前言
本文章收录在MySQL性能优化+原理+实战专栏,点击此处查看开篇介绍。
本文摘录自 ▪ 小孩子4919《MySQL是怎样运行的:从根儿上理解MySQL》
 到现在为⽌,MySQL对于我们来说还是⼀个⿊盒,我们只负责使⽤客户端发送请求并等待服务器返回结果,表中的数据到底存到了哪⾥?以什么格式存放的?MySQL是以什么⽅式来访问的这些数据?这些问题我们统统不知道?
到现在为⽌,MySQL对于我们来说还是⼀个⿊盒,我们只负责使⽤客户端发送请求并等待服务器返回结果,表中的数据到底存到了哪⾥?以什么格式存放的?MySQL是以什么⽅式来访问的这些数据?这些问题我们统统不知道?
之前的文章我们大致知道MySQL服务器上负责对表中数据的读取和写⼊⼯作的部分是存储引擎,⽽服务器⼜⽀持不同类型的存储引擎,⽐如InnoDB、MyISAM、Memory等,不同的存储引擎⼀般是由不同的⼈为实现不同的特性⽽开发的,真实数据在不同存储引擎中存放的格式⼀般是不同的,甚⾄有的存储引擎⽐如Memory都不⽤磁盘来存储数据,也就是说关闭服务器后表中的数据就消失了。由于InnoDB是MySQL默认的存储引擎,也是我们最常⽤到的存储引擎,所以本文带你了解InnoDB存储结构。当我们熟悉了⼀个存储引擎的数据存储结构之后,其他的存储引擎都是依葫芦画瓢。
目录
- 一、InnoDB⻚简介
- 二、InnoDB⾏格式
- 三、指定行格式的语法
- 四、Compact⾏格式
- 4.1 记录的额外信息
- 4.1.1 变⻓字段⻓度列表
- 4.1.2 NULL值列表
- 4.1.3 记录头信息
- 4.2 记录的真实数据
- 4.3 CHAR(M)列的存储格式
一、InnoDB⻚简介
InnoDB是⼀个将表中的数据存储到磁盘上的存储引擎,所以即使关机后重启我们的数据还是存在的。⽽真正处理数据的过程是发⽣在内存中的,所以需要把磁盘中的数据加载到内存中,如果是处理写⼊或修改请求的话,还需要把内存中的内容刷新到磁盘上。⽽我们知道读写磁盘的速度⾮常慢,和内存读写差了⼏个数量级,所以当我们想从表中获取某些记录时,InnoDB采取的⽅式是:将数据划分为若⼲个⻚,以⻚作为磁盘和内存之间交互的基本单位,InnoDB中⻚的⼤⼩⼀般为 16K,也就是在⼀般情况下,⼀次最少从磁盘中读取16KB的内容到内存中,⼀次最少把内存中的16KB内容刷新到磁盘中。
二、InnoDB⾏格式
我们平时是以记录为单位来向表中插⼊数据的,这些记录在磁盘上的存放⽅式也被称为⾏格式或者记录格式。设计InnoDB存储引擎到现在为⽌设计了4种不同类型的⾏格式,分别是:
CompactRedundantDynamicCompressed
随着时间的推移,他们可能会设计出更多的⾏格式,但是不管怎么变,在原理上⼤体都是差不多
三、指定行格式的语法
create table表名 (列的信息) row_format=⾏格式名称
or
alter table 表名 row_format=⾏格式名称
比如我们在testdb库中创建一张学习的表demo,可以这样指定它的行格式
mysql> use testdb;
Database changed
mysql> create table demo1( c1 varchar(10), c2 varchar(10) not null, c3 char(10), c4 varchar(10), c5 varchar(1024)) charset=ascii row_format=compact;
Query OK, 0 rows affected (0.01 sec)
可以看到我们刚刚创建的这个表的⾏格式就是compact,我们还指定了这个表的字符集为ascii,因为ascii字符集只包括空格、标点符号、数字、⼤⼩写字⺟和⼀些不可⻅字符。我们现在向这个表中插⼊两条记录
mysql> insert into demo1 values('aaaaa','bbbb','ccc','dd','e');
Query OK, 1 row affected (0.00 sec)
mysql> insert into demo1 values('eeeee','ffff',null,null,'abcdefghijklmnopqrstuvwxyzabcdefghijklmnopqrstuvwxyzabcdefghijklmnopqrstuvwxyzabcdefghijklmnopqrstuvwxyzabcdefghijklmnopqrstuvwxyz');
Query OK, 1 row affected (0.01 sec)
现在表中的记录就是这个样⼦的
mysql> select * from demo1;
+-------+------+------+------+------------------------------------------------------------------------------------------------------------------------------------+
| c1 | c2 | c3 | c4 | c5 |
+-------+------+------+------+------------------------------------------------------------------------------------------------------------------------------------+
| aaaaa | bbbb | ccc | dd | e |
| eeeee | ffff | NULL | NULL | abcdefghijklmnopqrstuvwxyzabcdefghijklmnopqrstuvwxyzabcdefghijklmnopqrstuvwxyzabcdefghijklmnopqrstuvwxyzabcdefghijklmnopqrstuvwxyz |
+-------+------+------+------+------------------------------------------------------------------------------------------------------------------------------------+
2 rows in set (0.00 sec)
演示表的内容也填充好了,现在我们就来看看各个⾏格式下的存储⽅式到底有啥不同吧
四、Compact⾏格式

如图,⼀条完整的记录其实可以被分为记录的额外信息和记录的真实数据两⼤部分,下边我们详细看⼀下这两部分的组成
4.1 记录的额外信息
这部分信息是服务器为了描述这条记录添加的⼀些信息,这些额外信息分为3类,分别是变⻓字段⻓度列表、NULL值列表和记录头信息,我们分别看⼀下
4.1.1 变⻓字段⻓度列表
我们知道MySQL⽀持⼀些变⻓的数据类型,⽐如varchar(M)、varbinary(M)、各种TEXT类型,各种BLOB类型,我们也可以把拥有这些数据类型的列称为变⻓字段,变⻓字段中存储多少字节的数据是不固定的,所以我们在存储真实数据的时候需要顺便把这些数据占⽤的字节数也存起来,这样才不⾄于把MySQL服务器搞懵,所以这些变⻓字段占⽤的存储空间分为两部分:
- 真正的数据内容
- 占⽤的字节数
在Compact⾏格式中,把所有变⻓字段的真实数据占⽤的字节⻓度都存放在记录的开头部位,从⽽形成⼀个变⻓字段⻓度列表,各变⻓字段数据占⽤的字节数按照列的顺序逆序存放。
我们拿demo1表中的第⼀条记录来举个例⼦。因为demo1表的、c1、c2、c4、c5列都是变⻓的数据类型,所以这四个列的值的字节⻓度都需要保存在记录开头处,我们来看⼀下第⼀条记录各变⻓字段内容字节的⻓度:
| 列名 | 存储内容 | 字节长度(十进制) | 内容长度(十六进制) |
|---|---|---|---|
| c1 | ‘aaaaa’ | 5 | 0x05 |
| c2 | ‘bbbb’ | 4 | 0x04 |
| c4 | ‘dd’ | 2 | 0x02 |
| c5 | ‘e’ | 1 | 0x01 |
⼜因为这些⻓度值需要按照列的逆序存放,所以最后变⻓字段⻓度列表的字节串⽤⼗六进制表示,效果就是:01 02 04 05,把这个字节串组成的变⻓字段⻓度列表填⼊上边的示意图中的效果如下:
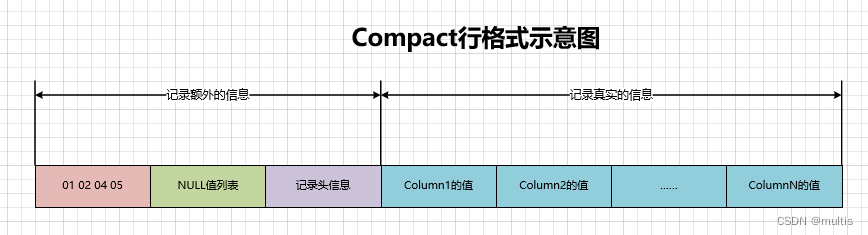
我们也可以查看底层存储文件:demo1.ibd,用16进制编辑器打开,我这里使用的是Notepad++和他的HEX-Editor插件。可以找到如下的数据域(可能会有其中 mysql 生成的行数据不一样,但是我们创建的行数据内容应该是一样的,而且数据长度应该是一摸一样的,可以搜索01 02 04 05字符,找到这些数据):

由于第⼀⾏内容占⽤的字节数⽐较⼩,⽤1个字节就可以表示,但是如果变⻓列的内容占⽤的字节数⽐较多,可能就需要⽤2个字节来表示。具体⽤1个还是2个字节来表示真实数据占⽤的数,InnoDB有它的⼀套规则,这里我们⾸先声明⼀下W、M和L的意思:
假设某个字符集中表示⼀个字符最多需要使⽤的字节数为W
也就是使⽤
show charset语句的结果中的Maxlen列,⽐⽅说utf8mb4字符集中W就是4,utf8字符集中的W就是3,gbk字符集中的W就是2,ascii字符集中的W就是1
对于变⻓类型varchar(M)来说,这种类型表示能存储最多M个字符,所以这个类型能表示的字符串最多占⽤的字节数就是M×W。
假设它实际存储的字符串占⽤的字节数是L
所以确定使⽤1个字节还是2个字节表示真正字符串占⽤的字节数的规则就是这样:
-
如果M×W <= 255,那么使⽤1个字节来表示真正字符串占⽤的字节数
-
如果M×W > 255,则分为两种情况:
- 如果L <= 127,则⽤1个字节来表示真正字符串占⽤的字节数
- 如果L > 127,则⽤2个字节来表示真正字符串占⽤的字节数
也就是如果该可变字段允许存储的最⼤字节数(M×W)超过255字节
并且真实存储的字节数(L)超过127字节,则使⽤2个字节,否则使⽤1个字节。
另外需要注意的⼀点是,变⻓字段⻓度列表中只存储值为⾮NULL的列内容占⽤的⻓度,值为 NULL的列的⻓度是不储存的
我们查看第二行数据,第二行数据c5,它的字符串最多占⽤的字节数是1024,实际存储的字符串占用的字节是130,所以要用两个字节来表示长度,按照逆序存放 就是 82 80 04 05
如130*1转换成16进制为 0x82 也就是 0x02 + 0x80,最高位标识1之后,就是 0x82 + 0x80,对应咱们的变长字段长度列表的开头
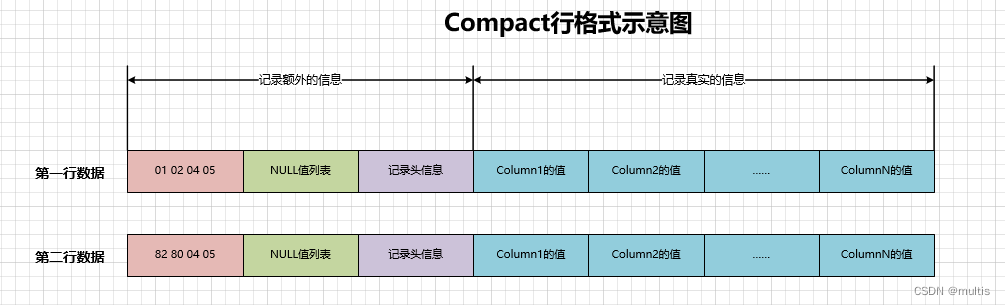
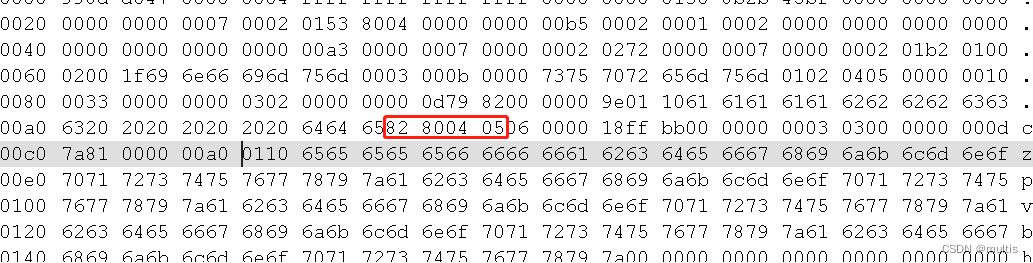 所以两行数据示意图如下:
所以两行数据示意图如下:
4.1.2 NULL值列表
我们知道表中的某些列可能存储NULL值,如果把这些NULL值都放到记录的真实数据中存储会很占地⽅,所以Compact⾏格式把这些值为NULL的列统⼀管理起来,存储到NULL值列表中,它的处理过程是这样的
- ⾸先统计表中允许存储NULL的列有哪些
我们前边说过,主键列、被NOT NULL修饰的列都是不可以存储NULL值的,所以在统计的时候不会把这些列算进去。⽐⽅说表
demo1的4个列c1、c3、c4、c5都是允许存储NULL值的,⽽c2列是被NOT NULL修饰,不允许存储NULL值。
-
如果表中没有允许存储 NULL 的列,则 NULL值列表也不存在了,否则将每个允许存储NULL的列对应⼀个⼆进制位,⼆进制位按照列的顺序逆序排列,⼆进制位表示的意义如下
- ⼆进制位的值为1时,代表该列的值为NULL。
- ⼆进制位的值为0时,代表该列的值不为NULL
因为表
demo1有4个值允许为NULL的列,所以这4个列和⼆进制位的对应关系就是这样:
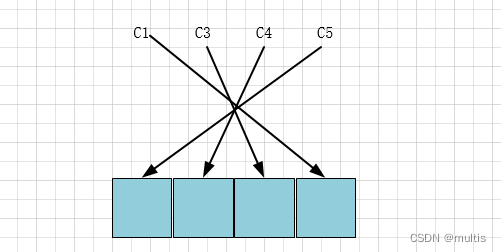
- MySQL规定NULL值列表必须⽤整数个字节的位表示,如果使⽤的⼆进制位个数不是整数个字节,则在字节的⾼位补0。
对于第⼀条记录来说,c1、c3、c4、c5 这4个列的值都不为NULL,所以它们对应的个二进制位,不足一个字节,所以在字节的高位补0,效果就是这样:
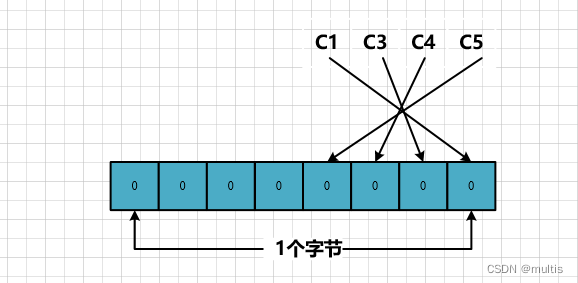
所以第⼀条记录的NULL值列表⽤⼗六进制表示就是:0x00,以此类推,如果一个表中有9个允许为NULL,那这个记录的NULL值列表部分就需要2个字节来表示了

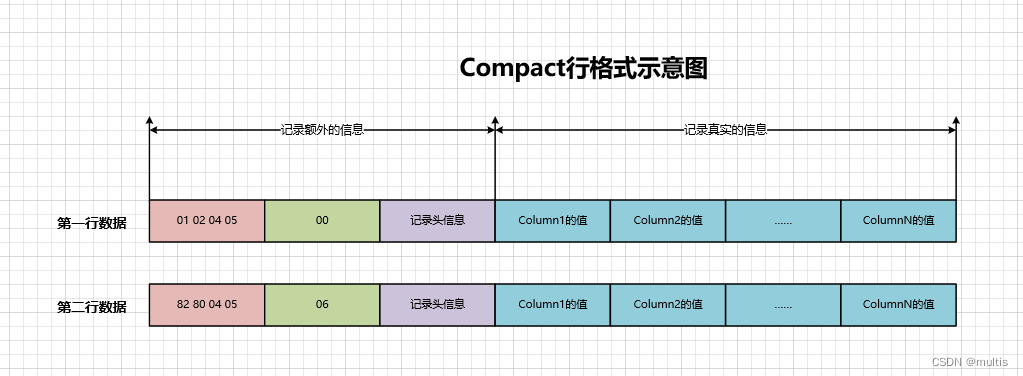
第二条数据c3、c4为值都为NULL,所以这4个列对应的⼆进制位的情况就是:

所以第⼆条记录的NULL值列表⽤⼗六进制表示就是:0x06,查看文件

所以这两条记录在填充了NULL值列表后的示意图就是这样:
4.1.3 记录头信息
除了变⻓字段⻓度列表、NULL值列表之外,还有⼀个⽤于描述记录的记录头信息,它是由固定的5个字节组成。5个字节也就是40个⼆进制位,不同的位代表不同的意思,如图:

这些⼆进制位代表的详细信息如下表:
| 名称 | ⼤⼩(单位:bit) | 描述 |
|---|---|---|
| 预留位1 | 1 | 没有使⽤ |
| 预留位2 | 1 | 没有使⽤ |
| delete_mask | 1 | 标记该记录是否被删除 |
| min_rec_mask | 1 | B+树的每层⾮叶⼦节点中的最⼩记录都会添加该标记 |
| n_owned | 4 | 表示当前记录拥有的记录数 |
| heap_no | 13 | 表示当前记录在记录堆的位置信息 |
| record_type | 3 | 表示当前记录的类型,0表示普通记录,1表示B+树⾮叶⼦节点记录,2表示最⼩记录,3表示最⼤记录 |
| next_record | 16 | 表示下⼀条记录的相对位置 |
我们查看demo1.ibd存储文件:

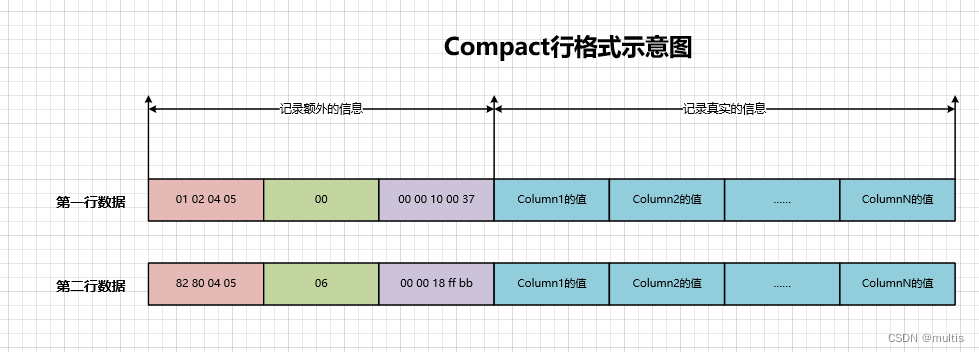
根据推理,很容易可以得到demo1数据表两条记录的记录头信息如下所示
第一行:00 00 10 00 3a
第二行:00 00 18 ff bb
根据记录头的构成,将上面的记录由十六进制转换为二进制分析
第一行:00000000 00000000 00010000 00000000 00110111
第一行:00000000 00000000 00011000 11111111 10111011
根据这些二进制数据,将数据按照记录头结构切分可以得到如下信息
| 预留位1(1b) | 预留位2(1b) | delete_mask(1b) | min_rec_mask(1b) | n_owned(4b) | heap_no(13) | record_type(3b) | next_record(16b) | |
|---|---|---|---|---|---|---|---|---|
| 第一行 | 0 | 0 | 0 | 0 | 0000 | 00000000 00010(2) | 000 | 00000000 00110111(55) |
| 第一行 | 0 | 0 | 0 | 0 | 0000 | 00000000 00011(3) | 000 | 11111111 10111011(65467) |
所以这两条记录在填充了记录头信息后的示意图就是这样:
4.2 记录的真实数据
对于demo1表来说,记录的真实数据除了c1、c2、c3、c4、c5这⼏个我们⾃⼰定义的列的数据以外,MySQL会为每个记录默认的添加⼀些列(也称为隐藏列),具体的列如下:
| 列名 | 是否必须 | 占⽤空间 | 描述 |
|---|---|---|---|
| row_id | 否 | 6字节 | ⾏ID,唯⼀标识⼀条记录 |
| transaction_id | 是 | 6字节 | 事务ID |
| roll_pointer | 是 | 7字节 | 回滚指针 |
小提示:
实际上这⼏个列的真正名称其实是:DB_ROW_IDDB_TRX_ID、DB_ROLL_PTR,为了美观才写成了row_id、transaction_id和roll_pointer,这⾥需要提⼀下InnoDB表对主键的⽣成策略:优先使⽤⽤户⾃定义主键作为主键,如果⽤户没有定义主键,则选取⼀个Unique键作为主键,如果表中连Unique键都没有定义的话,则InnoDB会为表默认添加⼀个名为row_id的隐藏列作为主键。所以我们从上表中可以看出:InnoDB存储引擎会为每条记录都添加DB_TRX_ID和DB_ROLL_PTR这两个列,但是row_id是可选的(在没有自定义主键以及Unique键的情况下才会添加该列)。这些隐藏列的值不用我们操心,InnoDB存储引擎会自己帮我们生成的。
因为表demo1并没有定义主键,所以MySQL服务器会为每条记录增加上述的3个列。

我们看看第一行内容的文件:

我们给第一行记录加上的真实数据,如下
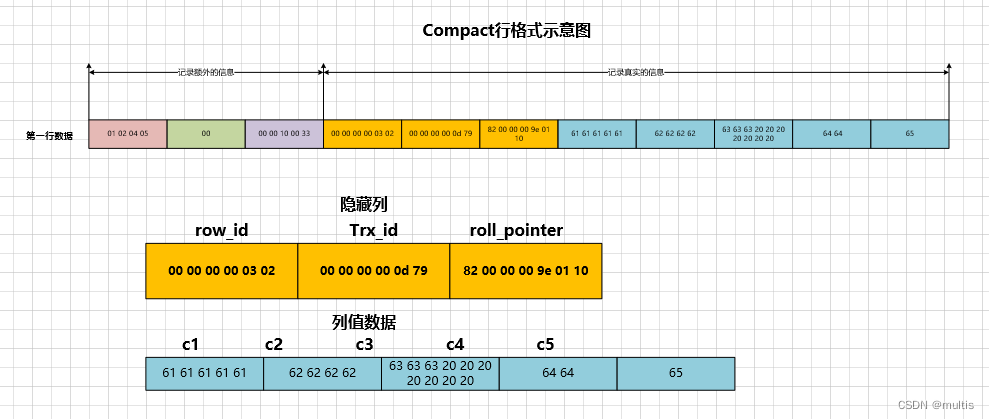
参考ASCII码对照表:16进制的61对应a 62对应b 63对应c 20对应空格(char以外的7个字节的统统都用空格字符填充) 64对应d 65对应e,懵逼了吧
4.3 CHAR(M)列的存储格式
demo1表的c1、c2、c4、c5列的类型是VARCHAR(10),而c3列的类型是CHAR(10),demo1表采用的是ascii字符集,这个字符集是一个定长字符集,也就是说表示一个字符采用固定的一个字节,如果采用变长的字符集(也就是表示一个字符需要的字节数不确定,比如gbk表示一个字符要1~2个字节、utf8表示一个字符要1~3个字节等)的话,c3列的长度也会被存储到变长字段长度列表中。
对于CHAR(M)类型的列来说,当列采用的是定长字符集时,该列占用的字节数不会被加到变长字段长度列表,而如果采用变长字符集时,该列占用的字节数也会被加到变长字段长度列表。
小提示:
变长字符集的CHAR(M)类型的列要求至少占用M个字节,而VARCHAR(M)却没有这个要求。比方说对于使用utf8字符集的CHAR(10)的列来说,该列存储的数据字节长度的范围是10~30个字节。即使我们向该列中存储一个空字符串也会占用10个字节,这是怕将来更新该列的值的字节长度大于原有值的字节长度而小于10个字节时,可以在该记录处直接更新,而不是在存储空间中重新分配一个新的记录空间,导致原有的记录空间成为所谓的碎片。
我们创建一张demo2表来看一下:
mysql> create table demo2( c1 varchar(10), c2 varchar(10) not null, c3 char(10), c4 varchar(10), c5 varchar(1024)) charset=utf8 row_format=compact;
Query OK, 0 rows affected, 1 warning (0.03 sec)
mysql> insert into demo2 values('aaaaa','bbbb','ccc','dd','e');
Query OK, 1 row affected (0.01 sec)
这里就不唠叨了,直接打开demo2.ibd文件查看

示意图中的效果如下:
 我们在插入一条数据
我们在插入一条数据
mysql> insert into demo2 values('一一一一一','一一 一','测试测试测试测测试','dd','e');
这条数据的字节数如下:5*3=15 3*3+1=10 3*9=27 2 1对应16进制逆序存放 01 02 1b oa of ,这里就不画图了,我们直接看demo2.ibd文件

这篇文档到此结束了,后面在讲其他的行格式,行溢出。本篇概念性有点强,大家可以慢慢理解。