编译,链接,全过程。
- 背景知识
- 预处理:
- 1.宏定义指令,如#define MAX 1;
- 2.条件编译指令,如#ifdef、 #ifndef、#else、#elif、#endif等。
- 3.头文件包含指令,如#include等。
- 4.特殊符号,预编译程序可以识别一些特殊的符号。
- 编译:
- 1.词法分析:
- 2.语法分析
- 3语义分析
- 4.中间语言生成
- 5.目标代码生成与优化
- 汇编:
- 链接:
- 两步链接:
- 1.空间与地址分配
- 2.符号解析与重定位
背景知识
ELF文件类型
| ELF文件类型 | 说明 | 实例 |
|---|---|---|
| 可重定位文件 | 这类文件包含了代码和数据,可以被用来链接成可执行文件或共享目标文件,静态链接库也可以归为这一类 | Linux的.o,Windows的.obj |
| 可执行文件 | 可以执行的程序 | Linux的/bin/bash Windows的.exe |
| 共享目标文件 | 这种文件包含了代码和数据,1.链接器可以使用这种文件与其它可重定位文件和共享目标文件链接,产生新的目标文件,2.动态连接器可以将这几个这种共享目标文件与可执行文件结合,作为进程映像的一部分来运行 | Linux的.so,Windows的DLL |
| 核心转储文件 | 当进程意外终止,系统可以将该进程的地址空间的内容急终止的一些其它信息转储到核心转储文件 | Linux 下的core dump |
编译器和汇编器生成可重定位目标文件(包括共享目标文件),链接器生成可执行目标文件。
目标文件:源代码编译后但未进行链接的中间文件,它与可执行文件的格式几乎是一样的。不仅如此动态链接库(Linux的.so和Windows的.dll)和静态链接库(Linux的.a和Windows的.lib)格式都是一样的。在Window按照PE-COFF,LInux下按照ELF存储。
现在PC流行的可执行文件格式主要是Windows下的PE和Linux下的ELF,它们都是COFF格式的变种
ELF可重定位文件

- .text:已编译程序的机器代码
- .rodata:只读数据
- .data:已初始化的全局变量和静态变量
- .bss未初始化的全局变量和静态变量
- .symtab:一个符号表,它存放程序中定义和引用的函数和全局变量的信息。(和编译器中的符号表不同,它不存放局部变量的信息)
- .rel.text: .text的重定位表
- .rel.data:.data的重定位表
- .debug:调试符号表,只有以-g选项调用编译器编译时,才会得到这种表
- .line:源程序中行号和.text节中机器指令之间的映射,只有以-g调用编译器时,才会得到这张表。
- .strtab:一个字符串表,内容包括.symtab和.debug节中的符号表,以及节头部中的节名字。
符号表:
符号表中每个条目的格式
typedef struct {
int name;
char type : 4,
binding : 4;
char reserved;
short section;
long value;
long size;
}Elf64_Symbol;
name:字符串表中的字节偏移
size:目标大小
value是符号的地址(决对运行时地址)
type:要么是函数,要么是数据
binging字段表示符号是本地还是全局的。
每个符号都被分配到目标文件的某个节,由section字段表示,该字段也是一个到一个节头部表的索引,有三个特殊的伪节,它们在节头部表中是没有条目的,
- ABS代表不该被重定位的符号
- UNDEF代表未定义的符号(在其它模块定义,在本模块引用)
- COMMON表示还未被分配位置的未初始化的数据目标。
对于COMMON符号,value字段给出对齐要求,而size给出最小的大小。
只有可重定位目标文件中才有这些伪节,可执行目标文件中是没有的。
COMMON与bss区别
COMMOE 未初始化的全局变量
.bss未初始化的静态变量,以及初始化为0的全局或静态变量。
预处理:
处理以"#"开始的预编译指令
1.宏定义指令,如#define MAX 1;
对于这种伪指令,预编译所要做的是将程序中的所有M用1来替换,一定要注意作为字符常量MAX则不被替换(因为已经是常量,其值已经是确定的)。与之相对应的还有#undef,则是将取消对某个宏的定义,使之在后面出现时再不被替换。
2.条件编译指令,如#ifdef、 #ifndef、#else、#elif、#endif等。
这些伪指令的引入使得程序员可以通过定义不同的宏来决定编译程序对哪些代码进行处理。换言而之也就是预编译程序将根据有关的文件,将哪些不必要的代码过滤掉。
3.头文件包含指令,如#include等。
把引用的头文件在引用点展开
4.特殊符号,预编译程序可以识别一些特殊的符号。
例如,在源程序中出现的LINE标识符将被解释为当前行号(十进制),FILE则被解释为当前被编译的C源程序的文件名称,FUNCTION则被解释为当前被编译的C源程序中的函数名称。
编译:
我们通过对下面这行代码进行举例来帮助理解
array[index] =(index+4)*(2+6);
1.词法分析:
源程序先被输入到扫描器中,将源代码的字符序列分割成一系列的记号(lex的程序(一种扫描器)可以实现词法扫描,它会按照用户之前描述好的词法规则将输入的字符创分割成一个个记号
符号分为:关键字,标识符,字面量(数据,字符串),特殊符合
而这行代码进行扫描后就产生了16个记号。
| 记号 | 类型 |
|---|---|
| array | 标识符 |
| [ | 左方括号 |
| index | 标识符 |
| ] | 右方括号 |
| = | 赋值 |
| ( | 左圆括号 |
| index | 标识符 |
| + | 加号 |
| 4 | 数字 |
| ) | 右圆括号 |
| * | 乘号 |
| ( | 左圆括号 |
| 2 | 数字 |
| + | 加号 |
| 6 | 数字 |
| ) | 右圆括号 |
2.语法分析
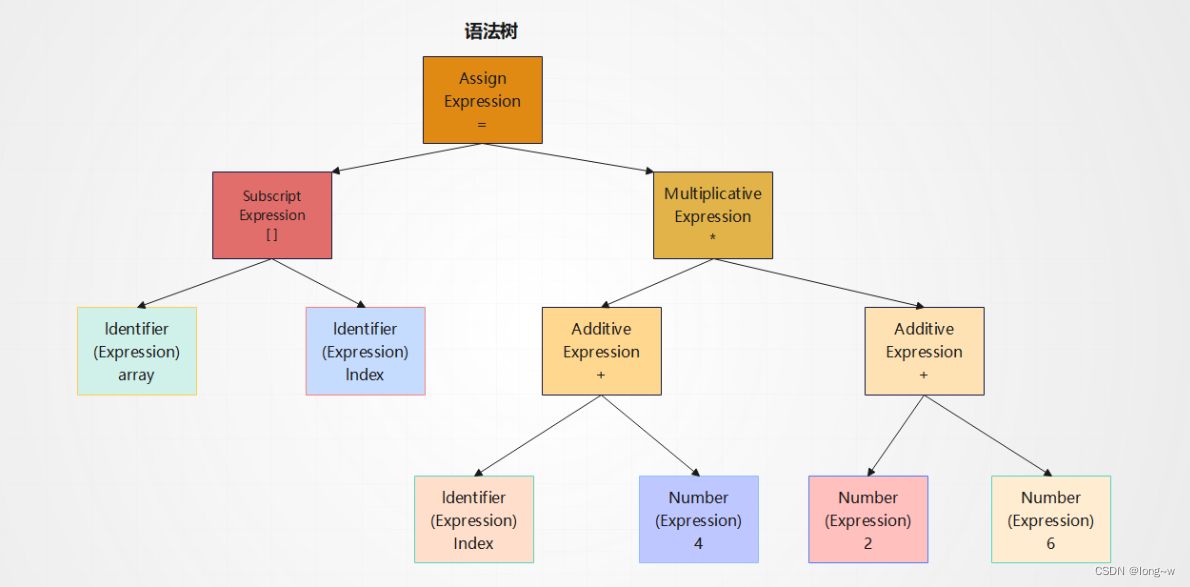
语法分析器将对由扫描器产生的记号进行语法分析(采用上下文无关语法),从而产生语法树(以表达式为节点的树),(yacc(一种语法分析器)可以根据用户给定的语法规则对输入的记号序列进行解析,从而构建一根语法树,对于不同的编程语义,编译器的开发者只需要改变语法规则,而无需为每个编译器编写一个语法分析器,所以它有被称为“编译器编译器 Compiler Compiler”)
我们可以看到,整个语句被看作成一个赋值表达式,赋值表达式的左边是一个数组表达式,它的右边是一个乘法表达式,数组表达式又由两个符号组成。而在语法分析的同时,很多运算的优先级和含义也被确定了下来,同时,如果出现了了表达式不合法,比如各种符号不匹配,表达式缺少操作符,编译器就会报告语法分析阶段的错误。
3语义分析
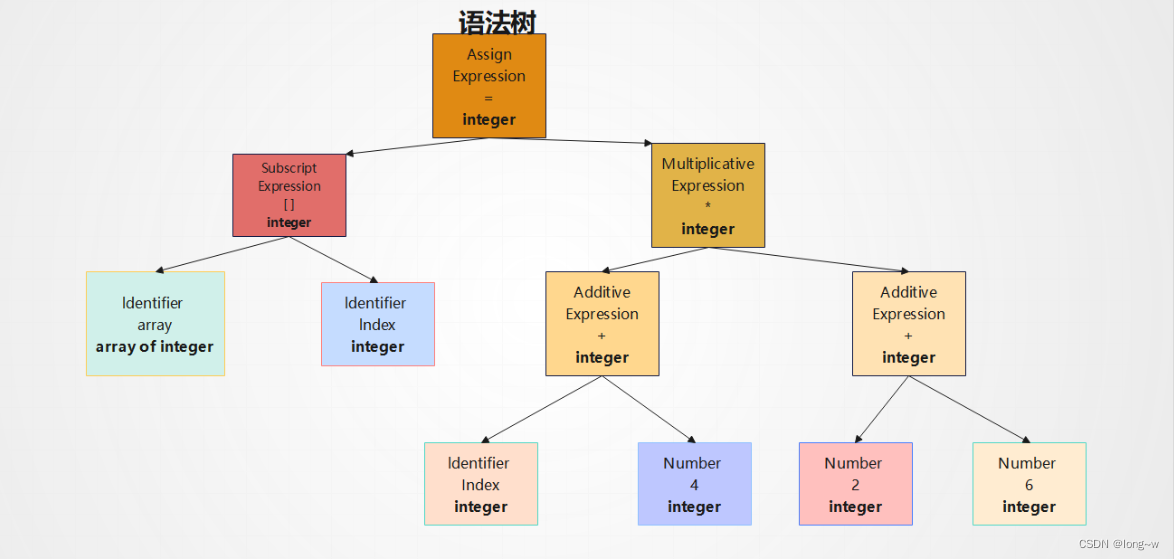
由语义分析器来完成,语法分析仅仅完成了对表达式语法层面的分析,并不了解这个语句是否真正有意义,(不能分析语法的对错,如一根指针和浮点数相乘是否合法),编译器能分析的语义是静态语义,而动态语义只能在运行期才能确定。(如0作为除数是一个运行期语义错误)
静态语义通常包括声名和类型的匹配,类型的转换,如将一个浮点型的表达式给一个整形表达式。
而比如将一个浮点型赋值给一个指针的时候,语义分析程序就会发现这个类型不匹配,编译器就会报错。 而比如将0做为除数是一个运行期语义错误。
经过语义分析后,整个语法树的表达式都被标识了类型,如果有些类型需要做隐式类型转换,语义分析程序就会在语法树中插入相应的转换节点。
4.中间语言生成
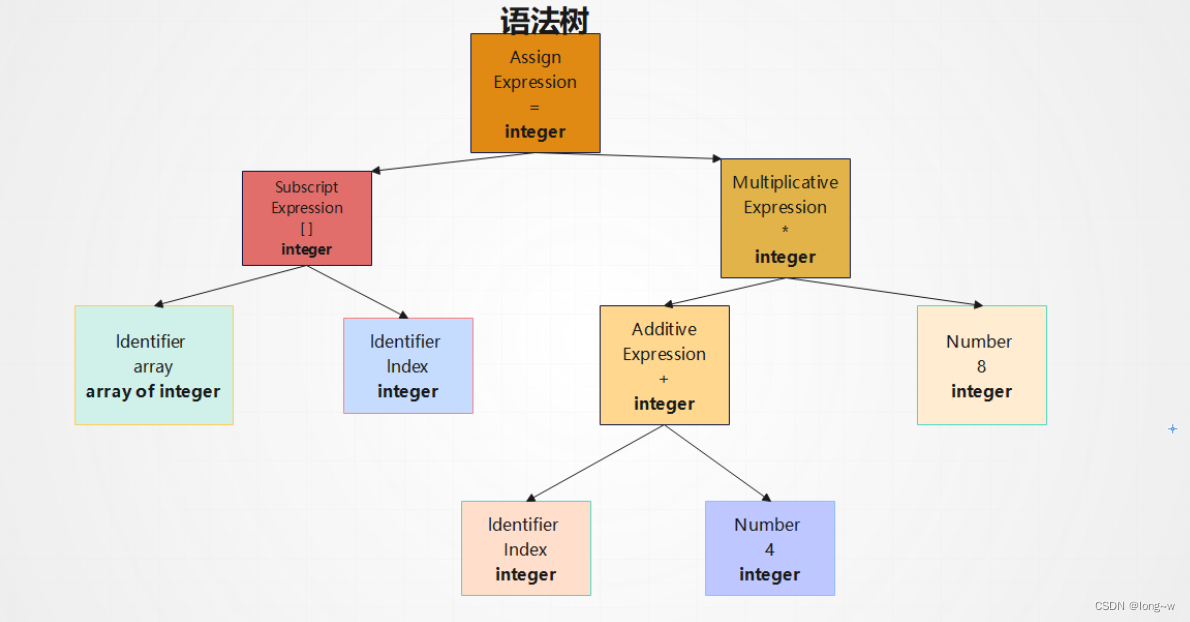
现代编译器通常会对源代码进行优化。
比如说上面的(2+6)就会被优化掉,因为它的值在编译期就可以被确定,所以这个表达式被优化成8,这个在语法树上做优化比较困难,所以源代码往往将语法树转化为中间代码(语法树的顺序表示,十分接近目标代码,但是它不包含数据的尺寸,变量地址,寄存器名字)
中间代码有很多形式(三地址码,P-代码)
中间代码使得编译器可以被分为前端和后端,编译器前端负责产生机器无关的中间代码,编译器后端负责将中间代码转换成目标机器代码,(这样对于一些可以跨平台的编译器,它们可以针对不同的平台使用同一个前端和针对不同机器平台的数个后端)。
5.目标代码生成与优化
源代码优化器产生中间代码标志着下面的过程都属于编译器后端,编译器后端主要包括代码生成器和目标代码优化器,
代码生成器将中间代码转化为目标机器代码,依赖于目标机器,因为不同的机器有着不同的字长,寄存器,整数类型和浮点数类型,
最后目标代码优化器对上述的目标代码进行优化,比如选择合适的寻址方式,使用位移来代替乘法运算,删除多余的指令。
因为现代高级编程语言的复杂性,至今没有一个编译器能够完整的支持c++语言标准所规定的所有语言特性。(所以在编译的时候需要指定它的标准。)
因为现代CPU的复杂性,为了支持这些特性,编译器的机器指令优化过程也十分复杂,
因为有些编译器支持多种硬件平台(如gcc几乎支持所有的CPU平台),即允许编译器编译出多种目标CPU的代码,这也导致编译器的指令生成更为复杂。
汇编:
将汇编代码转变成机器可以执行的指令
生成可重定位的二进制文件;(.obj文件)
此文件中生成符号表,符号表中存放的就是程序所产生的符号(例如:函数名,变量名等),我们的编译阶段是不会去给符号分配地址的。
链接:
对于早期程序来说,如下面的指令
第一条指令0001 0100 (0001xxxx表示跳转指令,这条指令表示跳转到第四条指令 )
第二条指令..................
第三条指令..................
第四条指令1000 0111
当程序修改时,比如对第二条指令进行删除或者在其之前添加指令。而当其一旦修改,第一条指令也要进行修改。(要调转的位置)
而在发展的过程中,汇编语言使用符号来标记位置,如我们把刚才的第四条指令命名为"foo"则第一条指令的汇编就为 jump foo,这个时候就算第一条指令和第四条之间有指令修改了,我们也不需要修改第一条指令了。当这个foo指令之前插入或减少了多少条指令导致foo的地址发送变化,汇编器在每次汇编程序时都会重新计算"foo"这个符号的地址,然后把所有引用都"foo"的指令修正到正确的地址。
这种用符号表明地址的概念在被汇编的使用而被迅速普及 从此函数的起始地址,变量的起始地址也用符号来表示。
而上面讲的重新计算各个符号的地址的过程就是重定位。
比如我们在main.c模块中调用了其它模块的foo函数,但是在编译器编译main.c的时候,编译器并不知道foo函数的地址,它暂时把这些调用foo的指令的目标地址搁置,等到最后链接的时候由连接器进行修正,填入正确的foo地址
在现代的程序中,代码往往有多个模块,而当不同模块之间的函数的调用,符号访问,即模块之间符号的引用,而把不同模板拼接到一起,则就是链接,链接的主要内容就算把各个模块之间引用的部分都处理好,也使得各个模块之间能够正确的链接。
原理:把一些指令对其它符号地址的引用加以修正。
主要过程:地址和空间分配,符号决议,重定位
符号决议有时也叫(符号绑定,名称绑定,名称决议,地址绑定,指令绑定),大体它们的意思都一样,但从细节来区分:决议更倾向于静态链接,绑定更倾向于动态链接,在静态链接中,我们将统一称为符号决议。
对于链接器来说:符号表中有三种不同的符号,
1.由模块m定义并能被其它模块引用的全局符号
2.由其它模块定义并被模块m引用的全局符号(外部符号)
3.只被模块m定义和引用的局部符号(这些符号在模块m中任务位置都可见,但是不能被其它模块引用)。
两步链接:
1.空间与地址分配
扫描所有的输入目标文件,获得它们各个段的长度,属性和位置,并且将输入目标文件中的符号表中所有的符号定义和符号引用收集起来,统一放到一个全局符号表中同时链接器进行相似段合并,并建立映射关系。
相似段合并
把所有输入文件的.text合并到输出文件的.text(.data,.bss都一样)
.bss段在目标文件和可执行文件中并不占用空间,但是它在装载时占用地址空间,所有链接器在链接.bss时,也将它们合并,并且分配虚拟空间。
链接前后各个段的属性

VMA(virtual Memory Address)虚拟地址,LMA(Load Memory Address)加载地址,
我们可以看到在链接前,目标文件中所有段的VMA都是0,因为虚拟空间还没有分配。
下面为链接前后,目标文件各段的分配,程序虚拟地址情况。
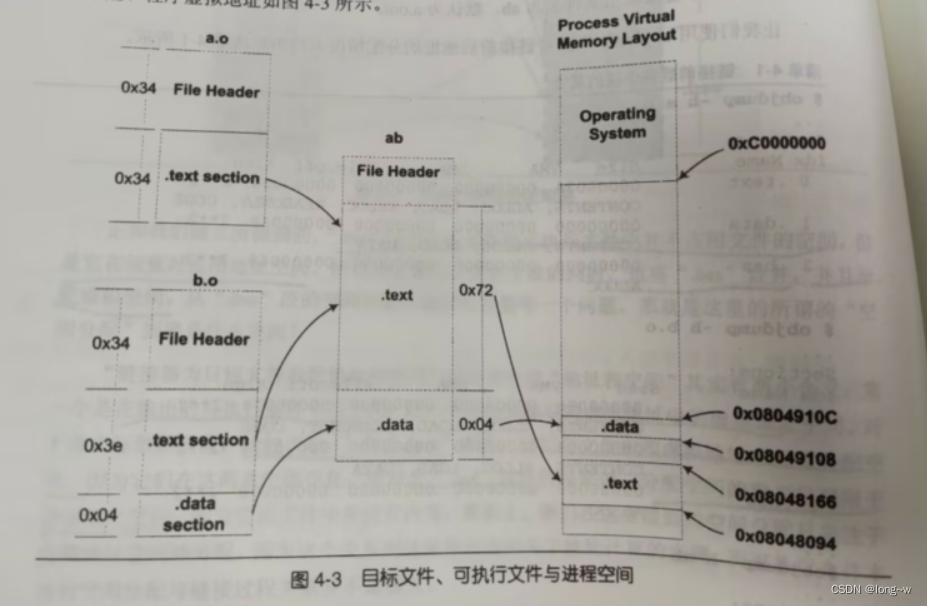
为什么链接器对可执行文件中".text"段分配的时候是从0x08049108,而不是从0开始呐,因为在Linux下,ELF可执行文件默认从地址0x0804800开始分配。
链接器计算各个符号的虚拟地址:
因为各个符号在段内的相对位置是固定的(链接器需要给每个符号加一个偏移,使它们能够调整到正确的位置)
如:a.o的main函数相对于a.o的.text的 偏移是x,经过链接合并后,a.o的.text段位于虚拟地址的0x08048094,但是由因为a.o的main位于.text段的首部,所以x为0,main的地址为0x08048094。
2.符号解析与重定位
符号解析:将每个符号引用正好和一个符号定义关联起来。
当编译器遇到一个不是在当前模块定义的符号,会加上该符号是在其它模块定义,生成一个链接器符号条目,并把它交给链接器处理,链接器就会查找由所有输入目标文件的符号表组成的全局符号表,找到后进行重定位。
重定位:链接器通过重定位表来确定那些指令需要被重定位。通过把每个符号定义与一个内存位置关联起来,从而重定位这些节,然后修改所有对这些符号的引用,使得它们指向这个内存位置。
重定位表:专门来存放这些需要重定位符号的信息。
对于每个要重定位的ELF段都有一个重定位表。
如代码段的.text有要被重定位的地方,那么就有一个对于的的.rel.text的段保存了代码段的重定位条目。
ELF重定位条目
typedef struct {
long offset;
long type : 32,
symbol : 32;
long addend;
}Elf64_Rela;




![BUUCTF Reverse/[2019红帽杯]xx](https://img-blog.csdnimg.cn/93c03c2b7ac245c8b705f5a7267e85ec.png)














