深加固股票交易
该项目打算在投资组合管理中利用深度强化学习。框架结构的灵感来自Q-Trader。代理人的奖励是在每个行动步骤评估的未实现净利润(意味着股票仍在投资组合中且尚未兑现)。对于每一步的不作为,投资组合中都会增加负惩罚,因为它错失了投资“无风险”国债的机会。在培训和评估管道中进行了许多新功能和改进。所有评估指标和可视化都是从头开始构建的。
For inaction at each step, a negtive penalty is added to the portfolio as the missed opportunity to invest in "risk-free" Treasury bonds. A lot of new features and improvements are made in the training and evaluation pipelines. All evaluation metrics and visualizations are built from scratch.
当前框架的主要假设和局限性:
- 交易对市场没有影响
- 仅支持单一股票类型
- 只有 3 个基本操作:买入、持有、卖出(没有卖空或其他复杂操作)
- 代理人在每个交易日结束时仅执行 1 个投资组合重新分配操作
- 所有重新分配都可以在收盘价完成
- 价格历史中没有缺失数据
- 无交易成本
当前框架的主要挑战:
- 从头开始实施算法,透彻了解它们的优缺点
- 建立可靠的奖励机制(学习往往是静止的/经常陷入局部最优)
- 确保框架可伸缩和可扩展
目前,状态被定义为标准化的相邻每日股票价格差异加上n天数[stock_price, balance, num_holding]。
未来,我们计划在框架中添加其他最先进的深度强化学习算法,例如近端策略优化 (PPO),并通过构建更复杂的价格张量等来增加每个算法中状态的复杂度等. 具有更广泛的深度学习方法,例如卷积神经网络或注意机制。此外,我们计划为高质量数据源集成更好的管道,例如来自像Quandl这样的供应商;和回测,例如zipline。
入门
要安装此项目中使用的所有库/依赖项,请运行
pip3 install -r requirement.txt
要训练 DDPG 代理或 DQN 代理,例如从 2010 年到 2015 年超过标准普尔 500 指数,请运行
python3 train.py --model_name=model_name --stock_name=stock_name
model_name是要使用的模型:要么DQN要么DDPG; 默认是DQNstock_name是用于训练模型的股票;默认为^GSPC_2010-2015,即从 2010 年 1 月 1 日到 2015 年 12 月 31 日的标准普尔 500 指数window_size是观察的跨度(天);默认是10num_episode是用于训练的集数;默认是10initial_balance是投资组合的初始余额;默认是50000
要评估 DDPG 或 DQN 代理,请运行
python3 evaluate.py --model_to_load=model_to_load --stock_name=stock_name
model_to_load是要加载的模型;默认为DQN_ep10;替代方案是DDPG_ep10等stock_name是用于评估模型的库存;默认为^GSPC_2018,即标准普尔 500 从 1/1/2018 到 12/31/2018initial_balance是投资组合的初始余额;默认是50000
where可以在目录stock_name中引用,也可以在目录中引用。datamodel_to_laodsaved_models
要可视化训练损失和投资组合价值波动历史,请运行:
tensorboard --logdir=logs/model_events
在哪里model_events可以在目录中找到logs。
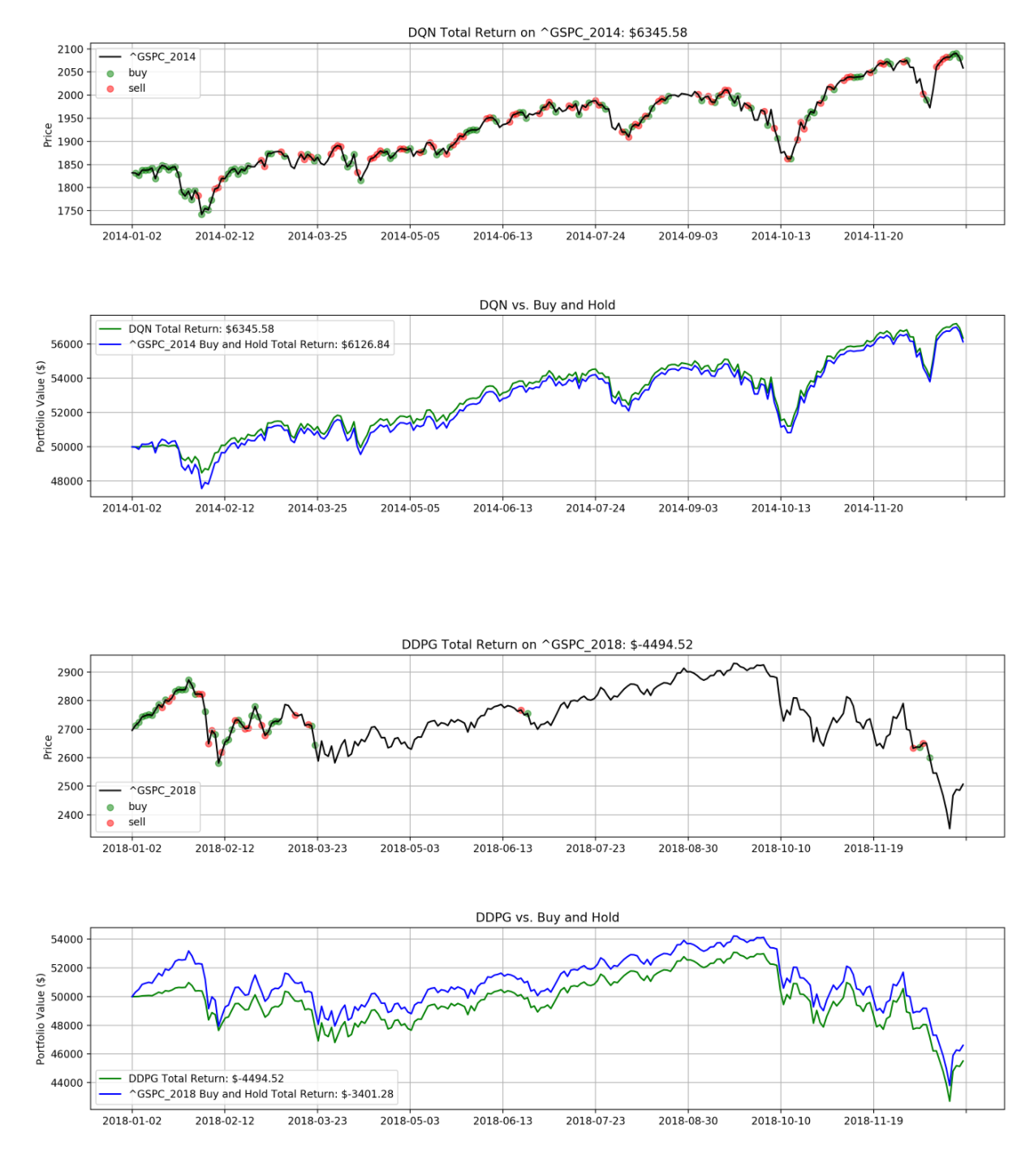
示例结果
请注意,以下结果仅通过 10 个 epoch 的训练获得。
常见问题 (FAQ)
- 该项目与其他价格预测方法(例如逻辑回归或 LSTM)有何不同?
- 像逻辑回归这样的价格预测方法有数字输出,必须分别映射(通过对预测价格的某种解释)到行动空间(例如买入、卖出、持有)。另一方面,强化学习方法直接输出代理的动作。
参考:
- 使用 Keras 和 Gym 进行深度 Q 学习
- 双深度 Q 网络
- 使用Keras和Deep Deterministic Policy Gradient玩转TORCS
- 实用的股票交易深度强化学习方法
- 通过强化学习学习交易简介
- 投资组合管理中的对抗性深度强化学习
- 金融投资组合管理问题的深度强化学习框架