Option类型
- 实际开发中, 在返回一些数据时, 难免会遇到空指针异常(NullPointerException), 遇到一次就处理一次相对来讲还是比较繁琐的. 在Scala中, 我们返回某些数据时,可以返回一个Option类型的对象来封装具体的数据,从而实现有效的避免空指针异常。
- Scala Option(选项)类型用来表示一个值是可选的(有值或无值)。
- Option[T] 是一个类型为 T 的可选值的容器: 如果值存在, Option[T] 就是一个 Some[T] ,如果不存在, Option[T] 就是对象 None 。
伪代码:
val myMap: Map[String, String] = Map("key1" -> "value")
val value1: Option[String] = myMap.get("key1")
val value2: Option[String] = myMap.get("key2")
println(value1) // Some("value1")
println(value2) // None- 在上面的代码中,myMap 一个是一个 Key 的类型是 String,Value 的类型是 String 的 hash map,但不一样的是他的 get() 返回的是一个叫 Option[String] 的类别。
- Scala 使用 Option[String] 来告诉你:「我会想办法回传一个 String,但也可能没有 String 给你」。
- myMap 里并没有 key2 这笔数据,get() 方法返回 None。
- Option 有两个子类别,一个是 Some,一个是 None,当他回传 Some 的时候,代表这个函式成功地给了你一个 String,而你可以透过 get() 这个函式拿到那个 String,如果他返回的是 None,则代表没有字符串可以给你。
代码示例:
package test12
object Test1 {
def main(args: Array[String]): Unit = {
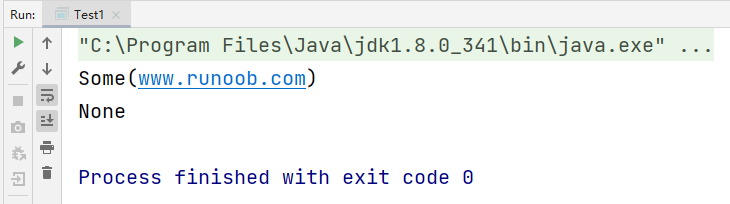
val sites = Map("runoob" -> "www.runoob.com", "goole" -> "www.goole.com")
println(sites.get("runoob"))
println(sites.get("baidu"))
}
}
运行结果:
代码示例:
package test12
object Test2 {
def div(a: Int, b: Int): Option[Int] = {
if (b == 0) {
None
} else {
Some(a / b)
}
}
def main(args: Array[String]): Unit = {
val result = div(10, 2)
val result1 = div(10, 0)
//模式匹配打印结果
result match {
case Some(x) => println(x)
case None => println("除数不能为0")
}
//getOrElse打印结果
println(result.getOrElse(0))
println(result1.getOrElse(0))
}
}
异常处理
代码示例:
package test12
object Test3 {
def main(args: Array[String]): Unit = {
val i = 10 / 0
println("hello")
}
}
运行结果:
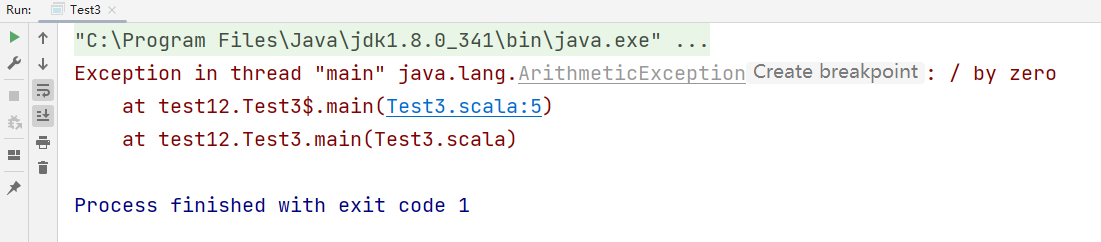
执行程序,可以看到scala抛出了异常,而且没有打印出来"hello "。说明程序出现错误后就终止了。那怎么解决该问题呢?
在Scala中,可以使用异常处理来解决这个问题. 而异常处理又分为两种方式:
-
方式一: 捕获异常.
注意: 该方式处理完异常后, 程序会继续执行.
-
方式二: 抛出异常.
注意: 该方式处理完异常后, 程序会终止执行.
捕获异常
格式:
try {
//可能会出现问题的代码
}
catch{
case ex:异常类型 1 => //代码
case ex:异常类型 2 => //代码
}
finally {
//代码
}代码示例:
package test12
object Test4 {
def main(args: Array[String]): Unit = {
try {
val i = 10 / 0
println("hello1")
} catch {
case e: Exception => e.printStackTrace()
} finally {
println("hello3")
}
println("hello2")
}
}
运行结果:
hello1不会打印,但是会打印hello3,hello2
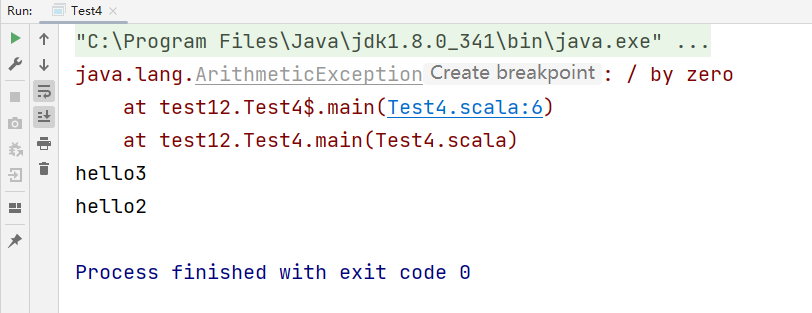
try中的代码是我们编写的业务处理代码.
在catch中表示当出现某个异常时,需要执行的代码.
在finally中,写的是不管是否出现异常都会执行的代码.
抛出异常
代码示例:
package test12
object Test5 {
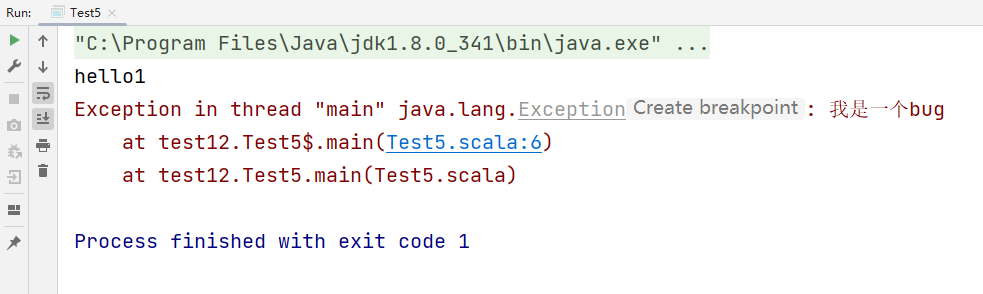
def main(args: Array[String]): Unit = {
println("hello1")
throw new Exception("我是一个bug")
println("hello2")
}
}
运行结果:
会打印hello1,不会打印hello2
IO
读取数据
在Scala语言的Source单例对象中中, 提供了一些非常便捷的方法, 从而使开发者可以快速的从指定数据源(文本文件, URL地址等)中获取数据, 在使用Source单例对象之前, 需要先导包,
即import scala.io.Source.
按行读取
格式:
// 1. 获取数据源文件对象.
val source:BufferedSource = Source.fromFile("数据源文件的路径","编码表")
// 2. 以行为单位读取数据.
val lines:Iterator[String] = source.getLines()
// 3. 将读取到的数据封装到列表中.
val list 1 :List[String] = lines.toList
// 4. 千万别忘记关闭Source对象.
source.close()代码示例:
需求:
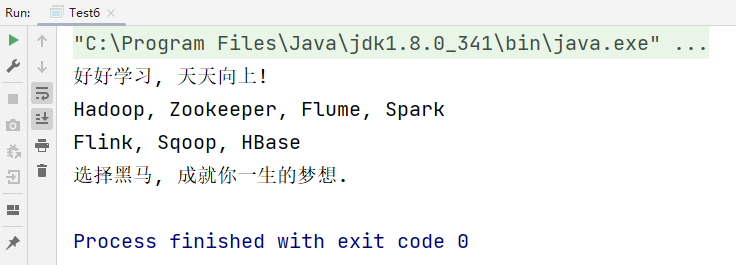
在当前项目下创建data文件夹, 并在其中创建1.txt文本文件, 文件内容如下:
好好学习, 天天向上!
Hadoop, Zookeeper, Flume, Spark
Flink, Sqoop, HBase
选择黑马, 成就你一生的梦想.
以行为单位读取该文本文件中的数据, 并打印结果.
package test12
import scala.io.Source
object Test6 {
def main(args: Array[String]): Unit = {
// 1. 获取数据源对象.
val resource = Source.fromFile("src/resources/test.txt")
// val lines: Iterator[String] = resource.getLines()
// 2 .通过getLines()方法, 逐行获取文件中的数据.
val lines = resource.getLines();
// 3. 将获取到的每一条数据都封装到列表中.
val list = lines.toList
// 4. 打印结果
list.foreach(println(_))
// 5. 记得关闭source对象.
resource.close()
}
}
运行结果:
按字符读取
Scala还提供了以字符为单位读取数据这种方式, 这种用法类似于迭代器, 读取数据之后, 我们可以通过hasNext()``,next()方法, 灵活的获取数据.
格式:
//1. 获取数据源文件对象.
val source:BufferedSource = Source.fromFile("数据源文件的路径","编码表")
//2. 以字符为单位读取数据.
val iter:BufferedIterator[Char] = source.buffered
//3. 将读取到的数据封装到列表中.
while(iter.hasNext)
print(iter.next())
//4. 千万别忘记关闭Source对象.
source.close()如果文件不是很大, 我们可以直接把它读取到一个字符串中.
val str:String = source.mkString
代码示例:
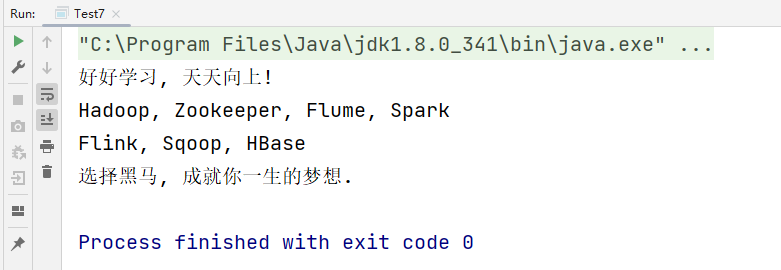
package test12
import scala.io.Source
object Test7 {
def main(args: Array[String]): Unit = {
// 1. 获取数据源对象.
val resource = Source.fromFile("src/resources/test.txt")
// 2. 获取数据源文件中的每一个字符.
val iter = resource.buffered
// 3. 通过hasNext(), next()方法获取数据.
while (iter.hasNext) {
print(iter.next())
}
// 4. 通过mkString方法, 直接把文件中的所有数据封装到一个字符串中.
val str = resource.mkString
// 5. 打印结果.
println(str)
// 6. 关闭source对象, 节约资源, 提高效率.
resource.close()
}
}
运行结果:
读取词法单元和数字
所谓的词法单元指的是以特定符号间隔开的字符串, 如果数据源文件中的数据都是数字形式的字符串, 我们可以很方便的从文件中直接获取这些数据, 例如:
10 2 5
11 2
5 1 3 2
格式
// 1. (^) 获取数据源文件对象.
val source:BufferedSource = Source.fromFile("数据源文件的路径","编码表")
// 2. 读取词法单元.
// \s表示空白字符(空格, \t, \r, \n等)
val arr:Array[String] = source.mkString.split("\\s+")
// 3. 将字符串转成对应的整数
val num = strNumber.map(_.toInt)
// 4. 千万别忘记关闭Source对象.
source.close()代码示例:
在当前项目下创建data文件夹, 并在其中创建2.txt文本文件, 文件内容如下:
10 2 5 11 2 5 1 3 2读取文件中的所有整数, 将其加 1 后, 把结果打印到控制台.
package test12
import scala.io.Source
object Test8 {
def main(args: Array[String]): Unit = {
val source = Source.fromFile("src/resources/test2.txt")
// \s表示空白字符(空格, \t, \ra, \n等)
// +表示数量词,即前面的内容至少出现一次,至多无限次
val number = source.mkString.split("\\s+")
//将字符串转成对应的整数
number.map(_.toInt + 1).foreach(println(_))
}
}
写入数据
Scala并没有内建的对写入文件的支持, 要写入数据到文件, 还是需要使用Java的类库.
代码示例:
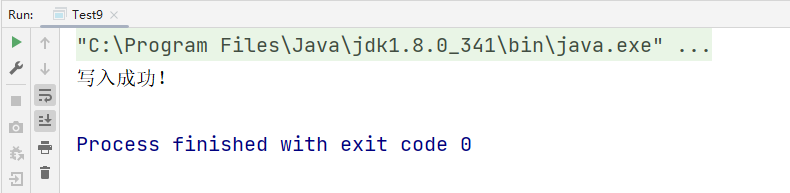
package test12
import java.io.FileOutputStream
object Test9 {
def main(args: Array[String]): Unit = {
val pw = new FileOutputStream("src/resources/test3.txt")
pw.write("好好学习,\r\n".getBytes())
pw.write("天天向上!\r\n".getBytes())
pw.close()
println("写入成功!")
}
}
运行结果:

高阶函数
Scala 混合了面向对象和函数式的特性,在函数式编程语言中,函数是“头等公民”,它和Int、String、Class等其他类型处于同等的地位,可以像其他类型的变量一样被传递和操作。也就是说, 如果一个函数的参数列表可以接收函数对象, 那么这个函数就被称之为高阶函数(High-Order Function).像我们之前学习过的map方法,它就可以接收一个函数,完成List的转换。
常用的高阶函数有以下几类:
-
作为值的函数
-
匿名函数
-
闭包
-
柯里化等等
作为值的函数
需求
将一个整数列表中的每个元素转换为对应个数的小星星, 如下:
List( 1 , 2 , 3 ...) => *, **, ***
代码示例:
package test13
object Test1 {
def main(args: Array[String]): Unit = {
val list = (1 to 10).toList
println(list)
val func = (a: Int) => "*" * a
//list.map(这里需要一个函数)
val list2 = list.map(func)
println(list2)
}
}
匿名函数
在Scala中,没有赋值给变量的函数就是匿名函数. 匿名函数是一种没有名称的函数,也称为lambda函数或函数字面量。在Scala中,可以使用下划线(_)或者箭头符号(=>)来创建匿名函数。
package test13
object Test2 {
def main(args: Array[String]): Unit = {
val list = (1 to 10).toList
println(list)
//通过map函数用来进行转换, 该函数内部接收一个: 匿名函数.
val list2 = list.map((a: Int) => "*" * a)
println(list2)
//简写
val list3 = list.map("*" * _)
println(list3)
}
}
柯里化
柯里化是一种函数转换技术,它将具有多个参数的函数转换为一系列具有单一参数的函数。在Scala中,柯里化函数是指将一个多参数函数转换为一系列单参数函数的过程。柯里化的好处是,它可以方便地创建一些高阶函数,使得代码更加简洁和易于维护。同时,柯里化还可以帮助我们更好地利用Scala的类型系统,提高代码的类型安全性。
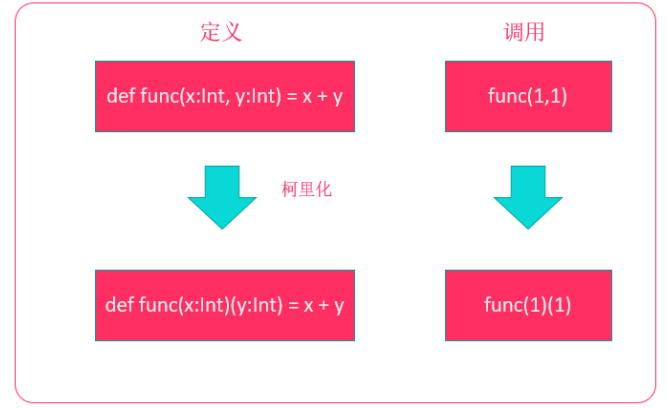
代码示例:
package test13
object Test3 {
//方式一普通写法
def merge1(s1: String, s2: String): String = s1 + s2
//方式二柯里化
def merge2(s1: String)(s2: String) = s1 + s2
def main(args: Array[String]): Unit = {
println(merge1("abc", "def"))
println(merge2("abc")("fff"))
}
}
闭包
闭包是指一个函数,它可以访问其定义范围内的变量,即使在该函数被调用之后,这些变量仍然存在。在Scala中,闭包通常是由一个函数和一个或多个自由变量组成的。自由变量是在函数内部定义之前已经存在的变量,但是在函数内部仍然可以被访问。因此,闭包允许函数在其定义范围之外访问变量,并且可以在函数执行后继续存在。闭包在Scala中通常用于函数式编程,可以用来创建高阶函数和实现惰性求值等功能。
----------------------------------------------------------------------------------------------------------------------------
代码示例:
package test13
object Test4 {
def multiplyBy(factor: Int) = (x: Int) => factor * x
def main(args: Array[String]): Unit = {
val timesTwo = multiplyBy(2)
val timesThree = multiplyBy(3)
println(timesTwo(5))
println(timesThree(5))
}
}
在这个例子中,我们定义了一个名为 multiplyBy 的函数,它接受一个整数参数 factor,并返回一个匿名函数。这个匿名函数接受一个整数参数 x,并返回 factor 乘以 x 的结果。
我们接着定义了两个变量 timesTwo 和 timesThree,它们分别调用 multiplyBy 函数,并传递参数 2 和 3。这样,timesTwo 变量就是一个函数,它将传入的参数乘以 2,timesThree 变量也是一个函数,它将传入的参数乘以 3。
在最后的两行代码中,我们分别调用了 timesTwo 和 timesThree 变量所代表的函数,并传递参数 5。这样,我们就得到了 10 和 15 这两个结果。
这里的关键点在于,multiplyBy 函数返回的是一个匿名函数,这个匿名函数可以访问 multiplyBy 函数中定义的变量 factor。这个匿名函数和它所在的函数形成了一个闭包,因为它“捕获”了 multiplyBy 函数中的变量。
这就是闭包的作用:它允许一个函数访问和操作它所在的作用域中的变量,即使这个函数已经离开了它所在的作用域。在这个例子中,我们可以看到闭包的实际应用,它让我们可以方便地创建一些类似于“乘法器”的函数,这些函数可以根据不同的因子来进行乘法运算。


![[架构之路-183]-《软考-系统分析师》-13-系统设计 - 高内聚低耦合详解、图解以及技术手段](https://img-blog.csdnimg.cn/img_convert/1b5eb161416b6c7a9e0917256b5f6f17.png)