目录
一、STL的诞生
二、STL基本概念
三、STL六大组件
大体分为六大组件:容器、算法、迭代器、仿函数、适配器(配接器)、空间配置器
四、容器、算法与迭代器的认识
容器container:存放数据地方
算法algorithm:解决问题的方法
迭代器iterator:容器与算法之间的黏着剂,算法通过迭代器才能访问容器中的元素
五、尝试vector容器
1、存放内置数据类型
2、存放自定义数据类型
一、STL的诞生
一直以来,软件界面临一个问题:代码重复利用。就像他写某个功能的代码,我也要用但是没拿到手上,必须我再写一份一样的,这样就重复写了,不仅浪费时间还让我们很难受。
C++面向对象和泛型编程的思想,目的就是提高复用性。
为了建立数据结构与算法的一套标准,STL就诞生了。
二、STL基本概念
STL:Standerd Template Library,标准模板库
广义上,STL分为:container容器,algorithm算法,iterator迭代器
容器和算法通过迭代器进行连接
STL几乎所有的代码都使用了类模板或函数模板
三、STL六大组件
大体分为六大组件:容器、算法、迭代器、仿函数、适配器(配接器)、空间配置器
①容器:各种数据结构,如vector、list、deque、set、map等,用来存放数据
②算法:各种常用算法,如sort、find、copy、for_each等
③迭代器:作为容器与算法中间的黏着剂
④仿函数:行为类似函数,可作为算法的某种策略
⑤适配器:用来修饰容器或仿函数或迭代器接口
⑥空间配置器:进行空间的配置与管理
四、容器、算法与迭代器的认识
容器container:存放数据地方
STL容器就是将一些使用最广泛的数据结构实现出来
常用的数据结构:数组、链表、树、栈、队列、集合、映射表等
这些容器又分为:
序列式容器:强调值的排序,其中每个元素有其固定的位置
关联式容器:二叉树结构,各元素之间没有严格的物理上的顺序关系
算法algorithm:解决问题的方法
以有限的步骤解决逻辑或数学上的问题
分为
质变算法:运算过程中会改变区间中元素的内容,例如拷贝、替换、删除等
非质变算法:运算过程中不改变区间中元素的内容,如查找、计数、遍历、寻找极值等
迭代器iterator:容器与算法之间的黏着剂,算法通过迭代器才能访问容器中的元素
提供一种方法,使其能够按序查找某个容器所含的各个元素,而又无需暴露该容器内部的表示方式
每个容器都有其专属的迭代器
迭代器的使用非常类似于指针
种类:
| 种类 | 功能 | 支持的运算 |
| 输入迭代器 | 对数据只读访问 | 只读,支持++、==、!= |
| 输出迭代器 | 对数据只写访问 | 只写,支持++ |
| 前向迭代器 | 读写操作,并能向前推进迭代器 | 读写,支持++、==、!= |
| 双向迭代器 | 读写操作,并能向前或向后推进 | 读写,支持++、-- |
| 随机访问迭代器 | 读写操作,可以以跳跃方式随机访问任意数据 | 读写,支持++、--、[n]、-n、<、<-、>、>= |
常用的迭代器是双向迭代器与随机访问迭代器
五、尝试vector容器
类似于数组
1、存放内置数据类型
容器:vector
算法:for_each
迭代器:vector<int>::iterator
下面使用代码认识vector
首先包含头文件<vector>
#include<vector>然后:
int main()
{
// 创建一个vector容器,类似于数组
vector<int> v;
// 使用vector的pushback函数插入数据
v.push_back(1);
v.push_back(2);
v.push_back(3);
v.push_back(4);
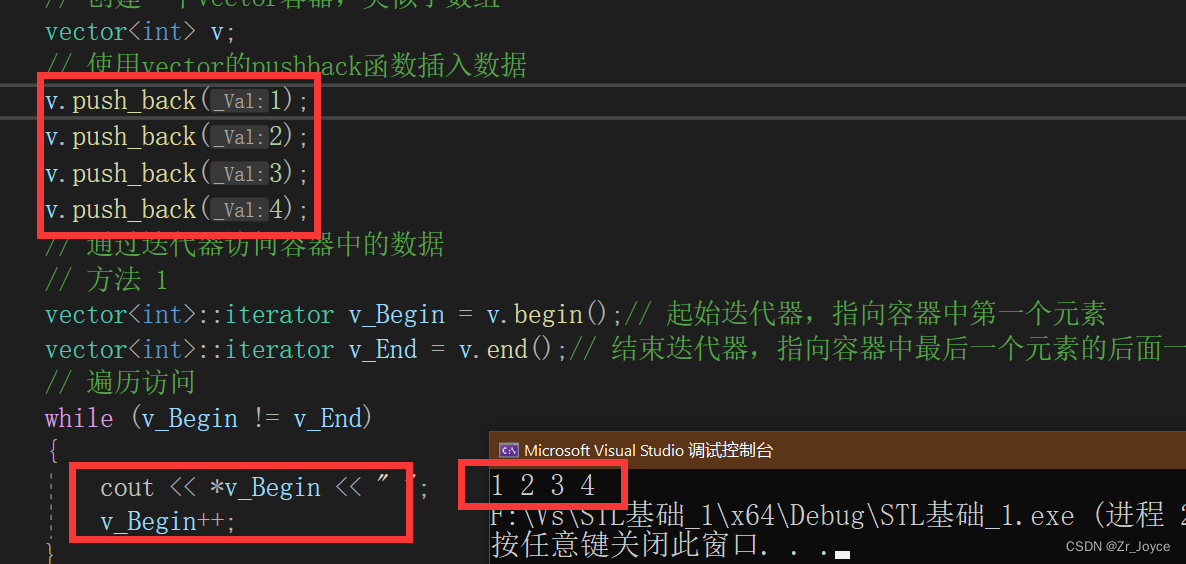
// 通过迭代器访问容器中的数据
// 方法 1
vector<int>::iterator v_Begin = v.begin();// 起始迭代器,指向容器中第一个元素
vector<int>::iterator v_End = v.end();// 结束迭代器,指向容器中最后一个元素的后面一个元素
// 遍历访问
while (v_Begin != v_End)
{
cout << *v_Begin << " ";
v_Begin++;
}
return 0;
}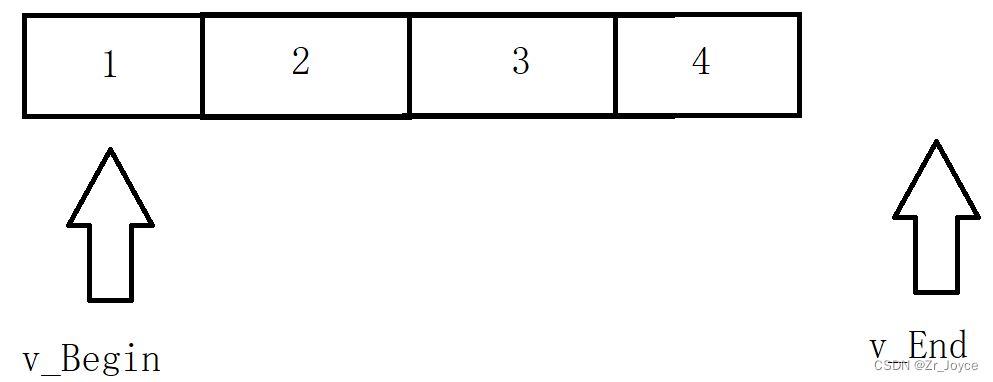
①这是第一种访问数据的方法
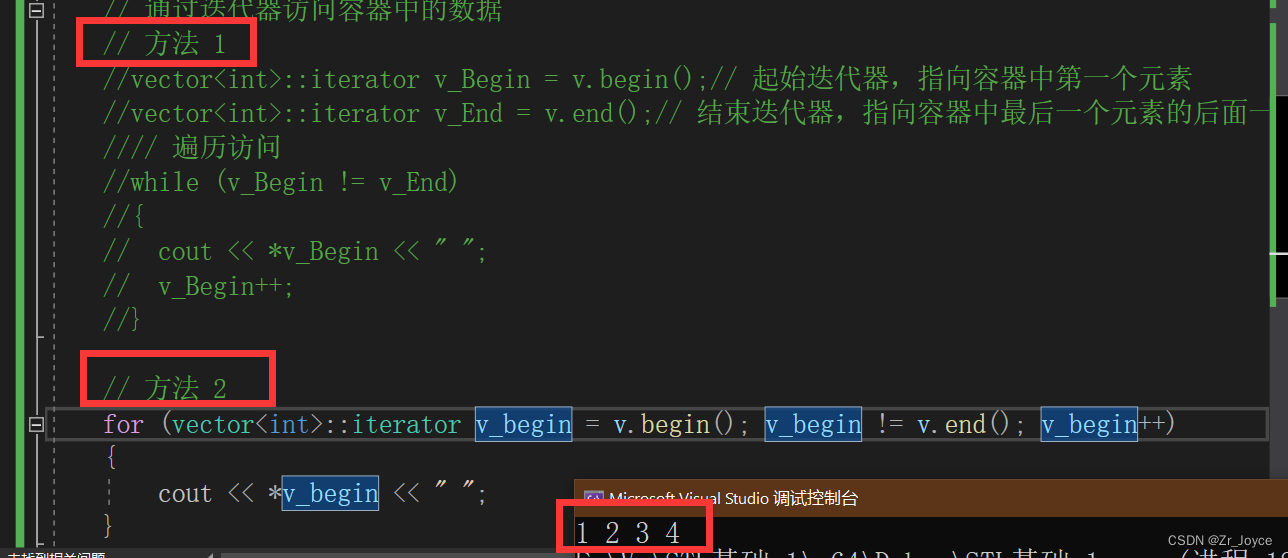
②然后我们使用第二种访问数的方法,直接把他们写在一起
// 方法 2
for (vector<int>::iterator v_begin = v.begin(); v_begin != v.end(); v_begin++)
{
cout << *v_begin << " ";
} 
③然后是第三种方式,我们使用内置算法for_each
首先包含标准算法头文件<algorithm>
#include<algorithm>// 标准算法头文件使用for_each函数
// 方法 3
for_each(v.begin(), v.end(), my_print);
// 起始位置 结束位置 调用的函数我们自己实现my_print函数
void my_print(int val)
{
cout << val << " ";
}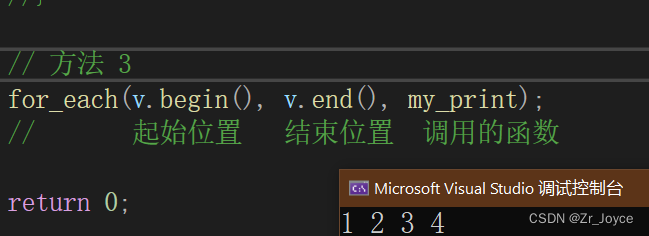
成功输出
而for_each函数的原理:
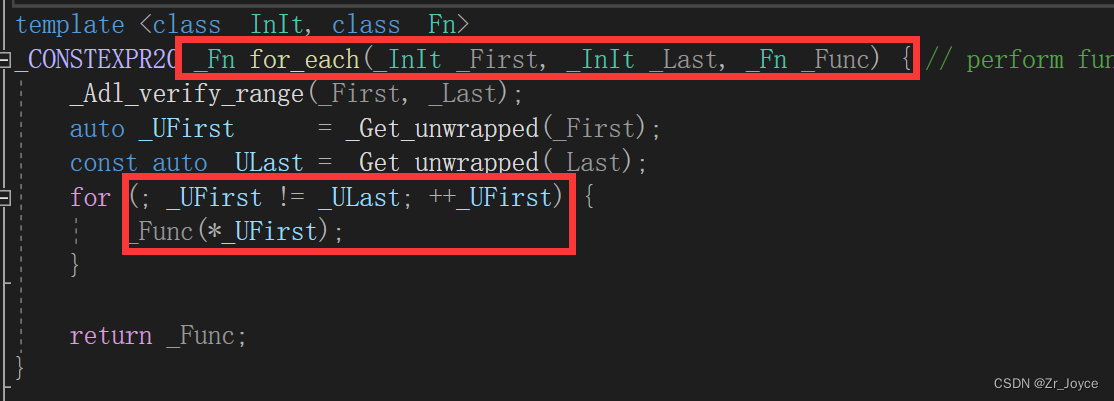
同样的起始地址与结束地址,以及函数
在for循环里,起始地址不等于结束地址,调用函数,参数为解引用*起始地址,所以我们函数参数是int val
2、存放自定义数据类型
①创建自定义数据类型class person
class person
{
public:
person(string name,int age)
{
m_age = age;
m_name = name;
}
int m_age;
string m_name;
};创建容器,并创建变量并尾插
void test01()
{
// 创建vector容器v
vector<person> v;
// 根据自定义数据类型创建对象
person p1("Joyce", 21);
person p2("Tatina", 20);
person p3("Yomi", 1);
person p4("nana", 18);
// 尾插进容器
v.push_back(p1);
v.push_back(p2);
v.push_back(p3);
v.push_back(p4);
// 访问数据
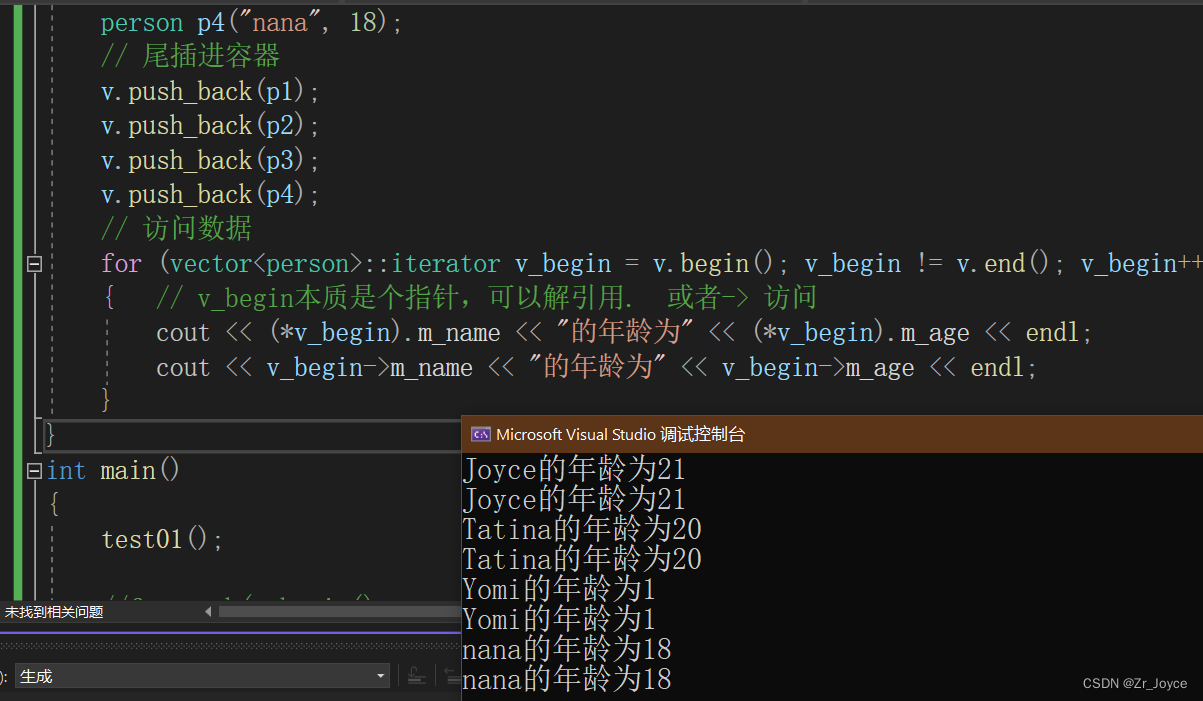
for (vector<person>::iterator v_begin = v.begin(); v_begin != v.end(); v_begin++)
{ // v_begin本质是个指针,可以解引用. 或者-> 访问
cout << (*v_begin).m_name << "的年龄为" << (*v_begin).m_age << endl;
cout << v_begin->m_name << "的年龄为" << v_begin->m_age << endl;
}
}
*v_begin的本质就是 vector后面<>中的person
②存放指针类型的自定义数据类型
同样的class person自定义数据类型
class person
{
public:
person(string name,int age)
{
m_age = age;
m_name = name;
}
int m_age;
string m_name;
};vector里我们不传入person,而是传入person*,即指针类型
void test02()
{
// 创建vector容器v
vector<person*> v;
// 根据自定义数据类型创建对象
person p1("Joyce", 21);
person p2("Tatina", 20);
person p3("Yomi", 1);
person p4("nana", 18);
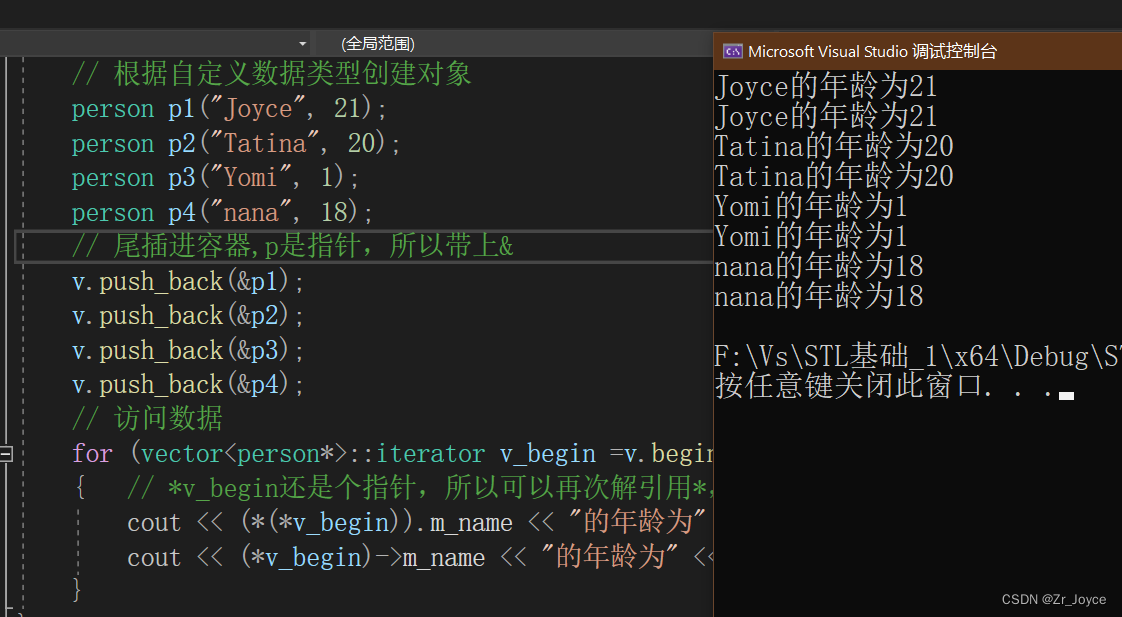
// 尾插进容器,p是指针,所以带上&
v.push_back(&p1);
v.push_back(&p2);
v.push_back(&p3);
v.push_back(&p4);
// 访问数据
for (vector<person*>::iterator v_begin =v.begin(); v_begin != v.end(); v_begin++)
{ // *v_begin还是个指针,所以可以再次解引用*,或者->访问
cout << (*(*v_begin)).m_name << "的年龄为" << (*(*v_begin)).m_age << endl;
cout << (*v_begin)->m_name << "的年龄为" << (*v_begin)->m_age << endl;
}
}
*v_begin的本质就是 vector后面<>中的person*
3、vector容器嵌套vector容器
void test03()
{
// 创建大容器v
vector<vector<int>> v;
// 创建小容器
vector<int> v1;
vector<int> v2;
vector<int> v3;
vector<int> v4;
// 向小容器中加入数据
int i = -1;
while (++i != 4)
{
v1.push_back(i + 1);
v2.push_back(i + 2);
v3.push_back(i + 3);
v4.push_back(i + 4);
}
// 将小容器加入到大容器中
v.push_back(v1);
v.push_back(v2);
v.push_back(v3);
v.push_back(v4);
// 通过大容器遍历所有数据
for (vector<vector<int>>::iterator v_begin = v.begin(); v_begin != v.end(); v_begin++)
{
// *v_begin == vector<int> ,所以我们需要再做一次遍历
for (vector<int>::iterator vv_begin = (*v_begin).begin();vv_begin != (*v_begin).end(); vv_begin++)
{
cout << *vv_begin << " ";
}
cout << endl;
}
}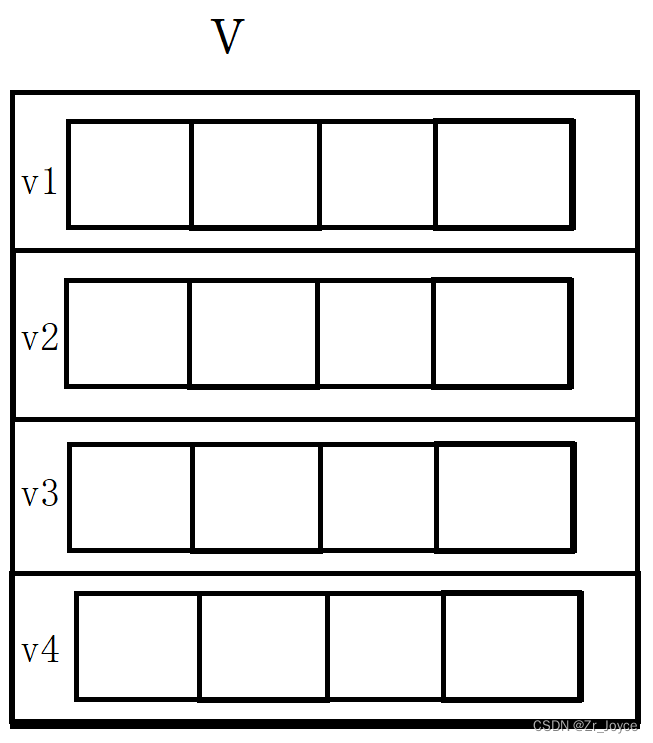
差不多是个二维数组
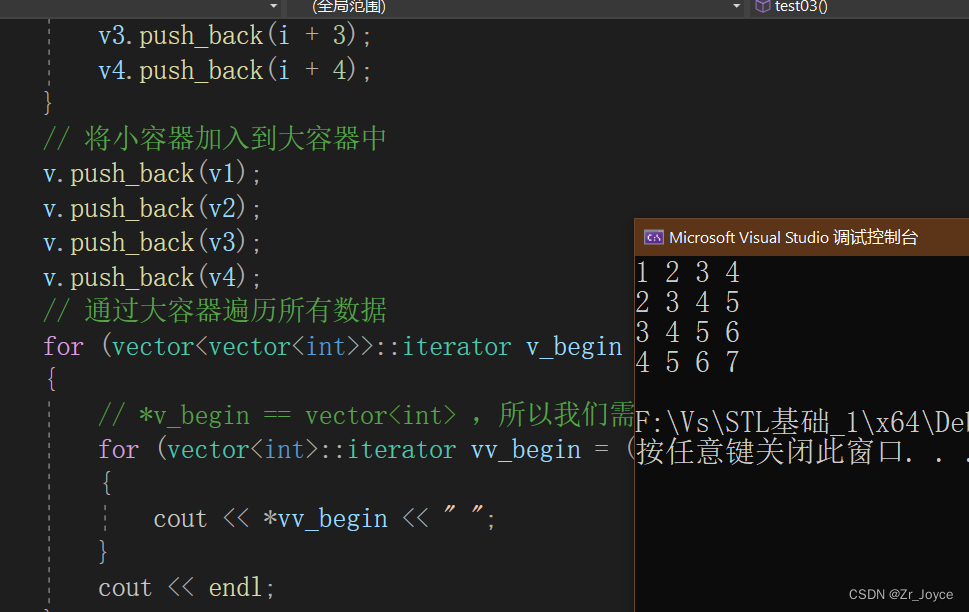
没啥说的,注意 *v_begin的本质就是 vector后面<>中的vector<int>,需要再来一次循环遍历数据,第二次遍历就用的(*v_begin)做对象,也就是(*v_begin).begin()是起始地址,(*v_begin).end()是结束地址,然后再*解引用访问