用空间连接工具,目标要素为面要素(因为题目要求将字段赋值给多边形字段显然想要的是面要素),连接要素为点数据。字段映射为max字段,字段中合并规则选取MAX。匹配规则为CONTAIN(ArcGIS Help:如果目标要素中包含连接要素中的要素,将匹配连接要素中被包含的要素。目标要素必须是面或折线。对于此选项,目标要素不能为点,且仅当目标要素为面时连接要素才能为面)。如此可以实现题目要求。
4.4 Spatial Join的原理即应用,如求取行车时间在20分钟内居民点人口总数大于2万人的银行网点;
这个题可能比较难,或许也很简单。假如只给定了银行网点和居民点数据,那么此题将应该简单至极。由于我们无法进行20min的直接衡量,所以按照实际的行车速度将20min转化为距银行网点距离,按照此距离进行空间连接,目标要素选择银行网点,连接要素选择居民点,字段映射传入居民点的人口总数字段即可,合并规则为SUM求和,连接操作为:JOIN_ONE_TO_MANY。匹配规则当然应该是WITHIN_A_DISTANCE(如果连接要素在目标要素的指定距离之内,将匹配处于该距离内的要素。在搜索半径参数中指定距离。),搜索半径为前面换算的距银行网点距离。如此对输出的新银行网点数据按属性选择,将人口总数大于2万人的银行选出;
如果还给定了交通道路数据,那么此题还涉及了交通网络知识。首先是基于银行网点和交通道路数据进行网络数据集的构建,成本或者阻抗选取行车时间(行车时间通过交通道路长度字段加以计算, time = L / speed),然通过建立服务区(10min阻断),将得到的服务区导出为shp文件(含有银行网点字段信息的面要素类),在此基础上进行空间连接,参数选取类似,仅匹配规则应该换为CONTAINS(ArcGIS Help:如果目标要素中包含连接要素中的要素,将匹配连接要素中被包含的要素。目标要素必须是面或折线。对于此选项,目标要素不能为点,且仅当目标要素为面时连接要素才能为面。)。然后为了我们能够原滋原味的获取满足要求的银行网点而不是对应的面要素,我们可以将银行网点与对应的面要素进行字段联合或者连接(都可以操作略有不同),然后进行按属性选取得到满足要求的银行网点。
4.5 缓冲区和叠置分析案例的主要思想,主要侧重于应用,并注意与其他章节的结合,比如地形分析结合(地势北高南低的处理)、与空间量算的结合(可选面积为最大怎样实现?)
此处模棱两可,仅简单说明,思想就不说了,自行体会。地势北高南低处理,不清楚,可能是对DEM进行坡向和坡度处理?然后选取出坡度满足一定阈值,坡向(坡向:斜坡的面对的方向。给定点位的坡向定义为斜面法线在平面上的投影和正北方向之间夹角)应该为180左右的北高南低地势区域?;
对于可选面积最大,可能就是属性表计算几何获取面积,然后按属性选择得到最大面积的要素。
以下内容暂时无
4.6 网络分析的概念、网络分析的主要功能、连通分量求解的概念;最佳路径分析的概念、TSP和VRP的概念、中国邮递员问题概念
- 网络分析的概念
- 网络分析的主要功能
- 连通分量求解的概念
- 最佳路径分析的概念
- TSP、VRP的概念
- 中国邮递员的问题概念
4.7 两种基本的网络:传输网络和效用网络的概念和主要研究内容
4.8 服务区分析的原理与应用(高级应用的理解:就医方便程度评价;服务区交叠区域的提取、消防站盲区及其中心位置建立新消防站)
ArcGIS传输网络
创建步骤,网络属性的创建
05 第五章
5.1 3D Feature Data的概念和创建方法
5.2 3D模型的概念;表面数据的概念;TIN概念
5.3 TIN模型与Arc/Info的TIN
5.4 TIN的显示风格化和TIN的创建方法
5.5 Terrain概念
5.6 三维透视观察的一些关键技术(可能与其他章节结合,如水库大坝和水库水面的三维展示);可视区分析的概念、通视性分析的概念
5.7 三维分析模块的表面分析、数字化小区关键技术