注:参考B站‘小土堆’视频教程
视频链接:【PyTorch深度学习快速入门教程(绝对通俗易懂!)【小土堆】
系列文章:
深度学习快速入门----Pytorch 系列1
深度学习快速入门----Pytorch 系列2
深度学习快速入门----Pytorch 系列3
文章目录
- 一、完整的模型训练套路
- 1、预备知识
- 2、步骤
- 3、代码
- 4、运行结果
- 二、利用GPU训练
- 1、需要修改的地方
- 2、比较CPU与GPU训练耗费时间
- 3、用.to(device)的方式
- 三、完整的模型验证套路
一、完整的模型训练套路
1、预备知识
通过argmax计算正确率:
import torch
outputs = torch.tensor([[0.1,0.2],
[0.3,0.4]])
print(outputs.argmax(1))
preds = outputs.argmax(1)
targets = torch.tensor([0,1])
print((preds == targets).sum())

思路

2、步骤
- 准备数据集
- 利用 DataLoader 来加载数据集
- 创建网络模型
- 损失函数
- 优化器
- 设置训练网络的一些参数
- 设置训练轮数
-
训练步骤
- 计算损失函数
- 优化
-
测试步骤
- 计算损失函数
- 计算准确率
-
- 展示
- 保存模型
3、代码
# model.py
import torch
from torch import nn
# 搭建神经网络
class Tudui(nn.Module):
def __init__(self):
super(Tudui, self).__init__()
self.model = nn.Sequential(
nn.Conv2d(3, 32, 5, 1, 2),
nn.MaxPool2d(2),
nn.Conv2d(32, 32, 5, 1, 2),
nn.MaxPool2d(2),
nn.Conv2d(32, 64, 5, 1, 2),
nn.MaxPool2d(2),
nn.Flatten(),
nn.Linear(64*4*4, 64),
nn.Linear(64, 10)
)
def forward(self, x):
x = self.model(x)
return x
if __name__ == '__main__':
tudui = Tudui()
input = torch.ones((64, 3, 32, 32))
output = tudui(input)
print(output.shape)
# train.py
import torchvision
from torch.utils.tensorboard import SummaryWriter
from model import *
# 准备数据集
from torch import nn
from torch.utils.data import DataLoader
train_data = torchvision.datasets.CIFAR10(root="dataset", train=True, transform=torchvision.transforms.ToTensor(),
download=True)
test_data = torchvision.datasets.CIFAR10(root="dataset", train=False, transform=torchvision.transforms.ToTensor(),
download=True)
# length 长度
train_data_size = len(train_data)
test_data_size = len(test_data)
# 如果train_data_size=10, 训练数据集的长度为:10
print("训练数据集的长度为:{}".format(train_data_size))
print("测试数据集的长度为:{}".format(test_data_size))
# 利用 DataLoader 来加载数据集
train_dataloader = DataLoader(train_data, batch_size=64)
test_dataloader = DataLoader(test_data, batch_size=64)
# 创建网络模型
tudui = Tudui()
# 损失函数
loss_fn = nn.CrossEntropyLoss()
# 优化器
# learning_rate = 0.01
# 1e-2=1 x (10)^(-2) = 1 /100 = 0.01
learning_rate = 1e-2
# 随机梯度下降法
optimizer = torch.optim.SGD(tudui.parameters(), lr=learning_rate)
# 设置训练网络的一些参数
# 记录训练的次数
total_train_step = 0
# 记录测试的次数
total_test_step = 0
# 训练的轮数
epoch = 10
# 添加tensorboard
writer = SummaryWriter("logs_train")
for i in range(epoch):
print("-------第 {} 轮训练开始-------".format(i+1))
# 训练步骤开始
tudui.train()
for data in train_dataloader:
imgs, targets = data
outputs = tudui(imgs)
loss = loss_fn(outputs, targets)
# 优化器优化模型
optimizer.zero_grad()
loss.backward()
optimizer.step()
total_train_step = total_train_step + 1
if total_train_step % 100 == 0:
print("训练次数:{}, Loss: {}".format(total_train_step, loss.item()))
writer.add_scalar("train_loss", loss.item(), total_train_step)
# 测试步骤开始
tudui.eval()
total_test_loss = 0
# 整体正确率
total_accuracy = 0
with torch.no_grad():
for data in test_dataloader:
imgs, targets = data
outputs = tudui(imgs)
loss = loss_fn(outputs, targets)
total_test_loss = total_test_loss + loss.item()
accuracy = (outputs.argmax(1) == targets).sum()
total_accuracy = total_accuracy + accuracy
print("整体测试集上的Loss: {}".format(total_test_loss))
print("整体测试集上的正确率: {}".format(total_accuracy/test_data_size))
writer.add_scalar("test_loss", total_test_loss, total_test_step)
writer.add_scalar("test_accuracy", total_accuracy/test_data_size, total_test_step)
total_test_step = total_test_step + 1
# 保存某一轮训练后的结果
torch.save(tudui, "tudui_{}.pth".format(i))
print("模型已保存")
writer.close()
4、运行结果
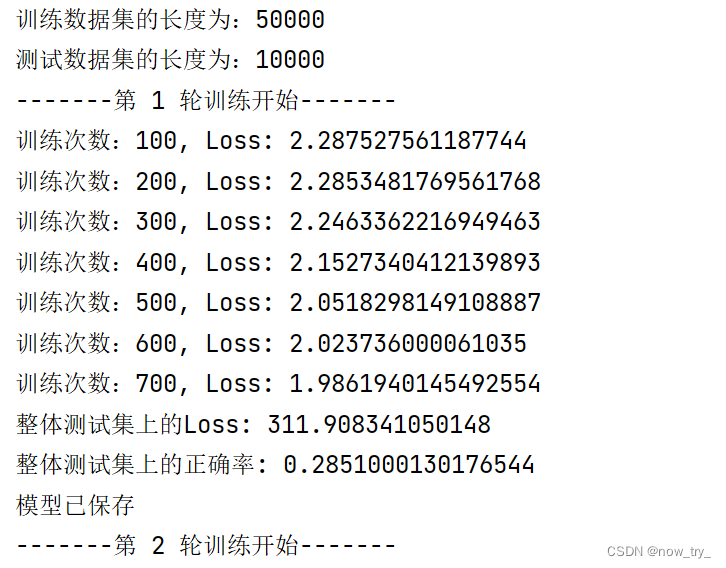
tensorboard:
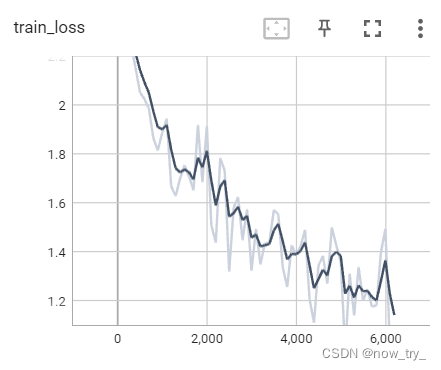
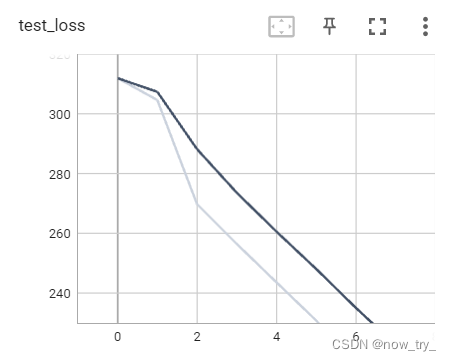
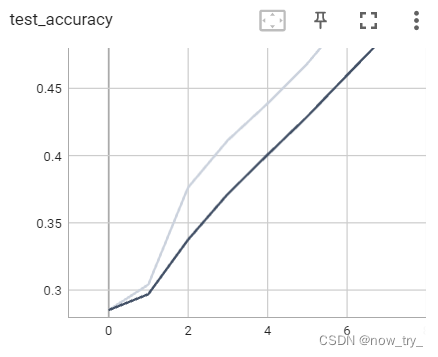
二、利用GPU训练
1、需要修改的地方
- 网络模型
- 数据(输入,标注)
- 损失函数
- .cuda()
import torch
import torchvision
from torch.utils.tensorboard import SummaryWriter
import time
# from model import *
# 准备数据集
from torch import nn
from torch.utils.data import DataLoader
train_data = torchvision.datasets.CIFAR10(root="dataset", train=True, transform=torchvision.transforms.ToTensor(),
download=True)
test_data = torchvision.datasets.CIFAR10(root="dataset", train=False, transform=torchvision.transforms.ToTensor(),
download=True)
# length 长度
train_data_size = len(train_data)
test_data_size = len(test_data)
# 如果train_data_size=10, 训练数据集的长度为:10
print("训练数据集的长度为:{}".format(train_data_size))
print("测试数据集的长度为:{}".format(test_data_size))
# 利用 DataLoader 来加载数据集
train_dataloader = DataLoader(train_data, batch_size=64)
test_dataloader = DataLoader(test_data, batch_size=64)
# 创建网络模型
class Tudui(nn.Module):
def __init__(self):
super(Tudui, self).__init__()
self.model = nn.Sequential(
nn.Conv2d(3, 32, 5, 1, 2),
nn.MaxPool2d(2),
nn.Conv2d(32, 32, 5, 1, 2),
nn.MaxPool2d(2),
nn.Conv2d(32, 64, 5, 1, 2),
nn.MaxPool2d(2),
nn.Flatten(),
nn.Linear(64*4*4, 64),
nn.Linear(64, 10)
)
def forward(self, x):
x = self.model(x)
return x
tudui = Tudui()
if torch.cuda.is_available():
tudui = tudui.cuda()
# 损失函数
loss_fn = nn.CrossEntropyLoss()
if torch.cuda.is_available():
loss_fn = loss_fn.cuda()
# 优化器
# learning_rate = 0.01
# 1e-2=1 x (10)^(-2) = 1 /100 = 0.01
learning_rate = 1e-2
optimizer = torch.optim.SGD(tudui.parameters(), lr=learning_rate)
# 设置训练网络的一些参数
# 记录训练的次数
total_train_step = 0
# 记录测试的次数
total_test_step = 0
# 训练的轮数
epoch = 10
# 添加tensorboard
writer = SummaryWriter("logs_train")
start_time = time.time()
for i in range(epoch):
print("-------第 {} 轮训练开始-------".format(i+1))
# 训练步骤开始
tudui.train()
for data in train_dataloader:
imgs, targets = data
if torch.cuda.is_available():
imgs = imgs.cuda()
targets = targets.cuda()
outputs = tudui(imgs)
loss = loss_fn(outputs, targets)
# 优化器优化模型
optimizer.zero_grad()
loss.backward()
optimizer.step()
total_train_step = total_train_step + 1
if total_train_step % 100 == 0:
end_time = time.time()
print(end_time - start_time)
print("训练次数:{}, Loss: {}".format(total_train_step, loss.item()))
writer.add_scalar("train_loss", loss.item(), total_train_step)
# 测试步骤开始
tudui.eval()
total_test_loss = 0
total_accuracy = 0
with torch.no_grad():
for data in test_dataloader:
imgs, targets = data
if torch.cuda.is_available():
imgs = imgs.cuda()
targets = targets.cuda()
outputs = tudui(imgs)
loss = loss_fn(outputs, targets)
total_test_loss = total_test_loss + loss.item()
accuracy = (outputs.argmax(1) == targets).sum()
total_accuracy = total_accuracy + accuracy
print("整体测试集上的Loss: {}".format(total_test_loss))
print("整体测试集上的正确率: {}".format(total_accuracy/test_data_size))
writer.add_scalar("test_loss", total_test_loss, total_test_step)
writer.add_scalar("test_accuracy", total_accuracy/test_data_size, total_test_step)
total_test_step = total_test_step + 1
torch.save(tudui, "tudui_{}.pth".format(i))
print("模型已保存")
writer.close()
2、比较CPU与GPU训练耗费时间
- CPU

- GPU

3、用.to(device)的方式
# ···
# 定义训练的设备
device = torch.device("cuda")
# ···
tudui = Tudui()
tudui = tudui.to(device)
# 损失函数
loss_fn = nn.CrossEntropyLoss()
loss_fn = loss_fn.to(device)
# ···
# 训练步骤开始
tudui.train()
for data in train_dataloader:
imgs, targets = data
imgs = imgs.to(device)
targets = targets.to(device)
outputs = tudui(imgs)
loss = loss_fn(outputs, targets)
# ···
# 测试步骤开始
tudui.eval()
total_test_loss = 0
total_accuracy = 0
with torch.no_grad():
for data in test_dataloader:
imgs, targets = data
imgs = imgs.to(device)
targets = targets.to(device)
outputs = tudui(imgs)
loss = loss_fn(outputs, targets)
total_test_loss = total_test_loss + loss.item()
accuracy = (outputs.argmax(1) == targets).sum()
total_accuracy = total_accuracy + accuracy
三、完整的模型验证套路

用GPU训练30轮后的网络模型:
import torch
import torchvision
from PIL import Image
from torch import nn
image_path = "imgs/dog.png"
image = Image.open(image_path)
print(image)
image = image.convert('RGB')
transform = torchvision.transforms.Compose([torchvision.transforms.Resize((32, 32)),
torchvision.transforms.ToTensor()])
image = transform(image)
print(image.shape)
class Tudui(nn.Module):
def __init__(self):
super(Tudui, self).__init__()
self.model = nn.Sequential(
nn.Conv2d(3, 32, 5, 1, 2),
nn.MaxPool2d(2),
nn.Conv2d(32, 32, 5, 1, 2),
nn.MaxPool2d(2),
nn.Conv2d(32, 64, 5, 1, 2),
nn.MaxPool2d(2),
nn.Flatten(),
nn.Linear(64*4*4, 64),
nn.Linear(64, 10)
)
def forward(self, x):
x = self.model(x)
return x
model = torch.load("tudui_29_gpu.pth", map_location=torch.device('cpu'))
print(model)
image = torch.reshape(image, (1, 3, 32, 32))
model.eval()
with torch.no_grad():
output = model(image)
print(output)
print(output.argmax(1))
运行结果:
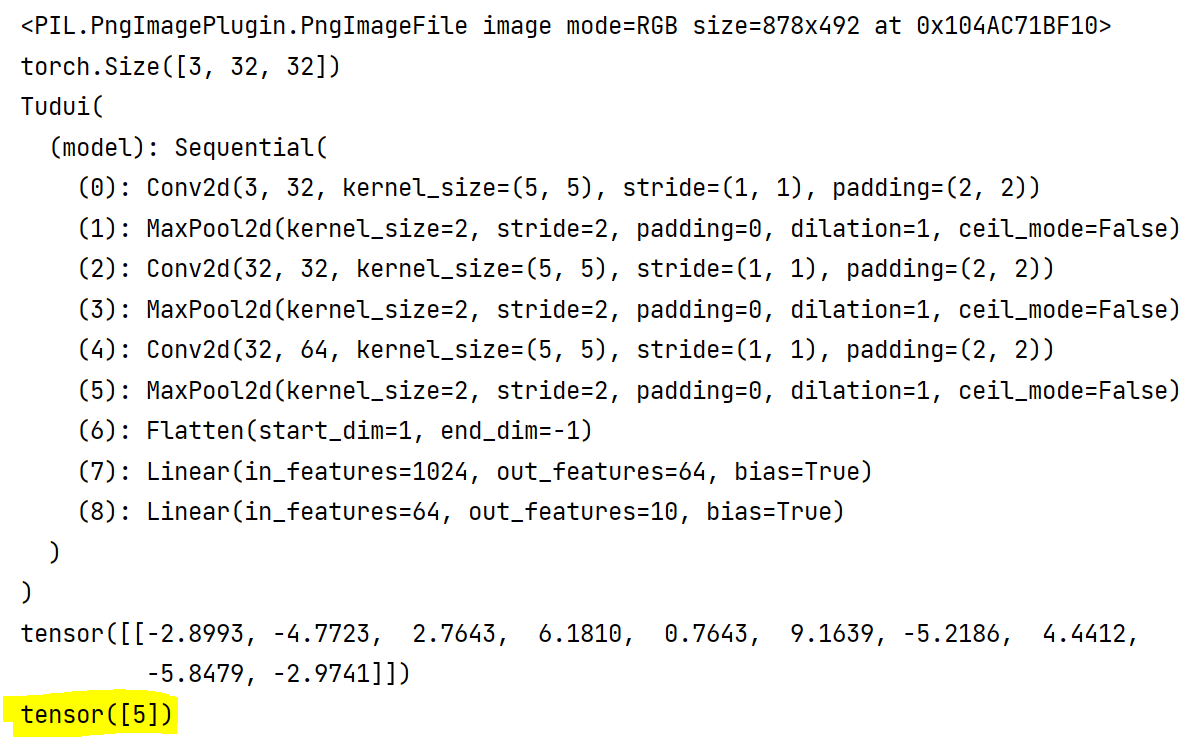
与CIFAR10数据集比较,预测正确:

![[附源码]计算机毕业设计JAVA小区供暖收费管理系统](https://img-blog.csdnimg.cn/828f8cc4b803406392a2f84aa7dac1cf.png)