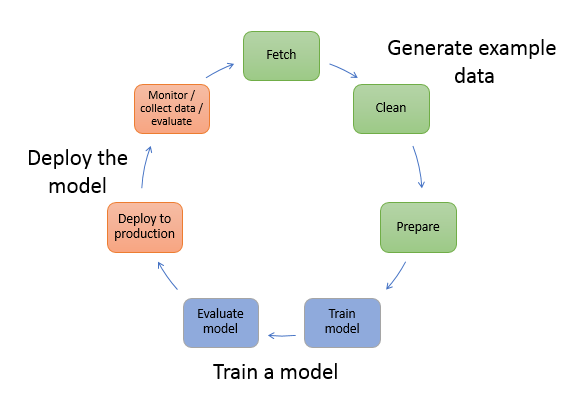
如果你喜欢哲学并且你是一个 IT 从业者,那么你很可能对软件哲学感兴趣,你能发现存在于软件领域的哲学之美。本文我们就从软件哲学的角度来了解一下亚马逊云科技的拳头级产品 Amazon SageMaker,有两个出发点:一是 SageMaker 本身设计所遵循的软件哲学;二是从软件哲学的角度我们应该如何使用 SageMaker 提供的功能。SageMaker 是一个全托管的机器学习平台(包括传统机器学习和深度学习),它覆盖了整个机器学习的生命周期,如下图所示:
| 亚马逊云科技开发者社区为开发者们提供全球的开发技术资源。这里有技术文档、开发案例、技术专栏、培训视频、活动与竞赛等。帮助中国开发者对接世界最前沿技术,观点,和项目,并将中国优秀开发者或技术推荐给全球云社区。如果你还没有关注/收藏,看到这里请一定不要匆匆划过,点这里让它成为你的技术宝库! |
我们从如下的几个方面来展开讨论:
- 天下没有免费的午餐——权衡之道
- 简单之美——大道至简
- 没有规矩不成方圆——循规蹈矩
- 没有“银弹”——对症下药
- 变化之本——进化本质
- 知其所以然——心中有数
- 保持一致性——质量可控
天下没有免费的午餐——权衡之道
软件有很多的品质(品质也叫非功能性需求):性能(比如时间性能,空间性能,模型性能),可用性,易用性,可扩展性,兼容性,可移植性,灵活性,安全性,可维护性,成本等。一个软件没有办法满足所有的品质,因此我们在和用户交流的过程中,要真的弄清楚用户想要的是什么(没有想象中那么简单),哪个或者哪些软件的品质是用户当前最关心的。很多软件品质经常会互相制约(一个经典的例子就是安全性和时间性能,安全这个品质就是一个让人又爱又恨的东西,一般来说需要加入安全性的时候,在其他上下文不变的情况下,基本上时间性能就会变差了),所以我们需要权衡,而在权衡的时候一定要把握好“度“。
对于 SageMaker 来说:
- SageMaker Processing job 要求数据的输入和输出都需要在 S3,基本原理图如下:
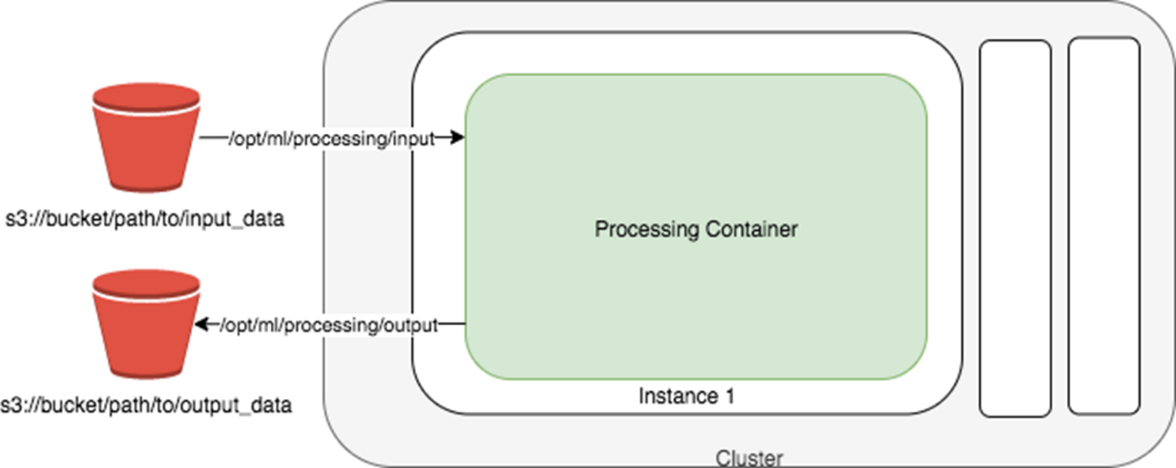
SageMaker Processing job 提供了托管的单个实例或者集群来做数据预处理,特征工程以及模型评估。如果你的原始数据并没有存放在 S3,这个时候你需要权衡空间性能与可托管性(可托管性的好处是很多运维的工作就不需要你关心了,交给了亚马逊云科技来运维),是把数据从源拷贝到 S3 来使用托管的 Processing job 服务还是就地来用自建的集群来处理;如果你的原始数据本身就存放在 S3,那么直接用 Processing job 来使用 SkLearn 或者 SparkML 来进行数据预处理或者特征工程是你的首选。
- SageMaker 的内建算法对数据输入格式的要求以及可配置的有限的超参数。SageMaker 提供的内建算法(SageMaker 对常见的 ML 任务基本都提供了一种或者多种算法)对数据输入格式的要求以及提供的超参数可能与开源界的算法的数据输入格式和提供的超参数略有区别。这里你需要权衡易用性与灵活性:如果你只是想实现一个 ML 的任务并且不想关注算法的实现细节,那么可以优先尝试 SageMaker 的内建算法;如果你想更深入了解算法的实现细节以及更灵活的超参数设置,那么建议的选择是把你的算法或者开源的算法迁移到 SageMaker 中。
- SageMaker 训练时的 HPO 自动超参数优化功能的使用。自动超参数优化的初衷是为了减轻算法工程师/数据科学家/应用科学家们手工调参的痛苦。SageMaker 的 HPO 自动超参数优化对于内建算法和非内建算法都支持,并提供了贝叶斯搜索和随机搜索两种方式供你选择。不是所有的算法都需要走自动超参数调优,需要权衡模型性能(就是指模型效果)与成本。一般来说,对于深度学习模型或者海量数据集的情况下可能做自动超参数调优的时间代价和成本代价太大。因此在实际的 ML 项目中,用户很少对深度学习模型或者海量数据集做自动超参数调优;对于传统的机器学习模型并且在数据集不大的情况下,可以考虑用自动超参数调优来找到可能的最优解。
- SageMaker 内建的 inference pipeline 的数据流。SageMaker Inference pipeline 可以把多个容器(容器中可以跑特征处理逻辑或者跑模型 serving 逻辑)串接起来,它的目的是把推理时的特征处理模块和模型串接起来,或者把多个模型做成上下游串接起来。它的数据流是这样的:
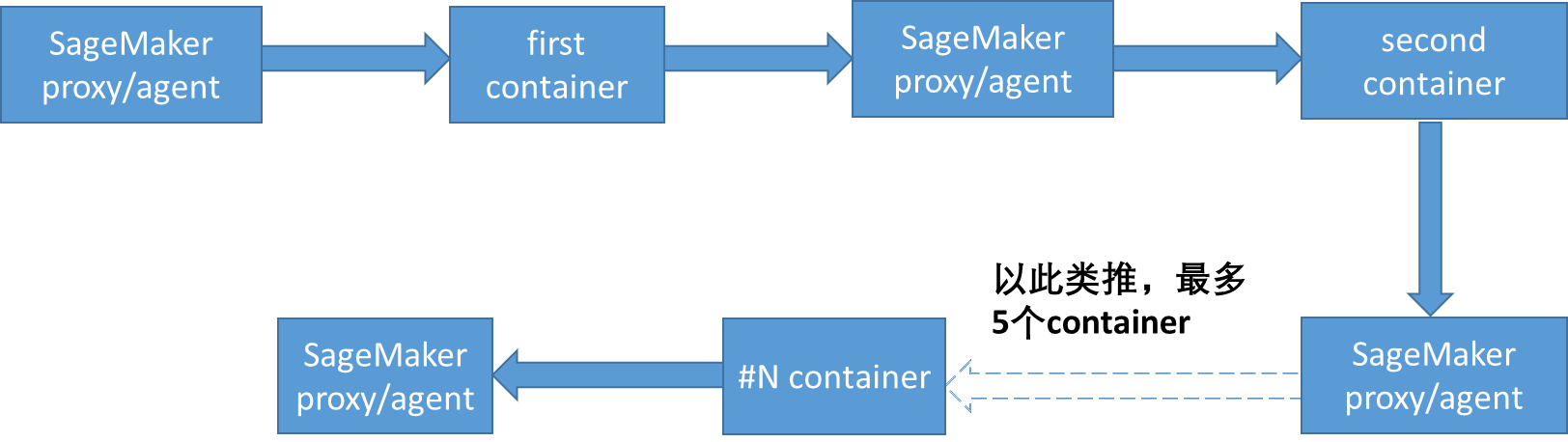
也就是说,每个容器的输出由 SageMaker 内部组件做中转,该组件把上一个容器的输出做为新的 request 发送到下一个容器。通过使用 Inference pipeline 这个功能可以简单方便的实现模型的上下游串接或者特征处理模块和模型的串接,但从上面的数据流可以看到会带入一些延迟,这个时候你需要考虑延迟是否在可以接受的范围内并使用 Inference pipeline,也就是需要权衡易用性与时间性能。
- SageMaker 中对于 Tensorflow 和 Pytorch 两种框架都提供了多种训练方式。训练方式包括开源框架原生的方式以及 SageMaker 专门实现的针对这两种框架的数据并行和模型并行两种方式。SageMaker 的数据并行训练方式适合每个 GPU 卡可以跑完整的模型训练但是数据集是海量的情况;SageMaker 的模型并行训练方式适合单个 GPU 卡无法直接跑模型训练的情况(比如模型太大了)。也就是说,在海量数据集大规模训练或者超大模型训练的场景,使用 SageMaker 的这两种专有的训练方式比框架原生的训练方式会更高效,但是使用 SageMaker 的数据并行和模型并行的训练方式的话,对于框架的版本有要求并且需要一定的代码修改,因此需要你权衡代码的可移植性与时间性能。
简单之美——大道至简
“简单”可能的含义有很多,比如精简,简朴,可读性好等。“简单”的度量标准可能每个人的理解都不一样,但是一个通用的原则是,“您”在设计软件的时候尽量多想着:“软件需要别人来用,还需要别人来迭代和维护”,您一定要高抬贵手。“简单”的对立面就是“复杂”,业界的共识是通过降低复杂度来得到高质量长生命期的软件,而如何降低复杂度是每个软件设计人员以及开发人员无时无刻需要关注的事情。
在 SageMaker 中的体现:
- SageMaker 是基于 container 的设计,到目前为止没有选择 Kubernetes。在当前业界大兴 Kubernetes 的情况下,SageMaker 并没有随大流。Kubernetes 的功能很强大但是很复杂,对于 SageMaker 来说,很多 Kubernetes 的功能用不上,那么为了减少软件依赖以及降低复杂度,SageMaker 选择了更轻量的设计(杀鸡真的没有必要用牛刀)。
- SageMaker high level API(high level API 指的是SageMaker Python SDK,这个 API 的使用习惯类似常见的 ML 框架比如SKLearn)设计很简洁,类层次也很清晰(分层就是一种降低复杂度的方法),很多 feature 通过简单的参数设置就能搞定。比如通过简单的设置distribution 参数就把底层复杂的分布式环境部署隐藏掉了(信息隐藏也是降低复杂度的一种方法),让 API 调用者的关注点更集中在训练脚本本身;比如简单的设置模型的 S3 保存位置,SageMaker 就会帮助你在训练结束或者训练中断时把对应目录下的模型压缩打包并上传到 S3 指定路径;比如通过设置 git_config 参数,你就可以直接用 github 中的代码在 SageMake 中来训练,而不需要你关心代码的拉取过程。
- SageMaker 提供了多种算法选择:内建算法,BYOS(基于预置的机器学习框架来自定义算法),BYOC(自定义算法设计并自己来打包容器镜像)和第三方应用市场(在 Amazon Marketplace 中挑选第三方算法包,直接在 Amazon SageMaker 中使用)。而 BYOS 和 BYOC 是 SageMaker 中实际用的最多的两种选择。那如何选择 BYOS 和 BYOC?总的来说,优先看 BYOS 是否能满足需求。BYOS 相对于 BYOC 要容易,需要迁移到 SageMaker 的工作量也少。而选择 BYOC,常见的是如下的情景:

除了上面这些情景,尽量优先考虑 BYOS 的方式,它使用方式简单,学习曲线也相对平缓。
- SageMaker 提供了两个可用于超参数的变量 sagemaker_program 和 sagemaker_submit_directory 来帮助你轻松的完成 BYOC 的调试。前者告知 SageMaker 把这个参数的值作为 user entry point(就是用户提供的需要 SageMaker 调用的脚本),后者则是这个 entry_point 对应的代码以及它所依赖的代码打包(tar.gz)后的 S3 路径。通过设置这两个参数,在调试代码的时候只是需要把修改后的代码重新打包上传就可以,而不是每次都 build docker file,简单方便而且很节省时间。
没有规矩不成方圆——循规蹈矩
拥有丰富经验的你可能听过或者践行过契约式编程,而契约式编程简单说就是,你需要按照对方的一些约定来 coding。一般来说,只要是提供给别人使用的软件/工具,或多或少都会有一些约定。SageMaker 从尽量减少代码侵入性和最小代码迁移工作量的思路出发,提供了很多约定。
在 SageMaker 中的体现:
训练时,数据 Channel 相关的约定:

- 训练容器本地路径相关的约定,如下图所示:

我们重点关注下表中的四种路径(除了下面这些路径,训练过程中放置在其他路径下的文件,在训练结束后都会被丢弃):

SageMaker 给容器提供了很多方便使用的环境变量,包括 SageMaker 相关的和内建框架相关的。比如 SageMaker 相关的一部分环境变量如下:
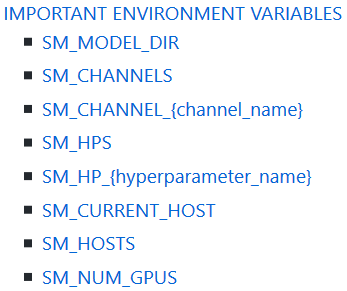
SageMaker 内建的 TF serving 框架的 service side batch 相关的环境变量如下:
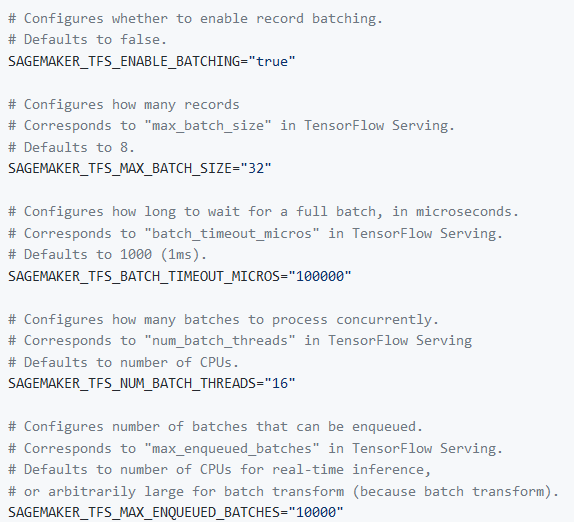
- SageMaker 内建算法对输入数据格式的要求。SageMaker 内建算法对输入数据的格式要求可能和开源算法对数据格式的要求不同,如果不注意这个,在调试模型的时候可能会出现比较奇怪的结果。比如 SageMaker 目标检测算法对 BBOX 的格式要求如下:对于 json 格式的输入标注文件, 要求的坐标格式是 [top, left, width, height],如果你的数据集的标注是PASCAL VOC 格式的(xmin,ymin,xmax,ymax)或者是 COCO 格式的(x,y,width,height),都需要做不同的转换;对于 recordIO 格式的输入文件, 要求坐标格式是相对坐标,[xmin/width,ymin/height,xmax/width,ymax/height]。
- Spot 实例与 SageMaker checkpoint 机制的配合。为了节省成本,使用 spot 实例进行训练是首选。为了让 spot 实例被回收对你的训练任务造成的影响最小化,SageMaker 通过两个参数 checkpoint_local_path 和checkpoint_s3_uri 来助你一臂之力(当然你不使用 spot 实例,也仍然可以利用 SageMaker 的 checkpoint 机制)。这样训练 job 被 spot 回收中断以后并自动重新开始训练后,就不用从头开始训练了,而是从最新的 checkpoint 开始接着训练(SageMaker 提供了 checkpoint 上传和下载的机制,你需要修改你的代码来配合,也就是你需要从约定的 checkpoint local 路径来初始化你的模型参数,否则是空谈),从而在节省成本的同时节省训练时间。
没有“银弹”——对症下药
可能我们自己脑海中或者遇到过别人问我们如下的问题:对于XX任务当前哪个模型效果最好?使用 AutoML 是不是就不需要我们做特征工程和样本工程了?自动超参调优是不是就彻底解放我们的手动超参调优了?如果真的是这样的话,那就太美好了。在软件界,“没有银弹”这句话流行很久了,对于人工智能领域也是同样道理,都需要 case by case 来分析每一个目标任务。
现在 Bert 以及 bert-like 的模型比如 GPT3,T5 等很火,恨不得只要是 NLP 的任务都用这样的模型。我觉得还是应该至少要考虑具体的目标任务是什么,目标任务的建模难度这两个因素来进行模型选型。如果在语料充足的情况下,做一个简单的文本分类任务,这个时候可能用一个简单的模型比如 fasttext 来就够用了,而不用 bert 模型做 fine tuning 这么复杂;如果是针对用户评论做细粒度情感分析任务,这个任务就很复杂了,用简单模型就可能不合适了,这个时候用比如 T5 这样的复杂模型才合适。盲目的追新和追热点,受伤的是你的项目(可能你能从中受益)。
对于 SageMaker 来说:
- SageMaker 有内建算法,BYOS,BYOC 和 Marketplace 以及新出的 JumpStart 上面的算法可供你选择,总有一款适合你。很有意思的一个现象是,SageMaker 在刚发布的时候 bulid 了17种内建算法,很多年过后一直也没有在增加新的内建算法。我猜测 SageMaker 的开发团队会认为,即使不断的增加一些内建算法,也没有办法及时对主流的一些算法进行跟进。正是因为针对任何一种细分场景,没有包治百病的“算法”,SageMaker 就不在内建算法上花费更多的时间和精力,它提供更灵活的 BYOS 和 BYOC 让用户把开源的算法方便的迁移过来,或者通过 Marketplace 让买家和卖家都能尝到使用算法的甜头。
- SageMaker 提供了 Autopilot 和 Auto model tuning(即自动超参数调优)这样两种 AutoML 机制。AutoML 一直是一个很热门的研究方向,也是我们人类很期待的一个能大量落地的方向(谁不喜欢简单省事就能完成一项任务呢?)。如果每个目标任务都可以用 AutoML 来解决的很好,那么大部分人都可以腾出时间来攻克别的技术难题了。虽然 Autopilot 可以直接对结构化数据来建模,它也能自动做一些特征处理,但是它并不是银弹,不是什么数据集直接丢给它就能出一个不错的效果的;要使用 Autopilot,自己提前做一些特征工程可能效果会更好(比如特征缩放,特征生成,特征交叉,甚至不同的缺失值处理方法,异常值处理等)。
而对于自动超参数调优,如果使用默认的超参数搜索空间,时间成本和金钱成本太大,那么还是需要人工首先限定每个需要搜索的超参数的区间的左右端点,同样这里没有“银弹”,左右端点的确定要么根据已有的经验,要么就是通过实验来大致选取。一定不要无条件的使用 Autopilot 或者自动超参数调优来解决你的问题,三思而后行!
变化之本——进化本质
为什么要考虑“变化”?设计之初就应该考虑到将来的可能变化,也就是说系统框架要设计的比较有弹性(就像亚马逊云科技的很多服务那样弹),对于将来的需求的改动不会付出很高代价。在软件设计中,经常会谈到“面向变化编程”,即永远不要假设需求不变,现实中需求大大小小经常变。变化是创新的必经之路,永恒不变的东西只有变化。
在 SageMaker 中的体现:
- SageMaker 早期的版本提供了 SageMaker-container 包供你使用来创建 SageMaker 兼容的容器和自定义的框架。后期的版本,为了让基于 SageMaker-container 包的容器镜像尽量更小更内聚,SageMaker 把这个 SageMaker-container 包拆分为 sagemaker-training toolkit(专为训练的容器)和 sagemaker inference toolkit(专为推理 /serving 的容器)两个包来瘦身。
- 随着不断的进化,SageMaker 现在是一个完全自洽的全生命周期的机器学习平台。在早期的时候,SageMaker 只有三大核心功能:训练,推理(离线推理和线上推理),notebook 实例。为了能把ML生命周期中的数据预处理,特征工程,模型评估这些功能也纳入,SageMaker 后续推出了 Processing job 来做这些事情。而随着很多用户对于多种机器学习任务的高质量标注需求的上升,SageMaker 推出了带有人工标注和机器自动标注的 Ground Truth 功能(这里又体现了客户至上的企业文化)。而随着 SageMaker Studio(它是用于机器学习的集成式开发环境 IDE,可让你构建、训练、调试、部署和监控机器学习模型)的推出,以及 MLOps 的更多功能的加入,现在的 SageMaker 变成了“超人”(短时间能增加如此多的功能并且还保持健壮,正是因为 SageMaker 的设计基因就是面向变化的)。
知其所以然——做到心中有数
我们可能知其然,但是所以然知道了吗?可能有些感兴趣的东西我们会去了解其深层的原因,但是软件的问题我们去研究了吗?软件是枯燥的,很多时候我们都是作为谋生的手段来应付之,因此不知所以然也就很正常了。但是如果您是要真正的学习东西,或者更好的服务于用户,最好还是”再深一点“。
对于 SageMaker 来说:
- SageMaker 相关的代码比较分散,为了满足好奇心可以去阅读源码。比如有 SageMaker 平台相关的开源代码包 sagemaker-container,sagemaker-training,sagemaker-inference;与内建框架相关的开源的代码比如 SageMaker tensorflow training,SageMaker tensorflow serving;SageMaker Python SDK 的开源实现代码。通过阅读这些代码,你会对 SageMaker 如何工作有更深刻的理解。
- 当训练文件的数量比较多的时候,SageMaker Pipe mode 和 File mode 哪种方式训练 更快呢?拿Tensorflow 的 tfrecorddataset API 来举例,在其他的 dataset API 基本一样的前提下,File mode 更快(这个在多个实际用户项目中测试过)。主要的区别就是 pipemodedataset API 和 tfrecorddataset API。tfrecorddataset API 可以设置 num_parallel_reads 来并行读取多个文件的数据,还可以设置 buffer_size 来优化数据读取。 Pipemodedataset API 则没有类似上面的参数来加速数据的读取。也就是说 Pipe mode 更适合读取文件数量不多,但是每个文件都很大的场景(除了这里提到的 Pipe mode 和 File mode,SageMaker 训练的数据读取方式还提供了 FastFile mode;SageMaker 训练支持的数据源除了 S3,还包括 Amazon Elastic File System 以及 Amazon FSX for Lustre,详细内容可以参考官方博客)。
- SageMaker Endpoint for TFS vs for Mxnet/Pytorch 的内建serving 框架复杂性对比。SageMaker Endpoint for TFS 的介绍如下:

SageMaker Endpoint for Pytorch serving 的介绍如下(SageMaker Endpoint for Mxnet serving 是类似的):只使用一个组件 torchserve,它的特点是,直接支持钩子函数;支持处理 /ping REST API;缺省会使用所有的GPU来做推理(而单个 TFS 进程只使用一个 GPU 来推理)。
保持一致性——质量可控
一致性是降低系统复杂度有利的手段。如果一个系统保持一致,意味着类似的事情用类似的方法去做,降低了认知负荷。在ML机器学习领域,我们经常会谈到一致性,比如效果线上线下一致性(如果模型离线效果好,模型上线以后表现不好,这就是发生了效果线上线下不一致),特征的线上线下一致性(特征的线上线下不一致是效果线上线下不一致的一个常见原因;特征的线上线下不一致指的是线下训练时样本中的特征的特征值可能会发生变化,并不和该样本在线上生成时的特征值完全一样。关于特征的线上线下一致性更详细的讨论请参考我的另一个文章)。保持一致性是模型质量可控的一个重要因素。
对于 SageMaker 来说:
- 使用 SageMaker Processing job 对训练集做的一些特征工程比如某个特征 Z-score 标准化,那么为了让预测时与训练时有一致的特征工程,需要如何处理呢?在对训练集做了某个特征的 Z-score 标准化以后,用到的该特征的均值和方差这些 metadata 需要保存起来(SparkML 和 Sklearn 都有相应的 API 把这些 metadata 以文件的形式保存起来);然后利用 SageMaker Inference pipeline 在第一个容器中把之前保存的 metadata 文件加载进来对原始特征进行 Z-score 标准化处理之后再送入第二个容器即模型推理容器。
- 如果在模型 serving 的时候,能及时知道每个特征的分布是否和训练时的数据集尤其是验证集的分布是否基本一致,对于模型才更可控。而 SageMaker 的 model monitor 的一个重要功能就是监控特征的统计漂移,如果模型在生产过程中接收到的数据的统计性质偏离了训练所依据的基准数据的性质,则模型将开始失去其预测的准确性。Model Monitor 使用规则检测数据漂移,并配合 Amazon 其他服务在发生数据漂移时向您发出警报。下图说明了此流程的工作方式:
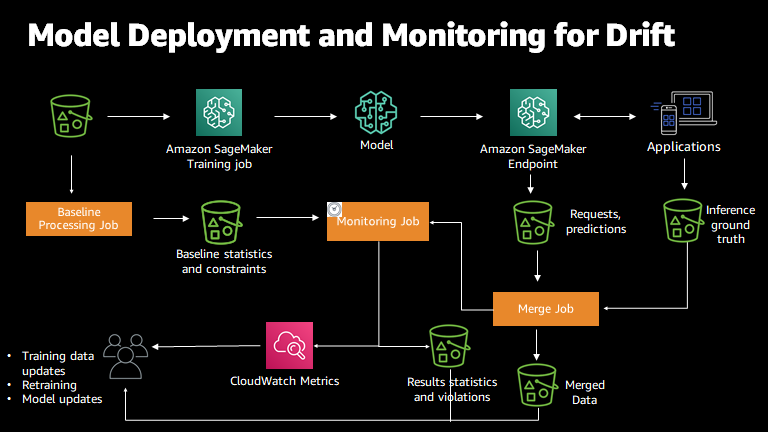
总结
本文从软件哲学角度来介绍了 SageMaker 的一些设计思想以及如何使用 SageMaker 的一些功能。总体来讲,不管你是否考虑采用 SageMaker 作为你的机器学习平台,至少它的这些实现的思路以及设计哲学都是可以用来参考的。SageMaker 作为全球使用量最大的机器学习平台,是值得你花时间来好好研究和探索以及实践的。关于 SageMaker 更多详细和更多深入的内容请参考我的 github。感谢大家的耐心阅读。
本篇作者

梁宇辉
亚马逊云科技机器学习产品技术专家,负责基于亚马逊云科技的机器学习方案的咨询与设计,专注于机器学习的推广与应用,深度参与了很多真实客户的机器学习项目的构建以及优化。对于深度学习模型分布式训练,推荐系统和计算广告等领域具有丰富经验。
文章来源:https://dev.amazoncloud.cn/column/article/63098fa80c9a20404da79138?sc_medium=regulartraffic&sc_campaign=crossplatform&sc_channel=CSDN