作者:彭晟,2023 年 Elastic 开发者大会讲师
概述
Elasticsearch 整合机器学习强化排序, 介绍如何将机器学习预测能力迁移至 ES 内部,增强排序能力, 构建一个高性能,分布式搜排一体系统,并通过落地更多复杂模型特征和更深的计算,为业务带来新的增长点,我们将 LR -> 树模型完成全量排序,给核心业务带来 1.2% 的 ab 增长。
背景介绍
我们团队主要负责哈啰四轮司乘匹配的召回排序。在顺风车司乘匹配场景中,司机发单后系统会从订单池中筛选展示合适的乘客订单,促进司机发单到完单,带来营收。整个过程排序是一个非常关键的环节。目前我们底层的排序架构是用了经典粗排-精排重排级联排序。

在粗排阶段,我们使用 LR(Logistic Regression)算法(简单规则)对数千个订单进行排序。而在精排阶段,我们筛选出前300名订单,并使用 rankservice 完成深度排序。在重排阶段,我们再选取 10 个订单进入业务相关重排。前年我们团队在精排阶段将模型由树模型升级成深度模型,并取得了不错的业务效果,同时也沉淀了一定的技术。因此我们开始考虑将粗排也进行精排化,即采取更加复杂的模型和更多的特征。参考行业经验以及业务场景的特点,如路线匹配路线和算法离线评估,我们决定将粗排从LR升级为效果更好的树模型。
在达成这个目标的同时,也会解决历史中存在的技术问题
- 之前精排阶段的树模型受限于技术,单机只能支持 300 排序 -> 升级到 ES 内部完成全排序
- LR的迭代全部手写代码 -> 编程配置化,加速迭代,增加稳定性
整体的方案
机器学习在线预测流程
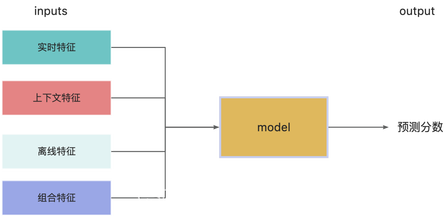
需要在程序中获取一批特征 inputs 传入模型,返回模型预测分数output.在这个过程中,根据来源分成以下几种类型
- 实时特征
- 上下文特征
- 离线特征
- 组合特征
每种类型特征都需要对应一套技术解决方案。
具体方案
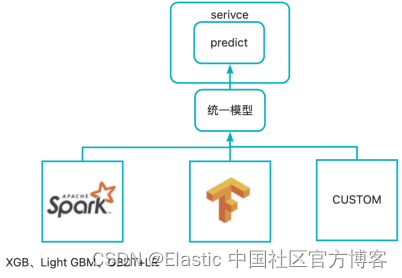
我们将整个机器学习以插件的形式嵌入 ES 内部,其中包含多个重要的组件

特征获取方案
实时特征
司机的实时特征由 flink 计算后上游查询从接口传入
订单的实时特征由 flink 写入索引
上下文特征
司机的实时特征由调用传参带入
离线特征
由 kkv 系统完成离线特征的加载,查询,更新,可以支持到分钟级别
组合特征
我们内部设计了一套 DSL,通过配置即可完成特征生成,包含了组合特征。
重要组件简介
kkv:
在线获取离线特征。
热加载:
ES 脚本插件需要重启整个集群才能完成更新,我们在它的底层接口进行了一层抽象,借助热加载的能力完成对业务插件的更新
执行引擎:
执行引擎主要用来对模型的加载,预测,底层支持多种算法模型预测
文件分发系统:
主要用于将文件更新到整个集群,触发业务回调,算法同学在训练平台玩完成 kv 训练,模型训练以及配置文件设置,会通过文件分发系统实时同步到整个 ES 集群,完成更新,触发业务回调
特征生成:
特征配置生成系统,通过自定义 DSL 获取全部的模型入参特征
DEBUG:
用于快速验证在 ES 内部机器学习模型预测的准确性
关键组件
执行引擎
执行引擎主要用于对模型的加载预测。
算法训练常见的模型有树模型,深度模型,还有部分自定义。不同的模型框架,算法可能需要工程做单独的适配,我们期望有一种通用的执行引擎可以解决掉复杂的适配问题。既可以支持在 sparkml 的模型,也可以支持深度学习,我们选择了mleap,一种通用的执行引擎.算法同学使用 sparkML 完成模型的训练,使用 mleap 进行序列化,生成统一的模型。
在线上使用 mleap 的 API 进行加载预测。
kkv 系统
主要用于离线特征的加载和查询,我们会面对一些海量离线特征存储查询的挑战。
挑战:
- 检索 rt 要求高
举个例子,假设本次检索命中了1000个订单,模型有100个离线特征,单位时间 kv 检索到达 10w 次
远程 io 无法支持,所以做成特征本地化
- 特征量大
我们的特征已经到达百亿级别,传统的加载无法支持,这块我们的解决方案是使用 mmap 内存映射技术,读取二进制实时反序列化,这个解决方案 ES 的docvalue 底层是一样的。
我们调研了一些常见 mmap 解决实现, ohc mapdb rocksdb paldb, 发现 paldb 在性能、存储和索引速度都是最快的。
线上数据:
(数据均来自精排的深度学习)
50G -> 20G -> 10G
hive 表 索引文件 映射内存
查询速率:获取390订单 100 纬度离线 100 组合 50 上下文的特征数据 耗时 5.6ms
(总 rt 18.5 tf预测: 12.5 特征: 6)

面对海量特征查询,本地 kkv 是机器学习预测性能的关键技术。
文件分发系统 dragonfly
主要用于更新文件触发业务回调
我们有配置文件 jar model kv config,需要被分发到 ES 内部,触发回调。我们针对共性的需求开发了一个分发系统。
实现逻辑很简单,文件通过 dragonlfy 上传到存储系统中(OSS,HDFS等),修改 meta , consumer 监听远程文件,发现 meta 变更自动下载文件 -> 校验 md5-> 触发回调用
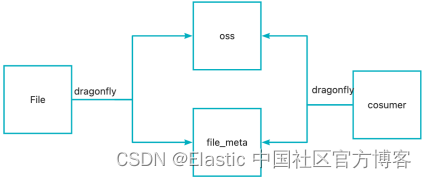

功能:
- 文件变更自动下载最新文件,触发业务回调
- 极速MD5校验 本地记录MD5
- 易用性 支持注解驱动
- 支持灰度加载,可与任意配置中心整合 apollo,自定义配置
- 更新回调状态 用于监控
- 支持多环境 采用虚拟环境
- 支持多回调等等
以下为 rankservice 与 spring 整合的截图
//文件监听
@Dragonfly(storagePath = "model/lo_cc_deep_model_v1.tar.gz")
public void getDeepFMModel(File file, String path) throws IOException {
super.getDeepFMModel(file,path);
}
//多回调
@Dragonfly(storagePath = "model/lo_cc_deep_model_v1.tar.gz")
public void test(File file, String path) throws IOException {
System.out.println("单体测试3");
}
//目录监听
@Dragonfly(dirPathMonitor = "model/deep",filterBean = ApolloFilter.class )
public void getDeepFMModel(File file, String path) throws IOException {
super.getDeepFMModel(file, path);
}个人经验,文件分发系统对于机器学习工程预测来说非常重要,属于事半功倍
热加载
不需要重启整个集群即可完成插件更新的功能
ES 启动的时候就会进行热加载插件的加载,通过 dragonfly 监听/回调业务 .jar,装载实现进入插件裤,ES query 中指定相关的实现即可完成对业务执行。
jar 里面包含了多种类型插件实现:
- filter实现:eta 过滤,夹脚过滤,沿途距离过滤等
- sort 实现:排序有顺路度,mleap 排序(树模型排序,tf 排序)
- script_field 实现:字段插件有顺路度

插件开发 tips:
- 是否存在外部资源
- 需要手动关闭
- 是否存在第三方 jar,存在内存泄漏
- 热加载常见问题内存泄漏,可以通过压测来发现
- 提前加载预热,防止突刺
- 对 class 提前初始化,存在资源加载的情况
- 模型提前预热
- 对 class 提前初始化,存在资源加载的情况
- 分层热加载
- 轻资源 class 的加载和卸载
- 重资源独立,不参与热加载,,比如 kv 热加载会导致之前的 kv pagecache 淘汰,重新 reload,会消耗系统资源
- 轻资源 class 的加载和卸载
- 错误日志限制输出
- ES 文档计算是 row by row,有多少文档输出多少次日志,严重消耗系统 CPU,导致服务不稳定
- 限制一次请求只能输出一个错误日志
- ES 文档计算是 row by row,有多少文档输出多少次日志,严重消耗系统 CPU,导致服务不稳定
配置化的迭代
我们期望特征迭代配置化 , 算法工程同学不写一行代码
难点:
特征组合(特征交叉),特征处理的逻辑千变万化,需要设计一套方案来解决特征灵活变换的问题.
介绍:如何获取一个组合特征
如图 8 所示,原始 user 特征+原始 item 特征 经过特征组合或者交叉 生成模型特征


我们看下之前的解决方案图 9: 每个特征都需要手写代码,一个模型有几百个特征,非常麻烦,并且容易出错。
我们的解决方案 使用自定义算子 + 原始特征 利用反射来完成特征生成。

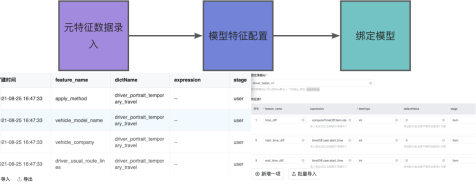
我们内部自研了一套 DSL,通过配置就完成模型任意类型特征的生成.(实时 kv 上下文 组合)
我们会将验证准确的特征配置录入到特征表中(图11),算法同学在录入模型特征的时候自动出提示,保证录入的准确性与效率,如果是模型微调 v2 版本,直接复制 v1 修改几个特征即可。整个算法特征被管理起来,保证同组使用的唯一性。
DEBUG
在 ES 内部快速完成机器学习 debug。
解决方案:
ES 内部有一个 API
org.elasticsearch.script.ScoreScript#execute(ExplanationHolderexplanation explanation)
我们将计算每个 item 预测过程进行对外输出
比如以下例子: 包含了策略名称,请求入参数,模型入参数
explanation.set(String.format("mleap(policyName=%s,params=%s,detail=%s)", this.sortPolicy, params,tempMap))如图所示:可以对匹配到的订单进行 debug
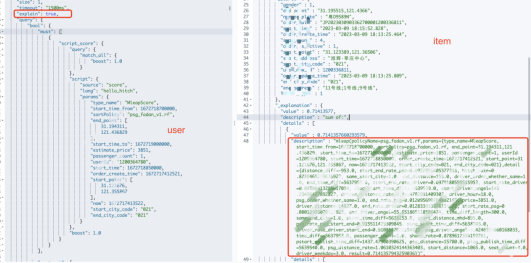
可以获得:原始 user 特征,原始 item 特征,模型入参特征详细信息,这样就可以对模型的准确进行校验。
稳定性:
我们从以下4点进行稳定性的保障。
完善压测方案
每次新上线模型前除了常规的 fat,uat 环境测试,上了 pre 环境会进行压测回归 & 新功能验证

针对存在的风险点进行极限压测
涉及变更点:业务插件,模型,特征
要求:新老插件交替,模型特征重置,保证不出现抖动,在任意变更点保证服务都是稳定的
方案:天级别变更为分钟级别变更
结果:经过一周的压测,服务整体稳定,没有出现内存泄露,基本判断方案成了
灰度变更
稳定性三板斧,可灰度,可监控,可回滚。由于新上模型,需要做变更灰度。我们借助 dragonfly 顺序加载 & 灰度来完成。
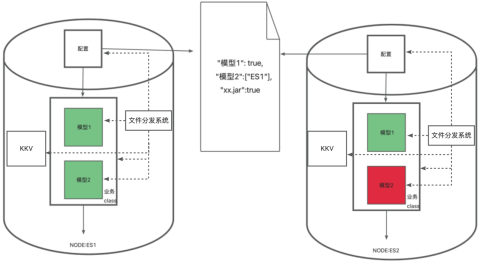
dragonfly 优先监听加载灰度文件,针对灰度文件配置加载其他文件.
如上图所示:
模型1:允许 2 台机器加载
模型2:只允许节点为 ES1 进行加载
jar:允许两台机器加载
机器学习分组加载
各个业务的模型不一样,需要的特征也不一样,我们期望针对每一个模型进行分组加载,而不是让每台机器全量加载。这里我们借助的是 ES 的分组特性和 index 的模板。我们在创建 index 的时候会直接绑定这个 index 在哪些机器上生成,如 index1 在 group1 上,index2在group2上,index3 在 group3上,通过文件分发系统来完成对整个机器学习的分组加载。同时,我们也可以通过对每个业务模型特征,进行分组加载来减少不必要的开销。例如,某些业务可能只需要部分特征进行训练,kkv 系统支持按需进行索引部分字段提供线上查询,这样就可以减少特征的维度,从而降低了计算成本,提升了系统性能。

模型预测加速
我们从三个维度进行机器学习的性能加速,首先是请求缓存,第一个是 user 特征的缓存,计算一次后可重复使用。第二个是对象复用,由于 ES 的计算是 row by row 的计算,我们计算完一个 row 后,它的模型入参 inputs 可以继续复用,下一个计算开始的时候直接对 item 维度特征修改即可。
其次是模型缓存,即模型预测加速.我们固定了输入/输出的 schema,并预分配足够的内存空间用于存储所有的结果数据,从而避免了多余的计算和内存空间动态分配的开销。同时,我们也采用了模型入参减少key的输入优化方式,进一步缩短了计算时间。
接下来是全局缓存,我们通过 mmap 内存映射技术做整个 kv 的加速,还有一些做特征加速。我们会有一些高频的特征,比如某个特征的均值、方差、最大值、最小值等,具有量小,高频访问特性,所以我们可以把它长驻堆内。

上线后业务上的表现
- 支持spark 全部的模型
- 模型迭代,免开发,通过特征配置化、热加载、压测、灰度可以快速稳定上线
- 算法插件组件化、可插拔、灵活编排和支持多轮排序
这里是一个常见的例子, ES 召回完成之后,直接进行级联排序,模型 B 进行 score,模型 C 进行 rescore。其次是灵活编排,我们整个模型库可能有 ABCDEF的模型,假设在第一阶段有10000个订单,我们使用模型 ABC 同时进行排序,排序后组合取 Top1000 进行模型 D 排序,排序后取 300 个进行模型E排序,整个过程非常灵活.

- 热加载, 特征 模型 jar 实时更新,无抖动
- 火焰图,单核心场景,排序只占到 7% 的 CPU 消耗
- 在单机单分片场景 1500深度下, 树模型相比 LR 多了 10ms
- 全场景 LR -> 树模型,顺风车核心ab 增加 1.2%
后续动作
短期目标:后续我们计划会补齐 ES 的排序短板,支持深度学习。
目前主要的问题在于 ES 的计算是 row by row 的,没有办法使用 TF 的 batch 计算,每一次计算 TF 都要开启 session,这是非常耗资源的。这块未来会通过 ES rescore 插件来解决。
同时我们会去整合 openvino,目前在业内有很多机器学习框架,如 Tensorflow、飞桨、Pytorch、Caffe 等,算法又有这方面的诉求,需要工程同学去做每一个框架适配,我们在思考有没有统一的解决方案,可以将主流的 DL 框架收拢起来,使用一个 API 就能完成预测。我们发现可以使用 openvino 来解决这个问题。目前已经在做相关的技术调研,预计下半年可以上到我们的 rankservice 中,稳定半年以上就会开始迁移到 ES。

![[操作系统安全]缓冲区溢出](https://img-blog.csdnimg.cn/7464e87a2e4d4072b52e78f13449893a.png)