【数据结构实验】哈希表设计
简介
针对本班同学中的人名设计一个哈希表,使得平均查找长度不超过R,完成相应的建表和查表程序。文末贴出了源代码。
需求分析
- 假设人名为中国人姓名的汉语拼音形式,待填入哈希表的人名共有三十个左右,取平均查找长度上限为2,哈希函数用除留余数法构造,用伪随机探测再散列法处理冲突。
- 人名的长度均不超过19个字符,最长的人名如:庄双双(Zhuang Shuangshuang)。
- 应充分研究这些人名的特点,尽量找到一个冲突较小的哈希函数,使得存储时分布尽量均匀。
概要设计
- 用线性表顺序存储结构存储哈希表,哈希表及其中元素的定义如下:
typedef char* KeyType;
typedef struct ElemType
{
KeyType key;
}ElemType;
typedef struct
{
ElemType *elem;
int count;
int sizeindex;
}HashTable;
- 主程序:
int main()
{
初始化;
do{
接受命令;
处理命令;
}while(“命令”!=“退出”)
}
- 本程序共有个4模块,调用关系如下:
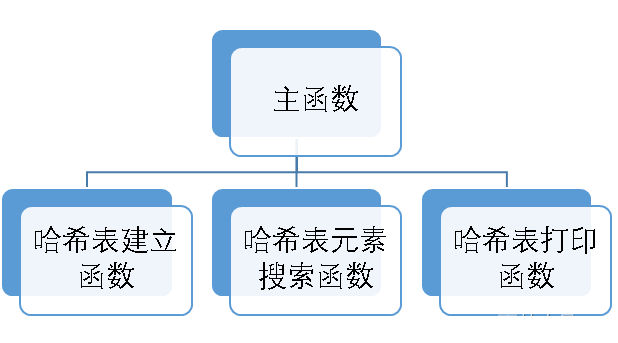
在建立哈希表时,就是通过反复搜索哈希表中的元素进行哈希表的建立。
详细设计
- 所用到的函数声明如下:
/*函数声明*/
Status InitHashTable(HashTable &H);
//初始化哈希表
void Get_RandomSequence();
//生成随机序列
void collision(int &p,int c);
//地址冲突时进行下一次探测
Status DestroyHashTable(HashTable &H);
//删除哈希表
int Hash(KeyType K);
//求出哈希地址
Status InsertHash(HashTable &H, ElemType e);
//将元素e插入哈希表中
void RecreateHashTable(HashTable *H);
//空间不足时,重新分配哈希表
bool equal(KeyType K1,KeyType K2);
//判断两个关键字是否相等
Status SearchHash(HashTable H, KeyType K, int &p, int &c);
//在哈希表中搜索相应元素
Status BulidHash(HashTable &H);
//建立哈希表
void PrintHash(HashTable H);
//打印哈希表
void onScreen();
//生成用户界面,供用户输入选择
2.完整代码:
/*头文件*/
#include<stdio.h>
#include<iostream>
#include <cstring>
#include <ctype.h>
#include<string.h>
#include<math.h>
#include<time.h>
#include<stdlib.h>
/*宏定义*/
#define SUCCESS 1
#define UNSUCCESS 0
#define DUPLICATE -1
#define OK 1
#define ERROR 0
#define MaxNameSize 19
#define NULLKEY NULL
using namespace std;
typedef int Status;
typedef char* KeyType;
typedef struct ElemType
{
KeyType key;
}ElemType;
typedef struct
{
ElemType *elem;
int count;
int sizeindex;
}HashTable;
int length;//length为表长度
int hashsize[]={71,73,79,83,89,97};
int RandomSequence[50];
/*函数声明*/
Status InitHashTable(HashTable &H);
void Get_RandomSequence();
void collision(int &p,int c);
Status DestroyHashTable(HashTable &H);
int Hash(KeyType K);
Status InsertHash(HashTable &H, ElemType e);
void RecreateHashTable(HashTable *H);
bool equal(KeyType K1,KeyType K2);
Status SearchHash(HashTable H, KeyType K, int &p, int &c);
Status BulidHash(HashTable &H);
void PrintHash(HashTable H);
void onScreen();
int main()
{
HashTable H;
InitHashTable(H);
Get_RandomSequence();
onScreen();
char choice;
char* want;
int p=0;int c=0;
want=new char[MaxNameSize];
BulidHash(H);
while(1)
{
fflush(stdin);
cin>>choice;
switch(choice)
{
case 'P':
PrintHash(H);
onScreen();
break;
case 'S':
while(1)
{
c=0;
p=0;
cout<<"开始查找,输入quit返回"<<endl;
fflush(stdin);
gets(want);
if(strcmp(want,"quit")==0)
break;
if(SearchHash(H,want,p,c)==SUCCESS)
{
cout<<"已找到"<<endl;
cout<<"哈希地址为:"<<p<<"\t查找次数:"<<c+1<<endl;
}
else
{
cout<<"未找到"<<endl;
cout<<"查找次数:"<<c+1<<endl;
}
delete(want);
want=new char[MaxNameSize];
}
onScreen();
break;
case 'Q':
exit(0);
break;
default:
cout<<"输入错误"<<endl;
break;
}
}
}
void onScreen()
{
cout<<"-------------------------欢迎使用哈希表查找----------------------------------"<<endl;
cout<<"请选择需要进行的操作(输入相应字母):"<<endl;
cout<<"P.打印哈希表"<<endl;
cout<<"S.查找元素"<<endl;
cout<<"Q.退出程序"<<endl;
}
Status InitHashTable(HashTable &H)
{
H.count=0;
H.sizeindex=0;
length=hashsize[H.sizeindex];
H.elem=new ElemType[length];
if(!H.elem) exit(OVERFLOW);
for(int i=0;i<length;i++)
H.elem[i].key=NULLKEY;
return OK;
}
void Get_RandomSequence()
{
srand((int)time(NULL));
for(int i=0;i<50;i++)
RandomSequence[i]=rand()%length;
}
void collision(int &p,int c)
{
//p = (p + c) % length;
p=(p+RandomSequence[c])%length;
// p=(int)(p+pow(-1,c)*pow(2,c))%(length/2);
}
Status DestroyHashTable(HashTable &H)
{
delete(H.elem);
H.count=0;
H.sizeindex=0;
return OK;
}
int Hash(KeyType K)
{
if(length>0)
{
return (K[0]+K[strlen(K)-1]+K[strlen(K)-2])%length;
}
else
return -1;
}
void RecreateHashTable(HashTable *H)
{
int i, count = (*H).count;
int m=length;
ElemType *a, *elem = (ElemType*) malloc(count * sizeof(ElemType));
a = elem;
//printf("重建哈希表\n");
for (i = 0; i < m; i++) // 保存原有的数据到elem中
if (((*H).elem + i)->key != NULLKEY) // 该单元有数据
*elem++ = *((*H).elem + i);
elem = a;
(*H).count = 0;
(*H).sizeindex++; // 增大存储容量
m = hashsize[(*H).sizeindex];
ElemType *p = (ElemType*) realloc((*H).elem, m * sizeof(ElemType));
if (!p)
exit(0); // 存储分配失败
(*H).elem = p;
for (i = 0; i < m; i++)
(*H).elem[i].key = NULLKEY; // 未填记录的标志(初始化)
for (i = 0; i < count; i++) // 将原有的数据按照新的表长插入到重建的哈希表中
InsertHash(*H, *(elem + i));
}
bool equal(KeyType K1,KeyType K2)
{
if(!K1||!K2) return false;
int result=strcmp(K1,K2);
if(result==0)
return true;
else
return false;
}
Status SearchHash(HashTable H, KeyType K, int &p, int &c)
{
// 算法9.17
// 在开放定址哈希表H中查找关键码为K的元素,
// 若查找成功,以p指示待查数据元素在表中位置,并返回SUCCESS;
// 否则,以p指示插入位置,并返回UNSUCCESS,
// c用以计冲突次数,其初值置零,供建表插入时参考
p = Hash(K); // 求得哈希地址
while ((H.elem[p].key != NULLKEY) && // 该位置中填有记录
!equal(K, (H.elem[p].key))) // 并且关键字不相等
collision(p, ++c); // 求得下一探查地址p
if (equal(K, (H.elem[p].key)))
return SUCCESS; // 查找成功,p返回待查数据元素位置
else return UNSUCCESS; // 查找不成功(H.elem[p].key == NULLKEY),
// p返回的是插入位置
} // SearchHash
Status InsertHash(HashTable &H, ElemType e)
{ // 算法9.18
// 查找不成功时插入数据元素e到开放定址哈希表H中,并返回OK;
// 若冲突次数过大,则重建哈希表
int c = 0;
int p = 0;
if (SearchHash(H, e.key, p, c) == SUCCESS )
return DUPLICATE; // 表中已有与e有相同关键字的元素
else if (c <hashsize[H.sizeindex]/2)
{ // 冲突次数c未达到上限,(阀值c可调)
H.elem[p].key=e.key;
++H.count;
return SUCCESS; // 插入e
}
else
{
RecreateHashTable(&H); // 重建哈希表
return UNSUCCESS;
}
} // InsertHash
void PrintHash(HashTable H)
{
cout<<"打印hash表"<<endl;
cout<<"count\tp\tkey"<<endl<<endl;
int count=0;
for(int i=0;i<length;i++)
if(H.elem[i].key!=NULLKEY)
{
count++;
printf("%d\t%d\t%s\n\n",count,i,H.elem[i].key);
// cout<<<<"\t"<<<<endl;//H.elem[0].name
}
int p=0,c=0;
float total=0;
//char want[50];
while(1) //伪随机数还是有随机性的,此处可以保证平均查找长度小于2
{
for(int i=0;i<length;i++)
{
if(H.elem[i].key!=NULLKEY)
{
SearchHash(H,H.elem[i].key,p,c);
total+=c+1;
c=0;
}
}
if(total/33>=2) BulidHash(H);
else break;
}
cout<<"平均查找长度:"<<total/33<<endl;
}
Status BulidHash(HashTable &H)
{
FILE *fp;
ElemType e;
if((fp=fopen("姓名.txt","r"))==NULL)
{
cout<<"不能打开文件姓名.txt"<<endl;
return ERROR;
}
char temp[MaxNameSize];
while(fgets(temp,MaxNameSize,fp)!=NULL)
{
e.key=(char*)malloc(strlen(temp)*sizeof(char));
strcpy(e.key,temp);
e.key[strlen(e.key)-1]='\0';
// cout<<e.name<<endl;
InsertHash(H,e);
}
fclose(fp);
return OK;
}
调试分析
- 在最初设计哈希函数时,采用每个人名第一个字的第一个拼音的asc码作为哈希地址,出现了较多地址冲突,具体原因是班级内有较多的同姓的同学,因此进行了适当的修改,更改为每个人名字首个字符与倒数两个字符的asc码的和对表长取余的值。
- 最初只有班级同学的中文姓名格式,可以通过excel获取班级同学名字的拼音格式,高效迅速。
- 最初在搜索时时常出现找不到某个同学的情况,具体原因是因为文件读入格式出问问题,导致名字读入不完整或者建立哈希表时未插入到正确位置。
用户手册
进入程序后,用户将看到一下界面:
---欢迎使用哈希表查找-----
请选择需要进行的操作(输入相应字母):
P.打印哈希表
S.查找元素
Q.退出程序
用户可根据需求进行选择,班级同学的姓名无需手动输入,已自动从指定文件夹中读入。
调试数据
- 选择P,将打印哈希表,并自动计算平均查找长度:
打印hash表
count p key
1 3 Jin Weiqiang
2 5 Li Qiupeng
3 9 Chen Jiayi
4 11 Wangtao
5 12 Xiong Peiyao
6 13 Zhang Huan
7 14 Sun Xiaoni
8 16 Wu Guanpeng
9 17 Wang Zhihua
10 18 Li Jingyi
11 19 Xiong Junlin
12 20 Zhang Enhua
13 21 Chen Nianyu
14 24 Yu Liang
15 25 Zhou Xuanyu
16 30 Li Wenjie
17 31 Lin Haichuan
18 35 Jing Yaxing
19 37 Li Yapeng
20 43 Xiao Yi
21 44 Lin Zhaoqian
22 45 Zhang Xiaoyuan
23 48 Wu Yiting
24 50 Wu Jiajia
25 51 Zeng Yang
26 53 Chen Xiaoyu
27 57 Yu Zihuan
28 58 Zhang Yitian
29 63 Yang Dongsheng
30 66 Zhu Jinxin
31 67 Jiang Weiwei
32 69 Jia Shihao
33 70 Fu Yongning
平均查找长度:1.87879
- 输入S,再输入查找人名,将自动进行搜索并返回结果。
- 所用到的其他文件
姓名.txt
Chen Jiayi
Chen Nianyu
Chen Xiaoyu
Fu Yongning
Jia Shihao
Jiang Weiwei
Jin Weiqiang
Jing Yaxing
Li Jingyi
Li Qiupeng
Li Wenjie
Li Yapeng
Lin Haichuan
Lin Zhaoqian
Sun Xiaoni
Wangtao
Wang Zhihua
Wu Guanpeng
Wu Yiting
Wu Jiajia
Xiao Yi
Xiong Junlin
Xiong Peiyao
Yang Dongsheng
Yu Zihuan
Yu Liang
Zhang Enhua
Zhang Huan
Zhang Xiaoyuan
Zhang Yitian
Zeng Yang
Zhou Xuanyu
Zhu Jinxin