urllib目录
- 一、简介
- 二、发送请求
- 1、urlopen()函数
- 2、Request()函数
- 三、异常处理
- 四、解析URL
- 五、分析Robots协议
一、简介
urllib库是Python内置的标准库。包含以下四个模块:
1、request:模拟发送HTTP请求;
2、error:处理HTTP请求错误时的异常;
3、parse:解析、拆分、合并URL;
4、robotparser:解析网站的robots.txt文件
案例:
爬取知乎网站的数据
首先要构造HTTP请求,然后将HTTP响应的各部分进行输出
第一步:准备工作,创建zhuhu.py文件
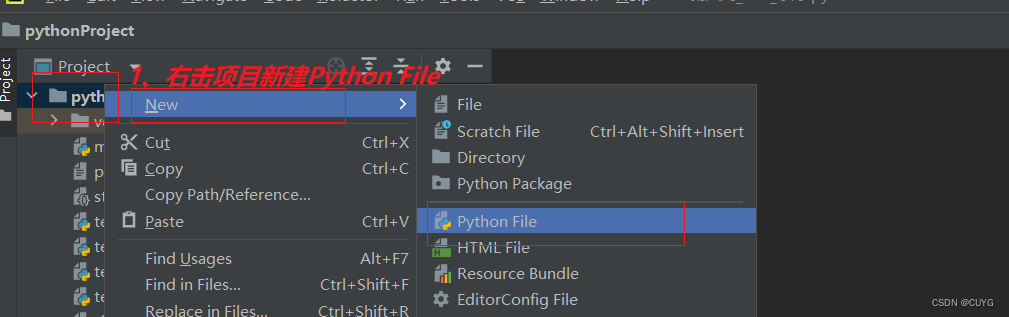
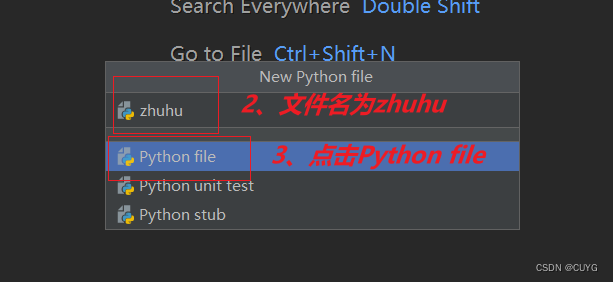
第二步:爬取菜鸟教程代码,敲入以下代码
#第一步:导入request模块
import urllib.request
#第二步:定义url字符串(菜鸟教程网站)
url = 'https://www.runoob.com/'
#第三步:构造HTTP请求,并把返回回值赋值给response
response = urllib.request.urlopen(url)
print('响应类型',type(response))
print('响应状态码',response.getcode())
print('编码方式',response.getheader('Content-Type'))
print('请求的URL',response.geturl())
#第四步:urlopen()函数获取网页,返回的网页内容数据格式为bytes类型,需要使用decode()函数解码,装换成str类型。
resp = response.read().decode('utf-8')
print('网页内容',resp)
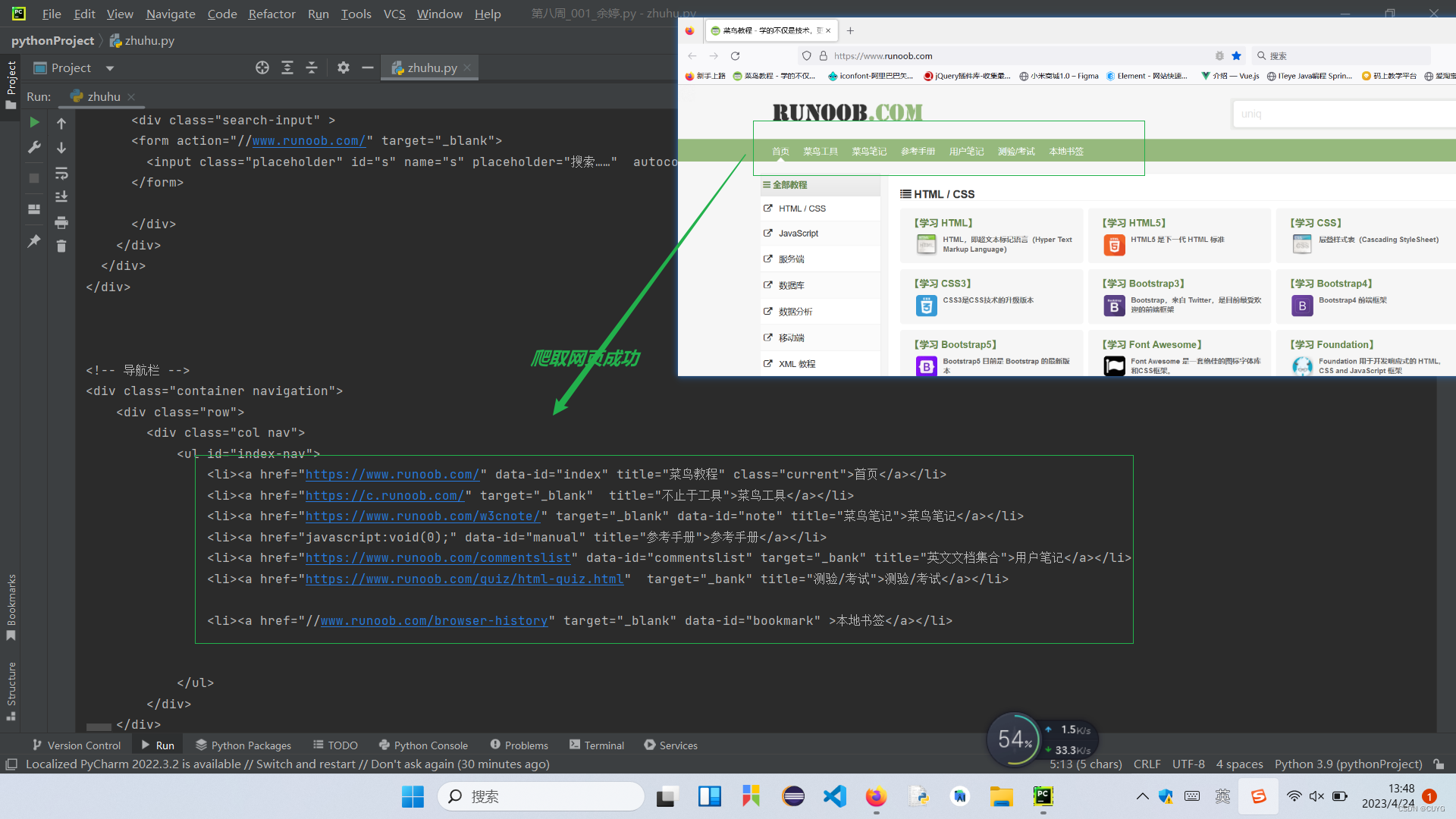
运行结果如下:
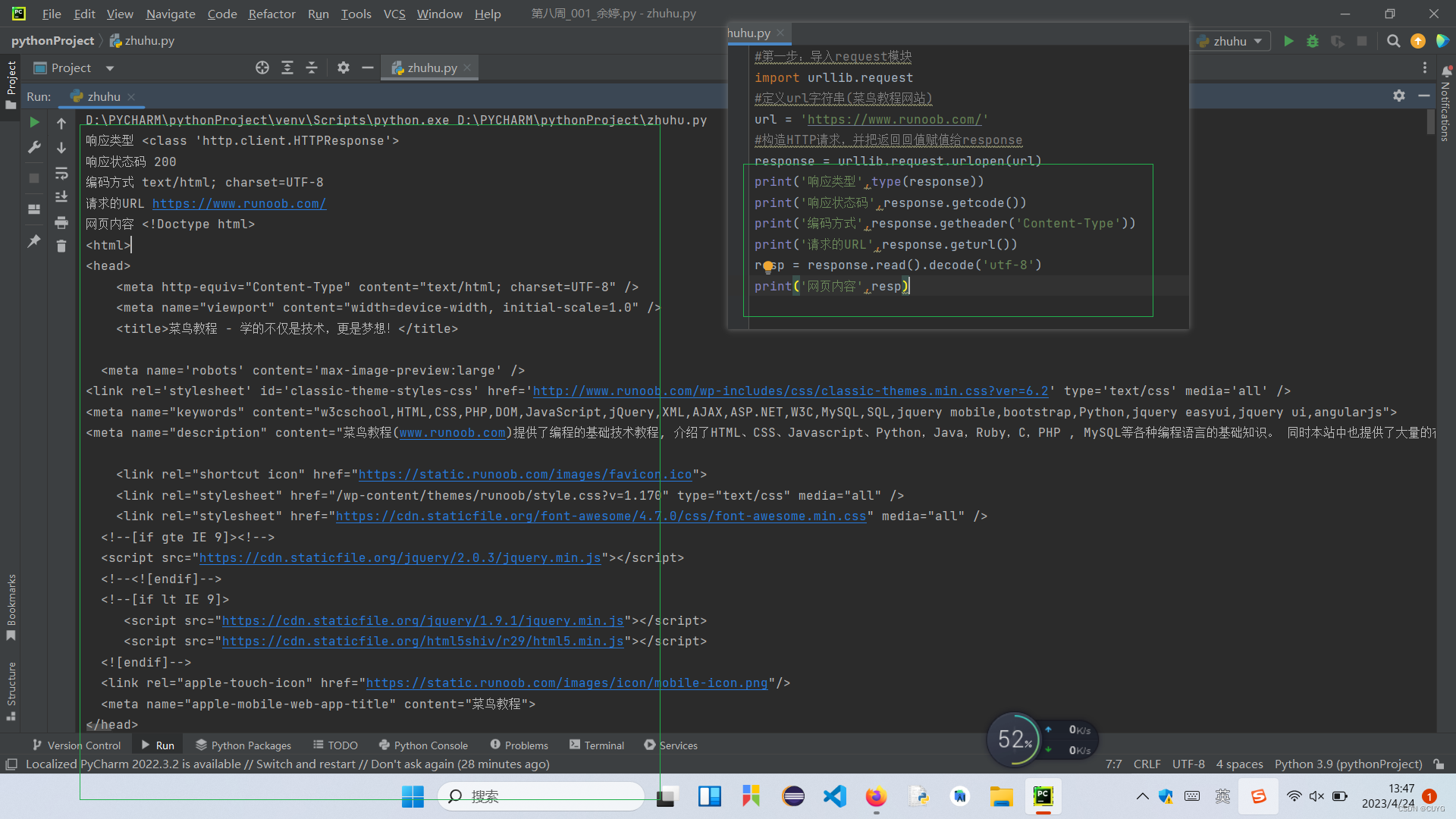
结果:爬取的内容与网页内容一致,爬取网页成功
二、发送请求
request模块提供了基本的构造HTTP请求方法,同时可以处理授权验证(authentication)、重定向(redirection)、Cookie会话等。
使用urlopen()函数和Request()函数构造HTTP请求。
1、urlopen()函数
原型:
urlopen(url,data=None,[timeout,]*,cafile=None,capath=None,cadefault=False,context=None)
url:请求的URL,必传。
data:请求信息,以get方式发送请求为None,以post方式发送请求时给出data参数(必须是bytes(字节流)类型)。
timeout:网络访问的超时时间。
cafile、captath、cadefault:用于实现可信任CA证书的HTTP请求很少使用。
context:实现SSL加密传输,很少使用。
注意:urlopen()函数的data参数必须是bytes(字节流)类型,如果是字典类型,可以先用urllib.parse模块的urlencode()函数编码。
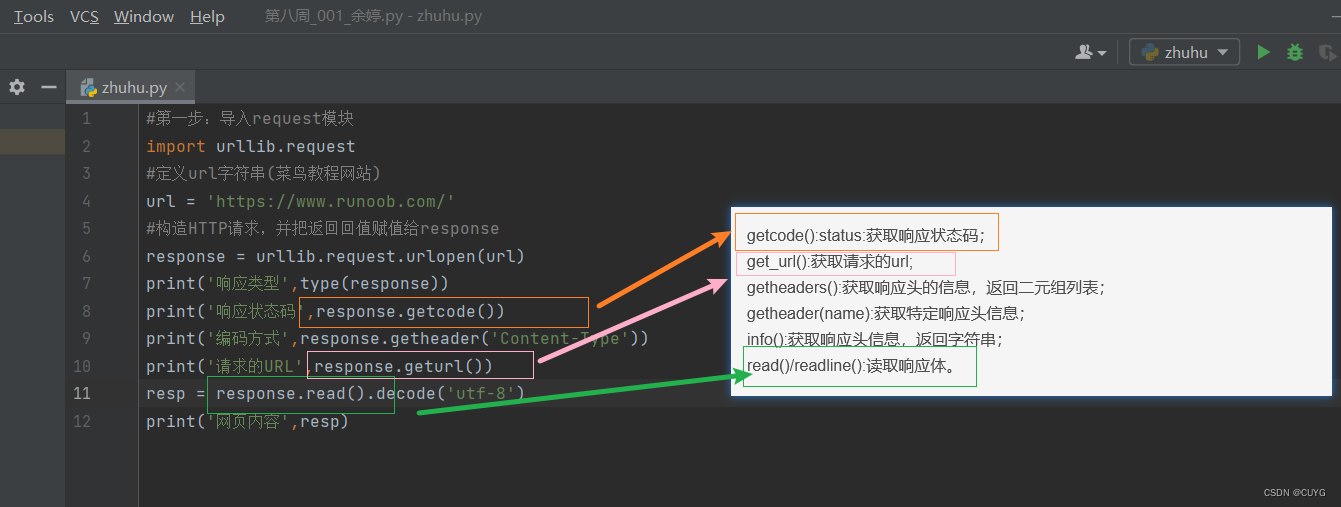
调用urlopen()函数后,返回一个HTTPResponse类型的对象,以下是
HTTPResponse类型对象提供的属性和方法。
getcode():status:获取响应状态码;
get_url():获取请求的url;
getheaders():获取响应头的信息,返回二元组列表;
getheader(name):获取特定响应头信息;
info():获取响应头信息,返回字符串;
read()/readline():读取响应体。
 urlopen()函数既可以实现GET请求,也可以通过设置data参数实现POST请求。
urlopen()函数既可以实现GET请求,也可以通过设置data参数实现POST请求。
2、Request()函数
函数原型:
Request(url,data=None,headers={},origin_req_host=None,unverifiable=False,method=None)
(1) url:请求的URL。
(2) data:请求信息,以get方式发送请求为None,以post方式发送请求时给出data参数(必须是bytes(字节流)类型)。
(3) headers:请求头信息(user_agent,cookie,host…)
(4) origin_req_host:客户端的host名称或者IP地址。
(5) unverifiable:表示请求无法验证,默认为False.
(6) method:请求方法(get/post)
当服务器有反爬虫机制时,可以通过设置headers参数伪装成浏览器去访问网站。
案例:爬取https://www.iconfont.cn/首页内容
#第一步:导入request模块
import urllib.request
#第二步:定义url字符串
url ='https://www.iconfont.cn/'
#第三步:设置headersvalue参数,伪装成浏览器
headersvalue = {
'user-agent':' Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/107.0.0.0 Safari/537.36'
}
#第四步:创建Request对象,并将返回的结果赋值给request
request =urllib.request.Request(url,headers=headersvalue)
#第五步:构造Http请求,并将返回结果赋值给response
response =urllib.request.urlopen(url)
#第六步:读取网页内容并解码
resp = response.read().decode('utf-8')
#第七步:输出网页内容
print("网页内容:",resp)
三、异常处理
error模块提供了request模块产生的异常处理,主要是URLError和HTTPError两个类。
1、URLError类:是error异常模块的基类,可以捕获request模块产生的异常,它具有一个reason属性(返回异常原因)。
2、HTTPError类是URLError类的子类,专门处理HTTP请求的异常,它具由3个属性,分别为reason(返回异常原因)、code(返回HTTP状态码)和headers(返回请求头)。
由于HTTPError是URLError的子类,并不能处理父类支持的异常处理,所以一般对两种异常分开捕获,可先捕获子类的异常,再捕获父类的异常。
#第一步:导入request模块
import urllib.request
#导入error模块
import urllib.error
#处理异常
try:
# 构造HTTP请求,并将返回的结果赋值给response
response = urllib.request.urlopen('https://www.gaoding.com/introduction')
# 捕获HTTP请求的异常
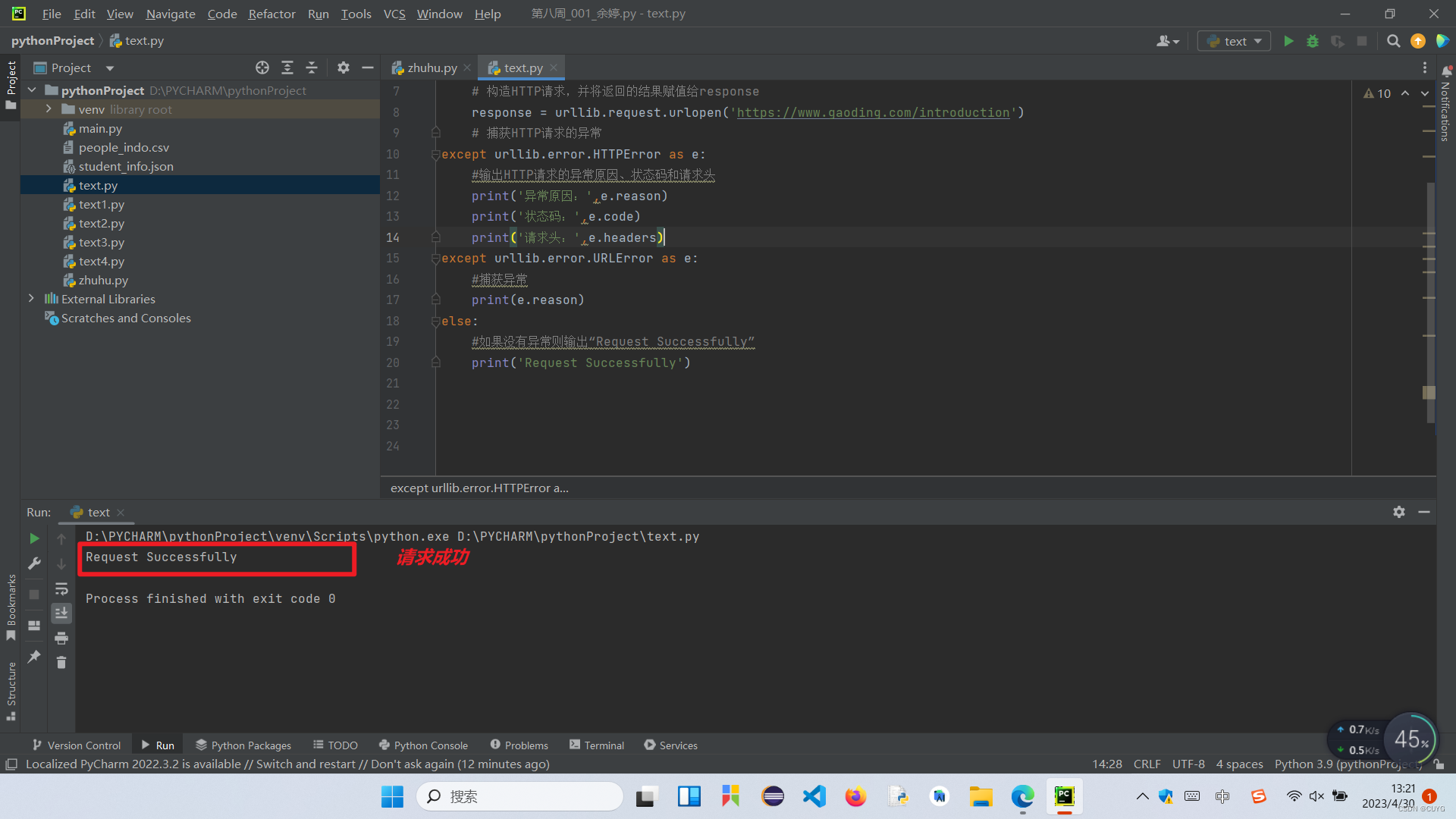
except urllib.error.HTTPError as e:
#输出HTTP请求的异常原因、状态码和请求头
print('异常原因:',e.reason)
print('状态码:',e.code)
print('请求头:',e.headers)
except urllib.error.URLError as e:
#捕获异常
print(e.reason)
else:
#如果没有异常则输出“Request Successfully”
print('Request Successfully')
四、解析URL
parse模块提供解析URL方法,如下:
拆分:
urlparse(urlstring):将URL拆分为六个部分:scheme、netloc、path、params、query、fragment。
urlsplit(urlstring):将URL拆分为五部分:scheme、netloc、path、query、fragment。
合并:
urljoin(url1,url2):将基础链接uel1和新链接url2合并,分析url1的scheme、netloc、path内容,并补充url2缺失的部分。
urlunparse(parts):将可迭代对象parts合并为URL,parts长度为7。
urlunsplit(parts):将可迭代对象parts合并为URL,parts长度为6.
装换:
urlencode(query):将字典形式的数据装换为URL后面的查询字符串。
parse_qs(qs):将URL后面的查询字符串转换为字典。
parse_qsl(qs):将URL后面的查询字符串转换为列表。
quote(str):将URL中的中文字符装换为URL编码。
unquote(str):将URL编码转换为中文字符,进行编码。
案例:
解析 https://www.zhihu.com/search?type=content&q=%E7%88%AC%E8%99%AB
#导入parse模块
import urllib.parse
#定义url字符串
url = 'https://www.zhihu.com/search?type=content&q=%E7%88%AC%E8%99%AB '
#拆分url并输出结果
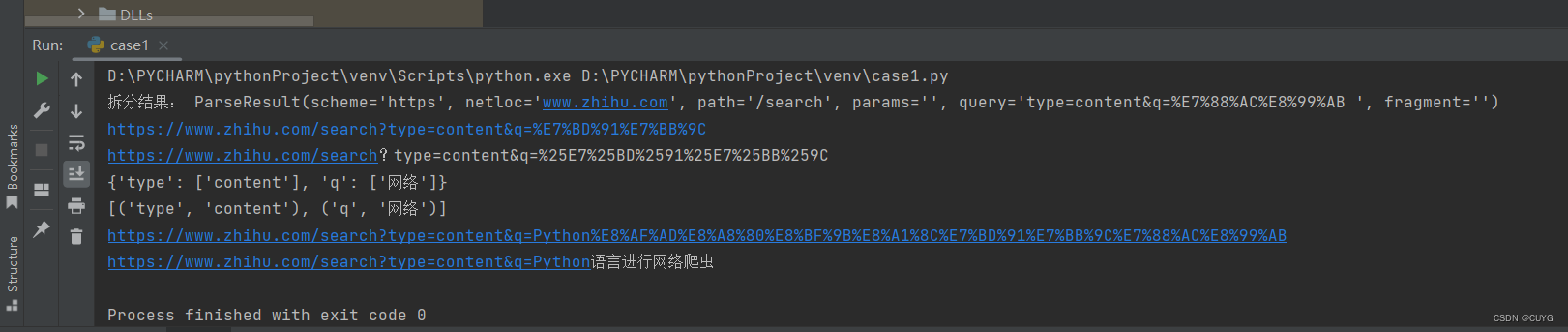
print("拆分结果:",urllib.parse.urlparse(url))
#合并url并输出结果
print(urllib.parse.urljoin('https://www.zhihu.com/search','?type=content&q=%E7%BD%91%E7%BB%9C'))
#定义params字符串
params={'type':'content','q':'%E7%BD%91%E7%BB%9C'}
#编码params参数,合并url并输出结果
print('https://www.zhihu.com/search?'+urllib.parse.urlencode(params))
#定义query字符串
query='type=content&q=%E7%BD%91%E7%BB%9C'
#将query转换成字典
print(urllib.parse.parse_qs(query))
#将query转换成列表
print(urllib.parse.parse_qsl(query))
#定义keyword中文字符串
keyword= 'Python语言进行网络爬虫'
#将中文字符串装换为URL编码,合并后赋值给url
url ='https://www.zhihu.com/search?type=content&q='+urllib.parse.quote(keyword)
#输出URL编码的url
print(url)
#将URL编码装换为中文字符并输出结果
print(urllib.parse.unquote(url))
运行结果:
五、分析Robots协议
robotparser模块提供了分析网站Robots协议的RobotFileParser类,它可以通过robots.txt文件来判断某网页是否能被爬取。
以下是RotbotFileParser类提供的方法:
(1)set_url():设置robots.txt文件的URL.
(2)read():读取robots.txt文件并进行分析。
(3)can_fetch():第一个参数为User_Agent,第二个参数为要爬取的网页的URL,判断该网页能否被爬取。
(4)parse():解析robots.txt文件中某些行的内容。
(5)mtime():返回上次抓取和分析的robots.txt文件的时间。
(6)modified():将当前时间设置为上次抓取和分析robots.txt时间。
案例:
#导入robotparser模块
import urllib.robotparser
#创建RobotsFileParser类对象response
response = urllib.robotparser.RobotFileParser()
#设置robots.txt文件的URL
response.set_url('https://www.zhihu.com/robots.txt')
#读取robots.txt文件并进行分析
response.read()
#定义爬虫名称
user_agent='zhuhupachong'
#定义知乎的发现url
url ='https://www.zhihu.com/explore'
#判断是否可以进行爬取
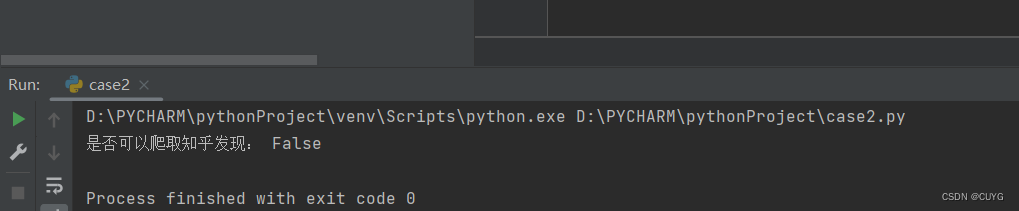
print("是否可以爬取知乎发现:",response.can_fetch(user_agent,url))
运行结果 :
![洛谷P8597 [蓝桥杯 2013 省 B] 翻硬币C语言/C++](https://img-blog.csdnimg.cn/22df30967e05430795ea9785711ba6be.png)