诸神缄默不语-个人CSDN博文目录
transformers官方文档:https://huggingface.co/docs/transformers/index
AutoModel文档:https://huggingface.co/docs/transformers/v4.23.1/en/model_doc/auto#transformers.AutoModel
AutoTokenizer文档:https://huggingface.co/docs/transformers/v4.23.1/en/model_doc/auto#transformers.AutoTokenizer
单任务就是直接用Bert表征,然后接一个Dropout,接一层线性网络(和直接使用AutoModelforSequenceClassification性质相同)。
多任务单数据集就是将单任务的线性网络改成给每个任务一个线性网络。
https://github.com/huggingface/transformers/blob/ad654e448444b60937016cbea257f69c9837ecde/src/transformers/modeling_utils.py
https://github.com/huggingface/transformers/blob/ee0d001de71f0da892f86caa3cf2387020ec9696/src/transformers/models/bert/modeling_bert.py
多任务多数据集则是参考transformers官方代码(上面两个网址),在多任务单数据集的基础上再把BertEmbeddings拆出来,所有任务仅共享BertEncoder部分。
(事实上多任务学习有很多种范式,本文使用的是基本的硬共享机制)
文章目录
- 1. 单任务文本分类
- 2. 多任务文本分类(单数据集)
- 3. 多任务文本分类(多数据集)
1. 单任务文本分类
本文用的数据集是https://raw.githubusercontent.com/SophonPlus/ChineseNlpCorpus/master/datasets/ChnSentiCorp_htl_all/ChnSentiCorp_htl_all.csv,预训练语言模型是https://huggingface.co/bert-base-chinese
可参考我写的另一个项目PolarisRisingWar/pytorch_text_classification
代码:
import csv,random
from tqdm import tqdm
from copy import deepcopy
from sklearn.metrics import accuracy_score,precision_score,recall_score,f1_score
import torch
import torch.nn as nn
from torch.utils.data import Dataset,DataLoader
from transformers import AutoModel, AutoTokenizer
#超参设置
random_seed=20221125
split_ratio='6-2-2'
pretrained_path='/data/pretrained_model/bert-base-chinese'
dropout_rate=0.1
max_epoch_num=16
cuda_device='cuda:2'
output_dim=2
#数据预处理
with open('other_data_temp/ChnSentiCorp_htl_all.csv') as f:
reader=csv.reader(f)
header = next(reader) #表头
data = [[int(row[0]),row[1]] for row in reader] #每个元素是一个由字符串组成的列表,第一个元素是标签(01),第二个元素是评论文本。
random.seed(random_seed)
random.shuffle(data)
split_ratio_list=[int(i) for i in split_ratio.split('-')]
split_point1=int(len(data)*split_ratio_list[0]/sum(split_ratio_list))
split_point2=int(len(data)*(split_ratio_list[0]+split_ratio_list[1])/sum(split_ratio_list))
train_data=data[:split_point1]
valid_data=data[split_point1:split_point2]
test_data=data[split_point2:]
#建立数据集迭代器
class TextInitializeDataset(Dataset):
def __init__(self,input_data) -> None:
self.text=[x[1] for x in input_data]
self.label=[x[0] for x in input_data]
def __getitem__(self, index):
return [self.text[index],self.label[index]]
def __len__(self):
return len(self.text)
tokenizer=AutoTokenizer.from_pretrained(pretrained_path)
def collate_fn(batch):
pt_batch=tokenizer([x[0] for x in batch],padding=True,truncation=True,max_length=512,return_tensors='pt')
return {'input_ids':pt_batch['input_ids'],'token_type_ids':pt_batch['token_type_ids'],'attention_mask':pt_batch['attention_mask'],
'label':torch.tensor([x[1] for x in batch])}
train_dataloader=DataLoader(TextInitializeDataset(train_data),batch_size=16,shuffle=True,collate_fn=collate_fn)
valid_dataloader=DataLoader(TextInitializeDataset(valid_data),batch_size=128,shuffle=False,collate_fn=collate_fn)
test_dataloader=DataLoader(TextInitializeDataset(test_data),batch_size=128,shuffle=False,collate_fn=collate_fn)
#建模
class ClsModel(nn.Module):
def __init__(self,output_dim,dropout_rate):
super(ClsModel,self).__init__()
self.encoder=AutoModel.from_pretrained(pretrained_path)
self.dropout=nn.Dropout(dropout_rate)
self.classifier=nn.Linear(768,output_dim)
def forward(self,input_ids,token_type_ids,attention_mask):
x=self.encoder(input_ids=input_ids,token_type_ids=token_type_ids,attention_mask=attention_mask)['pooler_output']
x=self.dropout(x)
x=self.classifier(x)
return x
loss_func=nn.CrossEntropyLoss()
model=ClsModel(output_dim,dropout_rate)
model.to(cuda_device)
optimizer=torch.optim.Adam(params=model.parameters(),lr=1e-5)
max_valid_f1=0
best_model={}
for e in tqdm(range(max_epoch_num)):
for batch in train_dataloader:
model.train()
optimizer.zero_grad()
input_ids=batch['input_ids'].to(cuda_device)
token_type_ids=batch['token_type_ids'].to(cuda_device)
attention_mask=batch['attention_mask'].to(cuda_device)
outputs=model(input_ids,token_type_ids,attention_mask)
train_loss=loss_func(outputs,batch['label'].to(cuda_device))
train_loss.backward()
optimizer.step()
#验证
with torch.no_grad():
model.eval()
labels=[]
predicts=[]
for batch in valid_dataloader:
input_ids=batch['input_ids'].to(cuda_device)
token_type_ids=batch['token_type_ids'].to(cuda_device)
attention_mask=batch['attention_mask'].to(cuda_device)
outputs=model(input_ids,token_type_ids,attention_mask)
labels.extend([i.item() for i in batch['label']])
predicts.extend([i.item() for i in torch.argmax(outputs,1)])
f1=f1_score(labels,predicts,average='macro')
if f1>max_valid_f1:
best_model=deepcopy(model.state_dict())
max_valid_f1=f1
#测试
model.load_state_dict(best_model)
with torch.no_grad():
model.eval()
labels=[]
predicts=[]
for batch in test_dataloader:
input_ids=batch['input_ids'].to(cuda_device)
token_type_ids=batch['token_type_ids'].to(cuda_device)
attention_mask=batch['attention_mask'].to(cuda_device)
outputs=model(input_ids,token_type_ids,attention_mask)
labels.extend([i.item() for i in batch['label']])
predicts.extend([i.item() for i in torch.argmax(outputs,1)])
print(accuracy_score(labels,predicts))
print(precision_score(labels,predicts,average='macro'))
print(recall_score(labels,predicts,average='macro'))
print(f1_score(labels,predicts,average='macro'))
用时约1h35min
实验结果:
| accuracy | macro-P | macro-R | macro-F |
|---|---|---|---|
| 91.89 | 91.39 | 90.33 | 90.82 |
2. 多任务文本分类(单数据集)
本文使用的数据集TEL-NLP来自:https://github.com/scsmuhio/MTGCN
我用的数据集文件是:https://raw.githubusercontent.com/scsmuhio/MTGCN/main/Data/ei_task.csv
出处论文MT-Text GCN:Multi-Task Text Classification using Graph Convolutional Networks for Large-Scale Low Resource Language
我用的泰卢固语Bert模型权重是:https://huggingface.co/kuppuluri/telugu_bertu(不是数据集原论文用的表征工具)
这是个泰卢固语多任务文本分类数据集。呃我其实完全不会泰卢固语,所以原则上我其实不想用这个数据集的,但是我只找到了这一个很典型的单数据集多任务文本分类数据集!
数据集示例:
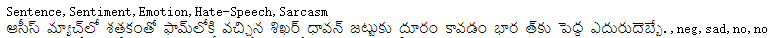
本文用的数据集预处理方法和论文里写的相似(无法相同,因为第一,这个数据集和论文里给的数据不一样,我也在GitHub项目里问了:Questions about data · Issue #1 · scsmuhio/MTGCN;第二,代码里没有给出每次划分的结果,我只能自定义随机种子实现;第三,我其实没太看懂论文里到底是咋分的,据我理解大概是5次按照7-1-2比例随机划分,用5次实验上的结果平均值作为最终结果,但是我懒得搞这么多次):
按照7-1-2比例随机划分数据集(随机种子为20221028)
(最终结果看起来和论文里报的结果就没法比,就完全不在一个谱上……)
跑了2次实验,对比使用单任务分类范式和多任务分类范式的区别,每次都是微调最多16个epoch,取macro-F1值最高的epoch的模型来做测试(多任务就是macro-F1平均值最高)。
单看实验结果的话,感觉多任务范式没有体现出明显的优势或劣势。但是多任务范式没有做什么优化就是啦,搞得比较简单,有时间的话再优化一下代码。
单任务版代码:
import csv,os,random
from tqdm import tqdm
from copy import deepcopy
from sklearn.metrics import accuracy_score,precision_score,recall_score,f1_score
import torch
import torch.nn as nn
from torch.utils.data import Dataset,TensorDataset,DataLoader
from transformers import AutoModel, AutoTokenizer, pipeline
#数据预处理
with open('other_data_temp/telnlp_ei.csv') as f:
reader=csv.reader(f)
header = next(reader) #表头
print(header)
data=list(reader)
#对标签进行数值化
map1={'neg':0,'neutral':1,'pos':2}
map2={'angry':0,'sad':1,'fear':2,'happy':3}
map3={'yes':0,'no':1}
random.seed(20221028)
random.shuffle(data)
split_ratio_list=[7,1,2]
split_point1=int(len(data)*split_ratio_list[0]/sum(split_ratio_list))
split_point2=int(len(data)*(split_ratio_list[0]+split_ratio_list[1])/sum(split_ratio_list))
train_data=data[:split_point1]
valid_data=data[split_point1:split_point2]
test_data=data[split_point2:]
#建立数据集迭代器
class TextInitializeDataset(Dataset):
def __init__(self,input_data) -> None:
self.text=[x[0] for x in input_data]
self.sentiment=[map1[x[1]] for x in input_data]
self.emotion=[map2[x[2]] for x in input_data]
self.hate=[map3[x[3]] for x in input_data]
self.sarcasm=[map3[x[4]] for x in input_data]
def __getitem__(self, index):
return [self.text[index],self.sentiment[index],self.emotion[index],self.hate[index],self.sarcasm[index]]
def __len__(self):
return len(self.text)
tokenizer = AutoTokenizer.from_pretrained("/data/pretrained_model/telugu_bertu",clean_text=False,handle_chinese_chars=False,
strip_accents=False,wordpieces_prefix='##')
def collate_fn(batch):
pt_batch=tokenizer([x[0] for x in batch],padding=True,truncation=True,max_length=512,return_tensors='pt')
return {'input_ids':pt_batch['input_ids'],'token_type_ids':pt_batch['token_type_ids'],'attention_mask':pt_batch['attention_mask'],
'sentiment':torch.tensor([x[1] for x in batch]),'emotion':torch.tensor([x[2] for x in batch]),'hate':torch.tensor([x[3] for x in batch]),
'sarcasm':torch.tensor([x[4] for x in batch])}
train_dataloader=DataLoader(TextInitializeDataset(train_data),batch_size=64,shuffle=True,collate_fn=collate_fn)
valid_dataloader=DataLoader(TextInitializeDataset(valid_data),batch_size=512,shuffle=False,collate_fn=collate_fn)
test_dataloader=DataLoader(TextInitializeDataset(test_data),batch_size=512,shuffle=False,collate_fn=collate_fn)
#建模
class ClsModel(nn.Module):
def __init__(self,output_dim,dropout_rate):
super(ClsModel,self).__init__()
self.encoder=AutoModel.from_pretrained("/data/pretrained_model/telugu_bertu")
self.dropout=nn.Dropout(dropout_rate)
self.classifier=nn.Linear(768,output_dim)
def forward(self,input_ids,token_type_ids,attention_mask):
x=self.encoder(input_ids=input_ids,token_type_ids=token_type_ids,attention_mask=attention_mask)['pooler_output']
x=self.dropout(x)
x=self.classifier(x)
return x
#运行
dropout_rate=0.1
max_epoch_num=16
cuda_device='cuda:1'
od_map={'sentiment':3,'emotion':4,'hate':2,'sarcasm':2}
loss_func=nn.CrossEntropyLoss()
for the_label in ['sentiment','emotion','hate','sarcasm']:
model=ClsModel(od_map[the_label],dropout_rate)
model.to(cuda_device)
optimizer=torch.optim.Adam(params=model.parameters(),lr=1e-5)
max_valid_f1=0
best_model={}
for e in tqdm(range(max_epoch_num)):
for batch in train_dataloader:
model.train()
optimizer.zero_grad()
input_ids=batch['input_ids'].to(cuda_device)
token_type_ids=batch['token_type_ids'].to(cuda_device)
attention_mask=batch['attention_mask'].to(cuda_device)
outputs=model(input_ids,token_type_ids,attention_mask)
train_loss=loss_func(outputs,batch[the_label].to(cuda_device))
train_loss.backward()
optimizer.step()
#验证
with torch.no_grad():
model.eval()
labels=[]
predicts=[]
for batch in valid_dataloader:
input_ids=batch['input_ids'].to(cuda_device)
token_type_ids=batch['token_type_ids'].to(cuda_device)
attention_mask=batch['attention_mask'].to(cuda_device)
outputs=model(input_ids,token_type_ids,attention_mask)
labels.extend([i.item() for i in batch[the_label]])
predicts.extend([i.item() for i in torch.argmax(outputs,1)])
f1=f1_score(labels,predicts,average='macro')
if f1>max_valid_f1:
best_model=deepcopy(model.state_dict())
max_valid_f1=f1
#测试
model.load_state_dict(best_model)
with torch.no_grad():
model.eval()
labels=[]
predicts=[]
for batch in test_dataloader:
input_ids=batch['input_ids'].to(cuda_device)
token_type_ids=batch['token_type_ids'].to(cuda_device)
attention_mask=batch['attention_mask'].to(cuda_device)
outputs=model(input_ids,token_type_ids,attention_mask)
labels.extend([i.item() for i in batch[the_label]])
predicts.extend([i.item() for i in torch.argmax(outputs,1)])
print(the_label)
print(accuracy_score(labels,predicts))
print(precision_score(labels,predicts,average='macro'))
print(recall_score(labels,predicts,average='macro'))
print(f1_score(labels,predicts,average='macro'))
多任务版代码:
import csv,os,random
from tqdm import tqdm
from copy import deepcopy
from statistics import mean
from sklearn.metrics import accuracy_score,precision_score,recall_score,f1_score
import torch
import torch.nn as nn
from torch.utils.data import Dataset,TensorDataset,DataLoader
from transformers import AutoModel, AutoTokenizer, pipeline
#数据预处理
with open('other_data_temp/telnlp_ei.csv') as f:
reader=csv.reader(f)
header = next(reader) #表头
print(header)
data=list(reader)
#对标签进行数值化
map1={'neg':0,'neutral':1,'pos':2}
map2={'angry':0,'sad':1,'fear':2,'happy':3}
map3={'yes':0,'no':1}
random.seed(20221028)
random.shuffle(data)
split_ratio_list=[7,1,2]
split_point1=int(len(data)*split_ratio_list[0]/sum(split_ratio_list))
split_point2=int(len(data)*(split_ratio_list[0]+split_ratio_list[1])/sum(split_ratio_list))
train_data=data[:split_point1]
valid_data=data[split_point1:split_point2]
test_data=data[split_point2:]
#建立数据集迭代器
class TextInitializeDataset(Dataset):
def __init__(self,input_data) -> None:
self.text=[x[0] for x in input_data]
self.sentiment=[map1[x[1]] for x in input_data]
self.emotion=[map2[x[2]] for x in input_data]
self.hate=[map3[x[3]] for x in input_data]
self.sarcasm=[map3[x[4]] for x in input_data]
def __getitem__(self, index):
return [self.text[index],self.sentiment[index],self.emotion[index],self.hate[index],self.sarcasm[index]]
def __len__(self):
return len(self.text)
tokenizer = AutoTokenizer.from_pretrained("/data/pretrained_model/telugu_bertu",clean_text=False,handle_chinese_chars=False,
strip_accents=False,wordpieces_prefix='##')
def collate_fn(batch):
pt_batch=tokenizer([x[0] for x in batch],padding=True,truncation=True,max_length=512,return_tensors='pt')
return {'input_ids':pt_batch['input_ids'],'token_type_ids':pt_batch['token_type_ids'],'attention_mask':pt_batch['attention_mask'],
'sentiment':torch.tensor([x[1] for x in batch]),'emotion':torch.tensor([x[2] for x in batch]),'hate':torch.tensor([x[3] for x in batch]),
'sarcasm':torch.tensor([x[4] for x in batch])}
train_dataloader=DataLoader(TextInitializeDataset(train_data),batch_size=64,shuffle=True,collate_fn=collate_fn)
valid_dataloader=DataLoader(TextInitializeDataset(valid_data),batch_size=512,shuffle=False,collate_fn=collate_fn)
test_dataloader=DataLoader(TextInitializeDataset(test_data),batch_size=512,shuffle=False,collate_fn=collate_fn)
#建模
class ClsModel(nn.Module):
def __init__(self,output_dims,dropout_rate):
super(ClsModel,self).__init__()
self.encoder=AutoModel.from_pretrained("/data/pretrained_model/telugu_bertu")
self.dropout=nn.Dropout(dropout_rate)
self.classifiers=nn.ModuleList([nn.Linear(768,output_dim) for output_dim in output_dims])
def forward(self,input_ids,token_type_ids,attention_mask):
x=self.encoder(input_ids=input_ids,token_type_ids=token_type_ids,attention_mask=attention_mask)['pooler_output']
x=self.dropout(x)
xs=[classifier(x) for classifier in self.classifiers]
return xs
#运行
dropout_rate=0.1
max_epoch_num=16
cuda_device='cuda:2'
od_name=['sentiment','emotion','hate','sarcasm']
od=[3,4,2,2]
loss_func=nn.CrossEntropyLoss()
model=ClsModel(od,dropout_rate)
model.to(cuda_device)
optimizer=torch.optim.Adam(params=model.parameters(),lr=1e-5)
max_valid_f1=0
best_model={}
for e in tqdm(range(max_epoch_num)):
for batch in train_dataloader:
model.train()
optimizer.zero_grad()
input_ids=batch['input_ids'].to(cuda_device)
token_type_ids=batch['token_type_ids'].to(cuda_device)
attention_mask=batch['attention_mask'].to(cuda_device)
outputs=model(input_ids,token_type_ids,attention_mask)
loss_list=[loss_func(outputs[i],batch[od_name[i]].to(cuda_device)) for i in range(4)]
train_loss=torch.sum(torch.stack(loss_list))
train_loss.backward()
optimizer.step()
#验证
with torch.no_grad():
model.eval()
labels=[[] for _ in range(4)]
predicts=[[] for _ in range(4)]
for batch in valid_dataloader:
input_ids=batch['input_ids'].to(cuda_device)
token_type_ids=batch['token_type_ids'].to(cuda_device)
attention_mask=batch['attention_mask'].to(cuda_device)
outputs=model(input_ids,token_type_ids,attention_mask)
for i in range(4):
labels[i].extend([i.item() for i in batch[od_name[i]]])
predicts[i].extend([i.item() for i in torch.argmax(outputs[i],1)])
f1=mean([f1_score(labels[i],predicts[i],average='macro') for i in range(4)])
if f1>max_valid_f1:
best_model=deepcopy(model.state_dict())
max_valid_f1=f1
#测试
model.load_state_dict(best_model)
with torch.no_grad():
model.eval()
labels=[[] for _ in range(4)]
predicts=[[] for _ in range(4)]
for batch in test_dataloader:
input_ids=batch['input_ids'].to(cuda_device)
token_type_ids=batch['token_type_ids'].to(cuda_device)
attention_mask=batch['attention_mask'].to(cuda_device)
outputs=model(input_ids,token_type_ids,attention_mask)
for i in range(4):
labels[i].extend([i.item() for i in batch[od_name[i]]])
predicts[i].extend([i.item() for i in torch.argmax(outputs[i],1)])
for i in range(4):
print(od_name[i])
print(accuracy_score(labels[i],predicts[i]))
print(precision_score(labels[i],predicts[i],average='macro'))
print(recall_score(labels[i],predicts[i],average='macro'))
print(f1_score(labels[i],predicts[i],average='macro'))
(多任务时间是单任务的1/4,具体差多少没计时)
实验结果对比(×100 保留2位小数):
| 任务-标签 | accuracy | macro-P | macro-R | macro-F |
|---|---|---|---|---|
| 单-sentiment | 85.69 | 64.38 | 63.55 | 63.73 |
| 多-sentiment | 86.37 | 65.74 | 63.29 | 63.9 |
| 单-emtion | 87.61 | 72.18 | 73.16 | 72.47 |
| 多-emotion | 88.28 | 79.97 | 66.51 | 70.81 |
| 单-hate-speech | 96.58 | 63.99 | 69.15 | 66.12 |
| 多-hate-speech | 96.84 | 66.36 | 72.78 | 68.99 |
| 单-sarcasm | 98.34 | 64.47 | 68.55 | 66.25 |
| 多-sarcasm | 98.03 | 60.92 | 66.04 | 62.96 |
3. 多任务文本分类(多数据集)
本文用的数据集是2种新浪微博数据,都来源于https://github.com/SophonPlus/ChineseNlpCorpus这个项目:
一个标注情感正负性(0/1):https://pan.baidu.com/s/1DoQbki3YwqkuwQUOj64R_g
一个标注4种情感:https://pan.baidu.com/s/16c93E5x373nsGozyWevITg
预训练语言模型是https://huggingface.co/bert-base-chinese
(时间太久了,懒得跑好几个epoch,我就都只跑1个epoch了)
单任务代码:
import csv,random
from tqdm import tqdm
from copy import deepcopy
from sklearn.metrics import accuracy_score,precision_score,recall_score,f1_score
import torch
import torch.nn as nn
from torch.utils.data import Dataset,DataLoader
from transformers import AutoModel, AutoTokenizer
#超参设置
random_seed=20221125
split_ratio='6-2-2'
pretrained_path='/data/pretrained_model/bert-base-chinese'
dropout_rate=0.1
max_epoch_num=1
cuda_device='cuda:3'
output_dim=[['/data/other_data/weibo_senti_100k.csv',2],['/data/other_data/simplifyweibo_4_moods.csv',4]]
#数据预处理
random.seed(random_seed)
#建立数据集迭代器
class TextInitializeDataset(Dataset):
def __init__(self,input_data) -> None:
self.text=[x[1] for x in input_data]
self.label=[x[0] for x in input_data]
def __getitem__(self, index):
return [self.text[index],self.label[index]]
def __len__(self):
return len(self.text)
tokenizer = AutoTokenizer.from_pretrained(pretrained_path)
def collate_fn(batch):
pt_batch=tokenizer([x[0] for x in batch],padding=True,truncation=True,max_length=512,return_tensors='pt')
return {'input_ids':pt_batch['input_ids'],'token_type_ids':pt_batch['token_type_ids'],'attention_mask':pt_batch['attention_mask'],
'label':torch.tensor([x[1] for x in batch])}
#建模
class ClsModel(nn.Module):
def __init__(self,output_dim,dropout_rate):
super(ClsModel,self).__init__()
self.encoder=AutoModel.from_pretrained(pretrained_path)
self.dropout=nn.Dropout(dropout_rate)
self.classifier=nn.Linear(768,output_dim)
def forward(self,input_ids,token_type_ids,attention_mask):
x=self.encoder(input_ids=input_ids,token_type_ids=token_type_ids,attention_mask=attention_mask)['pooler_output']
x=self.dropout(x)
x=self.classifier(x)
return x
#运行
loss_func=nn.CrossEntropyLoss()
for task in output_dim:
with open(task[0]) as f:
reader=csv.reader(f)
header = next(reader) #表头
data = [[int(row[0]),row[1]] for row in reader] #每个元素是一个由字符串组成的列表,第一个元素是标签(01),第二个元素是评论文本。
split_ratio_list=[int(i) for i in split_ratio.split('-')]
split_point1=int(len(data)*split_ratio_list[0]/sum(split_ratio_list))
split_point2=int(len(data)*(split_ratio_list[0]+split_ratio_list[1])/sum(split_ratio_list))
train_data=data[:split_point1]
valid_data=data[split_point1:split_point2]
test_data=data[split_point2:]
train_dataloader=DataLoader(TextInitializeDataset(train_data),batch_size=16,shuffle=True,collate_fn=collate_fn)
valid_dataloader=DataLoader(TextInitializeDataset(valid_data),batch_size=128,shuffle=False,collate_fn=collate_fn)
test_dataloader=DataLoader(TextInitializeDataset(test_data),batch_size=128,shuffle=False,collate_fn=collate_fn)
#64-512在第一个数据集上是可行的,在第二个数据集上会OOM,所以我直接全调一样了
model=ClsModel(task[1],dropout_rate)
model.to(cuda_device)
optimizer=torch.optim.Adam(params=model.parameters(),lr=1e-5)
max_valid_f1=0
best_model={}
for e in tqdm(range(max_epoch_num)):
for batch in train_dataloader:
model.train()
optimizer.zero_grad()
input_ids=batch['input_ids'].to(cuda_device)
token_type_ids=batch['token_type_ids'].to(cuda_device)
attention_mask=batch['attention_mask'].to(cuda_device)
outputs=model(input_ids,token_type_ids,attention_mask)
train_loss=loss_func(outputs,batch['label'].to(cuda_device))
train_loss.backward()
optimizer.step()
#验证
with torch.no_grad():
model.eval()
labels=[]
predicts=[]
for batch in valid_dataloader:
input_ids=batch['input_ids'].to(cuda_device)
token_type_ids=batch['token_type_ids'].to(cuda_device)
attention_mask=batch['attention_mask'].to(cuda_device)
outputs=model(input_ids,token_type_ids,attention_mask)
labels.extend([i.item() for i in batch['label']])
predicts.extend([i.item() for i in torch.argmax(outputs,1)])
f1=f1_score(labels,predicts,average='macro')
if f1>max_valid_f1:
best_model=deepcopy(model.state_dict())
max_valid_f1=f1
#测试
model.load_state_dict(best_model)
with torch.no_grad():
model.eval()
labels=[]
predicts=[]
for batch in test_dataloader:
input_ids=batch['input_ids'].to(cuda_device)
token_type_ids=batch['token_type_ids'].to(cuda_device)
attention_mask=batch['attention_mask'].to(cuda_device)
outputs=model(input_ids,token_type_ids,attention_mask)
labels.extend([i.item() for i in batch['label']])
predicts.extend([i.item() for i in torch.argmax(outputs,1)])
print(task[0])
print(accuracy_score(labels,predicts))
print(precision_score(labels,predicts,average='macro'))
print(recall_score(labels,predicts,average='macro'))
print(f1_score(labels,predicts,average='macro'))
多任务代码:
import csv,random
from tqdm import tqdm
from copy import deepcopy
from sklearn.metrics import accuracy_score,precision_score,recall_score,f1_score
import torch
import torch.nn as nn
from torch.utils.data import Dataset,DataLoader
from transformers import AutoTokenizer,AutoConfig
from transformers.models.bert.modeling_bert import BertEmbeddings,BertEncoder,BertPooler
from transformers.modeling_outputs import BaseModelOutputWithPoolingAndCrossAttentions
from transformers.modeling_utils import ModuleUtilsMixin
instance=ModuleUtilsMixin()
#超参设置
random_seed=20221125
split_ratio='6-2-2'
pretrained_path='/data/pretrained_model/bert-base-chinese'
dropout_rate=0.1
max_epoch_num=1
cuda_device='cuda:2'
output_dim=[2,4]
#数据预处理
random.seed(random_seed)
#数据1
with open('/data/other_data/weibo_senti_100k.csv') as f:
reader=csv.reader(f)
header = next(reader) #表头
data = [[int(row[0]),row[1]] for row in reader] #每个元素是一个由字符串组成的列表,第一个元素是标签(01),第二个元素是评论文本。
random.shuffle(data)
split_ratio_list=[int(i) for i in split_ratio.split('-')]
split_point1=int(len(data)*split_ratio_list[0]/sum(split_ratio_list))
split_point2=int(len(data)*(split_ratio_list[0]+split_ratio_list[1])/sum(split_ratio_list))
train_data1=data[:split_point1]
valid_data1=data[split_point1:split_point2]
test_data1=data[split_point2:]
#数据2
with open('/data/other_data/simplifyweibo_4_moods.csv') as f:
reader=csv.reader(f)
header = next(reader) #表头
data = [[int(row[0]),row[1]] for row in reader] #每个元素是一个由字符串组成的列表,第一个元素是标签(01),第二个元素是评论文本。
random.shuffle(data)
split_ratio_list=[int(i) for i in split_ratio.split('-')]
split_point1=int(len(data)*split_ratio_list[0]/sum(split_ratio_list))
split_point2=int(len(data)*(split_ratio_list[0]+split_ratio_list[1])/sum(split_ratio_list))
train_data2=data[:split_point1]
valid_data2=data[split_point1:split_point2]
test_data2=data[split_point2:]
#建立数据集迭代器
class TextInitializeDataset(Dataset):
def __init__(self,input_data) -> None:
self.text=[x[1] for x in input_data]
self.label=[x[0] for x in input_data]
def __getitem__(self, index):
return [self.text[index],self.label[index]]
def __len__(self):
return len(self.text)
tokenizer=AutoTokenizer.from_pretrained(pretrained_path)
def collate_fn(batch):
pt_batch=tokenizer([x[0] for x in batch],padding=True,truncation=True,max_length=512,return_tensors='pt')
return {'input_ids':pt_batch['input_ids'],'token_type_ids':pt_batch['token_type_ids'],'attention_mask':pt_batch['attention_mask'],
'label':torch.tensor([x[1] for x in batch])}
train_dataloader1=DataLoader(TextInitializeDataset(train_data1),batch_size=16,shuffle=True,collate_fn=collate_fn)
train_dataloader2=DataLoader(TextInitializeDataset(train_data2),batch_size=16,shuffle=True,collate_fn=collate_fn)
valid_dataloader1=DataLoader(TextInitializeDataset(valid_data1),batch_size=128,shuffle=False,collate_fn=collate_fn)
valid_dataloader2=DataLoader(TextInitializeDataset(valid_data2),batch_size=128,shuffle=False,collate_fn=collate_fn)
test_dataloader1=DataLoader(TextInitializeDataset(test_data1),batch_size=128,shuffle=False,collate_fn=collate_fn)
test_dataloader2=DataLoader(TextInitializeDataset(test_data2),batch_size=128,shuffle=False,collate_fn=collate_fn)
config=AutoConfig.from_pretrained(pretrained_path)
#建模
class ClsModel(nn.Module):
def __init__(self,output_dim,dropout_rate):
super(ClsModel,self).__init__()
self.config=config
self.embedding1=BertEmbeddings(config)
self.embedding2=BertEmbeddings(config)
self.encoder=BertEncoder(config)
self.pooler=BertPooler(config)
self.dropout=nn.Dropout(dropout_rate)
self.classifier1=nn.Linear(768,output_dim[0])
self.classifier2=nn.Linear(768,output_dim[1])
def forward(self,input_ids,token_type_ids,attention_mask,type):
output_attentions=self.config.output_attentions
output_hidden_states=self.config.output_hidden_states
return_dict=self.config.use_return_dict
if self.config.is_decoder:
use_cache=self.config.use_cache
else:
use_cache = False
input_shape = input_ids.size()
batch_size, seq_length = input_shape
device = input_ids.device
# past_key_values_length
past_key_values_length = 0
if attention_mask is None:
attention_mask = torch.ones(((batch_size, seq_length + past_key_values_length)), device=device)
if type==1:
self.embeddings=self.embedding1
else:
self.embeddings=self.embedding2
# We can provide a self-attention mask of dimensions [batch_size, from_seq_length, to_seq_length]
# ourselves in which case we just need to make it broadcastable to all heads.
dtype=attention_mask.dtype
# We can provide a self-attention mask of dimensions [batch_size, from_seq_length, to_seq_length]
# ourselves in which case we just need to make it broadcastable to all heads.
if attention_mask.dim() == 3:
extended_attention_mask = attention_mask[:, None, :, :]
elif attention_mask.dim() == 2:
# Provided a padding mask of dimensions [batch_size, seq_length]
# - if the model is a decoder, apply a causal mask in addition to the padding mask
# - if the model is an encoder, make the mask broadcastable to [batch_size, num_heads, seq_length, seq_length]
if self.config.is_decoder:
extended_attention_mask = ModuleUtilsMixin.create_extended_attention_mask_for_decoder(
input_shape, attention_mask, device
)
else:
extended_attention_mask = attention_mask[:, None, None, :]
else:
raise ValueError(
f"Wrong shape for input_ids (shape {input_shape}) or attention_mask (shape {attention_mask.shape})"
)
# Since attention_mask is 1.0 for positions we want to attend and 0.0 for
# masked positions, this operation will create a tensor which is 0.0 for
# positions we want to attend and the dtype's smallest value for masked positions.
# Since we are adding it to the raw scores before the softmax, this is
# effectively the same as removing these entirely.
extended_attention_mask = extended_attention_mask.to(dtype=dtype) # fp16 compatibility
extended_attention_mask = (1.0 - extended_attention_mask) * torch.iinfo(dtype).min
encoder_extended_attention_mask = None
# Prepare head mask if needed
# 1.0 in head_mask indicate we keep the head
# attention_probs has shape bsz x n_heads x N x N
# input head_mask has shape [num_heads] or [num_hidden_layers x num_heads]
# and head_mask is converted to shape [num_hidden_layers x batch x num_heads x seq_length x seq_length]
head_mask=[None] *self.config.num_hidden_layers
embedding_output = self.embeddings(
input_ids=input_ids,
position_ids=None,
token_type_ids=token_type_ids,
inputs_embeds=None,
past_key_values_length=past_key_values_length,
)
encoder_outputs = self.encoder(
embedding_output,
attention_mask=extended_attention_mask,
head_mask=head_mask,
encoder_hidden_states=None,
encoder_attention_mask=encoder_extended_attention_mask,
past_key_values=None,
use_cache=use_cache,
output_attentions=output_attentions,
output_hidden_states=output_hidden_states,
return_dict=return_dict,
)
sequence_output = encoder_outputs[0]
pooled_output = self.pooler(sequence_output) if self.pooler is not None else None
if not return_dict:
return (sequence_output, pooled_output) + encoder_outputs[1:]
x=BaseModelOutputWithPoolingAndCrossAttentions(
last_hidden_state=sequence_output,
pooler_output=pooled_output,
past_key_values=encoder_outputs.past_key_values,
hidden_states=encoder_outputs.hidden_states,
attentions=encoder_outputs.attentions,
cross_attentions=encoder_outputs.cross_attentions,
)['pooler_output']
x=self.dropout(x)
if type==1:
self.classifier=self.classifier1
else:
self.classifier=self.classifier2
x=self.classifier(x)
return x
loss_func=nn.CrossEntropyLoss()
model=ClsModel(output_dim,dropout_rate)
model.to(cuda_device)
optimizer=torch.optim.Adam(params=model.parameters(),lr=1e-5)
max_valid_f1=0
best_model={}
for e in tqdm(range(max_epoch_num)):
for batch in train_dataloader1:
model.train()
optimizer.zero_grad()
input_ids=batch['input_ids'].to(cuda_device)
token_type_ids=batch['token_type_ids'].to(cuda_device)
attention_mask=batch['attention_mask'].to(cuda_device)
outputs=model(input_ids,token_type_ids,attention_mask,1)
train_loss=loss_func(outputs,batch['label'].to(cuda_device))
train_loss.backward()
optimizer.step()
for batch in train_dataloader2:
model.train()
optimizer.zero_grad()
input_ids=batch['input_ids'].to(cuda_device)
token_type_ids=batch['token_type_ids'].to(cuda_device)
attention_mask=batch['attention_mask'].to(cuda_device)
outputs=model(input_ids,token_type_ids,attention_mask,2)
train_loss=loss_func(outputs,batch['label'].to(cuda_device))
train_loss.backward()
optimizer.step()
#验证
with torch.no_grad():
model.eval()
labels=[]
predicts=[]
for batch in valid_dataloader1:
input_ids=batch['input_ids'].to(cuda_device)
token_type_ids=batch['token_type_ids'].to(cuda_device)
attention_mask=batch['attention_mask'].to(cuda_device)
outputs=model(input_ids,token_type_ids,attention_mask,1)
labels.extend([i.item() for i in batch['label']])
predicts.extend([i.item() for i in torch.argmax(outputs,1)])
f11=f1_score(labels,predicts,average='macro')
labels=[]
predicts=[]
for batch in valid_dataloader2:
input_ids=batch['input_ids'].to(cuda_device)
token_type_ids=batch['token_type_ids'].to(cuda_device)
attention_mask=batch['attention_mask'].to(cuda_device)
outputs=model(input_ids,token_type_ids,attention_mask,2)
labels.extend([i.item() for i in batch['label']])
predicts.extend([i.item() for i in torch.argmax(outputs,1)])
f12=f1_score(labels,predicts,average='macro')
f1=(f11+f12)/2
if f1>max_valid_f1:
best_model=deepcopy(model.state_dict())
max_valid_f1=f1
#测试
model.load_state_dict(best_model)
with torch.no_grad():
model.eval()
labels=[]
predicts=[]
for batch in test_dataloader1:
input_ids=batch['input_ids'].to(cuda_device)
token_type_ids=batch['token_type_ids'].to(cuda_device)
attention_mask=batch['attention_mask'].to(cuda_device)
outputs=model(input_ids,token_type_ids,attention_mask,1)
labels.extend([i.item() for i in batch['label']])
predicts.extend([i.item() for i in torch.argmax(outputs,1)])
print(accuracy_score(labels,predicts))
print(precision_score(labels,predicts,average='macro'))
print(recall_score(labels,predicts,average='macro'))
print(f1_score(labels,predicts,average='macro'))
labels=[]
predicts=[]
for batch in test_dataloader2:
input_ids=batch['input_ids'].to(cuda_device)
token_type_ids=batch['token_type_ids'].to(cuda_device)
attention_mask=batch['attention_mask'].to(cuda_device)
outputs=model(input_ids,token_type_ids,attention_mask,2)
labels.extend([i.item() for i in batch['label']])
predicts.extend([i.item() for i in torch.argmax(outputs,1)])
print(accuracy_score(labels,predicts))
print(precision_score(labels,predicts,average='macro'))
print(recall_score(labels,predicts,average='macro'))
print(f1_score(labels,predicts,average='macro'))
单任务实验结果:
(第二个数据集为什么会这样我也很迷茫,但是我结果打印出来确实是这样的!)
| 数据集 | accuracy | macro-P | macro-R | macro-F | 用时 |
|---|---|---|---|---|---|
| weibo_senti_100k | 90.04 | 50 | 45.02 | 47.38 | 32min |
| simplifyweibo_4_moods | 0 | 0 | 0 | 0 | 2h |
多任务实验结果:(耗时2h30min)
| 数据集 | accuracy | macro-P | macro-R | macro-F |
|---|---|---|---|---|
| weibo_senti_100k | 85.54 | 88.62 | 85.69 | 85.29 |
| simplifyweibo_4_moods | 57.33 | 43.07 | 30.15 | 27.81 |






![[附源码]Python计算机毕业设计Django病人跟踪治疗信息管理系统](https://img-blog.csdnimg.cn/90ad6d91c9e34831b3df3b75e2bc0db2.png)




![[Power BI] 认识Power Query和M语言](https://img-blog.csdnimg.cn/e237f6927ec44bed9544d3d5e9b28fd5.png)