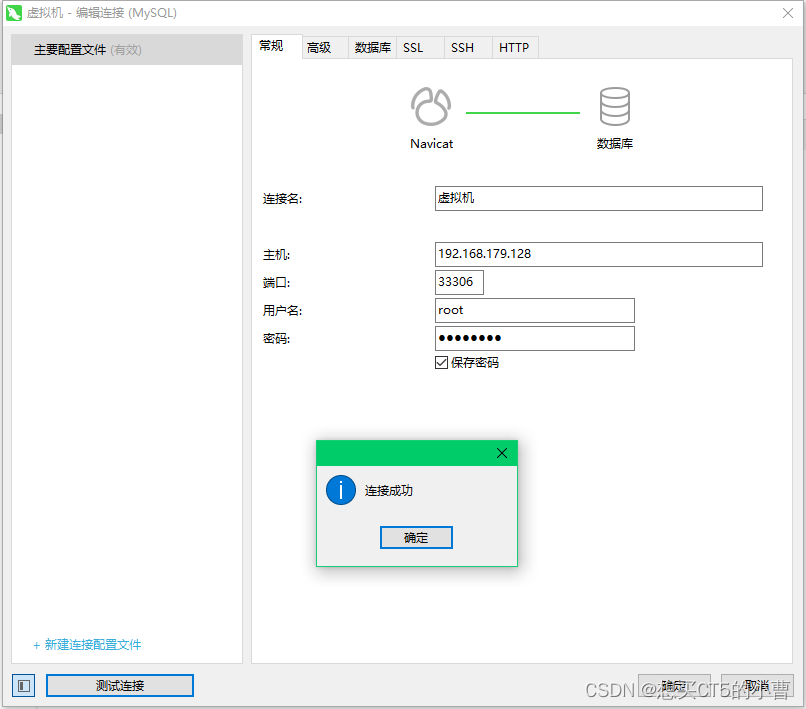
视频链接
[TA 補充課 Graph Neural Network (1/2) (由助教姜成翰同學講授) - YouTube]
[TA 補充課 Graph Neural Network (2/2) (由助教姜成翰同學講授) - YouTube]
[speech.ee.ntu.edu.tw/~tlkagk/courses/ML2020/GNN.pdf]
Introduction
应用:分类、Generation(生成)等
目前研究领域的架构图如下:

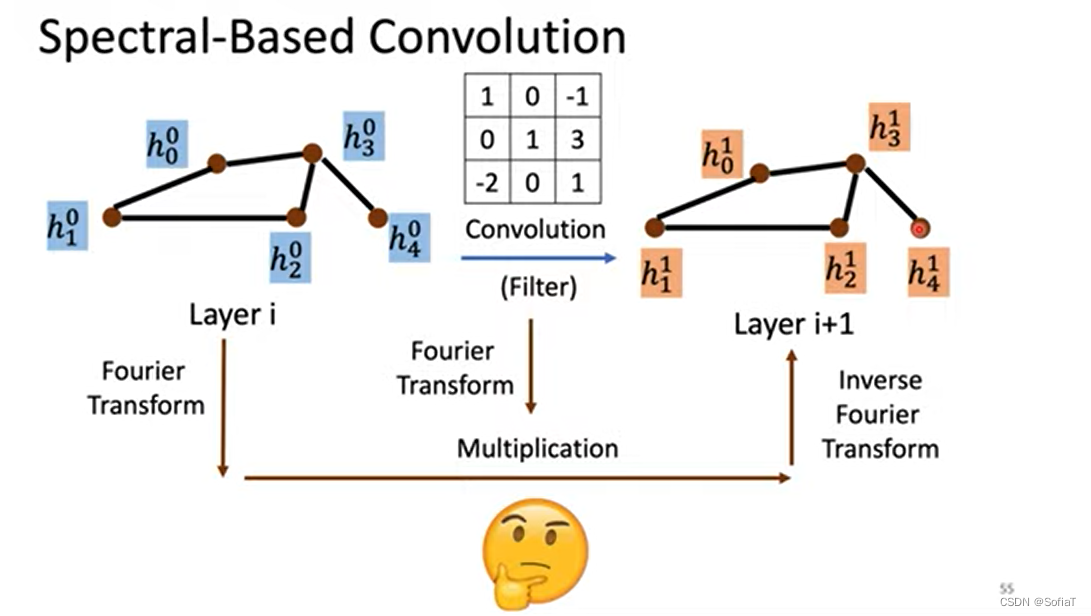
基于空间卷积、基于频率卷积(傅里叶变换)
Dataset & task & Benchmark

Graph Classification:图像转成结点然后分类。MNIST手写识别、CIFAR10物品类别识别
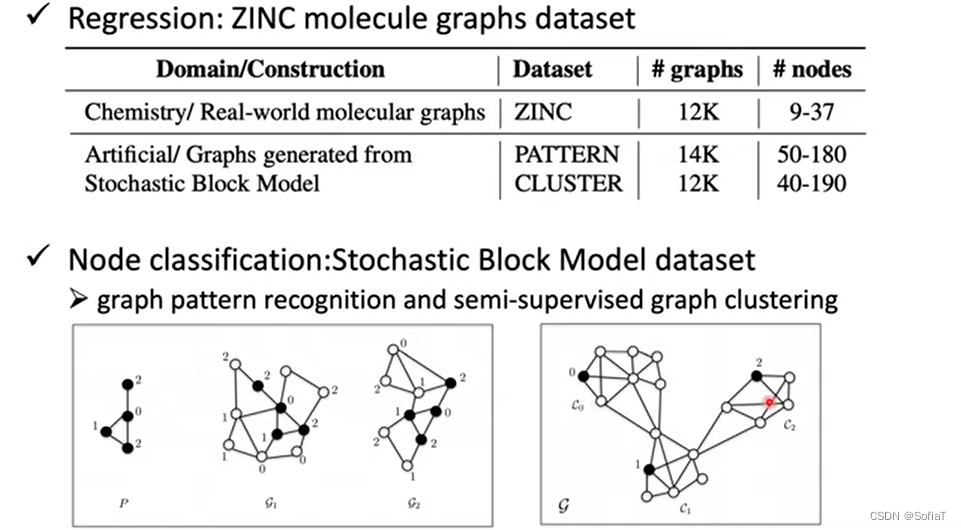
 Regression:ZINC预测化学物质的性质
Regression:ZINC预测化学物质的性质
Node classification:拓扑块位置定位,图聚类
 Edge classification:旅行商问题,遍历每个节点不重复
Edge classification:旅行商问题,遍历每个节点不重复
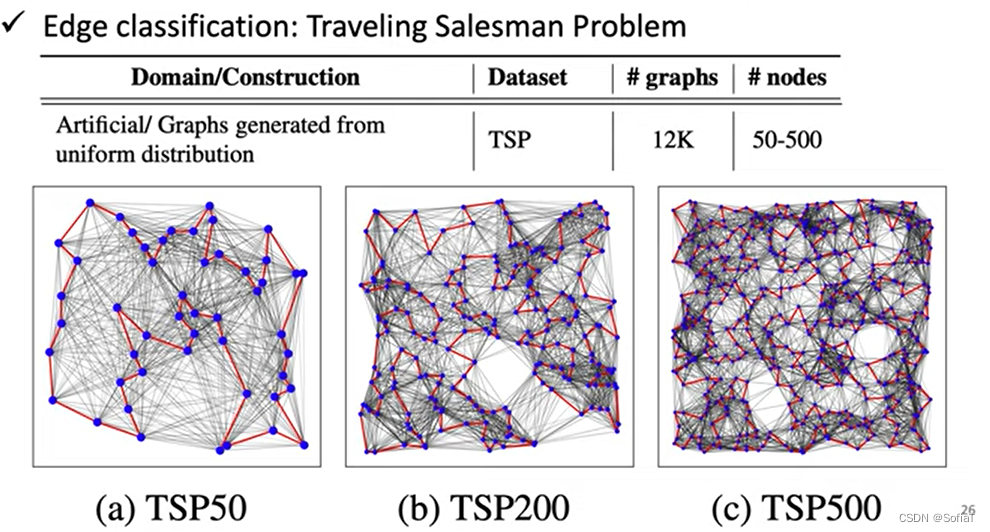
TA的课里面有详细对比不同Task的不同方法表现,总的来说层数不是越深越好(4/8层就够了),GCN表现很烂,有不同注意力参数的那类模型普遍会好。
Special Based GNN
总结方法和术语:
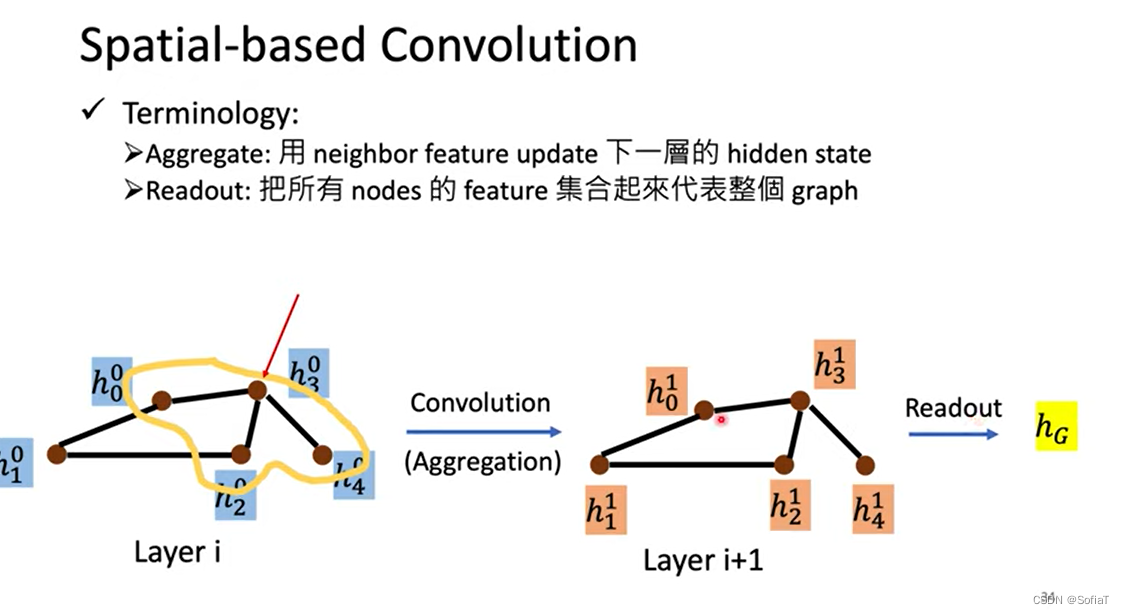 通过卷积结点本身与它邻居的feature聚合得到下一层、读出所有的feature得到整个graph
通过卷积结点本身与它邻居的feature聚合得到下一层、读出所有的feature得到整个graph
NN4G(Neural Networks for Graph)
首先把原始feature通过处理得到纯Embeddings(参数w1)为layer0,然后sum它的邻居节点再做trans(参数w1,0)再加上layer0本身,得到h1为layer1

针对得到的每一层,把所有的feature相加然后去平均,再做一次transform,然后相加,得到一个feature代表整个图
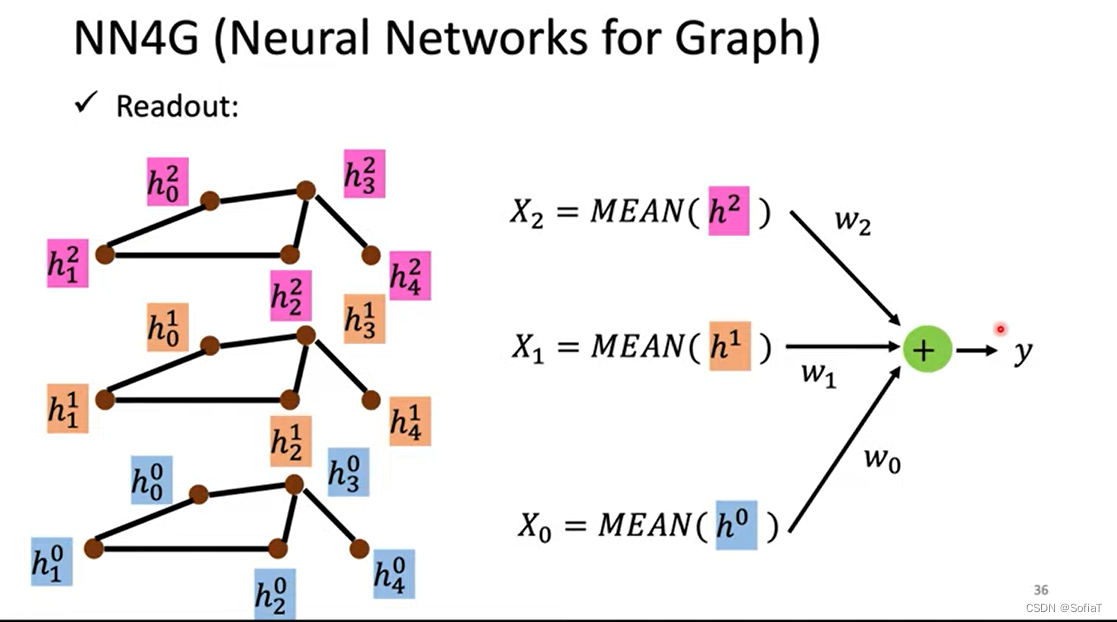
为什么是相加?因为不同结点的邻居数目不同,用相加比较好批量化处理。
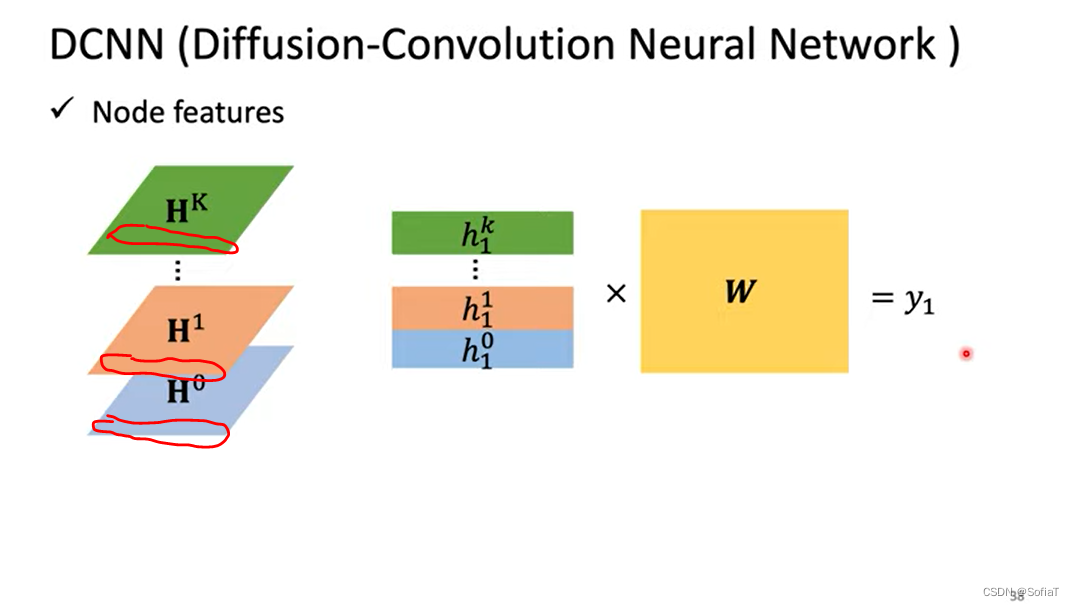
DCNN(Diffusion-Convolution Neural Network)
d(3,·)=1代表距离结点3为1的所有节点,所以layer0找1跳邻居平均值再transform,layer1找2跳邻居(的原始x feature 这样注意力没有掺杂别的信息),这样多层就能把多跳邻居的信息都看到。
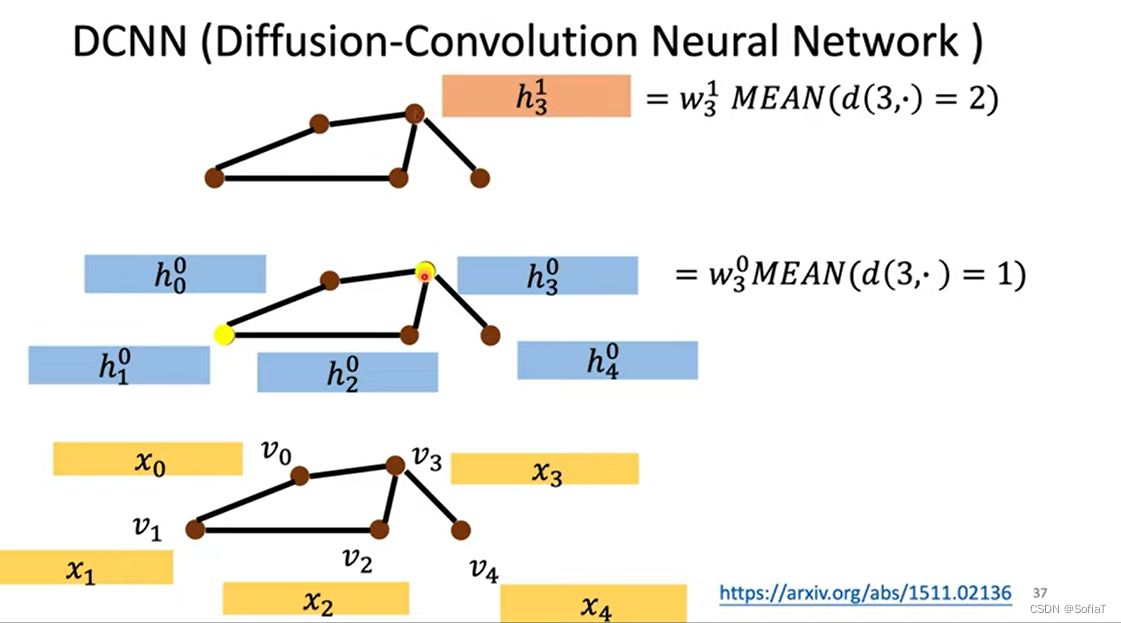
每一行都是一个节点的feature,把他们transform一下就得到最终这个node的feature
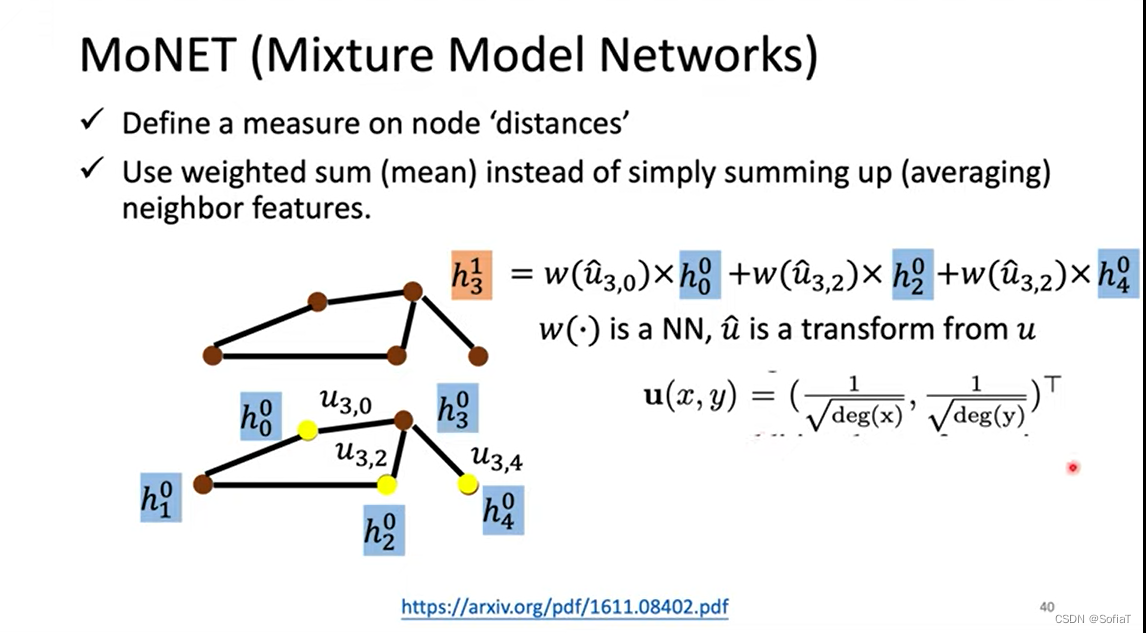
MoNET(Mixture Model Networks)
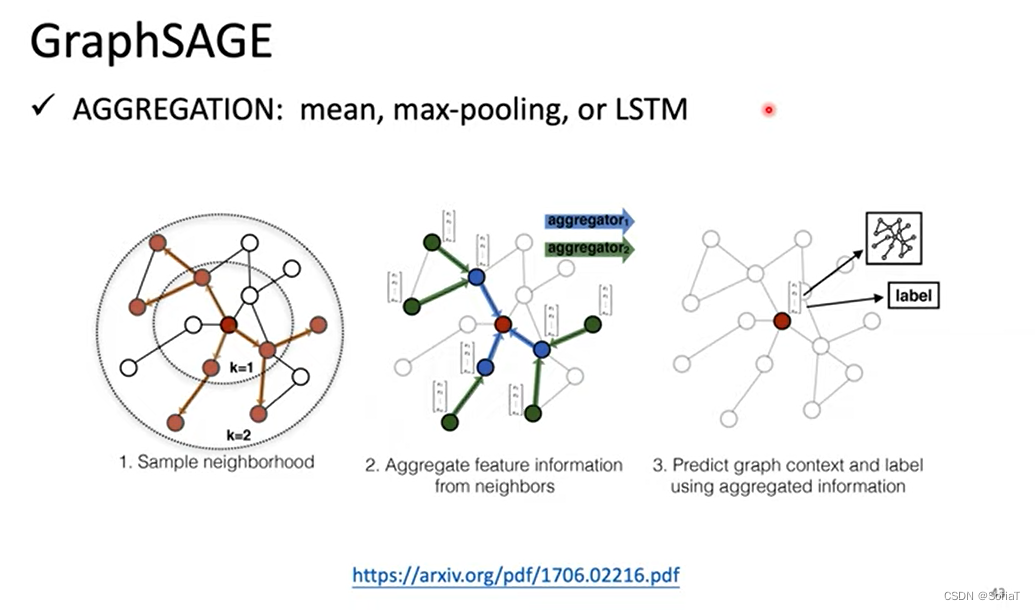
GraphSAGE
用LSTM来处理邻居的feature,这里邻居的顺序是随机的用来平衡LSTM的先后顺序影响
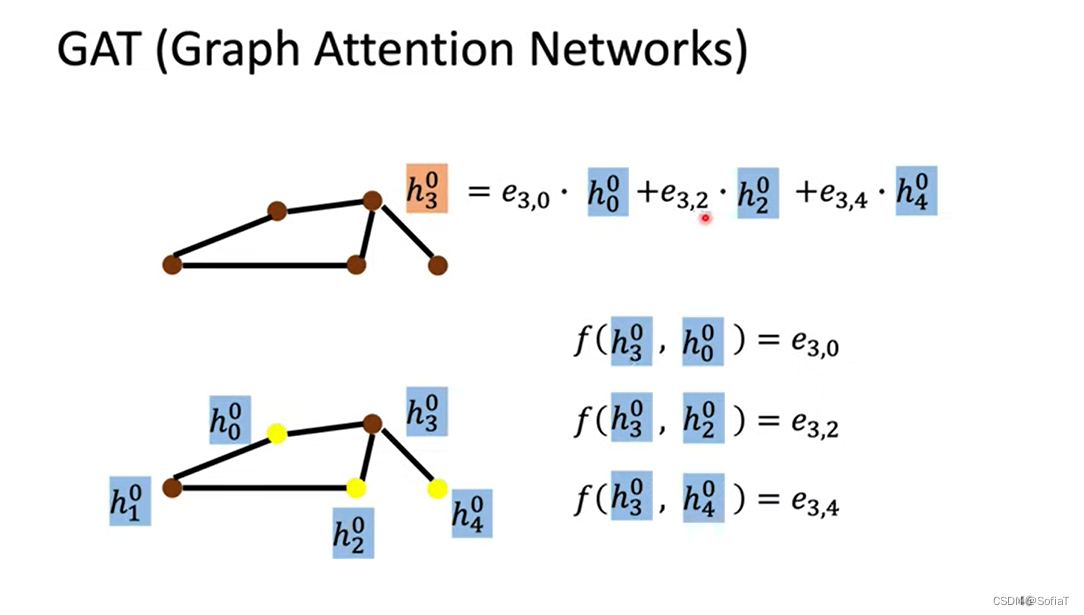
GAT(Graph Attention Neworks)
让机器自己去学每个node邻居的weight,这里的e就是energy,也就是对于节点i,节点j有多重要。

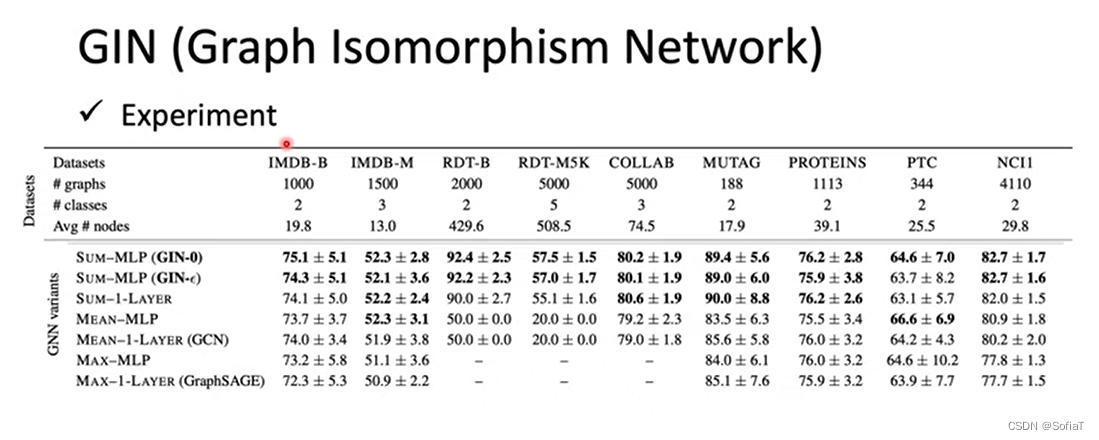
GIN(Graph Isomorphism Network)
先说结论,最好是把邻居节点加起来而不是用mean或者max,epsilon取0就好。
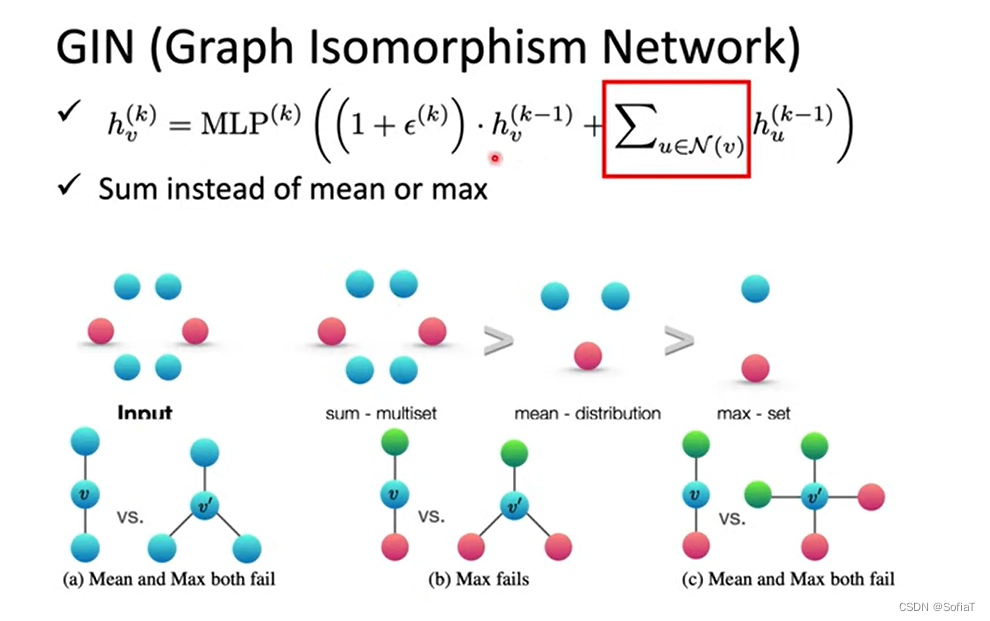
因为可以看到,在不同的单节点结构下,如果用sum是能区分的,但是用mean和max是不能区分的。
频率基础卷积
 一个向量是由基向量线性组合得到的,这里vk是基向量,ak是线性组合。这里假设是orthnormal basis正交基。这里可以看到线性组合可以由点乘计算出来(用二维向量试一下就知道了,其他方向是直接乘上0)
一个向量是由基向量线性组合得到的,这里vk是基向量,ak是线性组合。这里假设是orthnormal basis正交基。这里可以看到线性组合可以由点乘计算出来(用二维向量试一下就知道了,其他方向是直接乘上0)

有一个常用的正交基是傅里叶变化,即sin和cos。
ChebNet