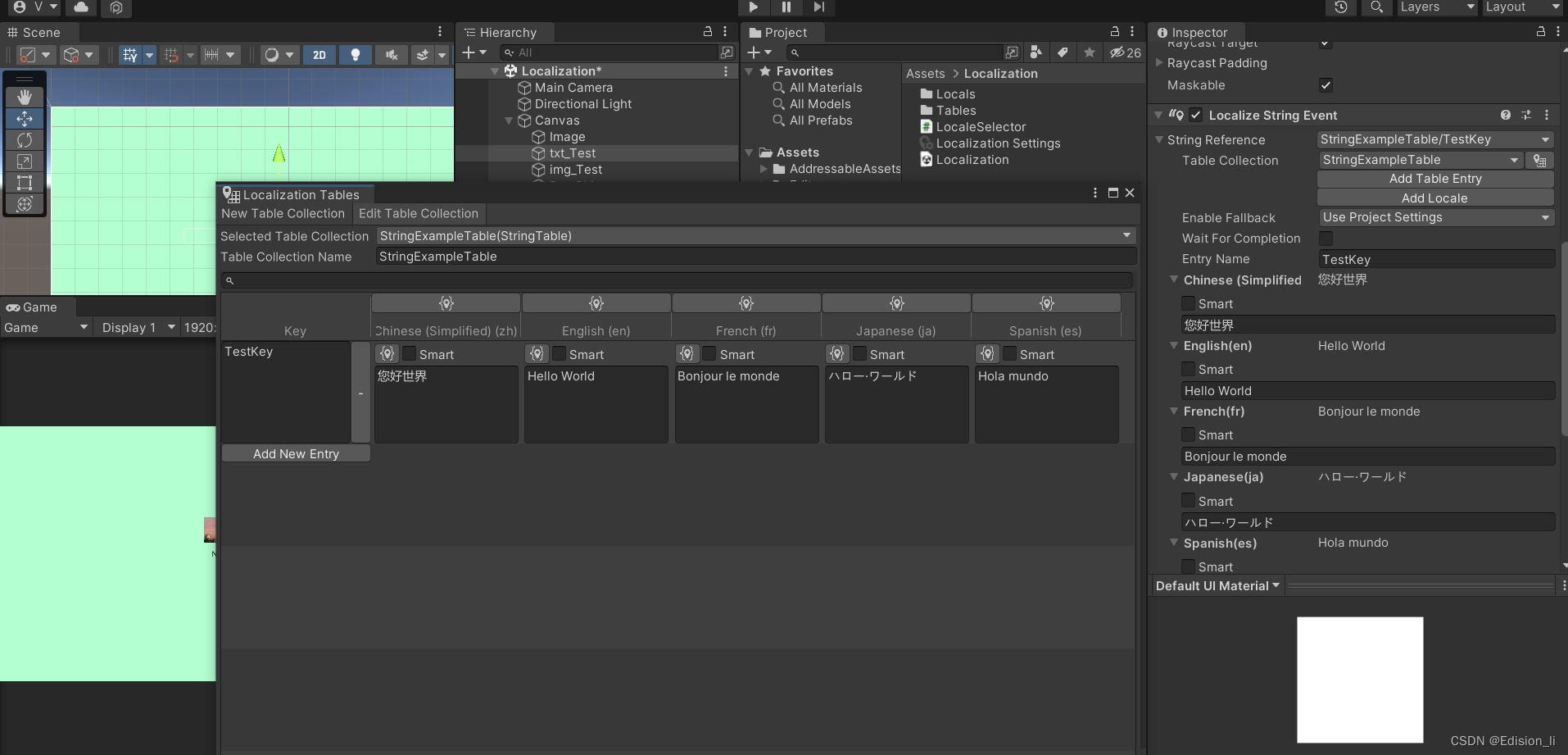
从源码的角度 :map --> sort —> copy --> sort -->reduce sort —> copy --> sort属于shuffle
InputFormat数据输入
切片与MapTask并行度决定机制
1)问题引出
MapTask的并行度决定Map阶段的任务处理并发度,进而影响到整个Job的处理速度。
思考:1G的数据,启动8个MapTask,可以提高集群的并发处理能力。那么1K的数据,也启动8个MapTask(启动也需要花费大量时间,而且消耗资源),会提高集群性能吗?MapTask并行任务是否越多越好呢?哪些因素影响了MapTask并行度?
2)MapTask并行度决定机制
数据块:Block是HDFS物理上把数据分成一块一块。数据块是HDFS存储数据单位。
MapTask数据片的数量决定,数据片的数量由片的大小和文件数量决定。一片就是一个MapTask
数据切片:数据切片只是在逻辑上对输入进行分片,并不会在磁盘上将其切分成片进行存储。数据切片是MapReduce程序计算输入数据的单位,一个切片会对应启动一个MapTask。
数据切片与MapTask并行度机制
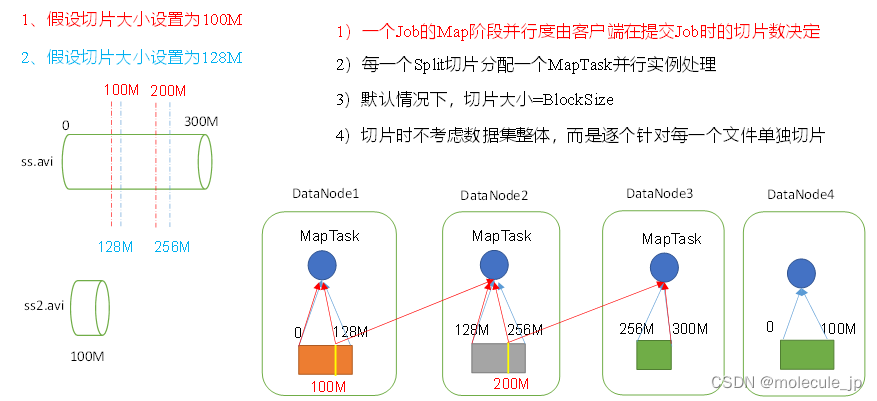
如果跨节点获取数据,非常消耗网络资源,网络资源很宝贵,而且节点上跑很多东西,kafka,zookeeper等。







![[Java]JavaWeb学习笔记(动力节点老杜2022)【Javaweb+MVC架构模式完结】](https://img-blog.csdnimg.cn/f6a00f3b9447476b91e2bb76e1d3f93e.png)