前言:大家好,我是小威,24届毕业生,在一家满意的公司实习。本篇文章将介绍Elasticsearch在Java中的几种API的使用,这块内容不作为面试中的重点。
如果文章有什么需要改进的地方还请大佬不吝赐教👏👏。
小威在此先感谢各位大佬啦~~🤞🤞

🏠个人主页:小威要向诸佬学习呀
🧑个人简介:大家好,我是小威,一个想要与大家共同进步的男人😉😉
目前状况🎉:24届毕业生,在一家满意的公司实习👏👏💕欢迎大家:这里是CSDN,我总结知识的地方,欢迎来到我的博客,我亲爱的大佬😘

文章目录
- Java中API查询文档
- 全文查询
- 精确查询
- 复合查询
- 排序和分页
- 高亮显示
- 图书推荐
Java中API查询文档
Elasticsearch在网页端查询文档对应的DSL语句如下:
GET /hotel/_search
{
"query": {
"match": {
"all": "如家"
}
},
"highlight": {
"fields": {
"name": {
"require_field_match": "false"
}
}
}
}
执行上述语句打印结果如下:
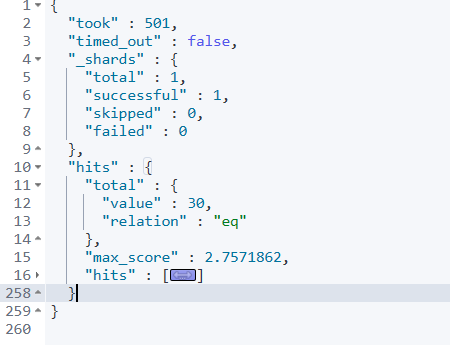
在Java代码中我们需要准备request,DSL语句以及发送请求
private RestHighLevelClient client;
@Test
void testMatchAll() throws IOException {
//准备request
SearchRequest request = new SearchRequest("hotel");//hotel为我们之前文章中所建立的索引库
//准备DSL语句,查询所有文档
request.source().query(QueryBuilders.matchAllQuery());
//发送请求
SearchResponse response = client.search(request, RequestOptions.DEFAULT);
//打印结果
System.out.println(response);
}
@BeforeEach
void setUp() {
client = new RestHighLevelClient(RestClient.builder(
HttpHost.create("http://192.168.220.***:9200")
));
}
@AfterEach
void tearDown() throws IOException {
client.close();
}
}
如下图所示,打印除开的结果为String类型,可以优化为HotelDoc对象类型。

其对应的Java代码改进后如下,以下的步骤是根据上面网页端响应出来的结果由外到内逐层解析出来的,相关详细注释如下:
@Test
void testMatchAll() throws IOException {
//准备request
SearchRequest request = new SearchRequest("hotel");
//准备DSL语句
request.source().query(QueryBuilders.matchAllQuery());
//发送请求
SearchResponse response = client.search(request, RequestOptions.DEFAULT);
//解析响应结果,对于网页端的hits,参考json解析结果由外到内逐层解析
SearchHits searchHits = response.getHits();
//获取命中的总条数
TotalHits total = searchHits.getTotalHits();
//打印搜索出多少条数据
System.out.println("共搜索出"+total+"条数据");
//搜索出的文档数组
SearchHit[] hits = searchHits.getHits();
//遍历文档数组
for (SearchHit hit : hits) {
//获取文档source
String json = hit.getSourceAsString();
//反序列为HotelDoc对象
HotelDoc hotelDoc = JSON.parseObject(json, HotelDoc.class);
//打印输出
System.out.println(hotelDoc);
}
执行上述代码所得结果如下,已反序列化为HotelDoc对象:

部分小结:
RestAPI其中构建DSL是通过RestHighLevelClient的source()方法实现的,如同我们浏览器中json中写的方法,其包含很多功能,如排序,分页,高亮等:
RestAPI中构建查询条件的核心部分是由QueryBuilders工具类提供的,其中包含了很多种查询方法。
全文查询
全文检索查询的match和multi_match查询与match_all的API基本一致,主要就是query部分的查询条件不一致,例如:
//这里的all是整合了需要查询的组合字段,在建立索引库时候添加的
request.source().query(QueryBuilders.matchQuery("all", "如家"));
除了此处不一致以外,其他代码均与上面一致

精确查询
精确查询常见的有term查询和range查询,可以使用QueryBuilders工具类来实现。
例如基于词条查询和范围查询的DSL语句如下:
# 词条查询
GET /hotel/_search
{
"query": {
"term": {
"city": "上海"
}
}
}
# 范围查询
GET /hotel/_search
{
"query": {
"range": {
"price": {
"gte": 100,
"lte": 200
}
}
}
}
使用QueryBuilders工具类来实现的代码如下:
request.source().query(QueryBuilders.termQuery("city","上海"));
request.source().query(QueryBuilders.rangeQuery("price").gt(150).lt(200));
复合查询
例如使用term查询和range查询组合到一起来进行组合查询,在DSL中的语句为:
GET /hotel/_search
{
"query": {
"bool": {
"must": [
{
"term": {
"city": {
"value": "上海"
}
}
}
],
"filter": [
{
"range": {
"price": {
"gte": 150,
"lte": 200
}
}
}
]
}
}
}
将其转化为Java语言中的代码,如下:
//准备DSL语句
BoolQueryBuilder boolQuery = QueryBuilders.boolQuery();
boolQuery.must(QueryBuilders.termQuery("city","上海"));
boolQuery.filter(QueryBuilders.rangeQuery("price").gt(150).lt(200));
request.source().query(boolQuery);
执行代码得到以下结果:

排序和分页
对搜索的结果进行排序和分页,是与query同级的参数,由以下的DSL语句可以看出:
GET /hotel/_search
{
"query": {
"match_all": {}
},
"from": 0,
"size": 5
, "sort": [
{
"price": {
"order": "desc"
}
}
]
}
上面DSL对于的Java代码如下,query和sort等为同级结构:
//准备DSL语句
request.source().query(QueryBuilders.matchAllQuery());
request.source().from(0).size(5);//查询结果显示五条数据
request.source().sort("price", SortOrder.ASC);//按照升序的顺序排列
执行结果如下:

高亮显示
高亮API包括请求DSL构建和结果解析两部分,DSL语句如下:
GET /hotel/_search
{
"query": {
"match": {
"all": "如家"
}
},
"highlight": {
"fields": {
"name": {
"require_field_match": "false"
}
}
}
}
网页端高亮显示结果如下图所示:

Java代码如下:
@Test
void testHighLighter() throws IOException {
//准备request
SearchRequest request = new SearchRequest("hotel");
//准备DSL语句
request.source().query(QueryBuilders.matchQuery("name","如家"));
request.source().highlighter(new HighlightBuilder().field("name").requireFieldMatch(false));
//发送请求
SearchResponse response = client.search(request, RequestOptions.DEFAULT);
//解析响应结果,对于网页端的hits,参考json解析结果由外到内逐层解析
handleResponse(response);
}
private void handleResponse(SearchResponse response) {
//解析响应结果,对于网页端的hits,参考json解析结果由外到内逐层解析
SearchHits searchHits = response.getHits();
//获取命中的总条数
TotalHits total = searchHits.getTotalHits();
//打印搜索出多少条数据
System.out.println("共搜索出" + total + "条数据");
//搜索出的文档数组
SearchHit[] hits = searchHits.getHits();
//遍历文档数组
for (SearchHit hit : hits) {
//获取文档source
String json = hit.getSourceAsString();
//反序列为HotelDoc对象
HotelDoc hotelDoc = JSON.parseObject(json, HotelDoc.class);
//获取高亮结果
Map<String, HighlightField> highlightFields = hit.getHighlightFields();
//如果高亮结果不为空才设置值
if(!CollectionUtils.isEmpty(highlightFields)){
//根据字段名称获取高亮结果
HighlightField highlightField = highlightFields.get("name");
if(highlightField!=null){
//获取高亮值
String name = highlightField.getFragments()[0].string();
//覆盖非高亮结果
hotelDoc.setName(name);
}
}
//打印输出
System.out.println(hotelDoc);
}
}

写了这么多API的使用”,感觉大佬如果看完的话会稍微有些累哈哈。
好了,本篇文章就先分享到这里了,后续会继续分享其他方面的知识,感谢大佬认真读完支持咯~

为了感谢朋友们的支持,接下来为粉丝朋友们送 些小福利哦(送书活动)~~
图书推荐
Java 诞生 27 年来,这本享誉全球的 Java 经典著作《Core Java》一路伴随着 Java 的成长,得到了百万 Java 开发者的青睐,几乎出现在每个“学Java要看什么书”类似的书单里,影响了几代技术人。
27年间,每当 Java 有新的 LTR 版本发布,这本书都会随之更新,这次也不例外。现在,针对 Java 17 新特性的《Java核心技术》第 12 版*中文版(卷1)终于上市了!
《Java核心技术》第 12 版涵盖了 Java 17 的最新特性,相应调整了部分内容结构,同时延续之前版本的优良传统,利用清晰明了的示例加以解释,并提供了全部示例代码,以便读者学习和灵活应用。它将续写从前的辉煌,使开发者能及时跟上 Java 前进的步伐。
我们寻找了50位曾经看着《Java核心技术》这本书成长起来的KOL推荐本书!大家的寄语全部收录在第12版新书中!

这本书究竟是怎样的一本书,得到众多开发者的一致推荐呢?

●《Java核心技术》并非市面那些零基础速成的书,很好地避免了开发基础书容易犯的“大而泛”的问题,尽管内容繁多,但对知识点的介绍并非泛泛而过。通过周密组织,从Java繁杂的内容中整理出一条清晰的主线,构成一个完整的知识体系。
●整本书不仅让你深入了解设计和实现Java应用涉及的所有基础知识和Java特性,还会帮助你掌握开发Java程序所需的全部基本技能。
●作者凯.霍斯特曼是Java技术坚定的倡导者,至今仍常年在国际上的各类计算机峰会上进行技术分享。在位于硅谷中心的圣何塞州立大学教学30余年,为硅谷的顶尖科技公司培养了大量计算机专业人才。非常熟知大厂要什么!所以他的书也是非常有针对性。
●为帮助大家更轻松地学习Java,作者还亲自录制了配套视频讲解课程,视频配有中文配音+中文字幕,与纸书涵盖内容基本一致,适配Java SE8以后的版本。纸书+视频搭配学习,学习Java更轻松。(B站搜索“Java核心技术站”直达)。
…
相信在学习Java的道路上有了《Java核心技术》这本书的辅助,你一定可以做到事半功倍。
评论区留言:人生苦短,我用Java(评论最多五条抽取四名幸运观众)。
京东自营购买链接:点击跳转
文章到这里就结束了,如果有什么疑问的地方请指出,诸佬们一起讨论😁
希望能和诸佬们一起努力,今后我们顶峰相见🍻
再次感谢各位小伙伴儿们的支持🤞