前言
多兴趣向量召回系列:
通过Youtube DNN推荐模型来理解推荐流程
多兴趣召回模型:MIND
推荐系统可以表达为序列推荐问题的形式,序列推荐任务是通过用户的历史行为来预测用户下一个感兴趣的item,这也与真实场景的推荐场景是符合的。
大部分模型会为每一个用户生成一个整体的用户嵌入向量(user embedding),但一个用户向量难以代表用户多方面的兴趣。
如下图,用户感兴趣的商品是涉及多个方面的,比如化妆品、包包等等。
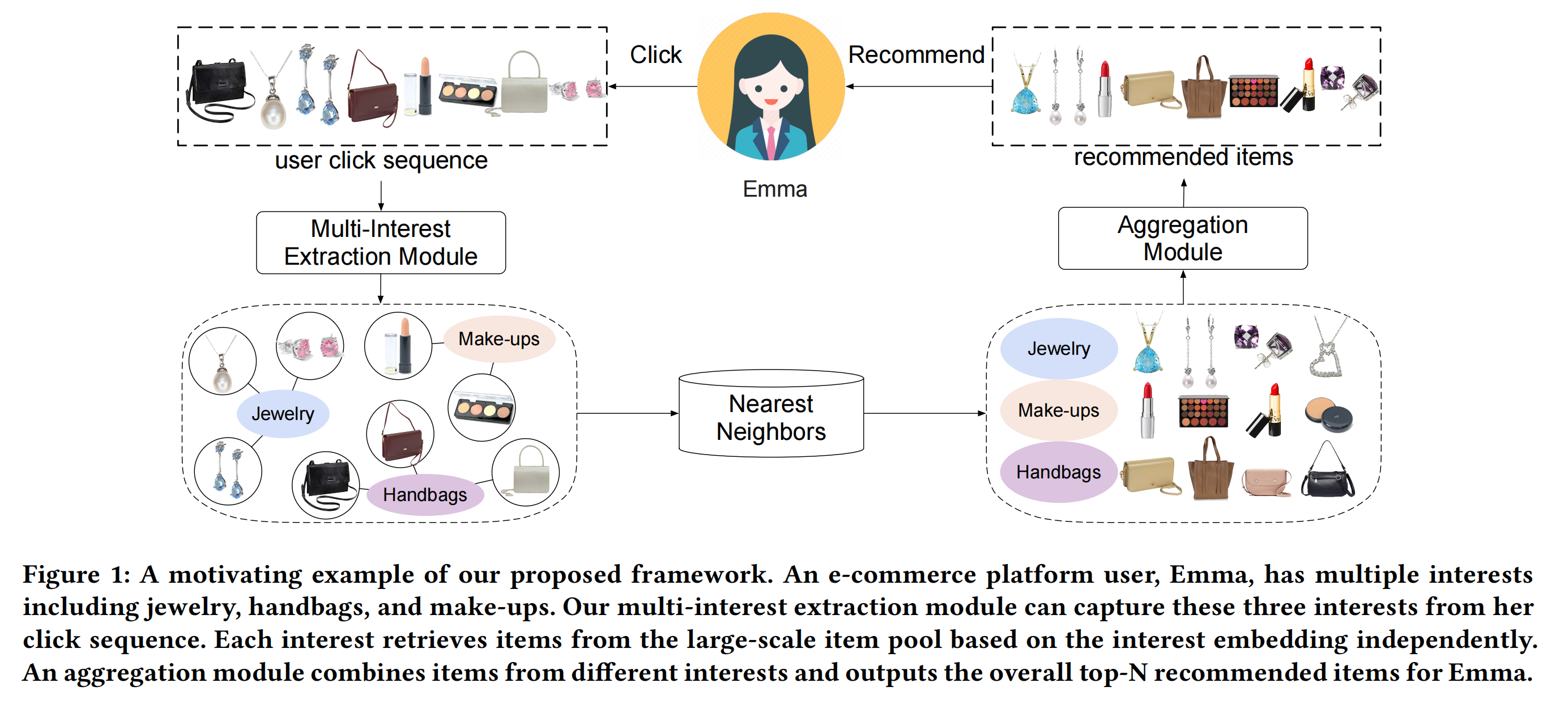
上一篇文章,我们已经讲述了一个可以提取多个用户兴趣向量的召回模型:MIND(Multi-Interest Network with Dynamic Routing)。
这次,我们再来说另一个相关的模型:ComiRec,同样是阿里发表的论文《Controllable Multi-Interest Framework for Recommendation》。
这篇论文的主要贡献为以下三点:
- 提出了一种在统一的推荐系统中集成了可控性(controllability)和多兴趣模块的框架;
- 通过在线上推荐系统的实现和学习,探索了个性化系统可控性的作用;
- 在真实的两个数据集中(Amazon Books和Taobao dataset),取得了state-of-the-art的表现。
#模型框架
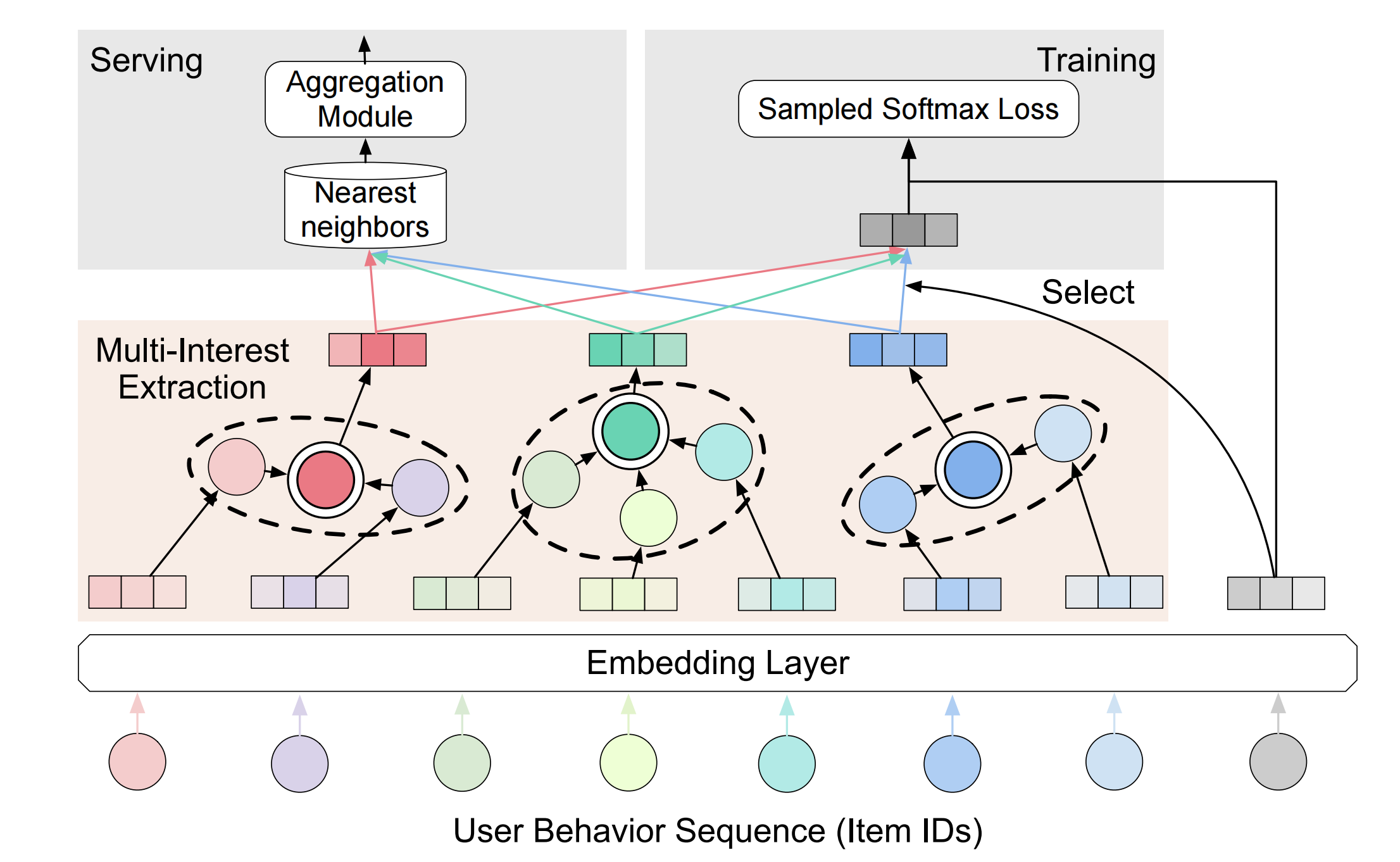
从这张结构图可以看出,ComiRec的整体与MIND还是比较像的。
- 用户的行为序列即互动过的item列表,通过Embedding Layer层转换为item embeddings;
- 然后这些item embeddings给到Multi-Interest Extraction,得到用户的K个interest embeddings;
- 在训练阶段,会选择一个与target item embedding最接近的interest embeddings,来计算sampled softmax loss;
- 在预测阶段,每个interest embeddings都会召回top-N个item即总共K*N个,然后进入Aggregation Module,最终得到N个item作为推荐结果。
下面,我们对每个模块进行拆解解读。
Embedding Layer还是常规的embedding做法,在这里就不再赘述了。
Multi-Interest Framework
论文中使用了两种多兴趣提取模块:Dynamic Routing和Self-Attentive Method,并且分别称为ComiRec-DR和 ComiRec-SA。
Dynamic Routing
这个方法是出自CapsNet《Dynamic routing between capsules》,大体的思想是:
- 一个capsule(胶囊)是一组神经元,这些神经元的向量代表了一种类型的实体,例如一个object或者一个object的部分;
- 一个capsule的输出向量的length( ∣ ∣ s ∣ ∣ ||s|| ∣∣s∣∣)又代表了当前输入下,该实体向量为capsule表征的概率。
阿里将用户行为序列的item embeddings作为初始的capsule,然后提取出多个兴趣capsules,即为用户的多个兴趣。
令 e i e_i ei为第一层网络的第i个capsules,那么下一层网络的第j个capsules为:
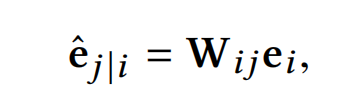
W i j W_{ij} Wij为转换矩阵。
接着,第j个capsule的全部输入为:
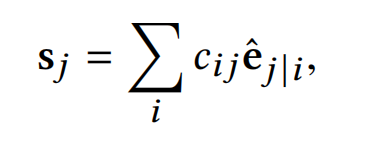
其中, c i j c_{ij} cij为第i个capsule和下一层的第j个capsule的耦合系数,由迭代的动态路由计算决定,并且加和为1。
作者使用“routing softmax”来计算这个耦合系数, b i j b_{ij} bij代表了第i个capsule和下一层的第j个capsule是成对(be coupled to)的先验概率log值,初始化为0:
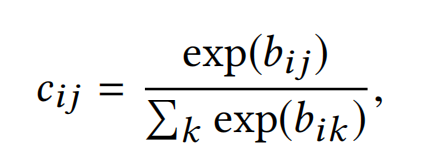
最后,第j个capsule的输入 s j s_j sj会通过一个非线性的"squashing"函数,得到输出的capsule v j v_j vj。
squash函数的目的主要是让short的向量缩放到length接近为0,而long的向量缩放到length接近于1(略低于1)。这里有起到向量筛选的作用,不相关或者不重要的向量length会趋于0,而相关或者重要的向量length就基本保持不变。
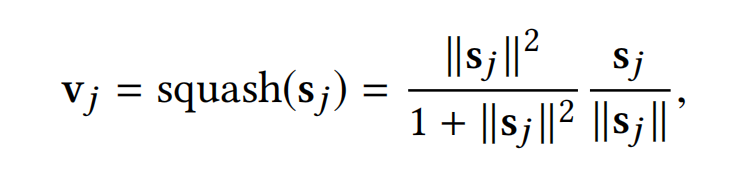
上面的过程会经过多次的迭代。最终输出的capsules V u = [ v 1 , . . . , v K ] ∈ R d × K V_u=[v_1,...,v_K]\in R^{d \times K} Vu=[v1,...,vK]∈Rd×K就是用户的多个兴趣capsules(interest embeddings)。
整个Dynamic Routing的算法流程如下:

###Self-Attentive Method
自我注意力机制也可以应用到多兴趣提取模块。给定用户的行为序列embeddings H ∈ R d × n H\in R^{d\times n} H∈Rd×n(n为序列的长度),使用自我注意力机制可以得到这些行为序列embeddings的权重 a ∈ R n a\in R^n a∈Rn:
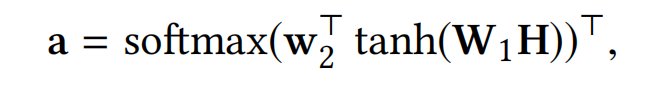
其中 w 2 ( s i z e 为 d a ) 和 W 1 ( s i z e 为 d a × d ) w_2(size为d_a)和W_1(size为d_a\times d) w2(size为da)和W1(size为da×d)都是可以训练的参数。
接着,再使用权重a对用户行为序列embeddings进行加权求和,就可以得到用户的兴趣向量表征: v u = H a v_u=Ha vu=Ha
但是,作者为了能够利用上用户行为序列的顺序信息,增加了一个维度与行为序列embeddings相同的可训练的位置向量(positional embeddings),让其与行为序列embeddings相加;并且为了能够提取用户多个方向的不同兴趣,让 w 2 从一维扩展为二维矩阵 W 2 ( d a × K ) w_2从一维扩展为二维矩阵W_2(d_a \times K) w2从一维扩展为二维矩阵W2(da×K):
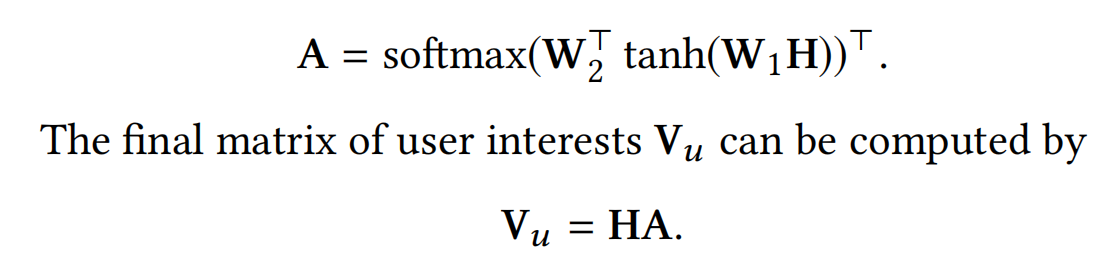
Model Training
在模型训练阶段,提取了用户的多个 interest embeddings之后,会从中挑选一个与target item i ( e m b e d d i n g 为 e i ) i(embedding为e_i) i(embedding为ei)最贴合的embedding,使用内积作为度量进行挑选:
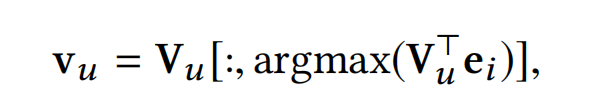
目标函数仍然是结合负采样的最大似然法:
( I I I是全量的item库,计算代价过高,所以使用负采样来代替)
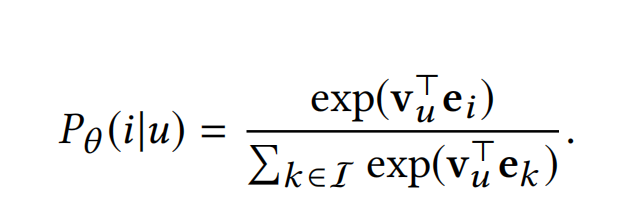
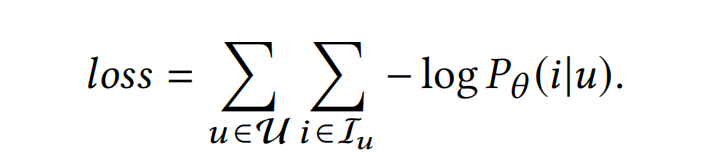
Online Serving
线上预测时,通过多兴趣提取模块计算得到用户的多个兴趣向量,每个兴趣向量可以分别从大规模的item库召回N个item,然后这些N*K个item会再输入到一个聚合模块,来决定整体的item候选集,最终排序分数的最高的N个item会作为最终的召回结果。
Aggregation Module
一个最直接的聚合方法,也是MIND使用的,就是直接使用上一步的召回分数(内积相似度),挑选分数最高的N个item:
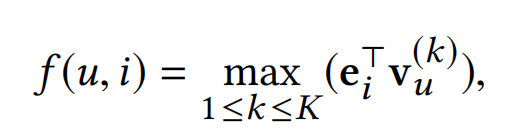
这个方法是对推荐准确率最有效的,但作者认为推荐系统不能单单考虑准确率,用户更希望能够推荐一些新的或者不同的东西。
因此论文提出一种综合考虑推荐准确率和多样性的聚合方法。
给定多兴趣提取模块召回的K*N个items的集合M,求出N个items的集合S,满足下式分数最大:
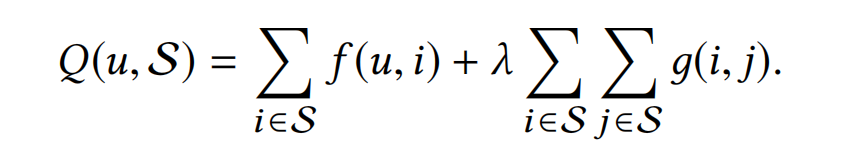
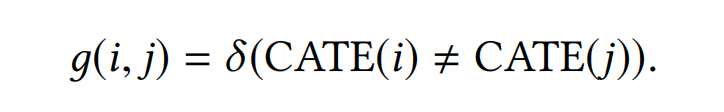
其中, λ ≥ 0 \lambda \ge 0 λ≥0是一个可控因素,也就是论文强调的推荐系统的可控性,当 λ = 0 \lambda=0 λ=0时,则等同于最直接的聚合方法,当 λ = ∞ \lambda=\infty λ=∞时,则会召回的item多样性是最丰富的;
δ ( ⋅ ) \delta(\cdot) δ(⋅)是一种指示函数( indicator function),在论文的场景下,当i和j的品类相同时,g(i, j)=1,反之则g(i, j)=0。
在推理时,论文提出了一种最大化Q(u,S)的贪心算法,具体如下:

工程细节
推荐模型除了要学习模型的相关知识,其实数据方面的工程工作也是相当重要的,甚至其重要性相比模型是有之过而无不及。下面就再来讲讲这篇论文一些工程上的实现。
数据集划分
论文是按照用户来划分数据集的,训练集:验证集:测试集的比例为8:1:1。
训练集毫无疑问是使用全部点击序列来训练模型,用户的点击序列为 ( e 1 ( u ) , e 2 ( u ) , . . . , e k ( u ) , . . . , e n ( u ) ) (e_1^{(u)},e_2^{(u)},...,e_k^{(u)},...,e_n^{(u)}) (e1(u),e2(u),...,ek(u),...,en(u)),那么每个训练样本则会使用序列的前k个items来作为模型的输入,来预测第k+1个item,其中 k = 1 , 2 , . . . , ( n − 1 ) k=1,2,...,(n-1) k=1,2,...,(n−1);
(这里对于初学者,如果仅仅研究了模型,那么对于样本的构造也是可能设计错误的)
验证集和测试集是使用用户的前面80%的点击序列来作为模型的输入,然后去预测后面的点击序列。
这样做的好处是相比同个用户的行为序列在训练和验证时都使用到(即不是按照用户来划分数据集,而是所有样本随机划分),更具泛化性,效果更可信。
评估指标
论文使用了三个常规的指标来离线评估模型的召回效果。
**Recall:**为了更好的可解释性,使用用户平均的recall而不是全局平均。 I ^ u , N \hat{I}_{u,N} I^u,N为模型召回的top-N个items, I u I_u Iu为用户的真实点击item。Recall度量了用户的真实点击items被模型召回命中的比例。
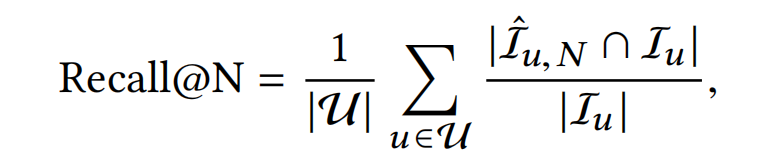
**Hit Rate:**度量了模型召回的items至少命中一个用户的真实items的比例
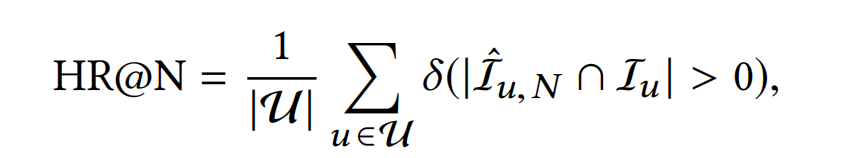
这里的 δ ( ⋅ ) \delta(\cdot) δ(⋅)同样是一种指示函数( indicator function),跟上述的含义相同。
**Normalized Discounted Cumulative Gain:**NDCG度量了模型召回的items命中的位置,命中的位置越靠前,NDCG的分数就越高,效果当然也就越好。
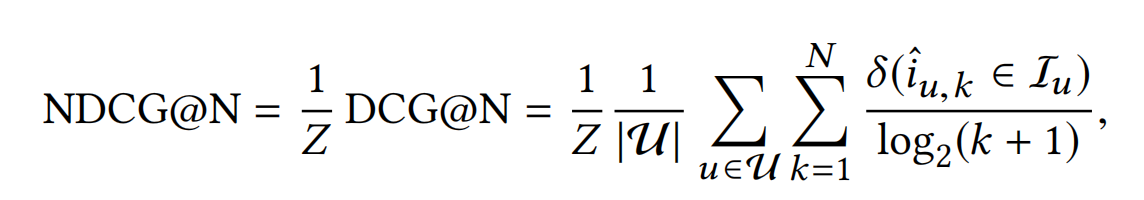
其中, i ^ u , k \hat{i}_{u,k} i^u,k为用户u召回的第k个item,Z是一个常量,它的值等于DCG的最大可能值,其实就是模型推荐召回的items位置与真实的items完全一致时,DCG的值。
推荐多样性
为了让推荐系统取得更高的准确率,一些研究建议需要让推荐多元化来避免单调性以及提升用户的体验。
论文使用了以下的方式来计算推荐的items的多样性:
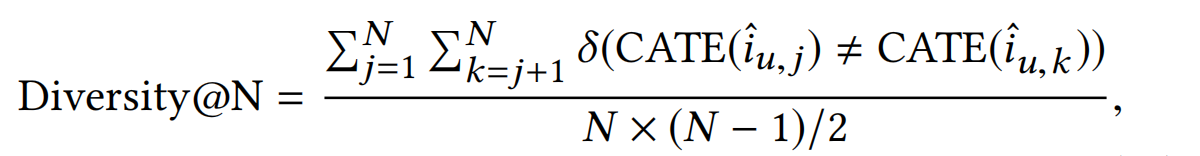
模型超参数
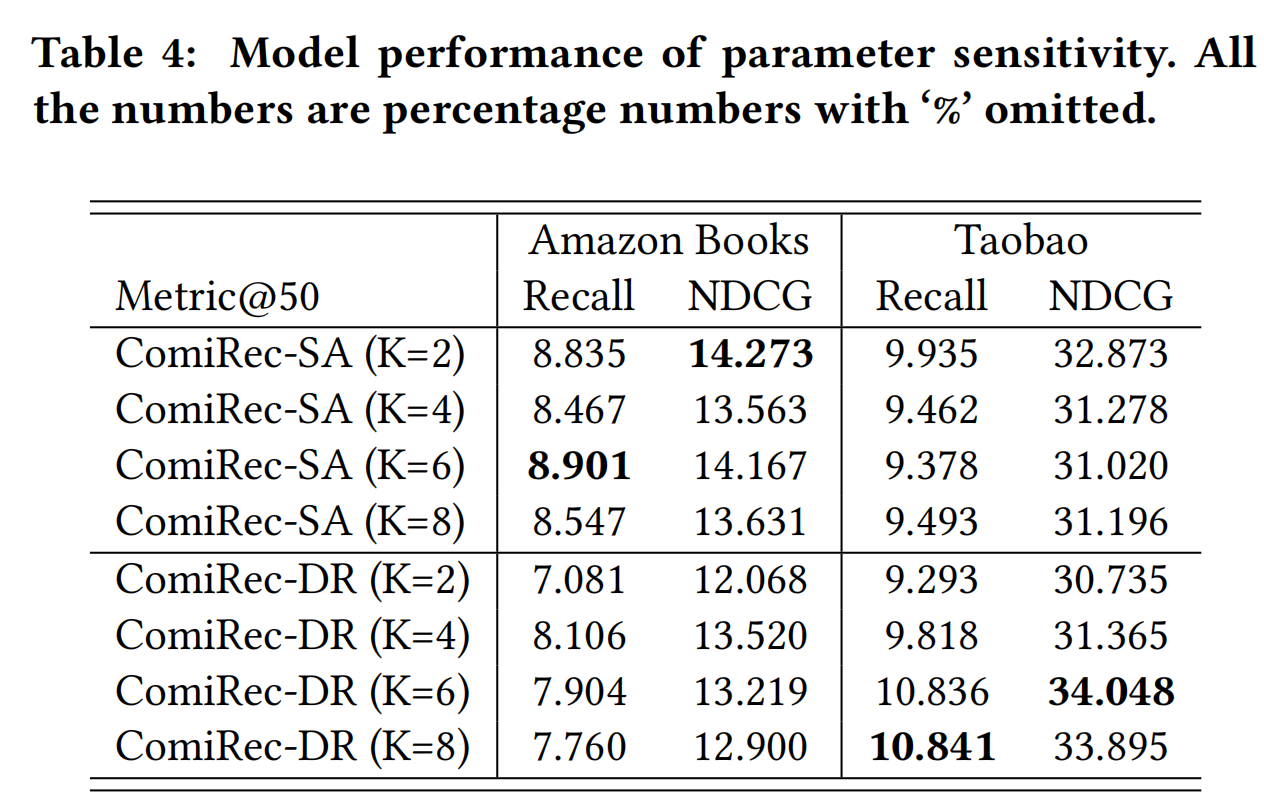
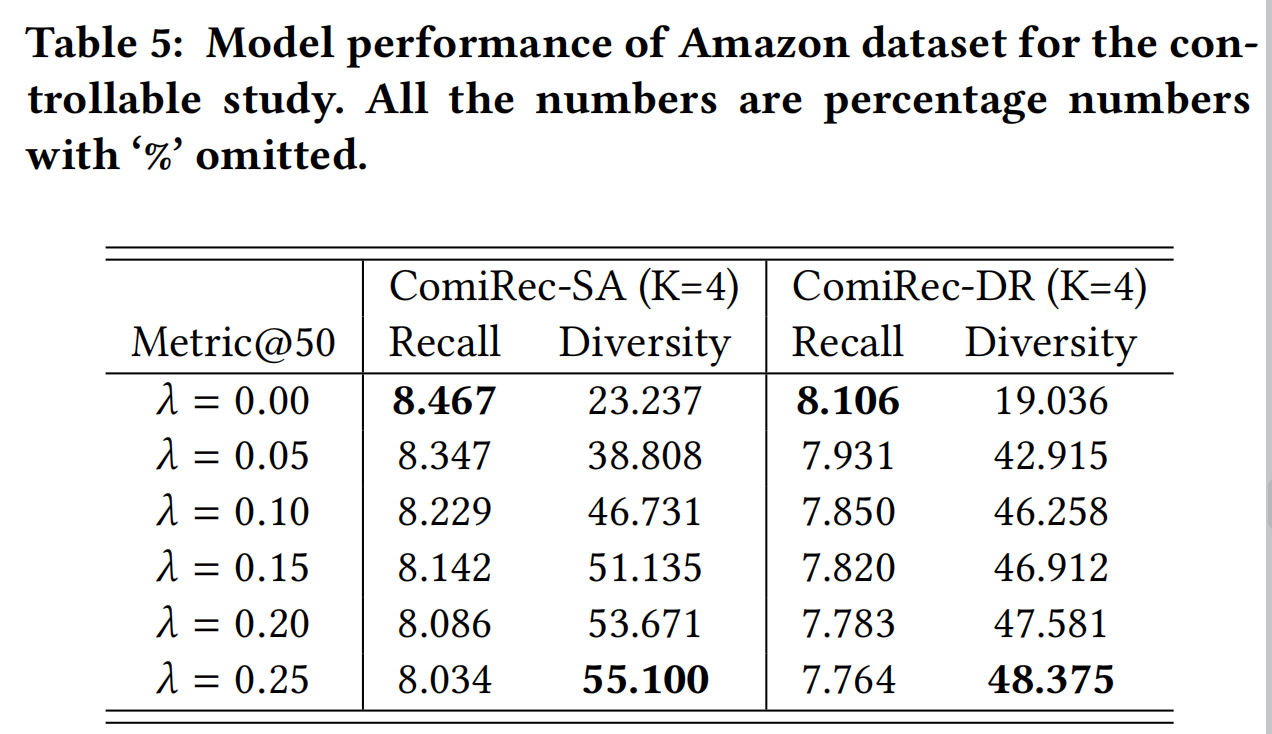
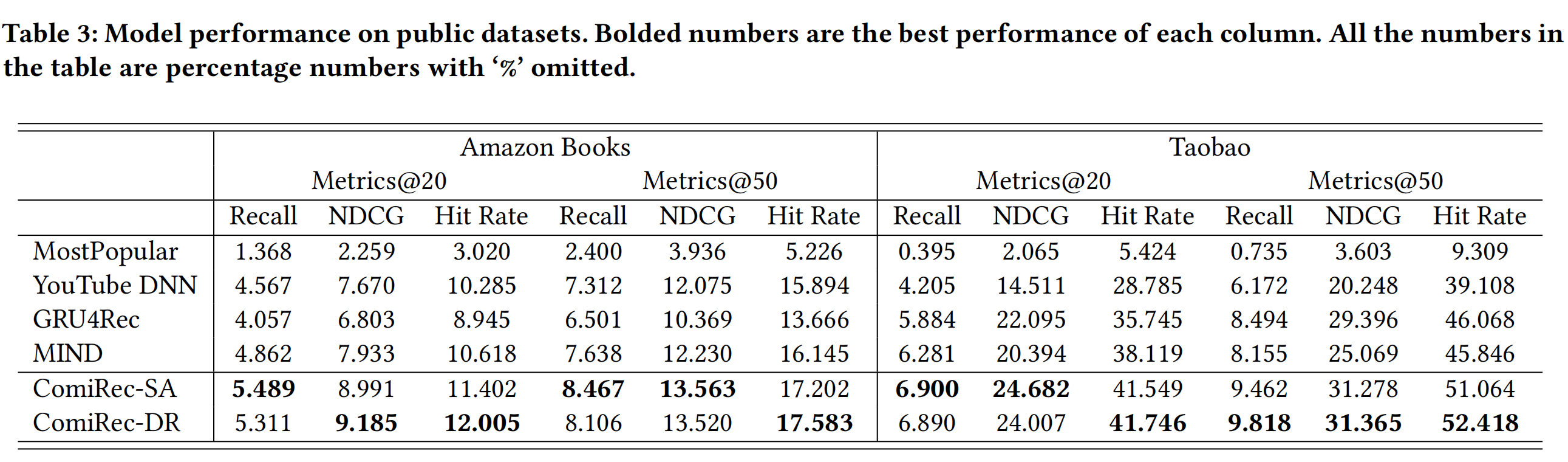
实验结果
- embedding的维度为64
- 负采样的负样本数量为10
- 多兴趣提取模块提取的interest embeddings的数量K=4
- 使用Adma优化器,学习率为0.001
- 训练步数为了1百万
代码实现
GitHub
总结
- 论文指出了推荐召回模型中单个用户兴趣向量的弊端,提出一种可以提取多个用户兴趣向量的模型ComiRec,包括两种多兴趣提取模块:Dynamic Routing和Self-Attentive Method,对应的模型分别为ComiRec-DR和ComiRec-SA;
- 提出一种新的对用户多个兴趣向量召回结果的聚合方法(Aggregation Module),指出推荐系统可控性的重要性(论文中主要体现了推荐的多样性控制);
- 与MIND有很多相似的地方,都是为了解决单个用户兴趣向量召回的局限性,而区别也主要是上面两点。另外需要注意的一点是动态路由方法也是不同的:MIND是提出了新的Behavior-to-Interest (B2I) dynamic routing,而该论文是原始的dynamic routing(CapsNet);还有一个就是MIND的用户兴趣向量的个数K是由用户的历史行为序列的长度动态计算得到,而ComiRec是固定的。
- 最后,论文对用户的其他特征没有说明如何处理使用,像常规的离散特征embedding、连续特征直接拼接或者分箱再embedding,也是可以一起加进去的。