多分类
随机梯度下降、随机森林和朴素贝叶斯都可以处理多分类问题,而logistic回归、支持向量机是严格的二分类分类器,但是可以用一些方法将多个二分类分类器组合在一起完成多分类任务。
1. OvR(one-versus-the-rest、one-versus-all)
比如识别手写数字时,直接训练10个二分分类器,遇到新图片时,分别跑这10个模型,然后选得分最高的那个作为识别结果。
2. OvO(one-versus-one)
比如识别手写数字时,为每一对数字(0-1,0-2…8-9)训练一个二分分类器。那么N个类需要训练 N x (N - 1) / 2 个分类器。遇到新图片时,分别跑45个模型,看哪个类赢得多。OvO的优点是只在当前这对数字的训练集上训练。相比于在大的训练集上训练较少的分类器,在小的数据集上训练较多分类器会更快些。一些算法很难在大数据集上扩展,比如SVM,就比较适合OvO。
当使用二分分类器处理多分类任务时,scikit learn会根据算法特性,自动选择使用OvR策略还是OvO策略。
from sklearn.svm import SVC
some_digit = X[5]
svm_clf = SVC()
svm_clf.fit(X_train, y_train)
some_digit_scores = svm_clf.decision_function([some_digit])
print(svm_clf.predict([some_digit]))
print(some_digit_scores)
print(np.argmax(some_digit_scores))
print(svm_clf.classes_)
[2]
[[ 2.7442516 -0.30125634 9.31399134 7.26965016 3.75753908 3.74771902
0.71155138 2.76650678 8.2765048 6.21840456]]
2
[0 1 2 3 4 5 6 7 8 9]
由上面可以看到,decision_function的分数有10个,说明是OvR,分数最高的确实是index=2,也就是“2”类。
对于天然能多分类的分类器,比如SGD,它是不需要经过OvR或者OvO策略的,其decision_function()返回的值也会大很多(之前有过负几万到正几千)。
分类器训练时,classes_属性存储了分类列表(已根据值排序),但是index不一定跟类本身一致。这里只是刚好一致。
如果要强制使用OvO或OvR,那么只要创建一个 实例,然后把分类器传递进去即可。
import time
from sklearn.svm import SVC
some_digit = X[5]
from sklearn.multiclass import OneVsOneClassifier, OneVsRestClassifier
start = time.time()
ovo_clf = OneVsOneClassifier(SVC())
ovo_clf.fit(X_train, y_train)
print(ovo_clf.predict([some_digit]))
end = time.time()
print(end - start)
print(len(ovo_clf.estimators_))
start = time.time()
ovr_clf = OneVsRestClassifier(SVC())
ovr_clf.fit(X_train, y_train)
print(ovr_clf.predict([some_digit]))
end = time.time()
print(end - start)
print(len(ovr_clf.estimators_))
[2]
156.24309158325195
45
[2]
1002.182160139084
10
可以看到OvR确实耗时更多。
错误分析
假设已经选好了模型,现在想要提升它的效果,那么方法之一就是分析模型中存在什么错误,予以解决。
假设我们使用一个SGD模型,先做一个简单的缩放,可以看到准确率提升了一些:
from sklearn.linear_model import SGDClassifier
from sklearn.model_selection import cross_val_score
sgd_clf = SGDClassifier()
sgd_clf.fit(X_train, y_train)
print(cross_val_score(sgd_clf, X_train, y_train, cv=3, scoring="accuracy"))
# [0.88735 0.83815 0.8769 ]
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
X_train_scaled = scaler.fit_transform(X_train.astype(np.float64))
print(cross_val_score(sgd_clf, X_train_scaled, y_train, cv=3, scoring="accuracy"))
# [0.89565 0.89795 0.9003 ]
查看混淆矩阵
from sklearn.linear_model import SGDClassifier
from sklearn.preprocessing import StandardScaler
from sklearn.model_selection import cross_val_score, cross_val_predict
from sklearn.metrics import confusion_matrix
sgd_clf = SGDClassifier()
scaler = StandardScaler()
X_train_scaled = scaler.fit_transform(X_train.astype(np.float64))
y_train_pred = cross_val_predict(sgd_clf, X_train_scaled, y_train, cv=3)
conf_mx = confusion_matrix(y_train, y_train_pred)
print(conf_mx)
plt.matshow(conf_mx, cmap=plt.cm.gray)
plt.show()
[[5597 0 21 7 9 50 37 6 195 1]
[ 0 6405 38 27 4 46 4 8 195 15]
[ 27 27 5262 98 70 28 68 38 330 10]
[ 24 17 118 5265 2 220 25 42 347 71]
[ 12 14 47 12 5225 11 39 27 281 174]
[ 29 16 31 181 54 4514 74 17 440 65]
[ 30 15 46 3 44 95 5561 5 118 1]
[ 20 10 53 34 52 13 3 5710 149 221]
[ 19 63 45 92 3 130 28 11 5412 48]
[ 24 18 30 69 121 38 1 180 288 5180]]
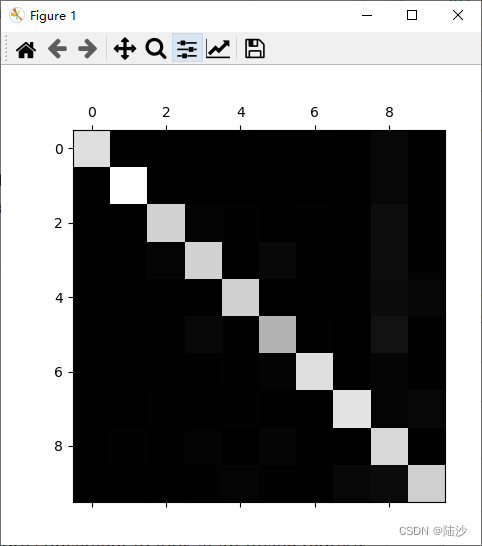
从上图可以看出,主对角线是浅色的,说明很多图像都是分对了。但是主对角线上一些区域是浅灰色的,应该考虑是图像较少或者分类效果不佳,下面通过一些方法区分这两种情况:
首先将混淆矩阵中的每个数据除以对应的类实例个数
# 按行求和,并且保持原有维度不变
row_sums = conf_mx.sum(axis=1, keepdims=True)
norm_conf_max = conf_mx / row_sums
# 把主对角线设为0,所以主对角线变暗,只关注错误的情况
np.fill_diagonal(norm_conf_max, 0)
plt.matshow(norm_conf_max, cmap=plt.cm.gray)
plt.show()

在上图中,行表示真实的分类,列表示预测的分类。由8号列颜色浅可以看出,许多图都被错误地分类到8了。所以应该努力减少分类错误的8,比如增加一些看起来像8但实际不是8的实例,或者增加一些特性(比如计算图中的封闭环数目,因为8有2个,6有1个,5没有),或者对图像做一些预处理,让某些特征更明显(比如前面说的封闭环)。
另外3和5也有较明显的浅色块,那是因为SGD算法给了每个像素每类一个权重,有新图像进来的时候SGD会计算权重和。因为某些3和5的图只在少量像素处有区别的话,模型就很容易搞混。而且如果某个3的图像顶部有连笔,并且连笔向左偏的话,就更容易搞错了。因此,还可以在图像预处理阶段将图像居中、摆正。
多标签分类
multilabel classification:比如相册的人物标注问题。一张图片里有多个人像,所以要输出一组标签。
some_digit = X[5]
print(y_train[5])
from sklearn.neighbors import KNeighborsClassifier
# 形成一行[True,False..] 长度与y_train相等
y_train_large = (y_train >= 7)
# 同理,判断y_train中每个元素是否是奇数
y_train_odd = (y_train % 2 == 1)
# np.c_将两列合在一起,组成一个二维数组,其中每个元素的第一位表示是否>=7,第二位表示是否为奇数
y_multi_label = np.c_[y_train_large, y_train_odd]
# 支持多标签
knn_clf = KNeighborsClassifier()
knn_clf.fit(X_train, y_multi_label)
print(knn_clf.predict([some_digit]))
y_train_knn_pred = cross_val_predict(knn_clf, X_train, y_multi_label, cv=3)
print(f1_score(y_multi_label, y_train_knn_pred, average="macro"))
2
[[False False]]
0.976410265560605
此时,每个标签的权重是一样大的,如果希望每个标签有不一样的权重:
print(f1_score(y_multi_label, y_train_knn_pred, average="weighted"))
0.9778357403921755
多输出分类
multioutput classification:输出的标签可能有多个,每个标签也可能有多个类。比如从图片中去掉噪点的任务:输入一张有噪点的图片,输出一张“干净”的图像,其中包含很多个像素点,每个点的取值范围是0~255。
from sklearn.neighbors import KNeighborsClassifier
knn_clf = KNeighborsClassifier()
# 添加随机噪声
noise = np.random.randint(0, 100, (len(X_train), 784))
X_train_mod = X_train + noise
noise = np.random.randint(0, 100, (len(X_test), 784))
X_test_mod = X_test + noise
y_train_mod = X_train
y_test_mod = X_test
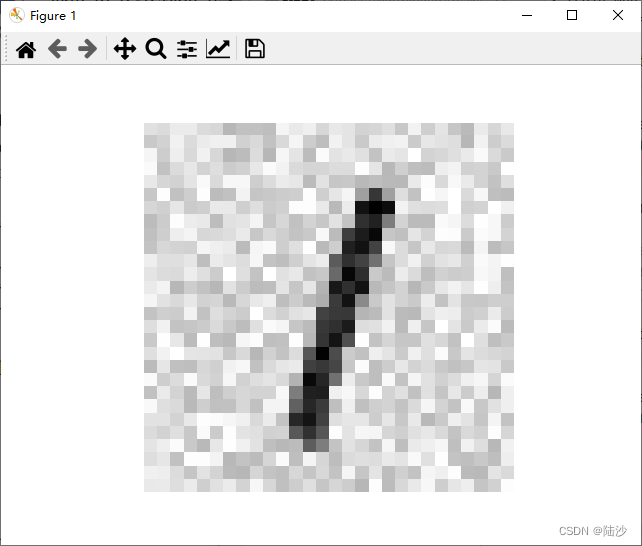
# 绘制有噪声的图像,即输入
some_digit_image = X_test_mod[5].reshape(28, 28)
plt.imshow(some_digit_image, cmap="binary")
plt.axis("off")
plt.show()
# 模型拟合、预测
knn_clf.fit(X_train_mod, y_train_mod)
clean_dit = knn_clf.predict([X_test_mod[5]])
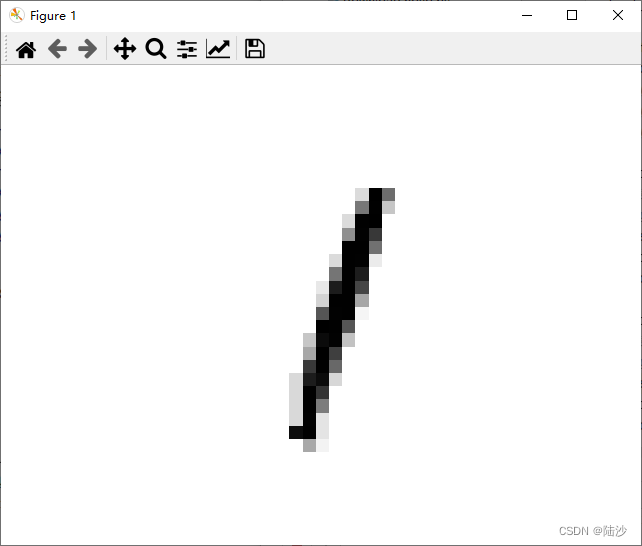
# 绘制输出图像
some_digit_image = clean_dit.reshape(28, 28)
plt.imshow(some_digit_image, cmap="binary")
plt.axis("off")
plt.show()