DETR 论文精读【论文精读】_哔哩哔哩_bilibili更多论文:https://github.com/mli/paper-reading/, 视频播放量 90699、弹幕量 493、点赞数 3566、投硬币枚数 2939、收藏人数 2564、转发人数 663, 视频作者 跟李沐学AI, 作者简介 ,相关视频:在线求偶|26岁985副教授,博一研究生 求偶视频,Transformer论文逐段精读【论文精读】,ViLT 论文精读【论文精读】,中科院博士单人间,一个小发现…单人间也别干坏事儿~,审稿人无法拒绝的Introduction:如何下钩子,突出工作的重要性和意义,你试过,高质量读研究生吗?,ViT论文逐段精读【论文精读】,导师对不起,您当院士的事可能得缓缓了,【精读AI论文】知识蒸馏 https://www.bilibili.com/video/BV1GB4y1X72R/?spm_id_from=333.999.0.0&vd_source=4aed82e35f26bb600bc5b46e65e25c22
https://www.bilibili.com/video/BV1GB4y1X72R/?spm_id_from=333.999.0.0&vd_source=4aed82e35f26bb600bc5b46e65e25c22
detr不需要proposal和anchor,利用transformer的全局建模能力,把目标检测看成是一个集合预测的问题,不需要nms。detr在大目标上表现的很好,小目标效果不行,大目标主要因为全局建模能力强。
abstract:目标检测是给定一张图片,去预测一堆框,每个框不仅要知道坐标还要需要知道这个框包含的物体的类别,但是这些框其实是一个集合,对于不同的图片来说,包含的框也是不一样的,每个图片对应的框集合是不一样的,因此我们的任务是给定一个图片,来预测这个框集合。detr把目标检测中的先验部分给去掉了,去掉了nms和anchor。detr提出了新的目标函数,通过二分匹配,强制模型输出独一无二的框,每个物体理想情况下只会生成一个框,此外使用了encoder-decoder的结构,在decoder时除了encoder的输入,还有一个额外的learned object query,这个在日后成为prompt的基础输入,这些query其实也有点类似anchor的意思,作者在论文最后也分析了这些query,其实他就是在deocder中筛选框。detr把learned object query和全局图像信息结合在一起,不停的通过cross-attention让模型输出一组框。不过这里虽然使用了encoder-decoder的架构,但是并不是自回归的,对于框的输出是并行的。
1.introduction
目标检测任务,其实就是对目标物体预测一些框和物体类别,其实就是一个集合预测的问题,目前的大多是检测器使用的都是间接的方式去处理集合预测问题,比如proposal,anchor和一些使用点的方法,使用回归或者分类来解决检测,依赖于nms,这些方法都会产生大量的冗余框。detr是怎么做的呢?

上图是detr的流程图,1.用一个cnn去抽特征,然后拉直,2.经过一个transformer encoder,进一步学习全局信息,3.用decoder来生成框的输出,上图中没有object query,当有了图像特征之后,这个query就限制了出框数,通过query在特征中做cross-attention,得到输出框,query=100就意味着最终会出100个框,4.得到100框之后要和gt计算loss,用二分图匹配,比如只有2个gt,在训练时,100个框和2个gt之间计算matching loss,从而决定100个框中对应gt的2个框,确定好匹配关系之后,会像常规目标检测一样计算分类loss和bounding box的loss,而没有匹配的框则会被标记成背景类。在推理时,不需要计算loss,在输出的100个框中卡一个置信度就能输出框了。
2.detr model
2.1 object detection set prediction loss
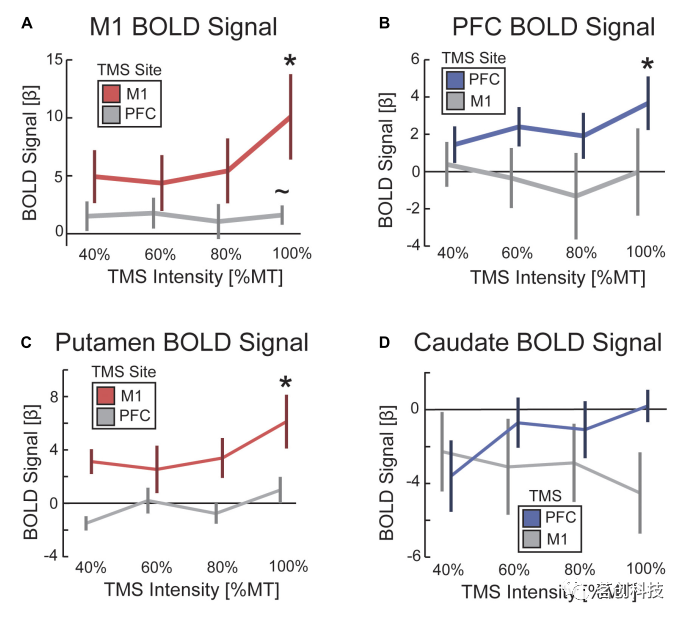
任何一张图在detr中都会输出100个框,在coco数据集上是够用了,但是一张图的gt就只有几个框,作者把这种匹配转成了二分图匹配问题,

![]()
上图中举个例子来解释二分图匹配,abc代表3个工人,xyz代表3个工作,每个工人完成不同工作的时间和报酬都不同,那么就有上图中一个矩阵,矩阵中描述了a工人完成x的一个cost,这个矩阵叫cost matrix,也叫损失矩阵,最优二分图匹配就是找到唯一解给每个人都分配最合适的工作且cost最小,如果把所有的组合都跑一遍一定能找到最优解,但是复杂度肯定高,匈牙利算法就是解决这个问题一种高效算法,在目标追踪中也是卡尔曼滤波加匈牙利算法,一般都是使用scipy中的linear sum assignment去解。在detr中abc就是100个预测框,xyz就是gt,那么cost matrix中应该放什么呢?这里面放的就是loss,对一般检测任务来说,loss包括两个部分,一个是分类loss,一个是box loss,遍历所有的预测框,用预测框和gt计算loss,然后把loss放到cost matrix中,使用scipy中的linear sum assignment得到最优解,其实这个找最优的匹配和之前proposal或者anchor的方式也类似,都是驱使预测框和gt更好的匹配,就是样本分配,只不过这里匹配是更强的约束,是希望得到一对一的匹配关系而不是一堆多的。在计算loss,利用这个loss去做梯度回传,
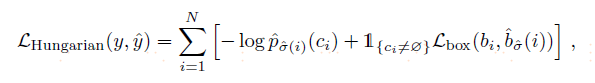
第一块是分类loss,第二块是box loss,这里的box loss通常使用l1 loss,但是在detr中对大目标比较友好,因此计算出来的loss偏大,不利于优化,因此还用了一个iou loss。detr的loss和一般目标检测最大的不同就是先算了一个最优匹配,然后再在最优匹配上计算这个loss。
2.2 detr architecture
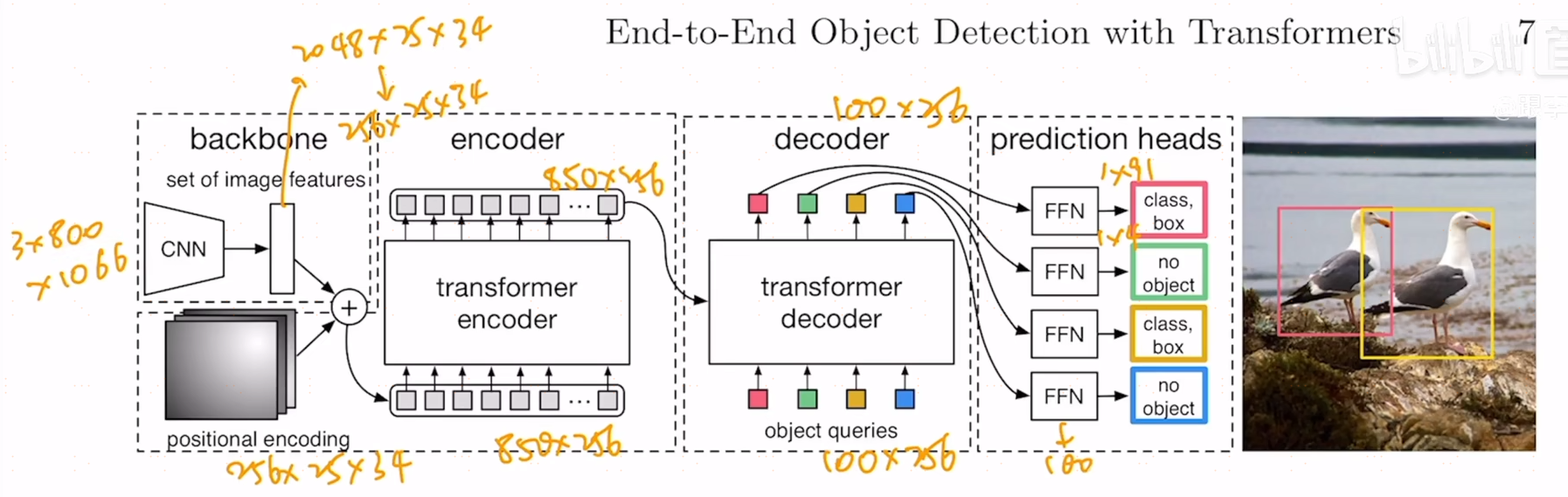
25x34是800x1066的1/32,经过cnn之后得到2048x25x34,加上位置编码,经过一个1x1的降维变成了850x256,850是序列长度,256是transformer的head dimension,经过一个encoder,输出还是850x256,作者用了6个encoder结构,在输入一个deocder,有一个object query,是个learnable embedding,它是一个learnable的positional embedding,维度是100x256,256是为了和之前维度对应,好计算loss,100是要得到100个框的输出,然后这个query在decoder中做cross-attnetion,deocder有两个输入,一个是全局特征的800x256,一个是query的100x256,用这两个反复的做attention,得到了100x256,decoder也用了6层,每层的输入输出也是不变的,都是100x256进,100x256出,最终,当得到100x256的特征之后,要加一个检测头,这个检测头是比较标准的,就是ffn,是个mlp,把特征给全连接层,全连接层会给两个预测,一个是物体类别的预测,一个是框的预测,中心点和宽高。用100个预测框和gt中的两个框做最优匹配,用匈牙利算法得到目标函数,梯度回传。
有一些细节,在decoder中,每一个decoder都会做一次object query,做object query主要为了移除冗余框,因为它们在相互通信之后,每个query可能会得到什么样一个框,作者在最后做了这样一个实验。此外在计算loss,为了让模型收敛的更快,在每一个decoder后面都加了auxiliary loss,因为每层输出都是100x156,因此每层都可以加个损失,这些ffn都是共享参数的,下面是模型的pytorch代码。

3.experiments
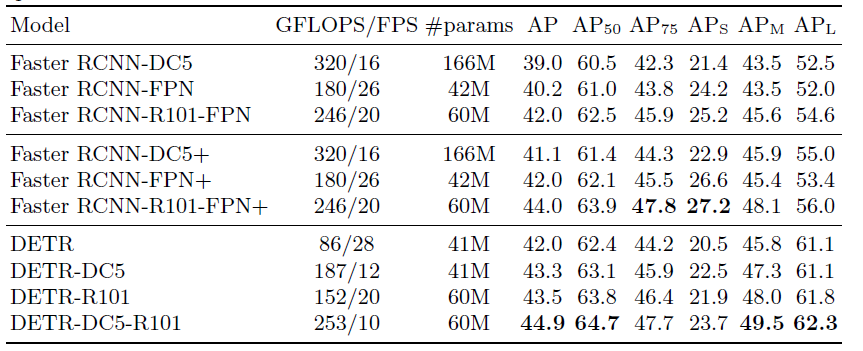
detr速度慢,小物体识别也不好,此外训练的轮数需要很长,不过这些缺点在deformable detr中都得到了解决。

上图是把encoder可视化了,在牛身上点一些点,以这些为基准和图像中其他点计算attention,这里面和后面出来的sam就一样了,sam中的点,框和mask作为prompt输入的,可以观察这些点的注意力是如何分布,实际上对物体的建模已经很好了,说明transformer的特征提取能力是真的强,这也使我对transformer在图像中的应用产生了很大的改观,尤其是日后引入弱监督或者自监督中使用transformer这种超强特征提取能力的backend是很有必要的,这块meta还有个dino的工作也是体现了transformer的建模能力。

上图是decoder的可视化,decoder到底在学什么?把每个物体的自注意力以不同颜色标出来了,不同的物体即便是有遮挡的情况下也能很好的学习。encoder和decoder一个都不能少,encoder在学一个全局的特征,尽可能让这些物体分开,但是光分开是不够的,对于头尾巴这些极值点,交给decoder去做,decoder把注意力放到边缘的学习上,和unet结构也比较相似,一般unet中的encoder去抽一个有语义特征,decoder来恢复图像,通过加入细节把原图恢复出来,这个和transformer中的encoder和decoder是比较类似的。

上图是object query的可视化,作者把cooc中val set中所有图片得到最终的输出框可视化了,虽说n=100,但是作者只画了20,每一个正方形都代表了一个object query,这个query到底在学什么?这些绿色点是小的box,红色的点表示大的横向的box,蓝色代表大的竖向的box,看完这些分布之后,会发现object query和anchor是有些类似的,只不过anchor是提前预设的,而query是学习的,比如第一个query,学到最后,每次给一张图,它会首先去图片的左下角去找一些小框,这前20个分布基本在中间位置都会去找大的横向的box,这和coco数据本身有关系,coco数据集中间经常会有一个大物体占据整个空间。