「 Redis 」大key对持久化有什么影响?
参考&鸣谢
Redis 大 Key 对持久化有什么影响? XiaoLinCoding
解决了Redis大key问题,同事们都夸他牛皮 大白斯基
快手面试官:Redis变慢了,如何快速排查? Java 那些事
redis 大 key 删除踩坑记 凌云
一、引言
Redis是一款高性能的内存数据库,它能够快速地处理大量的数据。然而,在实际应用中,我们可能会遇到一些大key的情况,这会对Redis的持久化功能造成一定影响。
大key指的是Redis中单个键所占用的空间超过一定阈值的情况。虽然大key在某些场景下能提高Redis的性能,但是在持久化方面,却会给恢复速度带来一定的难度。因此,了解大key对Redis持久化的影响是非常重要的。在本文中,我们将深入探讨大key对Redis持久化的影响,并介绍如何解决这些问题。
二、RDB和AOF
RDB:RDB是一种快照存储持久化方式,具体就是将Redis某一时刻的内存数据保存到硬盘的文件当中,默认保存的文件名为dump.rdb,而在Redis服务器启动时,会重新加载dump.rdb文件的数据到内存当中恢复数据。
AOF:与RDB存储某个时刻的快照不同,AOF持久化方式会记录客户端对服务器的每一次写操作命令,并将这些写操作以Redis协议追加保存到以后缀为aof文件末尾,在Redis服务器重启时,会加载并运行aof文件的命令,以达到恢复数据的目的。
在进行持久化时,Redis需要将数据写入磁盘中,然而大key的存在会对此产生一定的影响。
对于RDB和AOF的细节,详细请看
「 Redis 」RDB和AOF持久化全面解析
三、大 Key 对 AOF 日志的影响
先说说 AOF 日志三种写回磁盘的策略
Redis 提供了 3 种 AOF 日志写回硬盘的策略,分别是:
- Always,这个单词的意思是「总是」,所以它的意思是每次写操作命令执行完后,同步将 AOF 日志数据写回硬盘;
- Everysec,这个单词的意思是「每秒」,所以它的意思是每次写操作命令执行完后,先将命令写入到 AOF 文件的内核缓冲区,然后每隔一秒将缓冲区里的内容写回到硬盘;
- No,意味着不由 Redis 控制写回硬盘的时机,转交给操作系统控制写回的时机,也就是每次写操作命令执行完后,先将命令写入到 AOF 文件的内核缓冲区,再由操作系统决定何时将缓冲区内容写回硬盘。
这三种策略只是在控制 fsync() 函数的调用时机。
当应用程序向文件写入数据时,内核通常先将数据复制到内核缓冲区中,然后排入队列,然后由内核决定何时写入硬盘。
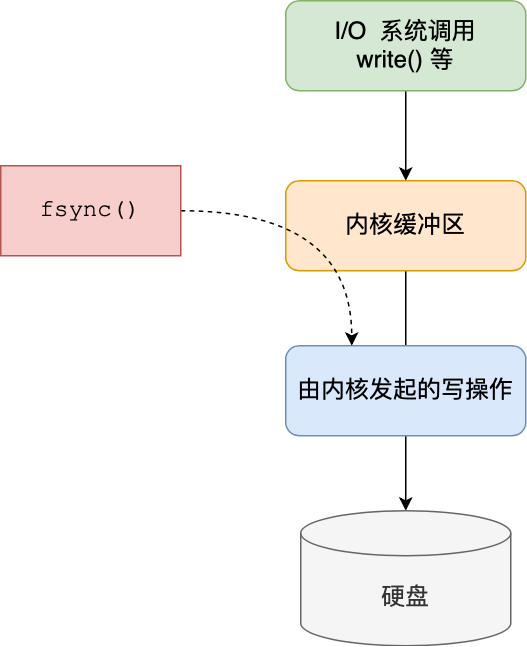
如果想要应用程序向文件写入数据后,能立马将数据同步到硬盘,就可以调用 fsync() 函数,这样内核就会将内核缓冲区的数据直接写入到硬盘,等到硬盘写操作完成后,该函数才会返回。
- Always 策略就是每次写入 AOF 文件数据后,就执行 fsync() 函数;
- Everysec 策略就会创建一个异步任务来执行 fsync() 函数;
- No 策略就是永不执行 fsync() 函数;
分别说说这三种策略,在持久化大 Key 的时候,会影响什么?
在使用 Always 策略的时候,主线程在执行完命令后,会把数据写入到 AOF 日志文件,然后会调用 fsync() 函数,将内核缓冲区的数据直接写入到硬盘,等到硬盘写操作完成后,该函数才会返回。
当使用 Always 策略的时候,如果写入是一个大 Key,主线程在执行 fsync() 函数的时候,阻塞的时间会比较久,因为当写入的数据量很大的时候,数据同步到硬盘这个过程是很耗时的。
当使用 Everysec 策略的时候,由于是异步执行 fsync() 函数,所以大 Key 持久化的过程(数据同步磁盘)不会影响主线程。
当使用 No 策略的时候,由于永不执行 fsync() 函数,所以大 Key 持久化的过程不会影响主线程。
四、大 Key 对 AOF 重写和 RDB 的影响
当 AOF 日志写入了很多的大 Key,AOF 日志文件的大小会很大,那么很快就会触发 AOF 重写机制。
AOF 重写机制和 RDB 快照(bgsave 命令)的过程,都会分别通过 fork() 函数创建一个子进程来处理任务。
在创建子进程的过程中,操作系统会把父进程的「页表」复制一份给子进程,这个页表记录着虚拟地址和物理地址映射关系,而不会复制物理内存,也就是说,两者的虚拟空间不同,但其对应的物理空间是同一个。
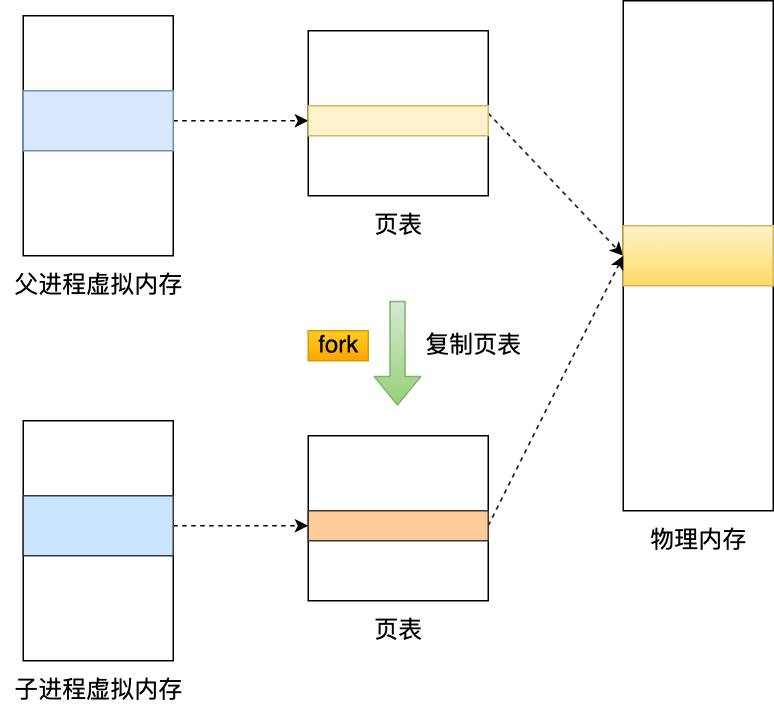 这样一来,子进程就共享了父进程的物理内存数据了,这样能够节约物理内存资源,页表对应的页表项的属性会标记该物理内存的权限为只读。
这样一来,子进程就共享了父进程的物理内存数据了,这样能够节约物理内存资源,页表对应的页表项的属性会标记该物理内存的权限为只读。
随着 Redis 存在越来越多的大 Key,那么 Redis 就会占用很多内存,对应的页表就会越大。
在通过 fork() 函数创建子进程的时候,虽然不会复制父进程的物理内存,但是内核会把父进程的页表复制一份给子进程,如果页表很大,那么这个复制过程是会很耗时的,那么在执行 fork 函数的时候就会发生阻塞现象。
而且,fork 函数是由 Redis 主线程调用的,如果 fork 函数发生阻塞,那么意味着就会阻塞 Redis 主线程。由于 Redis 执行命令是在主线程处理的,所以当 Redis 主线程发生阻塞,就无法处理后续客户端发来的命令。
我们可以执行 info 命令获取到 latest_fork_usec 指标,表示 Redis 最近一次 fork 操作耗时。
# 最近一次 fork 操作耗时
latest_fork_usec:315
如果 fork 耗时很大,比如超过1秒,则需要做出优化调整:
- 单个实例的内存占用控制在 10 GB 以下,这样 fork 函数就能很快返回。
- 如果 Redis 只是当作纯缓存使用,不关心 Redis 数据安全性问题,可以考虑关闭 AOF 和 AOF 重写,这样就不会调用 fork 函数了。
- 在主从架构中,要适当调大 repl-backlog-size,避免因为 repl_backlog_buffer 不够大,导致主节点频繁地使用全量同步的方式,全量同步的时候,是会创建 RDB 文件的,也就是会调用 fork 函数。
那什么时候会发生物理内存的复制呢?
当父进程或者子进程在向共享内存发起写操作时,CPU 就会触发写保护中断,这个「写保护中断」是由于违反权限导致的,然后操作系统会在「写保护中断处理函数」里进行物理内存的复制,并重新设置其内存映射关系,将父子进程的内存读写权限设置为可读写,最后才会对内存进行写操作,这个过程被称为「写时复制(Copy On Write)」。

写时复制顾名思义,在发生写操作的时候,操作系统才会去复制物理内存,这样是为了防止 fork 创建子进程时,由于物理内存数据的复制时间过长而导致父进程长时间阻塞的问题。
如果创建完子进程后,父进程对共享内存中的大 Key 进行了修改,那么内核就会发生写时复制,会把物理内存复制一份,由于大 Key 占用的物理内存是比较大的,那么在复制物理内存这一过程中,也是比较耗时的,于是父进程(主线程)就会发生阻塞。
所以,有两个阶段会导致阻塞父进程:
- 创建子进程的途中,由于要复制父进程的页表等数据结构,阻塞的时间跟页表的大小有关,页表越大,阻塞的时间也越长;
- 创建完子进程后,如果子进程或者父进程修改了共享数据,就会发生写时复制,这期间会拷贝物理内存,如果内存越大,自然阻塞的时间也越长;
这里额外提一下, 如果 Linux 开启了内存大页,会影响 Redis 的性能的。
Linux 内核从 2.6.38 开始支持内存大页机制,该机制支持 2MB 大小的内存页分配,而常规的内存页分配是按 4KB 的粒度来执行的。
如果采用了内存大页,那么即使客户端请求只修改 100B 的数据,在发生写时复制后,Redis 也需要拷贝 2MB 的大页。相反,如果是常规内存页机制,只用拷贝 4KB。
两者相比,你可以看到,每次写命令引起的复制内存页单位放大了 512 倍,会拖慢写操作的执行时间,最终导致 Redis 性能变慢。
那该怎么办呢?很简单,关闭内存大页(默认是关闭的)。
禁用方法如下:
echo never > /sys/kernel/mm/transparent_hugepage/enabled
五、总结
当 AOF 写回策略配置了 Always 策略,如果写入是一个大 Key,主线程在执行 fsync() 函数的时候,阻塞的时间会比较久,因为当写入的数据量很大的时候,数据同步到硬盘这个过程是很耗时的。
AOF 重写机制和 RDB 快照(bgsave 命令)的过程,都会分别通过 fork() 函数创建一个子进程来处理任务。会有两个阶段会导致阻塞父进程(主线程):
- 创建子进程的途中,由于要复制父进程的页表等数据结构,阻塞的时间跟页表的大小有关,页表越大,阻塞的时间也越长;
- 创建完子进程后,如果父进程修改了共享数据中的大 Key,就会发生写时复制,这期间会拷贝物理内存,由于大 Key 占用的物理内存会很大,那么在复制物理内存这一过程,就会比较耗时,所以有可能会阻塞父进程。
大 key 除了会影响持久化之外,还会有以下的影响。
- 客户端超时阻塞。由于 Redis 执行命令是单线程处理,然后在操作大 key 时会比较耗时,那么就会阻塞 Redis,从客户端这一视角看,就是很久很久都没有响应。
- 引发网络阻塞。每次获取大 key 产生的网络流量较大,如果一个 key 的大小是 1 MB,每秒访问量为 1000,那么每秒会产生 1000MB 的流量,这对于普通千兆网卡的服务器来说是灾难性的。
- 阻塞工作线程。如果使用 del 删除大 key 时,会阻塞工作线程,这样就没办法处理后续的命令。
- 内存分布不均。集群模型在 slot 分片均匀情况下,会出现数据和查询倾斜情况,部分有大 key 的 Redis 节点占用内存多,QPS 也会比较大。
如何避免大 Key 呢?
最好在设计阶段,就把大 key 拆分成一个一个小 key。或者,定时检查 Redis 是否存在大 key ,如果该大 key 是可以删除的,不要使用 DEL 命令删除,因为该命令删除过程会阻塞主线程,而是用 unlink 命令(Redis 4.0+)删除大 key,因为该命令的删除过程是异步的,不会阻塞主线程。
完!