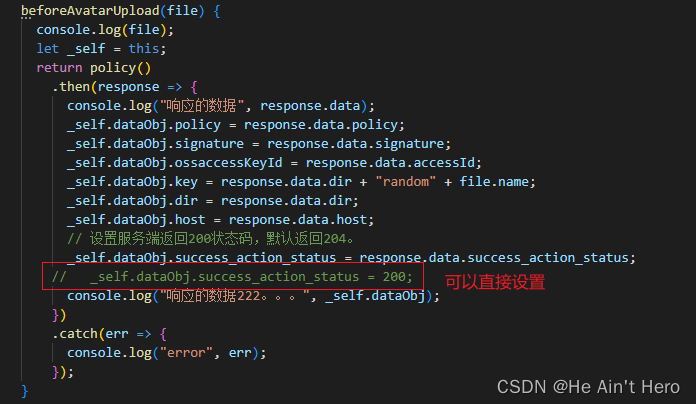
一次完整的HTTP请求所经历的步骤
1:首先进行DNS域名解析(本地浏览器缓存,操作系统缓存或者DNS服务器),首先会搜索浏览器自身的DNS缓存(缓存时间比较短,大概只有1分钟,且只能容纳1000条缓存)
如果浏览器自身的缓存里面没有找到,那么浏览器会搜索系统自身的DNS缓存
如果还没有找到,那么尝试从hosts文件里面去找
在前面三个过程都没有获取到的情况下,就去域名服务器查找
2:三次握手建立TCP连接
在HTTP工作开始之前,客户端首先要通过网络与服务器建立连接,HTTP连接是通过TCP来完成的。HTTP是比TCP更高层次的应用层协议,根据规则,只有低层协议建立之后,才能进行高层协议的连接,因此首先要建立TCP连接,一般TCP连接的端口是80
3:客户端发起HTTP请求
4:服务器响应HTTP请求
5:客户端解析html代码,并请求html代码中的资源
浏览器拿到html文件后,就开始解析其中的html代码,遇到js/css/image等静态资源时,就向服务器端去请求下载
6:客户端渲染展示内容
7:关闭TCP连接
一般情况下,一旦服务器向客户端返回了请求数据,它就要关闭TCP连接,然后如果客户端或者服务器在其头信息加入了Connection:keep-alive,TCP连接在发送后将仍然保持打开状态,于是客户端可以继续通过相同的连接发送请求。即3-6步骤可以反复进行。保持连接节省了为每个请求建立连接所需的时间,节约了网络带宽。
RPC(Remote Procedure Call 远程过程调用),是一种通过网络从远程计算机程序上请求服务,而不需要了解底层网络的技术
一次完整的RPC同步调用流程
1:服务消费方(client)以本地调用方式调用客户端存根
2:客户端存根:远程方法在本地模拟对象,一样的也有方法名,方法参数client stub接收到调用后负责将方法名,方法参数等包装,并将包装后的信息通过网络发送到服务端
3:服务端收到消息后,交给代理存根在服务器的部分后进行解码为实际的方法名和参数
4:server stub根据解码结果调用服务器上本地的实际服务
5:本地服务执行并将结果返回给server stub
6:server stub将返回结果打包成消息并发送至消费方
7:client stub接收到消息,并进行解码
8:服务消费方得到最终结果
RPC框架的目标就是要中间步骤都封装起来。让远程方法调用的时候感觉到就像在本地调用一样
Dubbo是一个典型的RPC运用
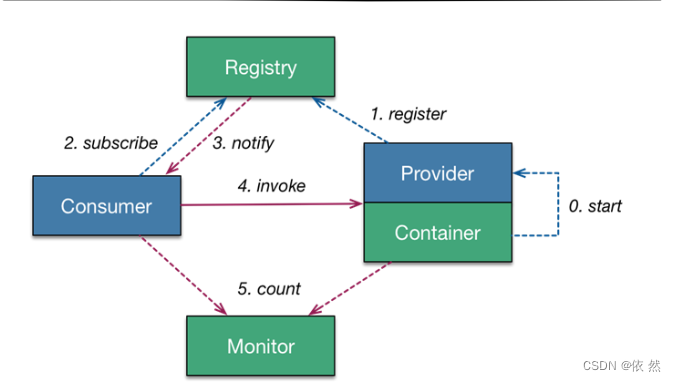
服务容器负责启动,加载,运行服务提供者
服务提供者在启动时,向注册中心注册自己提供的服务
服务消费者在启动时,向注册中心订阅自己所需的服务
注册中心返回服务提供者地址列表给消费者,如果有变更注册中心将基于长连接推送变更数据给消费者
服务消费者从提供者地址列中,基于负载均衡算法,选一台提供者进行调用,如果调用失败,再选另一条调用
服务消费者和提供者,在内存中累计调用次数和调用时间,定时每分钟发送一次统计数据到监控中心