N-gram是一种基于统计语言模型的算法,基本思想是将文本内容按照字节进行大小为N的滑动窗口操作,形成了长度是N的字节片段序列。
每一个字节片段称为gram,对所有gram的出现频度进行统计,并且按照事先设定好的阈值进行过滤,形成关键gram列表,也就是这个文本的向量特征空间,列表中的每一种gram就是一个特征向量维度。
该模型基于马尔可夫假设,每一个单词的出现都取决于它前面有限个单词。对于有限个单词数量n的不同定义,组成了不同的gram模型,
当n=1时,就是uni-gram,
当n=2时,就是bi-gram,
当n=3时,就是tri-gram,
在给定的训练语料中,利用贝叶斯定理,将上述的条件概率值都统计计算出来即可,以bigram为例,公示推导如下:
同理,可以得到trigram的条件概率公式:
n-gram条件概率公式为:
注意:如果N过大会导致对于当前单词的约束过强,则容易导致过拟合。简单理解就是特征太多训练集上是准确率高了,但是容易过拟合。
以Bi-gram为例,假设有三句话组成的语料库为:

则能计算出的概率为:
I出现3次,I do出现1次,则P(do|I)=1/3=0.33
do出现1次,do not出现1次,则P(not|do) =1/1=1
代码实现N-gram:
#coding:utf-8
def creat_ngram_list(input_list, ngram_num):
ngram_list = []
if len(input_list) <= ngram_num:
ngram_list.append(input_list)
else:
for temp in zip(*[input_list[i:] for i in range(ngram_num)]):
temp = "".join(temp)
ngram_list.append(temp)
return ngram_list
if __name__ == "__main__":
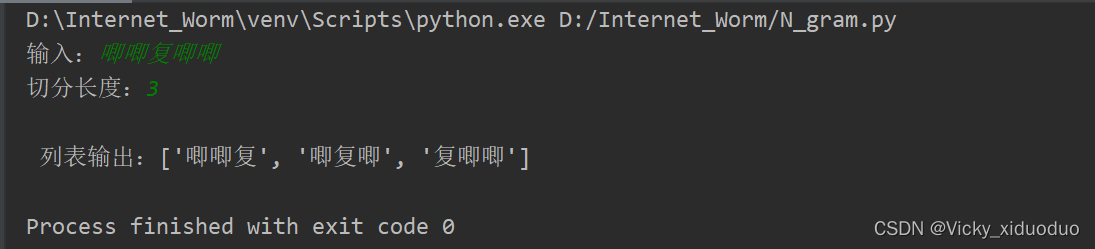
text = input("输入:")
ngram_num = int(input("切分长度:"))
print("\n 列表输出:{0}".format(creat_ngram_list(text,ngram_num)))结果为:
总结,N-gram模型的优点是基于有限的历史所以效率高,缺点是无法体现文本相似度,无法关联更早的信息。




![[附源码]Python计算机毕业设计Django的毕业生就业系统](https://img-blog.csdnimg.cn/f756222a4f4f4e649e9eefebad6abdd0.png)



![[附源码]计算机毕业设计springboot防疫物资捐赠](https://img-blog.csdnimg.cn/354131c1a87f4f428510820fe3f0fb6f.png)