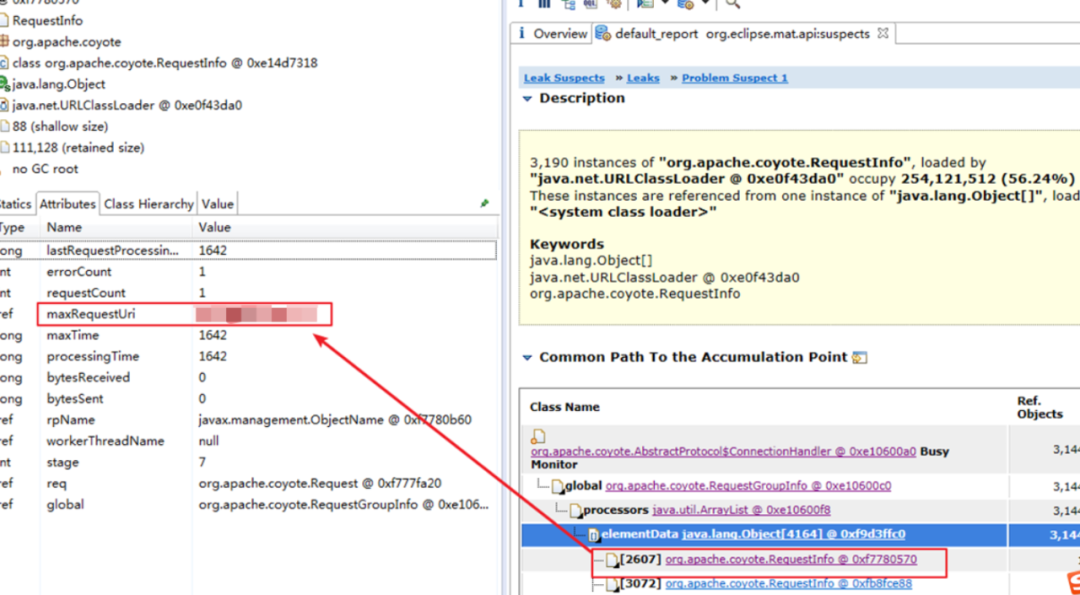
可靠、可扩展与可维护性
现在有很多都属于数据密集型,而不是计算密集型。对于这些类型应用,CPU的处理能力往往不是第一限制性因素,关键在于数据量、数据的复杂度及数据的快速多边形。
数据密集型应用模块:
- 数据库:存储数据,支持二次访问。
- 高速缓存:缓存复杂或操作代价昂贵的结果,加速下次访问。
- 索引:按关键字搜索数据并支持各种过滤。
- 流式处理:持续发送消息到另一个进程,处理采用异步方式。
- 批处理:定期处理大量的累计数据。
我们常见的数据库、队列、高速缓存,这些统称为“数据系统”
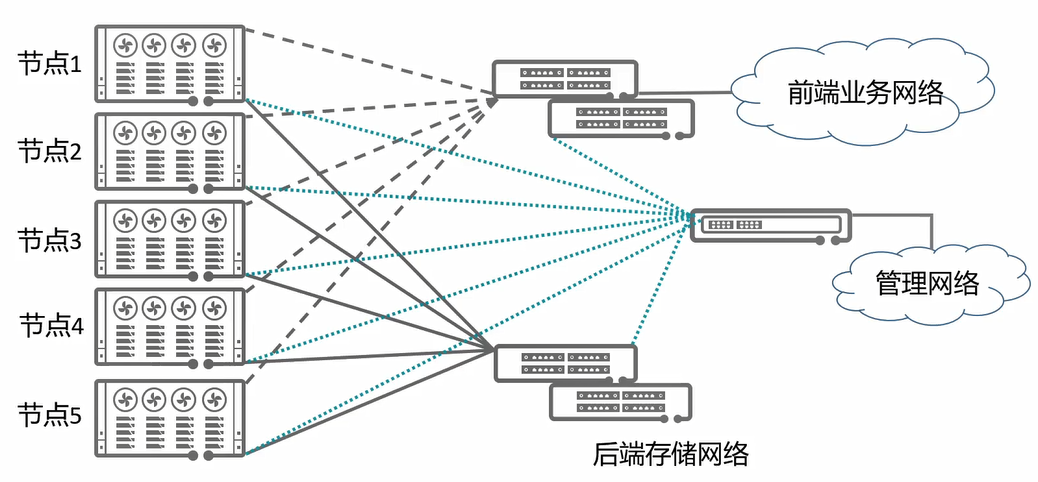
下面是一个常见的系统架构:

但是现实当中程序跑起来,并不是理想态的,会出现各种问题。例如:系统内出现局部失效,如何保证数据的正确性与完整性?发生降级该如何为客户提供一致的服务?负载增加,系统如何扩展?基于这些我们引入下面三个系统特性:
- 可靠性(Reliability)
当出现意外(硬件、软件故障、人为失误等),系统应可以正常工作;性能可能降低,但确保功能正常。 - 可扩展性(Scalability)
随着数据规模的增长,例如数据量、流量或复杂性,系统应以合理方式匹配这种增长 - 可维护性(Maintainability)
随着时间推移,新人加入系统开发和运维,系统都应搞笑运转。
可靠性
对于软件,典型的期望包括:
- 应用程序执行用户期望的功能。
- 可以容忍用户出现错误或不正确的使用方法。
- 性能可以应对典型的场景、合理负载压力和数据量。
- 系统可防止任何未经授权的访问和滥用。
可扩展性
- 描述负载
首先看Twitter典型业务操作:
(1)发布tweet消息:用户可以推送消息到所有关注者,平均大约4.6k request/sec,峰值约12k request/sec。
(2)主页时间线浏览:平均300k request/sec 查看关注对象的最新消息