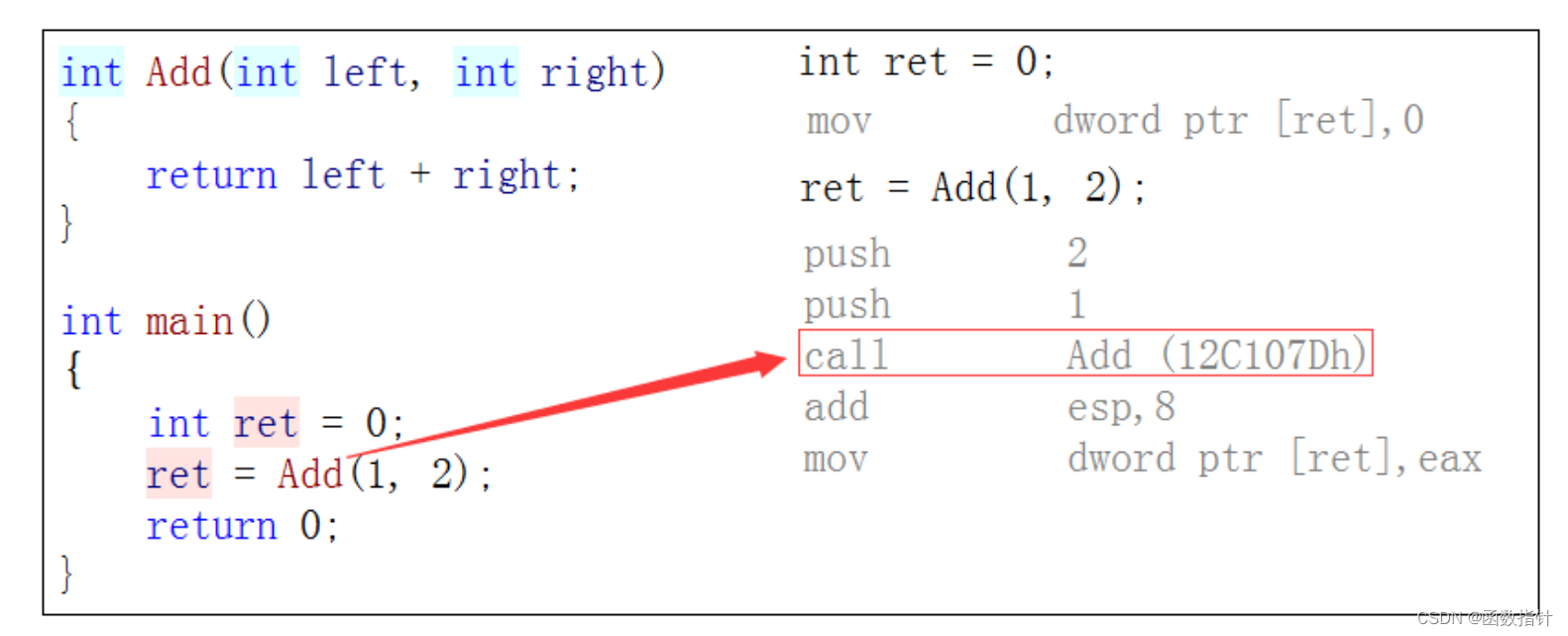
这一章节与前面写好的function关联太大,建议看书P291.
这章节主要讲述了添加attention的seq2seq,且只在decoder里面添加,所以全文都在讲这个decoter
目录
1.训练
2.预测
1.训练
#@save
class AttentionDecoder(d2l.Decoder):
"""带有注意⼒机制解码器的基本接⼝"""
def __init__(self, **kwargs):
super(AttentionDecoder, self).__init__(**kwargs)
@property
def attention_weights(self):
raise self._attention_weights Encoder对每个词的rnn输出作为key-values,输出为(bs,k-v,h)
Decoder对上一个词的rnn输出作为query(bs,1,h)
要预测下一词时,当前预测的作为query,编码器对应的各个原文输出为key-values,进行attention,来找到对应预测下一个词的查询
原seq2seq是将上一个rnn里最后一个state,现在允许所有词的输出都获取,根据上下文对应找到(bs,q,h///values)
只有decoder使用attention
前面的init只增加了一个attention,其他的emb、rnn、dense与seq2seq一样
init_state相比之前增加了enc_valid_lens,告知encoder中的有效长度
class Seq2SeqAttentionDecoder(AttentionDecoder):
def __init__(self, vocab_size, embed_size, num_hiddens, num_layers,
dropout=0, **kwargs):
super(Seq2SeqAttentionDecoder, self).__init__(**kwargs)
self.attention = d2l.AdditiveAttention(
num_hiddens, num_hiddens, num_hiddens, dropout)
self.embedding = nn.Embedding(vocab_size, embed_size)
self.rnn = nn.GRU(
embed_size + num_hiddens, num_hiddens, num_layers,
dropout=dropout)
self.dense = nn.Linear(num_hiddens, vocab_size)
def init_state(self, enc_outputs, enc_valid_lens, *args):
# outputs的形状为(batch_size,num_steps,num_hiddens).
# hidden_state的形状为(num_layers,batch_size,num_hiddens)
outputs, hidden_state = enc_outputs
return (outputs.permute(1, 0, 2), hidden_state, enc_valid_lens)
def forward(self, X, state):
# enc_outputs的形状为(batch_size,num_steps,num_hiddens).
# hidden_state的形状为(num_layers,batch_size,
# num_hiddens)
enc_outputs, hidden_state, enc_valid_lens = state
# 输出X的形状为(num_steps,batch_size,embed_size)
X = self.embedding(X).permute(1, 0, 2)
outputs, self._attention_weights = [], []
for x in X:
# query的形状为(batch_size,1,num_hiddens)
query = torch.unsqueeze(hidden_state[-1], dim=1)
# context的形状为(batch_size,1,num_hiddens)
context = self.attention(
query, enc_outputs, enc_outputs, enc_valid_lens)
# 在特征维度上连结
x = torch.cat((context, torch.unsqueeze(x, dim=1)), dim=-1)
# 将x变形为(1,batch_size,embed_size+num_hiddens)
out, hidden_state = self.rnn(x.permute(1, 0, 2), hidden_state)
outputs.append(out)
self._attention_weights.append(self.attention.attention_weights)
# 全连接层变换后,outputs的形状为
# (num_steps,batch_size,vocab_size)
outputs = self.dense(torch.cat(outputs, dim=0))
return outputs.permute(1, 0, 2), [enc_outputs, hidden_state,
enc_valid_lens]
@property
def attention_weights(self):
return self._attention_weights 对于for:每一步的context会变,所以需要一步一步更新context
query里面的hidden_state[-1]里面的-1表示获取最后一层的rnn_state(bs,h),原本为(n_layers,bs,h)
再context中,keys=values=enc_outputs,在此虽然最后维度长度相同,但是也可用加性attention。
T表示k-v,h为values,P289;out尺寸为(bs,T,h)表示原句子所有输出,经过attention得到的context表示拿到了(bs,q,values),在所有的outputs找到了q查询对应的值,
每个词的context不同,所以q=1,query为上一次decoder的输出的最后一层,再用attention再encoder的全部输出outputs(bs,T,h)找到相关的查询输出注意力权重和查询值(bs,q,values)--权重如何计算?通过grad自己找loss学的。
即context为(bs,1,h),再合并x送入decoder的rnn产生下一个词的预测。(vx
加了attention是利用decoder上一层输出到encoder中所有的out找到相关查询值,再与当前x拼一起产生预测,(第一个x的上一层输出query是encoder最后的state再state[-1]取最后一层)
embed_size, num_hiddens, num_layers, dropout = 32, 32, 2, 0.1
batch_size, num_steps = 64, 10
lr, num_epochs, device = 0.005, 250, d2l.try_gpu()
train_iter, src_vocab, tgt_vocab = d2l.load_data_nmt(batch_size, num_steps)
encoder = d2l.Seq2SeqEncoder(
len(src_vocab), embed_size, num_hiddens, num_layers, dropout)
decoder = Seq2SeqAttentionDecoder(
len(tgt_vocab), embed_size, num_hiddens, num_layers, dropout)
net = d2l.EncoderDecoder(encoder, decoder)
d2l.train_seq2seq(net, train_iter, lr, num_epochs, tgt_vocab, device)
2.预测
预测时,dec_x=1
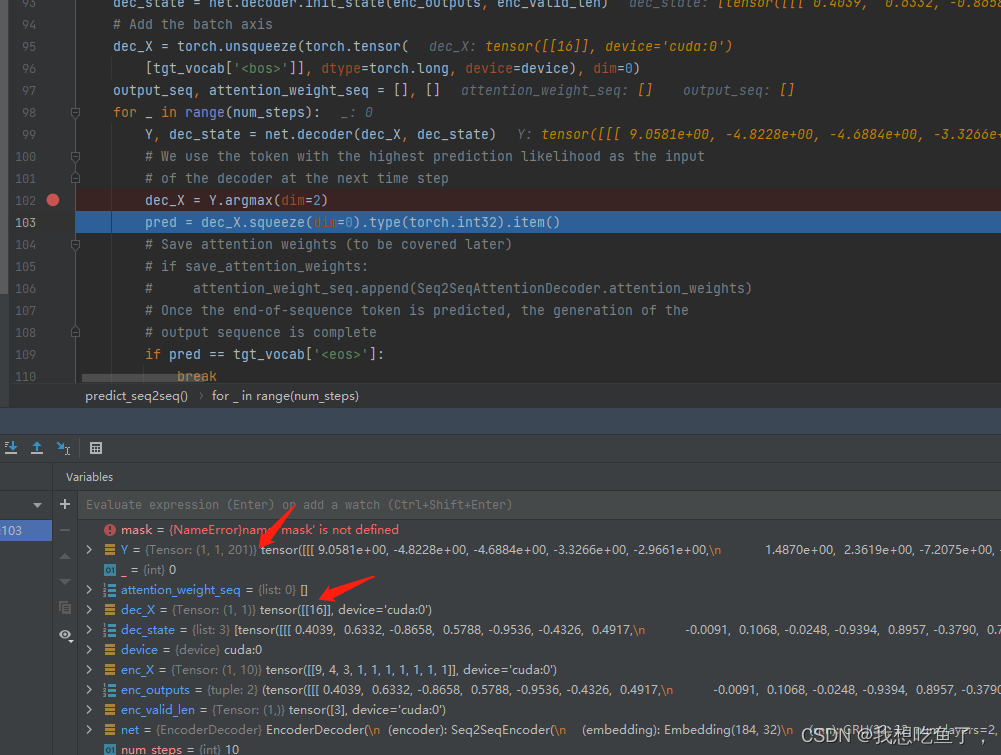
可见,预测的时候dec_x就是只有一个
(bs,T)--(1,1)
再送入decoder

经过emb后,且经过permute后,得到(T,bs,emb)
然后就是获取query,(bs,q,q_s),本次q_s=k_s=h=values;传入加性注意力拿到(bs,q,values),与当前x做拼接生成(bs,T,emb+h),再通过permute得到rnn的通识传入尺寸(T,bs,emb+h).通过rnn后得到out为(T,bs,h),再经过线性层并经过permute,得到最终输出(T,bs,len(v))
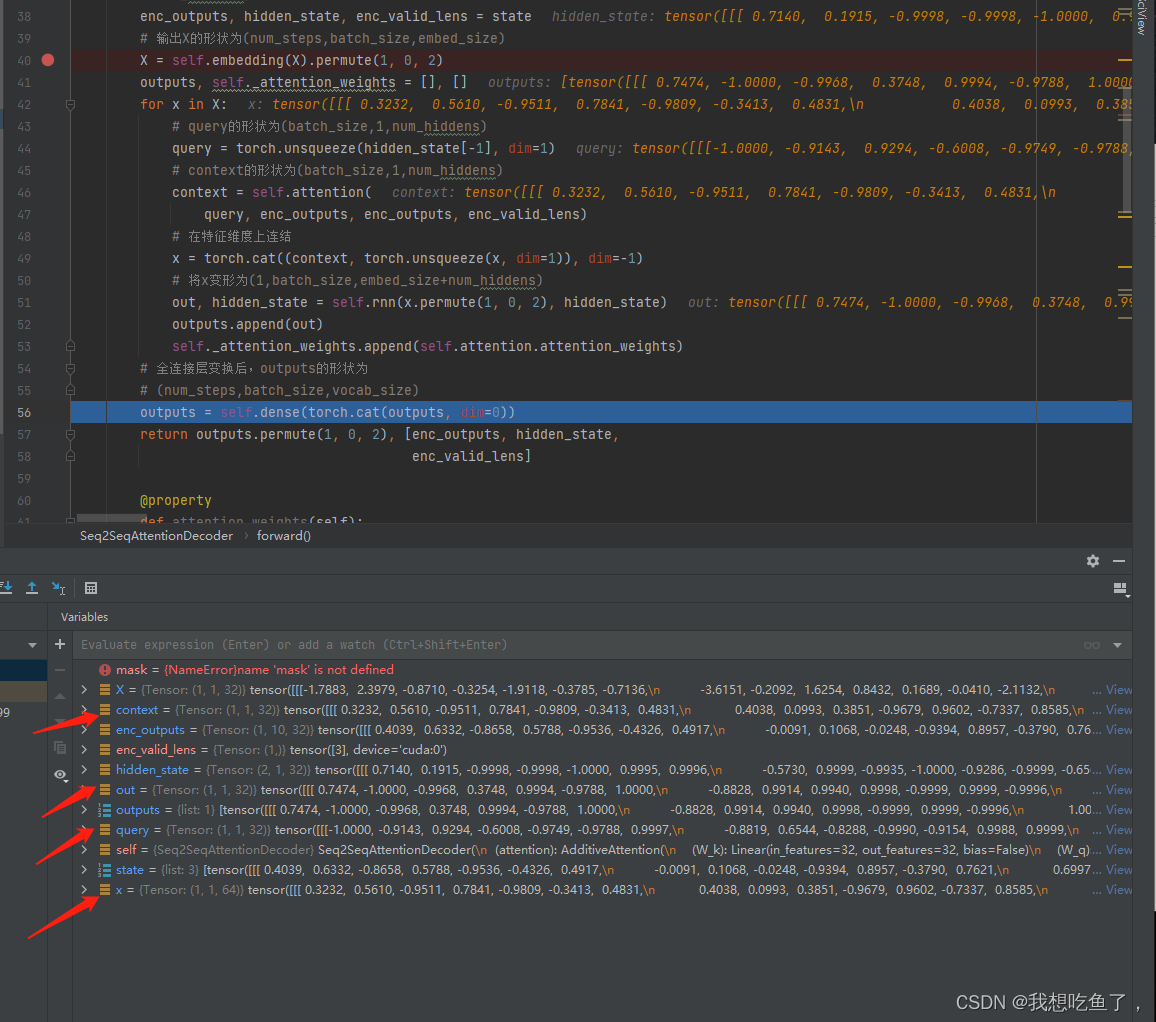
decoder中outputs传入dense线性层操作
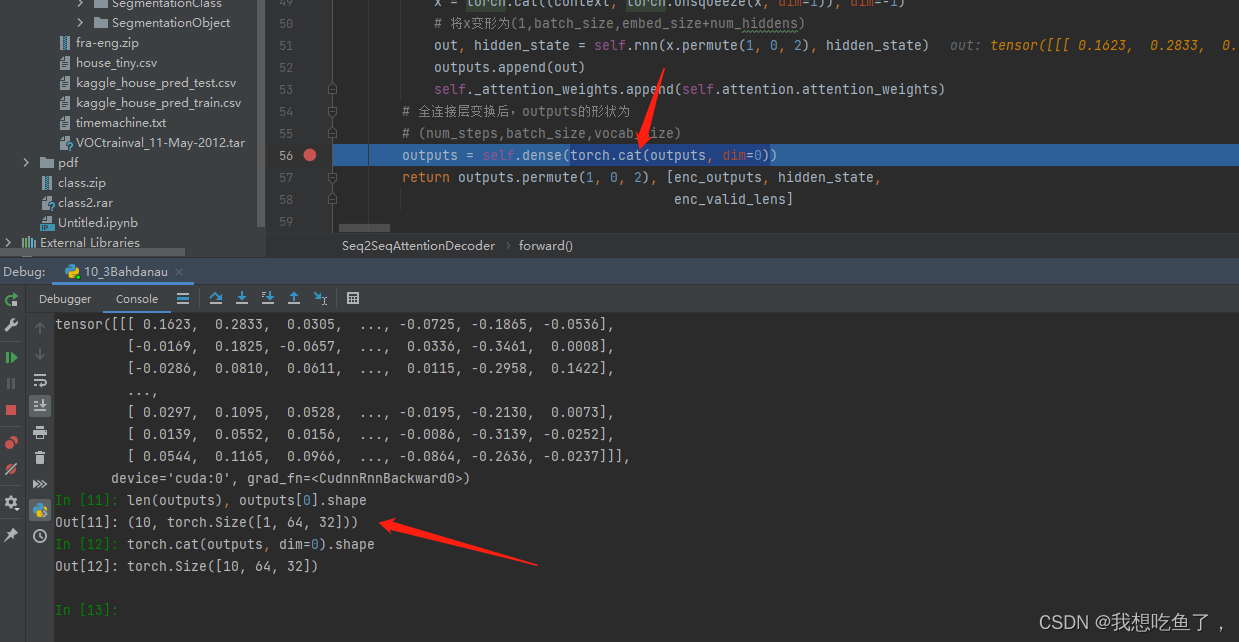
原先outputs是一个list,里面的每个元素为(1,bs,h);经过cat后,将T拼接起来形成(T,bs,h),一并传入dense获得整个T的最终输出(T,bs,len(v))


![[前端基础]异步操作(还没写完)](https://img-blog.csdnimg.cn/bb3f9d38abdd42898c30fbade8637050.png)