ClickHouse 在近几年是大数据分析引擎界的一匹黑马,从默默无闻到一路起飞,在 DB engine Rank 上进入前50名,成为全球数据引擎界耀眼的一颗明星。在全球范围内,ClickHouse 单表查询比其他引擎要快数倍以上,在过去的几年以来未曾有对手。ClickHouse 为什么会这么快?在实际使用当中如何应用这样一个引擎?本文根据MobTech袤博科技Java开发专家墨子的演讲分享整理而成,为大家详尽介绍最新的 ClickHouse Feature 和实战应用。
一、初探OLAP和ClickHouse
在数据科学领域,数据库系统可以分为联机事务处理(OLTP)和联机分析处理(OLAP)两种面向不同领域的数据库,OLAP数据库也被称为数据仓库。在探究ClickHouse之前,我们先了解OLAP和OLTP有何不同。OLAP是数据仓库系统的主要应用,其支持的对象主要是面向分析场景的应用,提供结构化的、主题化的数据给运营,实现业务反馈和辅助决策。同时,在有些场景中,也可以由数据仓库对业务进行支持。OLTP存储的主要是与业务直接相关的数据,强调准确、低时延、高并发,如果没有特别强调,基本上数据库里只会存储与业务相关的数据。
从产品上看,有专门面向OLTP的数据库,例如MySQL、PostgreSQL、Oracle等,也有专门面向OLAP的数据库,例如Presto、Druid、Apache Kylin、Apache Doris、ClickHouse等,本期侧重介绍不同的OLAP系统在应用场景中的表现。
OLAP场景中,已添加到数据库的数据不能修改,绝大多数是读请求。对于读取,从数据库中提取相当多的行,但只提取列的一小部分。数据以相当大的批次(> 1000行)更新,而不是单行更新,或者根本没有更新。宽表,即每个表包含着大量的列,查询相对较少(通常每台服务器每秒查询数百次或更少),对于简单查询,允许延迟大约50毫秒。通常,列中的数据相对较小,一般是数字和短字符串(例如,每个URL 60个字节),处理单个查询时需要高吞吐量(每台服务器每秒可达数十亿行)。事务不是必须的,对数据一致性要求低。每个查询有一个大表,除了它以外,其他的都很小。查询结果明显小于源数据。换句话说,数据经过过滤或聚合,因此结果适合于单个服务器的RAM中。
以下是现行的几款OLAP系统对比:
- Presto
是在Hadoop 上运行的分布式系统,使用与经典大规模并行处理(MPP) 数据库管理系统相似的架构。 它有一个协调器节点,与多个工作线程节点同步工作。 用户将其SQL 查询提交给协调器,由其使用自定义查询和执行引擎进行解析、计划并将分布式查询计划安排到工作线程节点之间。
评估:Presto优点是基于hadoop生态,存储和计算分离,基于Java开发。缺点是依赖大内存,查询速度比较慢。
- Druid
Druid专为需要快速数据查询与摄入的工作流程而设计,在即时数据可见性、即席查询、运营分析以及高并发等方面表现非常出色。 在实际中众多场景下数据仓库解决方案中,可以考虑将Druid当做一种开源的替代解决方案。
评估:Druid的数据维度预聚合,没有明细数据。
- Apache Kylin
Apache Kylin™是一个开源的、分布式的分析型数据仓库,提供Hadoop/Spark 之上的SQL 查询接口及多维分析(OLAP)能力以支持超大规模数据,最初由eBay 开发并贡献至开源社区。 它能在亚秒内查询巨大的表。 Apache Kylin™ 令使用者仅需三步,即可实现超大数据集上的亚秒级查询。
评估:Kylin优点是查询速度特别快,缺点是基于数据预计算,数据膨胀比较大,无明细数据。
- Apache Doris
Apache Doris是一个现代化的MPP分析型数据库产品。仅需亚秒级响应时间即可获得查询结果,有效地支持实时数据分析。Apache Doris的分布式架构非常简洁,易于运维,并且可以支持10PB以上的超大数据集。Apache Doris可以满足多种数据分析需求,例如固定历史报表,实时数据分析,交互式数据分析和探索式数据分析等,令您的数据分析工作更加简单高效。
- ClickHouse
ClickHouse 是俄罗斯的 Yandex 于 2016 年开源的列式存储数据库(DBMS),使用 C++语言编写,主要用于在线分析处理查询(OLAP) ,能够使用 SQL 查询实时生成分析数据报告。ClickHouse可以做用户行为分析,流批一体,线性扩展和可靠性保障能够原生支持 shard + replication,ClickHouse没有走hadoop生态,采用 Local attached storage 作为存储。
评估:Clickhouse优点是采用列式存储,支持SQL,丰富的表引擎,有索引优化策略,基于cpu向量执行引擎查询速度特别快。缺点是计算和存储在一起,无法大规模搭建集群。
二、ClickHouse现状和核心能力
ClickHouse完美的实现了OLAP和列式数据库的优势,因此在大数据量的分析处理应用中ClickHouse表现很优秀。ClickHouse版本迭代迅速,几乎每个月都有新版本发布,支持表引擎非常多,可达40多种。单机查询性能非常强悍,使用普通机械硬盘,每秒可扫描1亿行记录,数据压缩率比较高。
ClickHouse中最强大的表引擎是MergeTree系列。MergeTree 系列的引擎被设计用于插入极大量的数据到一张表当中。数据可以以数据片段的形式一个接着一个的快速写入,数据片段在后台按照一定的规则进行合并。相比在插入时不断修改(重写)已存储的数据,这种策略会高效很多。
MergeTree系列主要特点:
存储的数据按主键排序;
支持数据分区;
支持数据副本;
支持数据采样;
支持轻量级更新和删除操作;
支持表和列TTL。
- 支持数据修改和删除的MergeTree引擎:
VersionedCollapsingMergeTree
CollapsingMergeTree
ReplacingMergeTree
- 支持数据聚合的MergeTree引擎:
AggregatingMergeTree
SummingMergeTree
- 分布式表
在ClickHouse中,分布式表是由多个分片组成的逻辑表,分片可以存储在不同的物理节点上。每个分片都包含表的一部分数据,并且可以独立读取和写入数据。这种分片存储的方式有助于实现高扩展性和高可用性,因为当需要增加存储容量或提高性能时,可以通过添加更多的节点来实现。
要创建一个分布式表,首先需要定义该表的模式(即列的名称和类型),然后指定每个分片的位置和复制策略。对于每个分片,可以指定其副本数目和副本放置的位置。
当向分布式表中插入数据时,ClickHouse会根据每个分片配置的比重,把数据插入对应的分片种。查询也可以跨多个分片执行,以便并行化处理大量数据。
总的来说,ClickHouse的分布式表使得数据处理变得非常高效和可扩展,能够应对大规模的数据集合和高并发访问的需求。
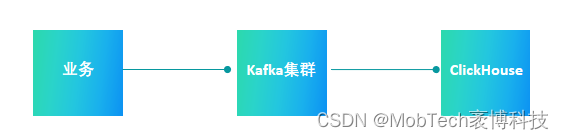
- 集成表:Kafka集成
通过kafka集成方式可以实现数据实时入库。Kafka集成表不存储数据,是一个数据管道。
步骤:
1,创建Kafka集成表。
2,创建业务表。
3,创建物化视图将两张表关联起来。
- 集成表:Hive集成
通过与Hive集成,可以通过Clickhouse对hive数据进行读写。其本质是通过hive获取Hadoop文件地址进行读写。在该集成模式,Clickhouse扮演计算引擎角色,hive扮演数据存储角色。主要用于离线数据查询。

- 数据副本的两种方式:ReplicatedMergeTree和Shard配置
ReplicatedMergeTree,基于表级别的数据复制,利用zookeeper实现副本间发现和通讯。但是zookeeper不涉及数据查询和传输。所有的MergeTree表前加Replicated即可实现副本功能,每个副本表都有全量数据。
Shard,每个ClickHouse节点都是一个分片,可以进行横向扩展。可以配置每个Shard多个副本,基于数据库实例级别的副本。
三、ClickHouse索引介绍
- 索引
ClickHouse支持主键索引,它将每列数据按照Index granularity进行划分,每个index granularity的开头第一行被称为一个mark行,主键索引存储该mark行对应的primary key值。对于where条件中含有primary key查询,通过对主键索引进行二分查找,能够指定定位到对应的index granularity,避免了全表扫描。
ClickHouse主键索引,并不对数据去重 。数据是按照Order by字段的顺序存储,primary key字段需要是order by字段的一部分。
- 稀疏索引
ClickHouse支持对任意列创建任意数量的稀疏索引。之所以叫稀疏索引,是因为它本质上行是对一个完整index granularity的统计信息,并不会记录具体每一行在文件中的位置。目前支持的稀疏索引类型:
1. minmax。以index granularity为单位,存储指定表达式计算后的min、max值。在等值和范围查询中能够快速跳过不满足要求的块,减少io。
2. set(max_rows)。以index granularity为单位,存储指定表达式的distinct value集合,用于快速判断等值查询是否命中该块。
3. ngrambf_v1。索引对于equals,like和in查询有很大优化。