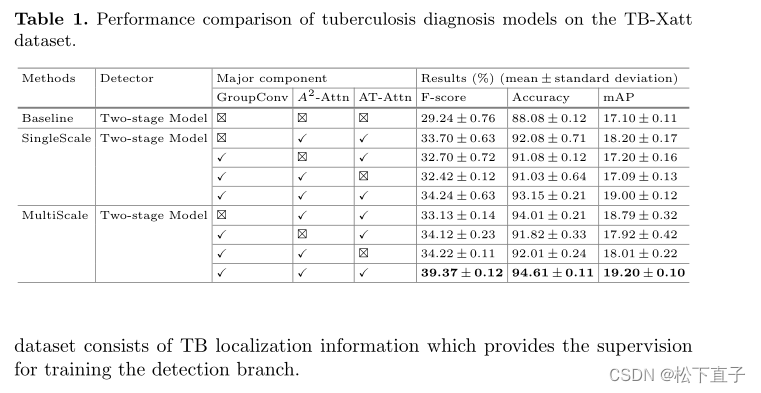
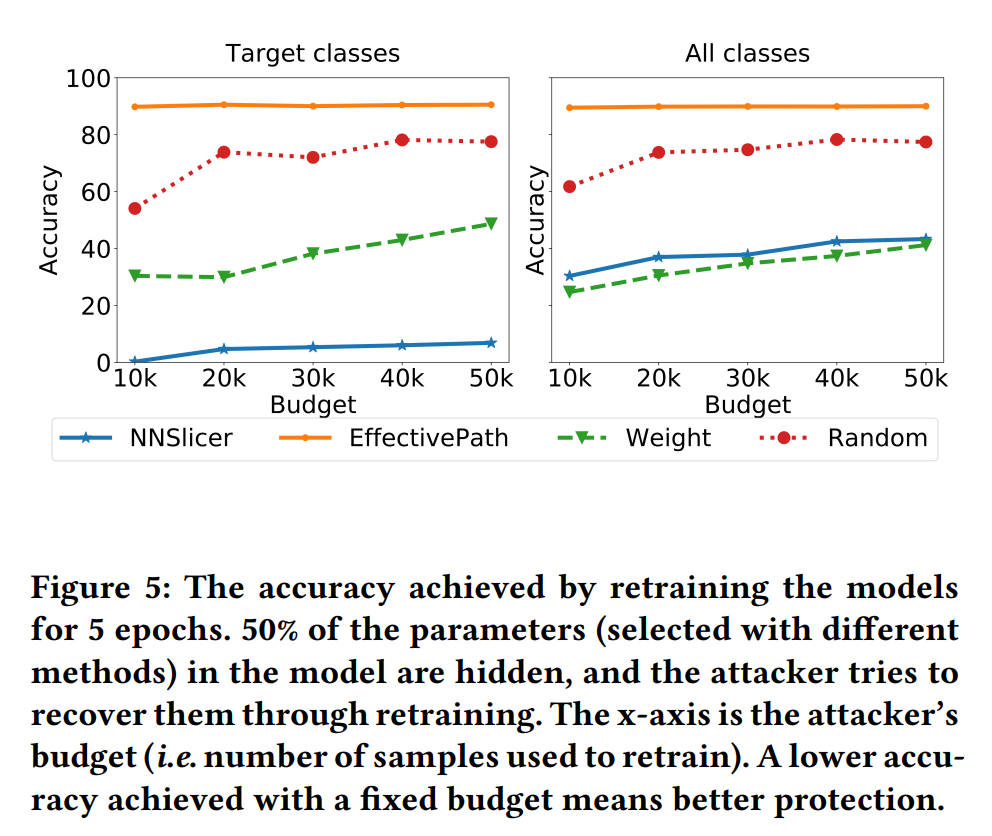
MergeTree的特点
MySQL中最强大的表引擎是InnoDB,ClickHouse中最强大的表引擎是MergeTree以及该系列中的其他引擎。MergeTree 系列的引擎被设计用于插入极大量的数据到一张表当中。数据可以以数据片段的形式一个接着一个的快速写入,数据片段在后台按照一定的规则进行合并。相比在插入时不断修改(重写)已存储的数据,这种策略会高效很多。
MergeTree的主要特点有以下几点:
- 存储的数据按主键排序
- 如果指定了分区键的话,可以使用分区
- 支持数据副本
- 支持数据采样
MergeTree如何存储数据
当数据被写入到MergeTree表中时,会创建多个数据片段并按照主键排序,根据官网的例子,如果主键是(CounterID, Date),数据片段中的数据会首先按照CounterID排序,CounterID相同的数据按照Date排序。
不同分区的数据会被分成不同的片段,ClickHouse 在后台合并数据片段以便更高效存储。不同分区的数据片段不会进行合并。合并机制并不保证具有相同主键的行全都合并到同一个数据片段中。
数据片段的格式有下面两种
- Wide:每一列都会在文件系统中存储为单独的文件
- Compact:所有列都存储在一个文件中,可以提高插入量少插入频率频繁时的性能
min_bytes_for_wide_part 和 min_rows_for_wide_part 控制数据存储格式,如果数据片段中的字节数或行数少于相应的设置值,数据片段会以 Compact 格式存储,否则会以 Wide 格式存储。
每个数据片段在逻辑上会被分成多个颗粒(granules),granules是ClickHouse进行数据查询时的最小不可分割的数据集,也是MergeTree查询如此快的其中一个原因。每个颗粒的第一行通过该行的主键值进行标记, ClickHouse 会为每个数据片段创建一个索引文件来存储这些标记。对于每列,无论它是否包含在主键当中,ClickHouse 都会存储类似标记。这些标记让您可以在列文件中直接找到数据。
颗粒的大小通过表引擎参数 index_granularity 和 index_granularity_bytes 控制。index_granularity 控制每个颗粒的行数,index_granularity_bytes 控制每个颗粒的大小。
通过例子展示数据存储
数据准备
首先建一张表并插入一些数据
CREATE database if not exists ck_test;
create table ck_test.user
(
id UInt32,
name String,
grade UInt32,
l_date Date
)
ENGINE = MergeTree
PARTITION BY toYYYYMM(l_date)
PRIMARY KEY(id)
ORDER BY id
SETTINGS index_granularity=3,
min_rows_for_wide_part = 0,
min_bytes_for_wide_part = 0;
INSERT into ck_test.user values(1,'张三',88,'2023-04-01'),(2,'李四',90,'2023-04-02'),(2,'王五',93,'2023-04-03'),(3,'赵六',80,'2023-04-04'),(4,'孙七',99,'2023-04-05');
INSERT into ck_test.user values(5,'张三',88,'2023-05-01'),(6,'李四',90,'2023-05-02'),(7,'王五',93,'2023-05-03'),(8,'赵六',80,'2023-05-04'),(9,'孙七',99,'2023-05-05');
为了方便演示,增加了index_granularity=2、min_rows_for_wide_part = 0、min_bytes_for_wide_part = 0三个参数。
index_granularity=2表示每两行就会生成一个颗粒文件
min_rows_for_wide_part = 0、min_bytes_for_wide_part = 0 主要为了让数据片段都以 Wide 类型存储,更能理解列式存储。否则少量数据就只会被存储在data.bin这一个文件里。
物理存储
ClickHouse默认的数据存储地址在/var/lib/clickhouse/data

按数据库分成不同的文件夹,进入每个文件夹,每张表又被分成多个文件夹

进入user文件夹内部,可以看到按不同的分区又被分成了不同文件夹

随便进入一个分区,可以看到真正存储数据的结构

*.bin 是列数据文件,如果是Wide格式存储,每一列就会生成一个bin文件,如果是Compact格式,就只会生成一个data.bin文件。
*.mrk2 是mark 文件,目的是快速定位 bin 文件数据位置。
minmax_l_date.idx 是分区键索引文件,主要是为了加速分区字段的查询。
primay.idx 主键索引文件,目的是加速主键查找。
*.txt文件存储了一些记录信息,比如count.txt存储这个分区下的总数,columns.txt存储了列信息。
bin和mrk2
MergeTree 在单个分区内的数据只有一份 *.bin,列名是这份数据文件的名称,bin文件会以排序键进行对齐。
Granule会把bin文件根据设定的 index_granularity 分成多个颗粒,然后通过 *.mrk2 记录颗粒信息。
以id这个字段为例,在建表时设置了 index_granularity=3,所以每三行数据会组成一个颗粒。

MergeTree中的主键索引
MergeTree 的查询速度主要也依赖于索引,MergeTree中的索引分为主键索引和跳数索引。主键索引对应的物理文件是 primary.idx 。
MergeTree 的主键索引采用的是稀疏索引的方式,这种稀疏索引能更快地在海量数据中实现快速检索。MergeTree 的主键索引会选取每个 granule 中的最小值作为主键标识,对应的效果图如下:

主键索引的稀疏度依赖于 index_granularity 的大小,基于稀疏索引,Merge可以快速定位到数据所在的颗粒,并快速定位到数据。
MergeTree 的另外一种索引格式是跳数索引,跳数索引会单独讲解。
使用MergeTree建一张表
了解原理之后,来看看MergeTree下的建表语句,属性中的字段在增删改查部分讲了,这里主要介绍MergeTree相关的参数
CREATE TABLE [IF NOT EXISTS] [db.]table_name [ON CLUSTER cluster]
(
name1 [type1] [DEFAULT|MATERIALIZED|ALIAS expr1] [TTL expr1],
name2 [type2] [DEFAULT|MATERIALIZED|ALIAS expr2] [TTL expr2],
...
INDEX index_name1 expr1 TYPE type1(...) GRANULARITY value1,
INDEX index_name2 expr2 TYPE type2(...) GRANULARITY value2
) ENGINE = MergeTree()
ORDER BY expr
[PARTITION BY expr]
[PRIMARY KEY expr]
[SAMPLE BY expr]
[TTL expr [DELETE|TO DISK 'xxx'|TO VOLUME 'xxx'], ...]
[SETTINGS name=value, ...]
ENGINE = MergeTree() 指定了表所采用的引擎
ORDER BY 是排序键,如果没有使用 PRIMARY KEY 显式指定的主键,ClickHouse 会使用排序键作为主键。
PARTITION BY 是分区键,分区后的数据会被放在不同的文件中,ClickHouse官方文档中说在大多数情况下不需要使用分区键,如果用了分区键也不需要使用比月更细粒度的分区,通过 toYYYYMM(date_column) 实现按月分区。
PRIMARY KEY 指定主键。
SAMPLE BY 用于指定采样表达式,ClickHouse支持近似查询,实现方式就是通过采样,比如计算所有访问的统计信息,只需对所有访问的1/10分数执行查询,然后将结果乘以10即可。采样的实现可以参考官网:
https://clickhouse.com/docs/zh/sql-reference/statements/select/sample
TTL 用于用于设置值的生命周期,可以为整张表设置,也可以给单个表设置,更加详细地关于TTL的认识可以参考下面这个文档:
https://clickhouse.com/docs/zh/engines/table-engines/mergetree-family/mergetree#mergetree-column-ttl
SETTINGS 用于控制MergeTree的额外参数,Settings按需进行调整,没有特殊需求一般不用手动调整:
- index_granularity — 索引颗粒度,默认值8192 ,在上面介绍存储格式时已经用到了。
- index_granularity_bytes — 索引粒度,以字节为单位,默认值: 10Mb。如果想要仅按数据行数限制索引粒度, 请设置为0(不建议)。
- min_index_granularity_bytes - 允许的最小数据粒度,默认值:1024b。该选项用于防止误操作,添加了一个非常低索引粒度的表。
- enable_mixed_granularity_parts — 是否启用通过 index_granularity_bytes 控制索引粒度的大小。在19.11版本之前, 只有 index_granularity 配置能够用于限制索引粒度的大小。当从具有很大的行(几十上百兆字节)的表中查询数据时候,index_granularity_bytes 配置能够提升ClickHouse的性能。如果您的表里有很大的行,可以开启这项配置来提升SELECT 查询的性能。
- use_minimalistic_part_header_in_zookeeper — ZooKeeper中数据片段存储方式 。如果use_minimalistic_part_header_in_zookeeper=1 ,ZooKeeper 会存储更少的数据。
- min_merge_bytes_to_use_direct_io — 使用直接 I/O 来操作磁盘的合并操作时要求的最小数据量。合并数据片段时,ClickHouse 会计算要被合并的所有数据的总存储空间。如果大小超过了 min_merge_bytes_to_use_direct_io 设置的字节数,则 ClickHouse 将使用直接 I/O 接口(O_DIRECT 选项)对磁盘读写。如果设置 min_merge_bytes_to_use_direct_io = 0 ,则会禁用直接 I/O。默认值:10 * 1024 * 1024 * 1024 字节。
- merge_with_ttl_timeout — TTL合并频率的最小间隔时间,单位:秒。默认值: 86400 (1 天)。
- write_final_mark — 是否启用在数据片段尾部写入最终索引标记。默认值: 1(不要关闭)。
- merge_max_block_size — 在块中进行合并操作时的最大行数限制。默认值:8192
- storage_policy — 存储策略。
- min_bytes_for_wide_part,min_rows_for_wide_part 在数据片段中可以使用Wide格式进行存储的最小字节数/行数。
- max_parts_in_total - 所有分区中最大块的数量。
- max_compress_block_size - 在数据压缩写入表前,未压缩数据块的最大大小。
- min_compress_block_size - 在数据压缩写入表前,未压缩数据块的最小大小。
- max_partitions_to_read - 一次查询中可访问的分区最大数。
参考文档
https://clickhouse.com/docs/zh/engines/table-engines/mergetree-family/mergetree
https://bohutang.me/2020/06/26/clickhouse-and-friends-merge-tree-disk-layout/