目录
1.概念
1.1.什么是MySQL
1.2.关系型数据库、非关系型数据库
1.3.库、表、字段
2.数据类型
2.1.数值
2.2.字符串
2.3.日期/时间
3.结构化查询语言
3.1.DDL
3.2.DML
3.3.DCL
3.4.DQL
3.4.1.结果集
3.4.2.取别名
3.4.3.查列
3.4.4.条件查询
3.4.5.模糊查询
3.4.6.去重
3.4.7.字段运算
3.4.8.排序
3.4.9.聚合函数
3.4.10.分组
3.4.11.having函数
3.4.12.分页查询
1.概念
1.1.什么是MySQL
开源、轻量级的一款关系型数据库,在业内有着广泛应用。
1.2.关系型数据库、非关系型数据库
按照组织数据的方式进行分类,数据库可以分为关系型、非关系型两种。两者各自的特点如下:
| 关系型 | 非关系型 |
|---|---|
| 用表格来组织数据,一个表里是一类数据 | 用各种数据结构(如文档、键值对、列族等)来存储数据 |
| 存储的数据是结构化数据,对数据的长度、类型有严格约束 | 存储的数据可以是半结构化、非结构化的,对数据的长度、类型没有严格约束 |
| 数据之间(表之间)可以通过主键、外键之间建立起很强的关系 | 数据之间相对独立,没有建立起很强关联关系的方式 |
| 用 SQL 语言来操作数据,提供了强大的事务管理和 ACID 特性 | 没有固定的查询语言,通常使用类似于文档的 API 来查询数据,一般不支持事务和ACID |
| 适用于需要高度结构化数据和高度数据一致性的应用场景 | 适用于需要高度可伸缩性、高速度读写、大数据处理等场景 |
1.3.库、表、字段
库、表、字段,可以理解为三者组成了数据库的层级结构,就像小区、单元楼、户之间的关系。
库(Database):库是一组相关的表的集合,可以看作是一个存储数据的容器。在数据库中,一个库通常对应一个应用程序或一个业务领域。
表(Table):表是一组有结构的数据集合,由若干行和若干列组成。每行表示一个记录,每列表示一种属性。表是数据库的核心,一个库可以包含多个表。
字段(Column):字段是表中的一列,用于存储一种特定类型的数据。字段具有一个名字和一个数据类型,可以包含整数、浮点数、字符串等不同类型的数据。每个字段还可以有约束条件,如主键、外键、非空约束等,用于保证数据的完整性和一致性。
主键:
表中一条数据的唯一标识,在同一个表中不允许重复,类似于一条数据的身份证号码。
外键:
用于关联两个表。两个表之间的外键值是相同的。
索引:
索引可以理解为一个
2.数据类型
MySql中常用的数据类型可以分为三类:
-
数值
-
字符串
-
日期/时间
2.1.数值
| 类型 | 大小 | 范围(有符号) | 范围(无符号) | 用途 |
|---|---|---|---|---|
| TINYINT | 1 Bytes | (-128,127) | (0,255) | 小整数值 |
| SMALLINT | 2 Bytes | (-32 768,32 767) | (0,65 535) | 大整数值 |
| MEDIUMINT | 3 Bytes | (-8 388 608,8 388 607) | (0,16 777 215) | 大整数值 |
| INT或INTEGER | 4 Bytes | (-2 147 483 648,2 147 483 647) | (0,4 294 967 295) | 大整数值 |
| BIGINT | 8 Bytes | (-9,223,372,036,854,775,808,9 223 372 036 854 775 807) | (0,18 446 744 073 709 551 615) | 极大整数值 |
| FLOAT | 4 Bytes | (-3.402 823 466 E+38,-1.175 494 351 E-38),0,(1.175 494 351 E-38,3.402 823 466 351 E+38) | 0,(1.175 494 351 E-38,3.402 823 466 E+38) | 单精度 浮点数值 |
| DOUBLE | 8 Bytes | (-1.797 693 134 862 315 7 E+308,-2.225 073 858 507 201 4 E-308),0,(2.225 073 858 507 201 4 E-308,1.797 693 134 862 315 7 E+308) | 0,(2.225 073 858 507 201 4 E-308,1.797 693 134 862 315 7 E+308) | 双精度 浮点数值 |
| DECIMAL | 对DECIMAL(M,D) ,如果M>D,为M+2否则为D+2 | 依赖于M和D的值 | 依赖于M和D的值 | 小数值 |
2.2.字符串
| 类型 | 大小 | 用途 |
|---|---|---|
| CHAR | 0-255 bytes | 定长字符串 |
| VARCHAR | 0-65535 bytes | 变长字符串 |
| TINYBLOB | 0-255 bytes | 不超过 255 个字符的二进制字符串 |
| TINYTEXT | 0-255 bytes | 短文本字符串 |
| BLOB | 0-65 535 bytes | 二进制形式的长文本数据 |
| TEXT | 0-65 535 bytes | 长文本数据 |
| MEDIUMBLOB | 0-16 777 215 bytes | 二进制形式的中等长度文本数据 |
| MEDIUMTEXT | 0-16 777 215 bytes | 中等长度文本数据 |
| LONGBLOB | 0-4 294 967 295 bytes | 二进制形式的极大文本数据 |
| LONGTEXT | 0-4 294 967 295 bytes | 极大文本数据 |
2.3.日期/时间
| 类型 | 大小 ( bytes) | 范围 | 格式 | 用途 |
|---|---|---|---|---|
| DATE | 3 | 1000-01-01/9999-12-31 | YYYY-MM-DD | 日期值 |
| TIME | 3 | '-838:59:59'/'838:59:59' | HH:MM:SS | 时间值或持续时间 |
| YEAR | 1 | 1901/2155 | YYYY | 年份值 |
| DATETIME | 8 | '1000-01-01 00:00:00' 到 '9999-12-31 23:59:59' | YYYY-MM-DD hh:mm:ss | 混合日期和时间值 |
| TIMESTAMP | 4 | '1970-01-01 00:00:01' UTC 到 '2038-01-19 03:14:07' UTC结束时间是第 2147483647 秒,北京时间 2038-1-19 11:14:07,格林尼治时间 2038年1月19日 凌晨 03:14:07 | YYYY-MM-DD hh:mm:ss | 混合日期和时间值,时间戳 |
3.结构化查询语言
结构化查询语言分为四类:
-
DDL,数据库定义语言
-
DML,数据操作语言
-
DQL,数据查询语言
-
DCL,数据控制语言
3.1.DDL
DDL,数据库定义语言,用来操作库、表、字段,用来对他们进行创建、删除、修改。
建库:
create database 名字 (character set utf8);
括号中是可填参数,建库时可以指定字符集。
create table 表名{
id bigint,
name varchar(25)
} (engine=innodb default charset=utf8);
括号中是可填参数,建表的时候可以指定引擎和字符集,不指定的话会用默认的引擎和字符集。
修改表结构:
修改字段:
alter table 表名 add 字段名 数据类型;
alter table 表名 drop 字段名;
alter table 表名 modify 字段名 数据类型;
alter table 表名 change 原始列名 新列名 数据类型;
修改表名:
rename table 原始表名 to 新表名;
修改表字符集
alter table 表名 character set 字符集名;
删除表
drop table 表名;
3.2.DML
DML,数据操作语言,用来对表中的数据进行增删改查。
查询:
select * from 表名;
插入:
insert into 表名 (列名1,列名2,…) value(值1,值2,…);
注意列名和值一一对应。
批量插入:
insert into student values(2,'chen',22),(2,'chen',22);
更新:
update 表名 set 列名 =新值 where 约束条件;
不跟约束条件的话表里的数据会全改
批量更新:
updata 表名 set 列名1 =新值,列名2=新值,….,where 约束条件;
不跟约束条件的话数据会全改
3.3.DCL
DCL,数据控制语言,定义权限。用来控制数据库、表、字段、用户的访问权限和安全级别。
常用关键字:grant、revoke等。
创建用户并分配权限:
create user 'usertest'@'%' indentified by '123456';
grant all privileges on mydb.* to 'usertest'@'%';
回收权限:
revoke delete on mydb.* from 'usertest'@'%'
查看权限:
show grants for 'usertest'@'%';
3.4.DQL
DQL,数据查询语言,SQL中最常用也是最核心的内容。
注意:本文的DQL暂时只限定于单表查询,多表联查在下一篇文章聊MySQL的高级内容时会细聊
3.4.1.结果集
查询出来的结果叫结果集,会以表的形式呈现,这张表是张虚拟的表,并不真实存在,存放在内存里面。
3.4.2.取别名
可以为表、字段取别名,如:
select username as un,password as pw from sys_user su where su.name='admin';
3.4.3.查列
select 列1,列2……from 表名;
3.4.4.条件查询
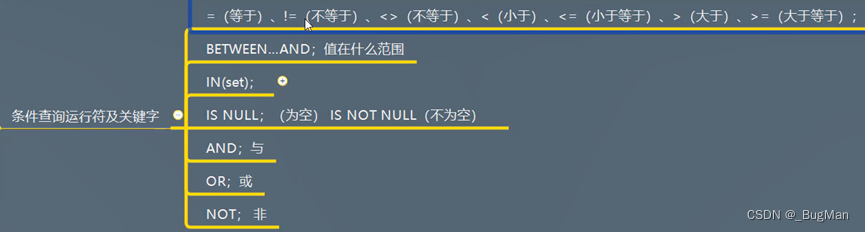
通过where后面的条件来约束查询的范围,where后面可以跟很多条件运算符:
3.4.5.模糊查询
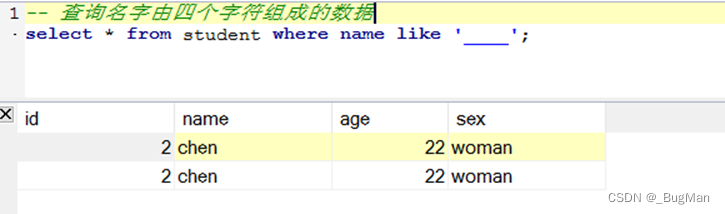
通配符:
‘_’ 一个下划线代表任意单个字符
‘%’百分号表示任意个字符。
注意:通配符必须由单引号引起来,否则会报错。
3.4.6.去重
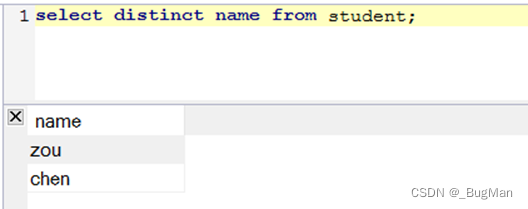
可以在字段前面跟上distinct关键字,查询结果会根据该关键字来去重。
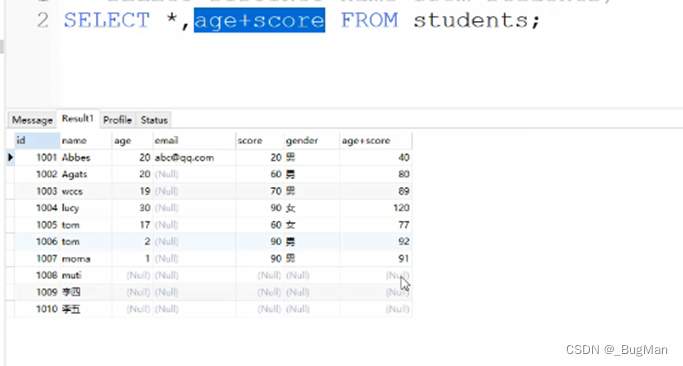
3.4.7.字段运算
字段运算的前提是都为数值型
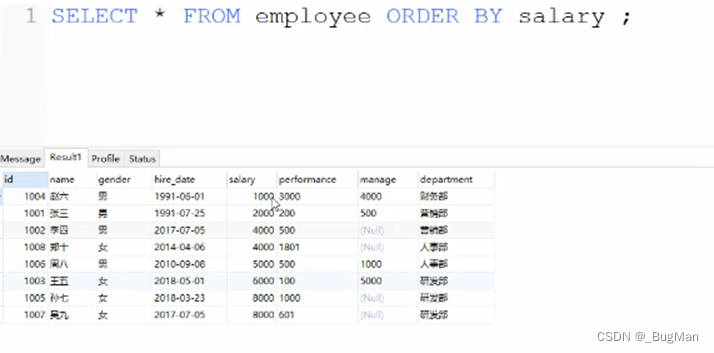
3.4.8.排序
使用order by来对查询结果按字段进行排序,默认是升序
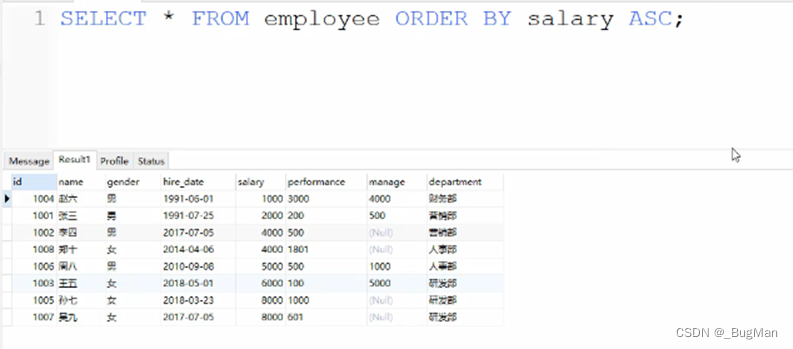
也可以指定为升序或者降序:
ASC指定为升序,DESC指定为降序,此处以ASC为例:
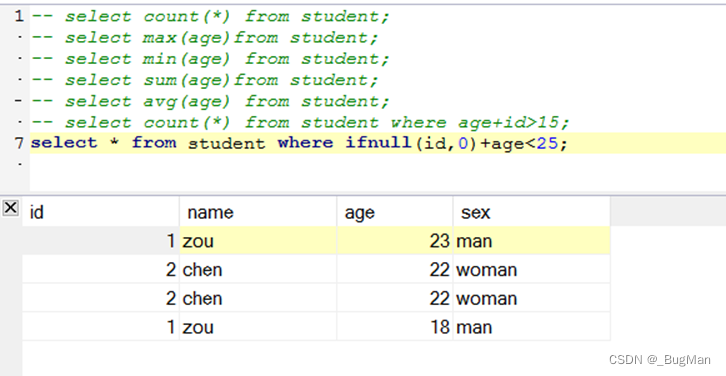
3.4.9.聚合函数
mysql有一些内置函数用来求最大、最小、平均值、总数等。
3.4.10.分组
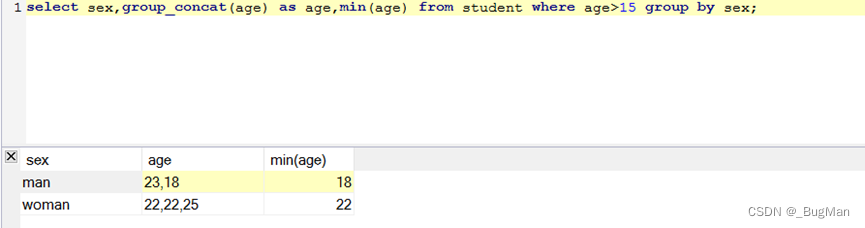
使用group by可以按照字段对结果集进行分组,想显示分组字段外的其他字段用group_concat函数:
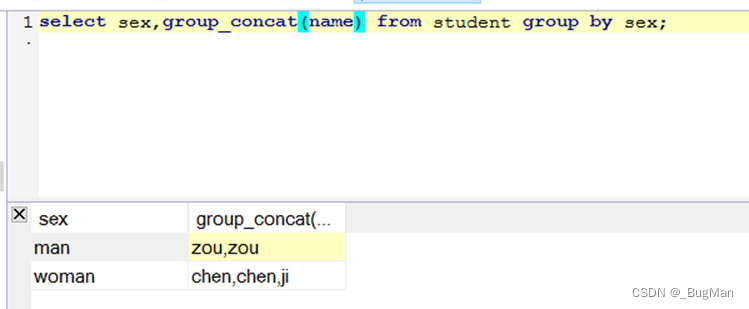
分组函数可以与聚合函数联合起来用,这样聚合函数的范围会限定在每一个分组内部:
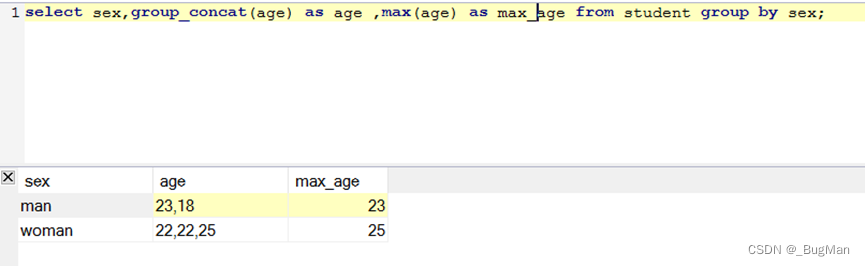
分组函数是对结果集进行分组,所以自然可以和条件函数一起联合使用:
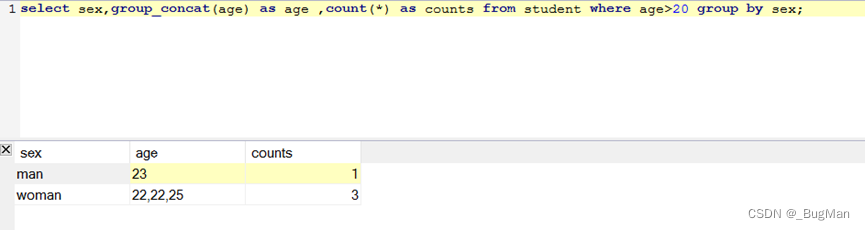
3.4.11.having函数
having和where的效果不一样!!!
having写在group by的后面,分组后对数据过滤。
where写在group by的前面,分组前对数据过滤。
having可以用聚合函数,因为操作的是一个分组
where不可以用聚合函数,因为操作的是单个数据
where是让不满足条件的数据从分组里干掉,
having是干掉含有不满足条件的分组
having函数:
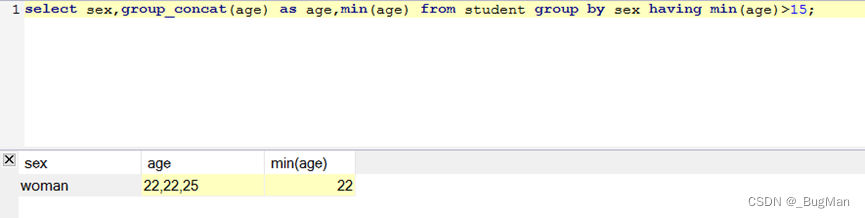
where函数:
3.4.12.分页查询
limit 起始位(0开始),查几位(包括当前位)