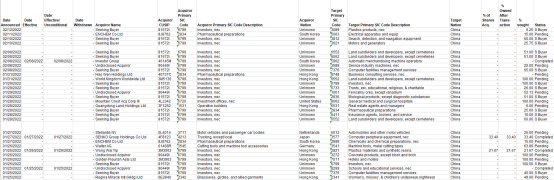
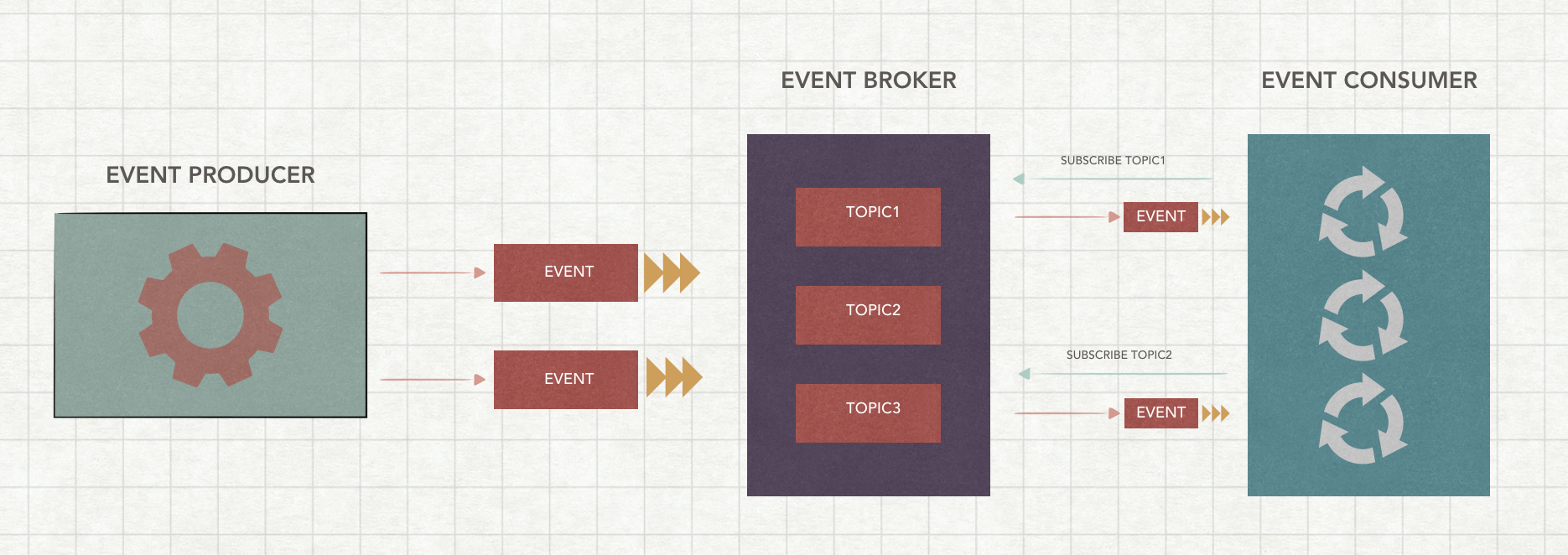
ceph 线程池
1. WHY
线程过多会带来调度开销,进而影响缓存局部性和整体性能。而线程池维护着多个线程,等待着监督管理者分配可并发执行的任务。这避免了在处理短时间任务时创建与销毁线程的代价。线程池不仅能够保证内核的充分利用,还能防止过分调度。可用线程数量应该取决于可用的并发处理器、处理器内核、内存、网络sockets等的数量。
2. WHAT
线程池和工做队列实际上是密不可分的。让任务推入工做队列,而线程池中的线程负责从工做队列中取出任务进行处理。
工做队列和线程池的关系,相似于狡兔和走狗的关系,正是由于有任务,因此才须要雇佣线程来完成任务,没有了狡兔,走狗也就失去了存在的意义。而线程必需要能够从工做队列中认领任务并完成,这就相似于猎狗要有追捕狡兔的功能
3. HOW
以osd侧的osd_op_tp线程为例:
对应于下面的代码分析流程

//线程池start在osd.init()
int OSD::init()
{
osd_op_tp.start();
}
void ShardedThreadPool::start()
{
shardedpool_lock.Lock();
start_threads();
shardedpool_lock.Unlock();
}
void ShardedThreadPool::start_threads()
{
assert(shardedpool_lock.is_locked());
int32_t thread_index = 0;
while (threads_shardedpool.size() < num_threads)
{
WorkThreadSharded *wt = new WorkThreadSharded(this, thread_index);
threads_shardedpool.push_back(wt);//池子加入线程
wt->create(thread_name.c_str());//创建线程
thread_index++;
}
}
void Thread::create(const char *name, size_t stacksize)
{
assert(strlen(name) < 16);
thread_name = name;
int ret = try_create(stacksize);
}
int Thread::try_create(size_t stacksize)
{
r = pthread_create(&thread_id, thread_attr, _entry_func, (void*)this);
restore_sigset(&old_sigset);
return r;
}
void *Thread::_entry_func(void *arg)
{
void *r = ((Thread*)arg)->entry_wrapper();
return r;
}
void *Thread::entry_wrapper()
{
....
return entry();
}
struct WorkThreadSharded : public Thread
{
ShardedThreadPool *pool;
void *entry() override
{
pool->shardedthreadpool_worker(thread_index);
return 0;
}
}
void ShardedThreadPool::shardedthreadpool_worker(uint32_t thread_index)
{
//轮询
ldout(cct,10) << "worker start" << dendl;
//队列初始化的时候便就入队了,详见各队列的构造函数
wq->_process(thread_index, hb);
ldout(cct,10) << "sharded worker finish" << dendl;
cct->get_heartbeat_map()->remove_worker(hb);
}
//ThreadPool实现的线程池,其每个线程都有机会处理工作队列的任意一个任务。
//这就会导致一个问题,如果任务之间有互斥性,那么正在处理该任务的两个线程有一个必须等待另一个处理完成后才能处理,从而导致线程的阻塞,性能下降
void OSD::ShardedOpWQ::_process(uint32_t thread_index, heartbeat_handle_d *hb)
{
//任务调度方式做了改进
osd->service.update_sched_out_queue();
osd->callback_trigger();//precheck_finisher.queue(c); //async process//也会被ms_fast_dispatch调用
lgeneric_subdout(osd->cct, osd, 4) << "dequeue status: ";//被阻塞的线程
boost::optional<PGQueueable> qi;
ThreadPool::TPHandle tp_handle(osd->cct, hb, timeout_interval,suicide_interval);
qi->run(osd, pg, tp_handle);//处理pg事件
}
//另外一种方式入队
ms_fast_dispatch--> enqueue_op --> op_shardedwq.queue(make_pair(pg, PGQueueable(op, epoch)))
--> _enqueue(item)-->enqueue_fetch_next -->queue.add_request(std::move(item), cl, qosparam, cost)
总结如何使用
1.声明线程池成员ThreadPool *_tp
2.声明队列类型ThreadPool::WorkQueue_*_wq
3.重写WorkQueue中对应函数_void_process,_void_process_finish
4.调用*_tp.add_work_queue(*_wq)将队列传入
4. 线程池及线程分类
- 第一类是普通类线程:
使用此类线程类直接申明继承自Thread,重写一个entry函数,在进程启动最初时,调用了create函数创建了线程,同时使用它的人必须自己定义消息队列。上面大部分线程都是此类,比如FileJournal::write_thread就是一个FileJournal::Writer类对象,它自己定义了消息队列FileJournal::writeq
第二类是SafeTimerThread类线程:
此类线程使用者可以直接申明一个SafeTimer成员变量,因为SafeTimer中已经封装了SafeTimerThread类和一个消息队列(成员是Context回调类),并完成了entry函数的逻辑流程。使用者使用方法,就是设置回调函数,通过SafeTimer::add_event_after函数将钩子埋入,等待规定时间到达后执行。
第三类是FinisherThread类线程:
此类线程使用者可以直接申明一个Finisher成员变量,因为Finsher中已经封装了FinisherThread类和一个消息队列(成员是Context回调类),并完成entry函数的逻辑流程。使用者使用方法,就是设置回调函数,通过Finisher::queue函数将钩子埋入,等待某类操作完成后执行。处理回调complete函数
第四类是ThreadPool内部线程:
这类线程由于是具体工作类线程,所以他们一般都是以线程池形式一下创建多个。ThreadPool类内部有多个线程set<WorkThread*>和多个消息队列vector<WorkQueue_*>组成。工作流程就是线程不断的轮询从队列中拿去数据进行操作(如下图)
-
op_tp 处理client来的请求
disk_tp 处理scrub操作
recovery_tp处理recovery_tp操作
command_tp 处理命令行来的操作
FileStore::op_tp 处理底层数据操作
进行操作(如下图)
-
op_tp 处理client来的请求
disk_tp 处理scrub操作
recovery_tp处理recovery_tp操作
command_tp 处理命令行来的操作
FileStore::op_tp 处理底层数据操作


![[附源码]计算机毕业设计springboot二手书店设计论文](https://img-blog.csdnimg.cn/fb4bac0659524e388bea00df43fe9e1d.png)






![[附源码]计算机毕业设计springboot病房管理系统](https://img-blog.csdnimg.cn/97316c053caf496891541c2e7cc937c9.png)