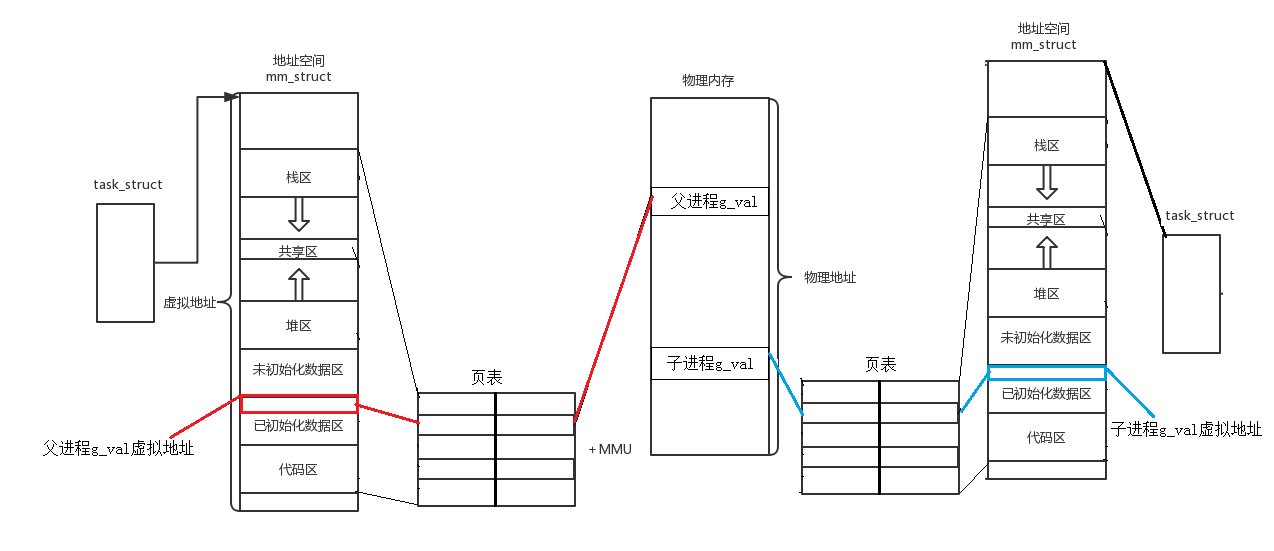
ABBYY,一款强大的OCR文字识别软件!
在日常的工作中,我们常常需要提取PDF或图片上的大段文字,如果字数少的话,我们可以直接手打,但如果出现大篇幅的文字,那就有点头疼了。今天,我就向大家推荐一款强大的OCR文字识别软件,来帮大家快速识别图片或PDF文件上的文字。
软件版本及系统:ABBYY FineReader PDF 15;Windows10系统
- 识别图片上的文字

图1:软件界面
首先,打开这款文字识别软件,我们会看到如下操作界面。
点击如图所指的按钮,转换文档,在OCR编辑器中打开。
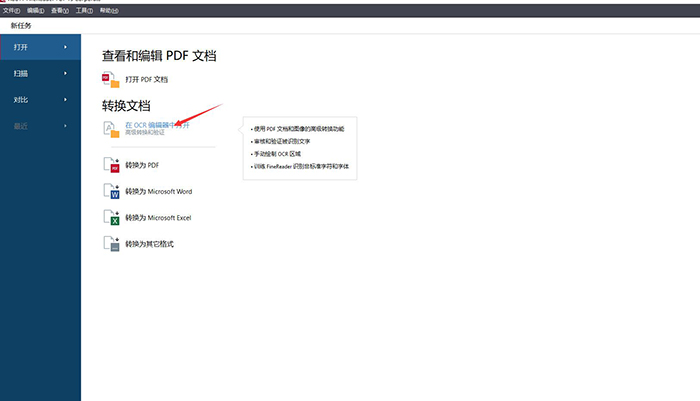
图2:在OCR编辑器中打开
点击命令后,找到我们提前准备好的文件,可以是图片,也可以是PDF文件。我这里以一张书籍截图来为大家做演示。

图3:选择文件
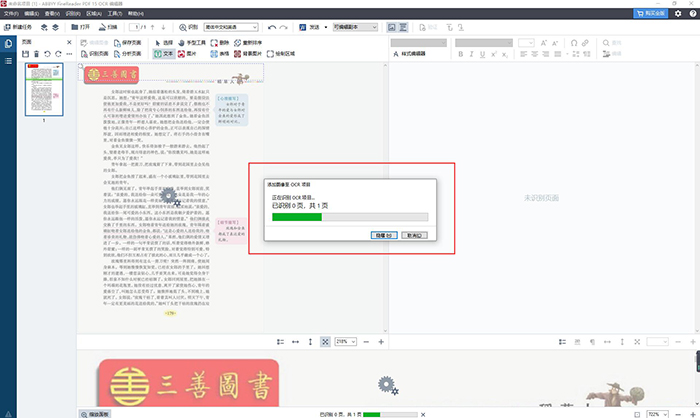
图4:开始识别
点选文件后,软件就会自动开始读取。画面中间就是软件读取识别的进度,速度的快慢与电脑的配置、文件的清晰度成正比。

图5:识别完成
在识别完成后,画面中会出现提示框,点击确定即可。右边便是软件识别出来的文字内容,可用于编辑储存。
- 文字储存与编辑
我们可以看到,在识别完成的文字部分,会出现一些带有蓝色底纹的文字。这些是未识别出来或是有异议的部分,原因是这部分的图片不够清晰,需要手动进行编辑。

图6:识别出来可编辑的文字

图7:手动编辑错误内容
选择带有蓝色底纹的文字内容,对照左边的文件图片,将识别错误的内容重新输入即可。

图8:选择识别范围
在识别的过程中,我们也可以自行选择想要识别的范围。如下图,我选择了右下角的解析,点击删除,那么右边文字框中对应的文字也消失了。

图9:删除不需要的部分
图10:储存文字
点击上方的发送按钮,即可将识别出来的文件存储下来。
这里我选择了储存为word格式,名称为书籍截图。

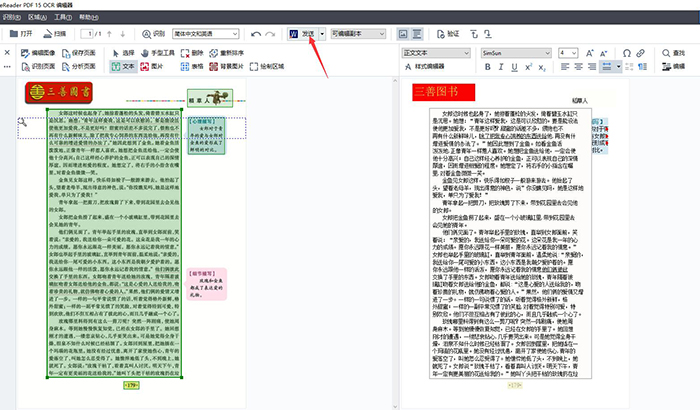
图11:编辑名称

图12:word文档
储存完成后,会直接在word软件中打开。

图13:编辑文字
在word中,我们可以自行对文字的大小、字体、段落格式进行编辑。
在word中确认了文字内容和格式后,点击文件另存为,即可转出最终文件。
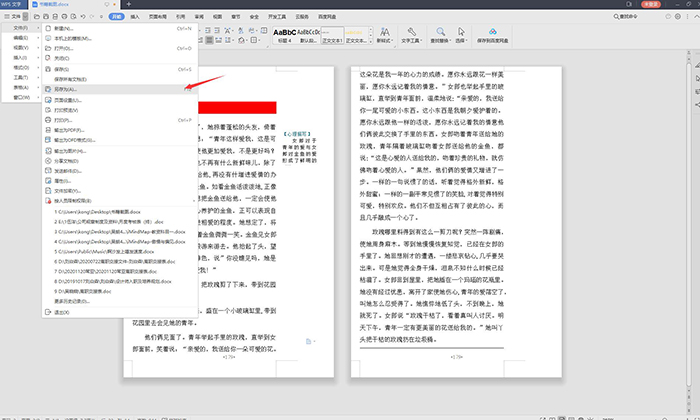
图14:储存文件
图15:文件命名
这里我们将文件命名为书籍的名称,代表这是最终的确认文件,和之前的文件区分开来。
图16:最终识别文件
最终识别出来的文件。
ABBYY 15 下载地址:https://souurl.cn/dJj29Y
以上,就是ABBYY这款文字识别软件使用图片识别的全过程了。通过这个方法,即使图片上有大批量的文字,我们也能够轻松将其识别出来,极大地方便了日常的学习和工作。