一、什么是机器学习
机器学习指的是,在没有明确设置的情况下,使得计算机拥有自我学习能力的领域。
二、监督学习和无监督学习
2.1 监督学习
监督学习是指,我们给予算法一个数据集,其中的数据包含了若干个标签。一个例子就是给出1万张水果的图片,并且每一张图片都标记好了该图片属于哪种水果。换言之,每个例子都会有一个“正确的答案“,用于告诉计算机该数据例应该得出什么样的结果。还有一个例子就是,给予一个房子面积和价格的数据集,这个数据集可以组成一个离散的图表,其中数据是房屋的大小,而价格就是标签
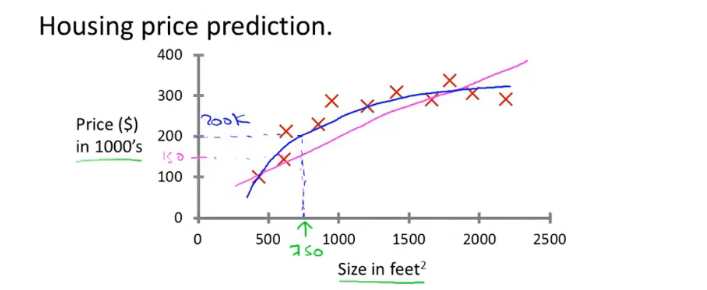
那么机器学习算法的任务就是根据已有的离散的房价数据,组织出一条连续的曲线。也就是说,从已有的数据中推测出更多的数据的答案。用更专业的属于来说,这是一个回归问题,也就是试图用离散的数据预测出连续的属性
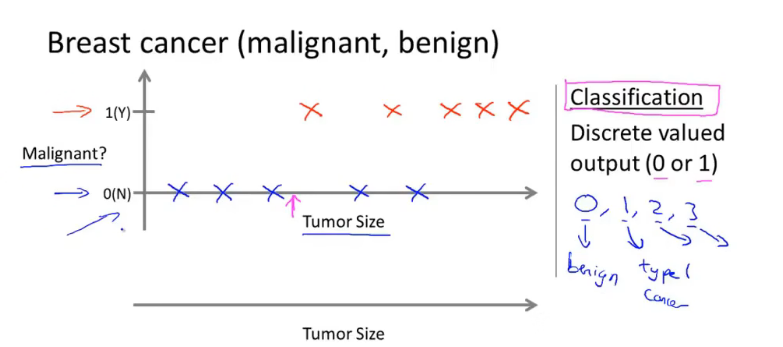
另外还有一个例子是,给出一个数据集,里面是若干乳腺肿瘤的大小以及该肿瘤是否是恶性肿瘤。根据该数据集推算出某个大小的肿瘤是恶性的还是良性的。用专业术语来说,这是一个分类问题,指的是我们需要预测的是一个离散的输出值。
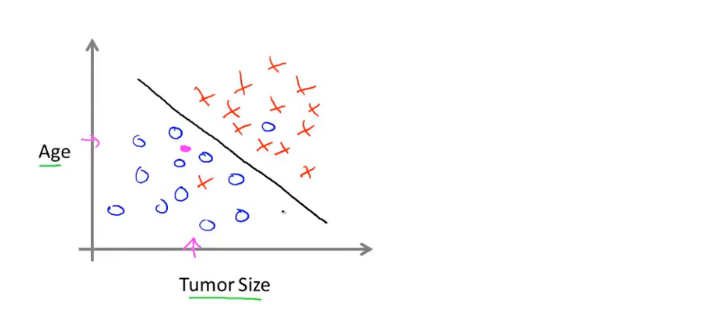
当然,对一个目标的预测往往不能只依靠一个属性,也可以加入多个属性对结果进行预测,比如结合病人的年龄和肿瘤的大小进行预测
2.2 无监督学习
在无监督学习中,数据集中的数据不会包含任何的标签或者有着相同的标签,程序需要自行地将数据进行处理,而无监督学习算法可能判定若干个数据为一个簇
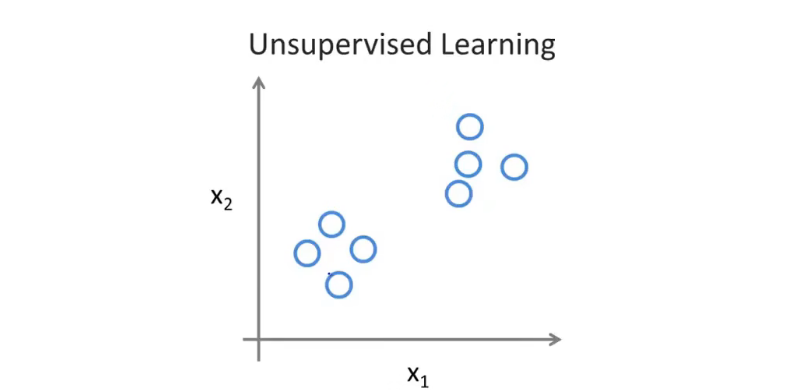
比如上述例子,程序可以将距离较近的点视作为一个簇,上图可以氛围两个簇,这又称之为聚类算法。
无监督学习的应用场景有很多,比如说在大型数据中心中,使用无监督学习找出哪些服务器数据交换更频繁,并且将他们放在一块,在社交网络分析中,可以通过各平台的关注和交流频率,划分出一个个用户簇,这些用户簇内的用户大概率是相互认识的,即使可能有些人你并没有关注他。
另外一个经典问题是鸡尾酒会问题,该问题是,在一个有两个人的鸡尾酒舞会上聊天,他们每个人身上都有一个麦克风,在A
的麦克风录制的音频中,响度较高的为A说的话,响度较低的为离A有一定距离的B说的话。使用无监督学习能够将两个说的话分离开来,这也是在复杂声音环境下的麦克风降噪算法的原理












![[架构之路-193]-《软考-系统分析师》-2-应用数学 - 项目周期与关键路径(PERT图、甘特图、单代号网络图、双代号网络图)](https://img-blog.csdnimg.cn/img_convert/b3a34093960e5ee0237313a2b2d0f32d.jpeg)