现实生活中的很多应用场景都需要涉及到三维信息。针对三维视觉技术应用场景复杂多样、三维感知任务众多、流程复杂等问题,飞桨为开发者提供了低成本的深度信息搜集方案 PaddleDepth 以及面向自动驾驶三维感知的全流程开发套件 Paddle3D 。

三维视觉技术应用场景
3D 视觉是近年来十分流行的概念。它着力于让计算机模仿人类大脑,对传感器采集到的数据进行理解和分析。以往我们做的二维视觉任务更多是对摄像头采集的彩色图像信息进行理解和分析,但现实生活中,很多场景需要三维信息,因此三维视觉任务应运而生。

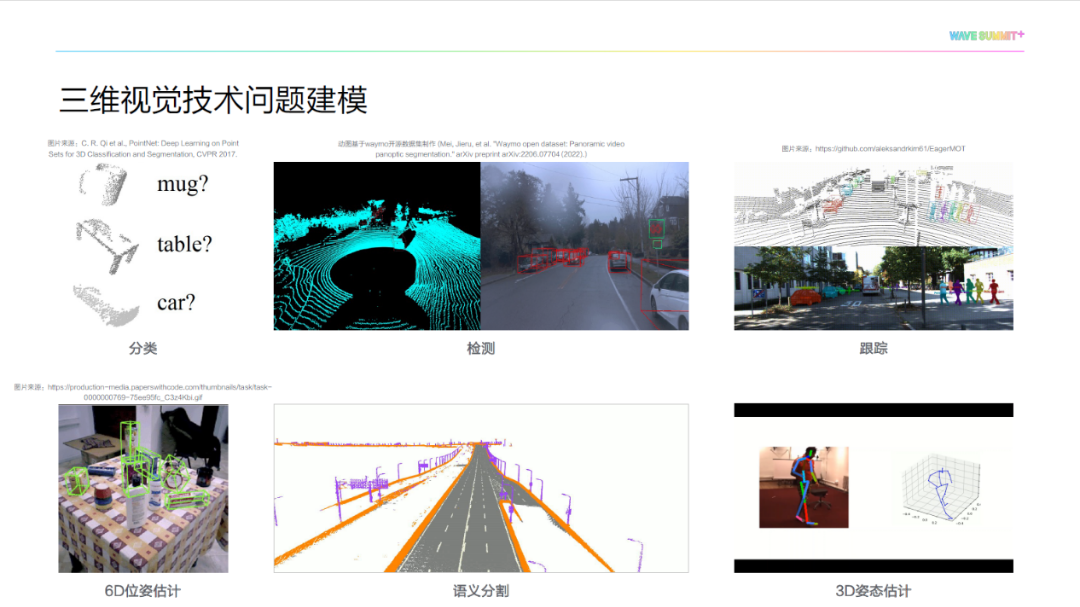
如下图所示,从展示的三维视觉技术应用场景可以看到,三维视觉技术在智能制造、智能无人系统、智能医疗等领域有极大的应用价值。

根据三维视觉技术应用场景,我们需要对问题进行针对性建模。例如,对于智能体育场景,需要通过 3D 姿态估计技术对运动员姿态量化分析。在自动驾驶场景下,需要通过 3D 目标检测和跟踪技术实时检测无人车旁边的车辆。
综上所述,三维视觉任务所要面对的主要场景复杂多变,我们需要针对具体业务场景选取合适的传感器,并根据采集的数据确定任务的具体建模方式。由此,我们发现了目前三维视觉技术落地需要解决的两大核心问题。

三维视觉应用难点及方案
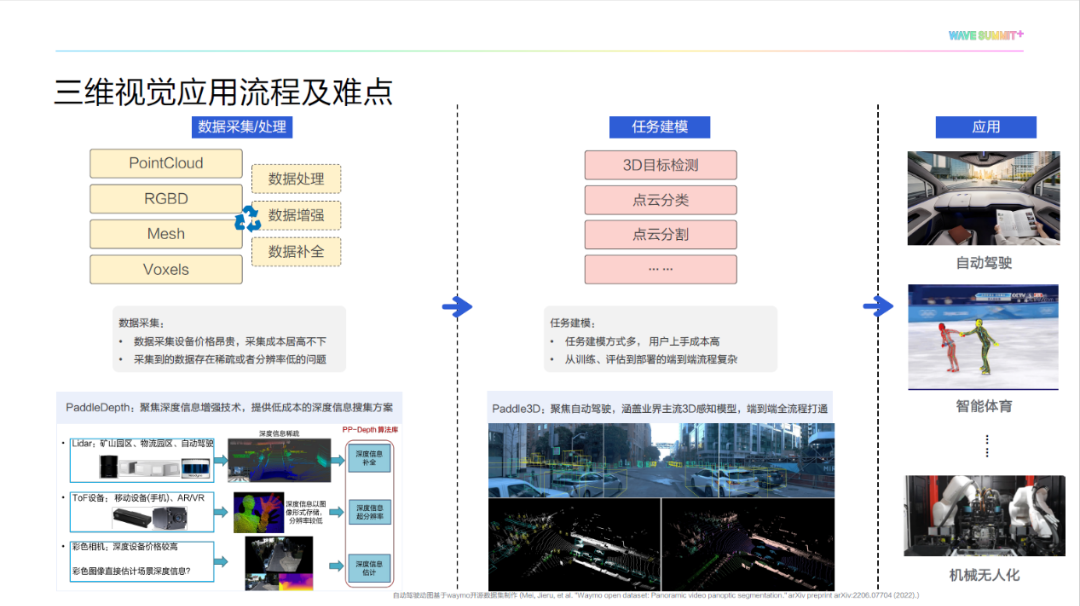
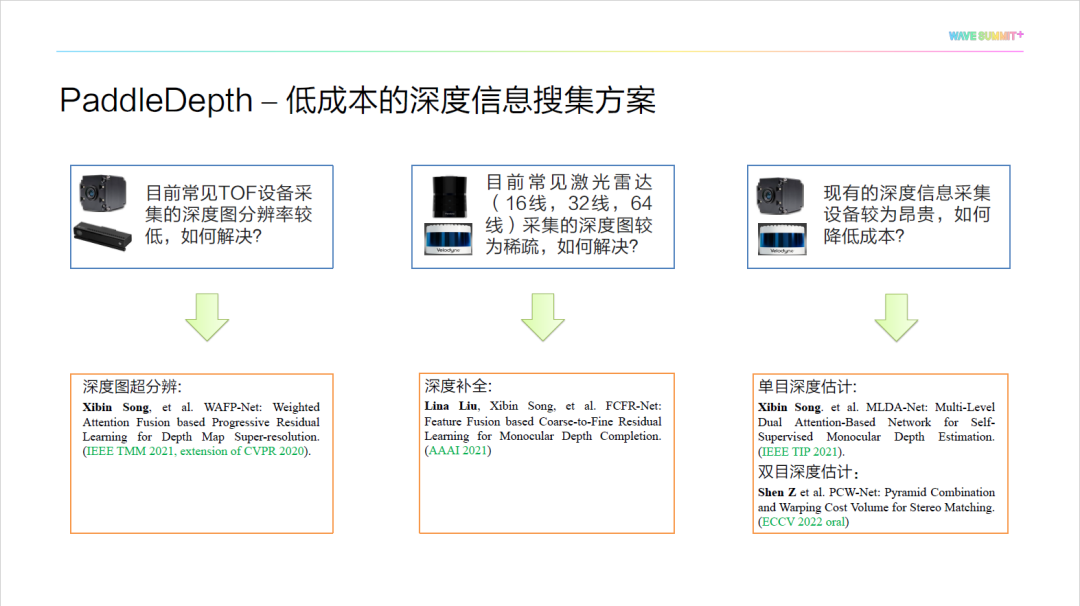
在数据采集上,现有三维数据采集设备存在价格昂贵、采集到的数据存在稀疏或者分辨率低等问题。针对这些问题,我们提出了飞桨深度增强开发套件 PaddleDepth 。目前,常用的深度信息采集设备分为激光雷达和 ToF (Time of Flight)设备。其中,激光雷达常应用于室外场景,它采集的深度信息较为稀疏,无法进行稠密三维重建,因此需要对深度信息进行补全。而ToF设备常应用于室内场景,它采集的深度信息一般以图像形式储存,分辨率较低,因此需要对深度信息进行超分操作。此外,现有的深度设备价格较高,极大限制了其在真实场景中的应用范围。因此我们考虑从彩色图像直接估计场景的深度信息,从而大幅度降低获取深度信息的成本,即深度信息估计。我们在飞桨深度增强开发套件 PaddleDepth 开源了深度信息增强技术,其可以提供一个低成本的深度信息收集方案。
在 3D 感知领域,训练、评估到部署的端到端流程非常复杂,基于此,飞桨提出了 Paddle3D ,其聚焦于 3D 感知领域,涵盖了大量的 3D 感知模型,并提供了从训练、评估到部署的全流程教程,以降低用户开发成本。

飞桨深度增强开发套件——PaddleDepth
如下图所示, PaddleDepth 旨在打造一个低成本的深度信息搜集方案,实现深度信息补全、深度信息超分辨和深度信息估计这三类深度信息增强技术的全覆盖。目前 PaddleDepth 共包含 10+ 前沿模型以及 4+ 首次开源的自研算法。

在技术影响力方面, PaddleDepth 所提出的深度信息补全、超分辨率、单/双目深度估计自研算法在各公开数据集中均达到 SOTA 的性能。

在开源数据集 KITTI 上, PaddleDepth 在自监督单目深度信息估计、有监督双目深度信息估计任务以及深度信息补全任务上均排名第一。在 Middlebury 数据集上, PaddleDepth 在深度超分辨率任务上排名第一,并在 ECCV2020 Robust Vision Challenge Stereo Matching task 上获得冠军,其深度信息增强技术业界领先。
以下是效果展示:
深度信息补全结果展示
相比于直接通过激光雷达得到稀疏深度图,通过深度信息补全,用户能够得到稠密的深度估计结果,更好地进行三维重建。

深度补全结果

补全后点云重建结果
深度图超分辨结果展示
通过深度图像超分辨,用户能够得到更稠密的三维重建结果。

左:超分辨率结果 右:原始点云结果
单目深度估计结果展示
通过单目深度估计,用户能够通过单张图片重建原始物体的三维信息。

单目深度估计结果

单目深度估计点云重建结果
双目深度估计结果展示
通过双目测距原理,用户能够更好地重建原始物体的三维信息。

双目深度估计结果

双目深度估计点云重建结果
如下图所示,通过三维重建结果对比,上述方法都能够得到较为合理的三维重建结果。其中深度补全和双目深度估计,通过激光雷达的输入和对局约束得到的结果更为准确。

PaddleDepth-点云重建结果展示
综上所述,针对现有三维信息采集设备的局限性,我们提出了飞桨 PaddleDepth ,以提供一个低成本的深度信息搜集方案。
-
通过深度图超分辨,主要用于解决采集的深度图像分辨率较低的问题;
-
通过深度补全,主要用于解决采集的深度图像稀疏的问题;
-
通过对输入彩色图像直接进行深度估计,用户可以进一步降低三维信息搜集成本。

飞桨三维感知开发套件—Paddle3D
前面提到三维感知开发任务的一个难点就是任务众多、流程复杂,基于这样的背景我们设计并开发了飞桨三维感知开发套件 Paddle3D 。
下图是 Paddle3D 整体的架构图,最底层是框架层,基于飞桨的核心框架进行开发。在飞桨框架之上我们提供了一些基础工具,包括常见数据集的集成和特定 3D 领域算子等。再往上是算法层,包括不同类别的算法。最上层是工具层,集成了飞桨的其他工具。
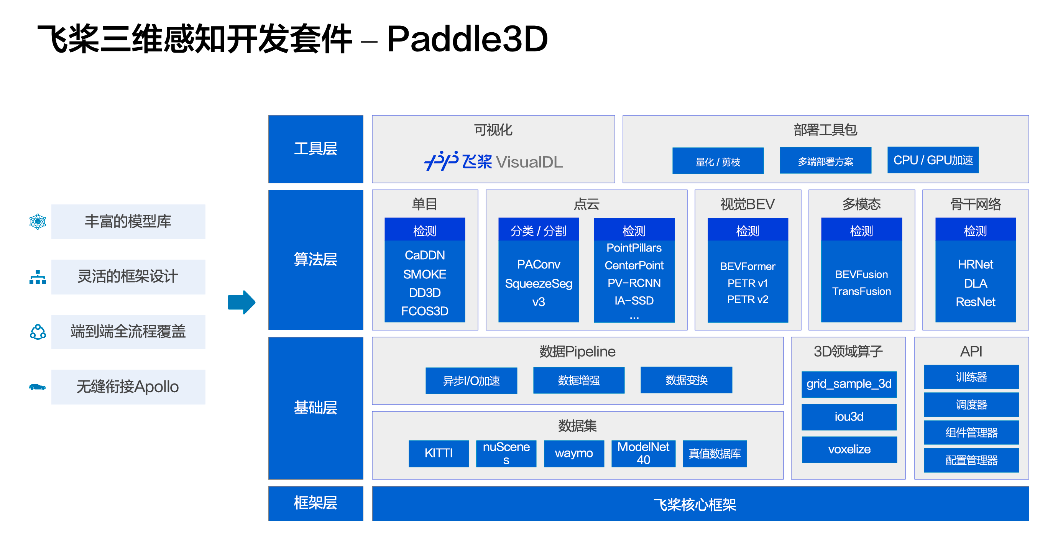
Paddle3D 具有四个特点,包括丰富的模型库、灵活的框架设计、端到端全流程覆盖、部署时无缝衔接 Apollo 。
丰富的模型库
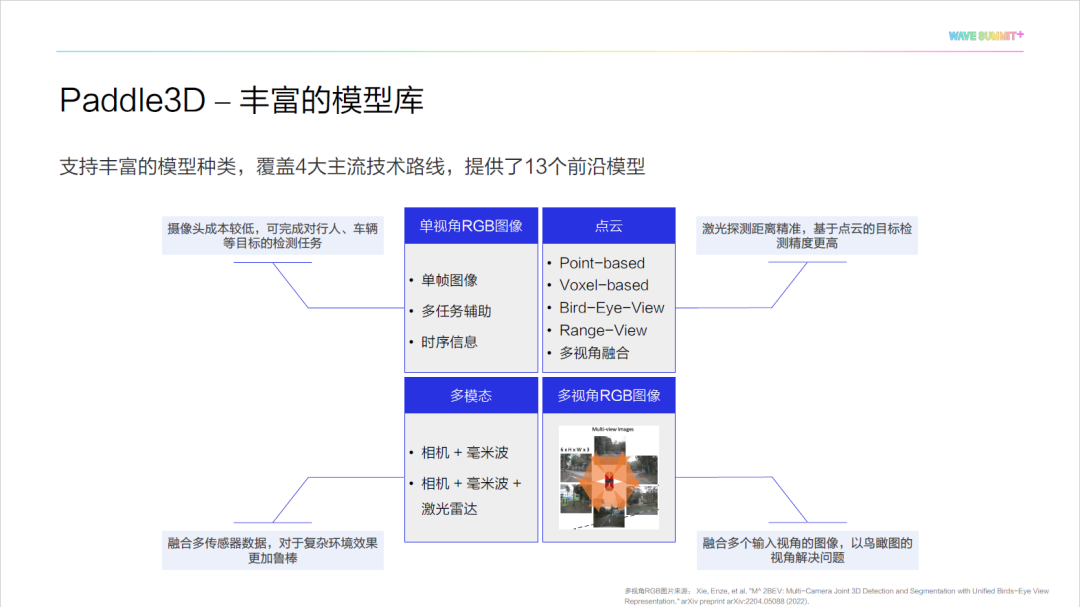
Paddle3D 涵盖了许多不同方向的前沿经典模型。比如基于单个相机进行的单目3D检测任务中的经典模型,如 SMOKE、CaDDN 等,这类方法的优点是摄像头成本较低、成本可控。Paddle3D 还集成了基于激光雷达的目标检测模型,即点云检测模型,如 PointPillars 、 IA-SSD 等,这类方法的优点是点云数据具有三维信息,基于点云的三维目标检测比单目 3D 的精度更高。Paddle3D 支持多模态模型,这类方法的优点是融合不同模态数据的优点,具有更好的鲁棒性。此外, Paddle3D 还支持目前比较火的多视角检测任务模型,如 BEVFormer、PETR 等。用户可以根据自己实际场景,选择合适的模型进行验证。
在基于点云的 3D 检测任务中,经常遇到的问题是显存与计算量都很大。为了避免这些问题,许多方法在模型结构上做了调整,将特征从三维空间映射到二维空间,来减少模型对显存的消耗,但是带来的另一个问题是模型的精度有所降低。针对这个问题,飞桨提供的解决方案是稀疏卷积 SparseConv ,它通过规则表减少无效计算,进而解决显存跟计算量的问题。
飞桨框架 2.4 版本已经提供了相关的能力, Paddle3D 中也集成了许多使用 SparseConv 的前沿模型,比如 PV-RCNN 、 Voxel R-CNN 等。
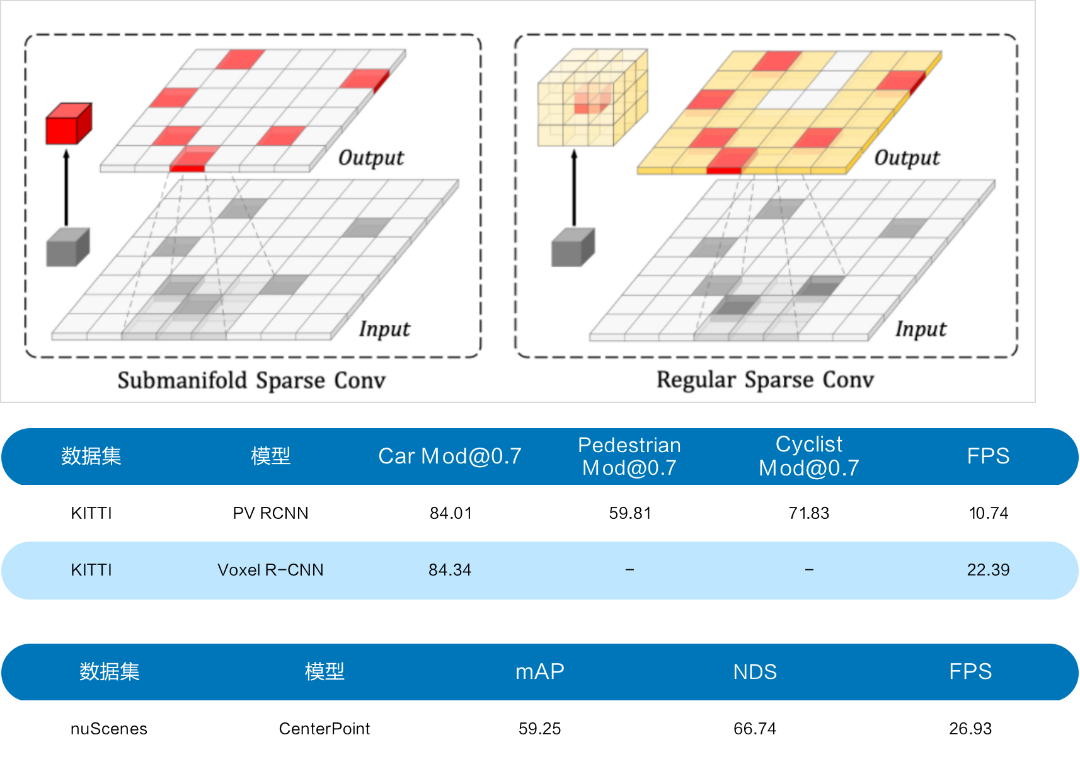
可以在上图看到列出的模型精度和速度指标,效果都非常好
灵活的框架设计
Paddle3D 的框架设计能够满足不同用户的诉求,对于需要将 Paddle3D 集成到特定任务的用户来说,可以基于飞桨提供的 API 进行快速的二次开发。
如下图所示,以模型训练为例,飞桨通过 6 个 API 快速完成模型组网、数据集加载、优化器定义等,然后启动训练功能。对于不需要进行二次开发的用户来说,使用飞桨提供的配置文件来配置不同组件,然后通过命令行工具,即可一键启动训练。
1. 六个API完成模型训练,满足二次开发或者集成需求
-
指定训练数据集
train_dataset = KittiMonoDataset(
dataset_root='datasets/KITTI’, mode='train‘,
transforms=[
T.LoadImage(reader='pillow', to_chw=False), T.Gt2SmokeTarget(mode='train', num_classes=3),
T.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])])-
定义模型
model = SMOKE(
backbone=DLA34(),
head=SMOKEPredictor(num_classes=3),
depth_ref=[28.01, 16.32],
dim_ref=[[3.88, 1.63, 1.53], [1.78, 1.70, 0.58], [0.88, 1.73, 0.67]])-
学习率更新策略
lr_scheduler = paddle.optimizer.lr.MultiStepDecay(
milestones=[36000, 55000],
learning_rate=1.25e-4)-
定义优化器
optimizer = paddle.optimizer.Adam(
learning_rate=lr_scheduler,
parameters=model.parameters())-
指定训练器
trainer = Trainer(
model=model,
optimizer=optimizer,
iters=20,
train_dataset=train_dataset)-
启动训练
trainer.train()2.配置化简易训练成本,一行命令启动训练
batch_size: 8
iters: 70000
train_dataset:
type: KittiMonoDataset
dataset_root: datasets/KITTI
transforms:
- type: LoadImage
reader: pillow
to_chw: False
- type: Normalize
mean: [0.485, 0.456, 0.406]
std: [0.229, 0.224, 0.225]
lr_scheduler:
type: MultiStepDecay
milestones: [36000, 55000]
learning_rate: 1.25e-4
optimizer:
type: Adampython tools/train.py --config configs/smoke/smoke_dla34_no_dcn_kitti.yml --iters 20 --log_interval 1 --num_worker 5
端到端全流程覆盖
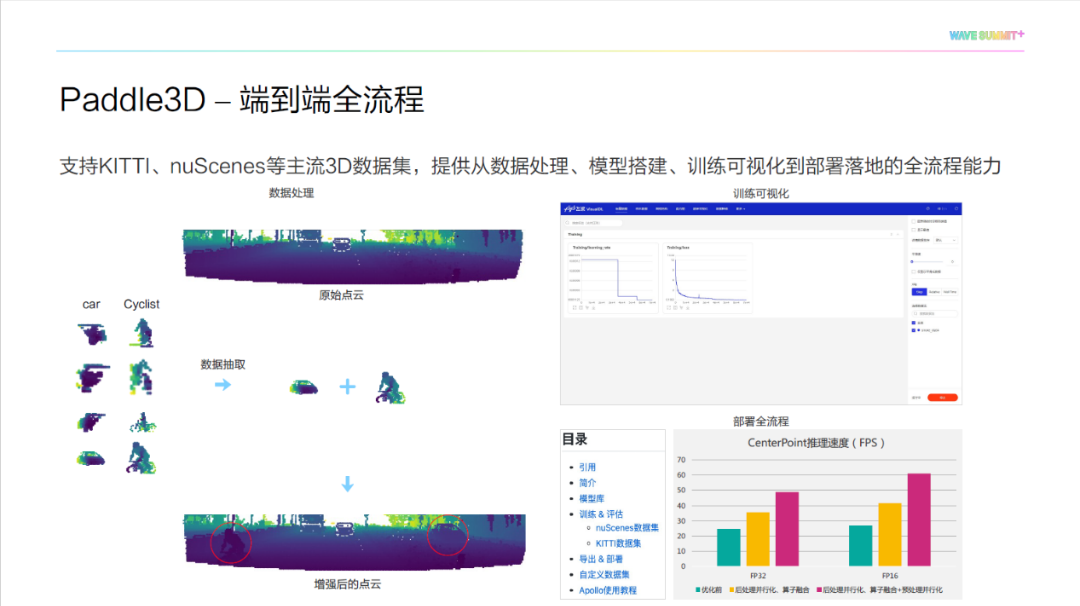
从数据准备开始,针对数据库生成的脚本,飞桨提供了对于点云数据的使用接口。在训练过程中,飞桨集成了 VisualDL ,可以实时地查看训练过程中的指标。在最后的模型部署部分,提供了完整详细的教程和部署脚本,以及对模型推理性能的极致优化。
无缝衔接Apollo
基于 Paddle3D 感知模型的开发流程完成 Paddle3D 训练模型后,将模型放到 Apollo 项目中,替换原有感知模型,调用相关感知接口,就可以启动自动驾驶前端软件 DreamView 查看模型的预测效果。
支持模型效果快速验证、多模态模型高性能融合,实现自动驾驶全栈式技术方案的高效搭建。
 基于Paddle3D的感知模型开发流程
基于Paddle3D的感知模型开发流程

综上所述,飞桨可以解决在三维感知任务中存在的两个难点。
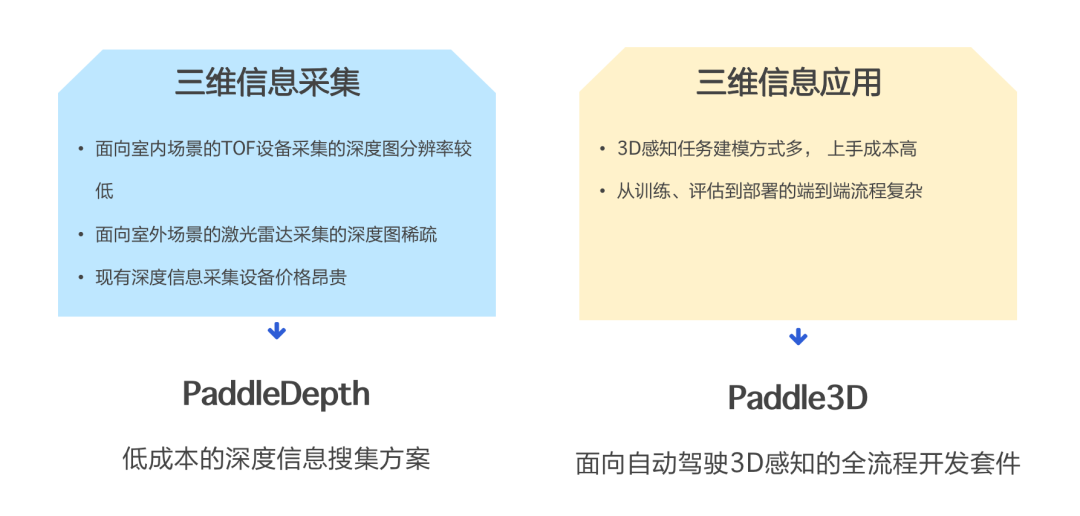
-
三维数据采集。比如数据采集设备价格昂贵、设备采集数据分辨率较低、激光雷达采集的深度图稀疏等,飞桨 PaddleDepth 为开发者提供了一个低成本的深度信息搜集方案。
-
三维信息应用。该方向的难点包括任务建模型方式多,上手成本高等。飞桨 Paddle3D 为开发者提供了一个 3D 感知方向的全流程开发方案,涵盖了大量的 3D 感知模型,并提供了从训练、评估到部署的全流程教程,用户可以快速进行效果验证。