目录
一、Flink概述
二、单机版安装配置
1.开启hadoop
2.解压Flink压缩包
3.修改文件名
4.开启客户端
5.访问webUI
三、集群配置
1.jobmanager配置
2.master配置
3.workers配置
4.分发配置
5.开启Flink集群
6.访问webUI
7.查看Job Manager
8.查看Task Managers
9.停止集群命令
10.webUI提交任务
11.命令行提交作业
12.命令行查看运行状态
13.查看所有正在运行的Flink作业
14.查看正在运行和已经取消的Flink作业
15.取消正在运行的Flink作业
16.再次查看已经取消的作业
四、Yarn模式配置
五、输出算子(sink)
1.获取Kafka生产者的消息,打印到控制台
2.开启kafka生产者
3.启动IDEA程序,然后在生产者输入内容,控制台就能够消费到
一、Flink概述
Flink 是 Apache 基金会旗下的一个开源大数据处理框架,Flink是专门处理实时数据的,下面是一段wordcount代码:
import org.apache.flink.api.java.utils.ParameterTool
import org.apache.flink.streaming.api.scala._
object StreamWordCount {
def main(args: Array[String]): Unit = {
// 1.创建一个流式执行环境
val env: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment
// 2.读取socket文本流数据
// val lineDataStream: DataStream[String] = env.socketTextStream("lxm147",7777)
val parameterTool: ParameterTool = ParameterTool.fromArgs(args)
val hostname: String = parameterTool.get("host")
val port: Int = parameterTool.getInt("port")
val lineDataStream: DataStream[String] = env.socketTextStream(hostname, port)
val sum1: DataStream[(String, Int)] = lineDataStream
.flatMap(_.split(" "))
.map((_, 1))
.keyBy(_._1)
.sum(1) // 二元组的第二个元素做统计
sum1.print()
env.execute()
}
}运行架构:程序中一系列操作就是Job,Job中每一步转换计算的操作就是Task,要把每一个Task运行在不同的节点或线程上。
客户端将代码转换为真正可以执行的作业,将作业提交给JobManager(协调调度中心),然后JobManager根据当前业务的资源进行作业任务的分配,将作业分配给TaskManager(工作节点),就可以进行业务执行。
任务槽:taskmanager.numberOfTaskSlots:1 针对每一个具体的任务给它分配的具体的系统资源,代表当前的taskmanager能够并行执行多少任务,这里的1是指一个Task不能并行执行任务,如果配置数量大一些,就相当于当前一个Task可以并行执行任务,设置了任务槽的数量,运行时未必会占用。
并行度:parallelism.default: 1任务真正运行时一个任务到底如何去并行。
二、单机版安装配置
1.开启hadoop
start-all.sh2.解压Flink压缩包
tar -zxf flink-1.13.0-bin-scala_2.12.tgz -C /opt/module/3.修改文件名
mv /opt/softwore/flink-1.13.0/ flink4.开启客户端
[lxm@linux102 flink]$ ./bin/start-cluster.sh 5.访问webUI
linux102:8081三、集群配置

1.jobmanager配置
vim /opt/module/flink/conf/flink-conf.yaml
jobmanager.rpc.address: linux102
2.master配置
vim /opt/module/flink/conf/masters
linux1023.workers配置
vim /opt/module/flink/conf/workers
linux103
linux104 4.分发配置
xsync /opt/module/flink5.开启Flink集群
[lxm@linux102 flink]$ ./bin/start-cluster.sh 6.访问webUI

7.查看Job Manager

8.查看Task Managers
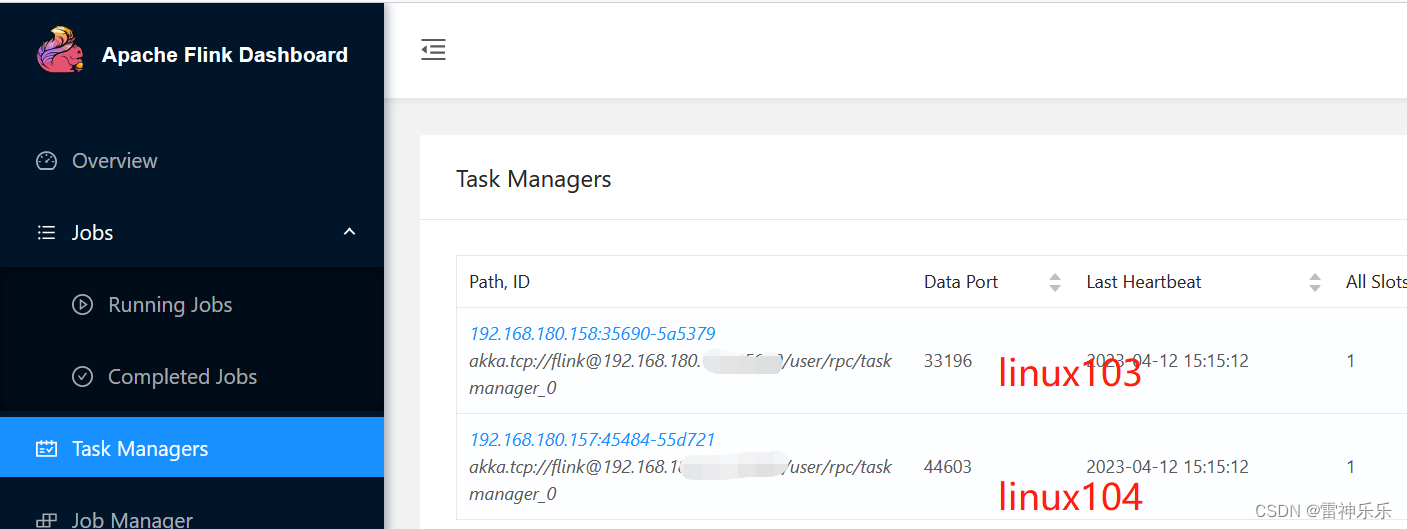
9.停止集群命令
[lxm@linux102 flink]$ ./bin/stop-cluster.sh10.webUI提交任务
(1)添加打包插件
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-assembly-plugin</artifactId>
<version>3.0.0</version>
<configuration>
<descriptorRefs>
<descriptorRef>jar-with-dependencies</descriptorRef>
</descriptorRefs>
</configuration>
<executions>
<execution>
<id>make-assembly</id>
<phase>package</phase>
<goals>
<goal>single</goal>
</goals>
</execution>
</executions>
</plugin>
</plugins>
</build>(2)打包

(3)提交jar包
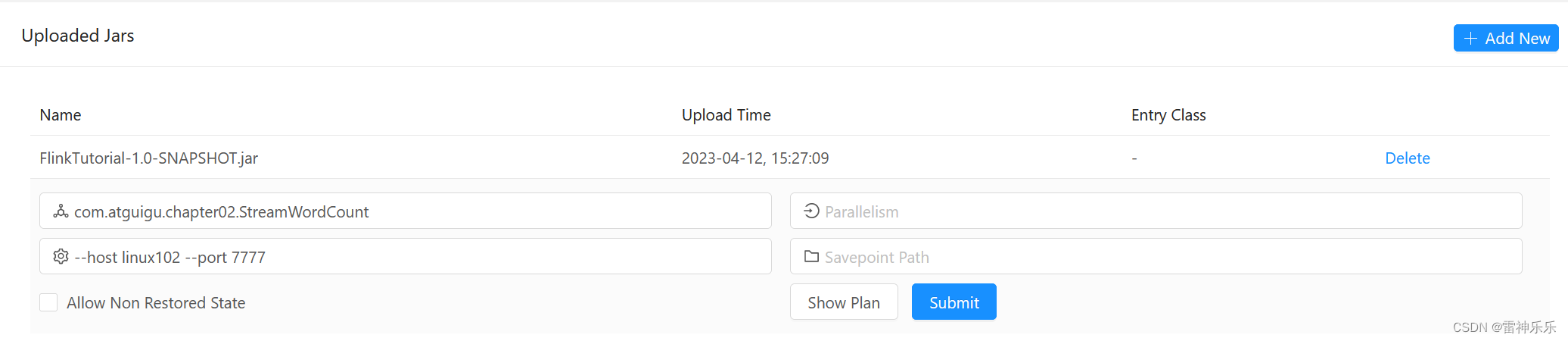
(4)开启服务器

(5)show plan
 (6)submit
(6)submit
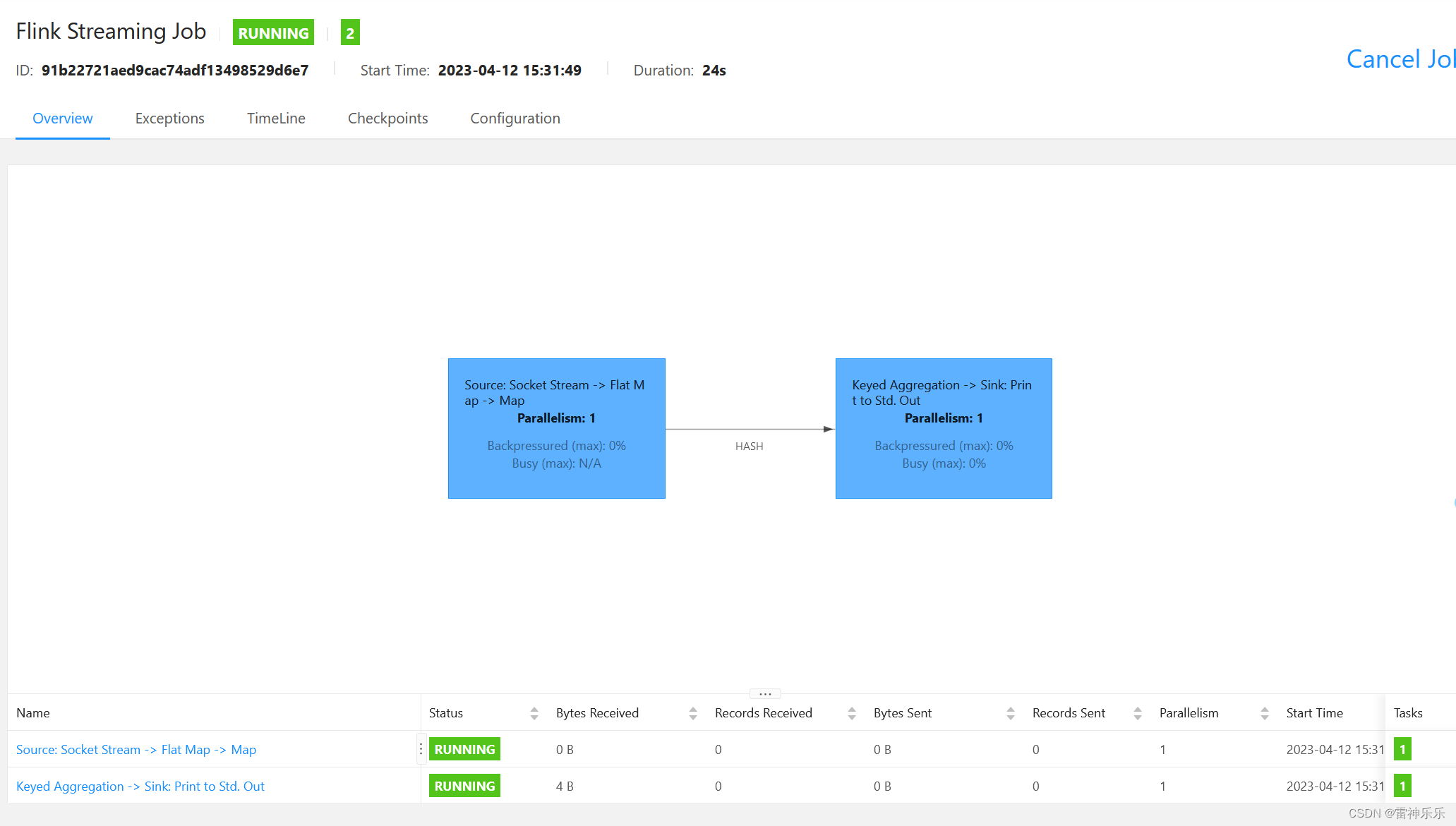
任务槽只占用了一个
 (7)客户端输入内容
(7)客户端输入内容

(8)查看结果
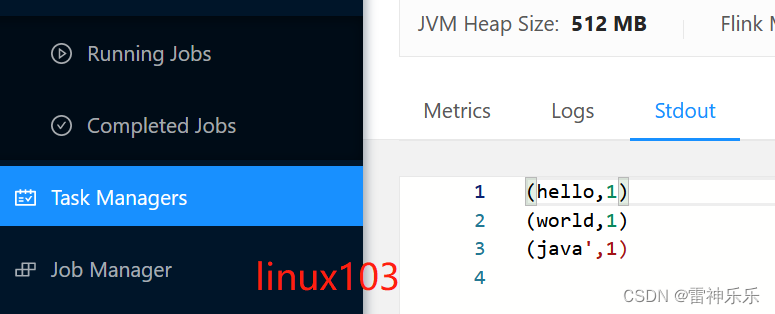
(9)关闭服务

任务槽恢复

11.命令行提交作业
开启客户端
[lxm@linux102 flink]$ nc -lk 7777
[lxm@linux102 flink]$ ./bin/flink run -m linux102:8081 -c com.atguigu.chapter02.StreamWordCount -p 2 ./FlinkTutorial-1.0-SNAPSHOT.jar --host linux102 --port 7777


 socket文本流无法并行,所以并行度是1
socket文本流无法并行,所以并行度是1
12.命令行查看运行状态
Job has been submitted with JobID baed661e5b5011b4f799a53fd5999122
[lxm@linux102 flink]$ ./bin/flink list baed661e5b5011b4f799a53fd5999122
Waiting for response...
------------------ Running/Restarting Jobs -------------------
12.04.2023 15:43:50 : baed661e5b5011b4f799a53fd5999122 : Flink Streaming Job (RUNNING)
--------------------------------------------------------------
No scheduled jobs.
13.查看所有正在运行的Flink作业
[lxm@linux102 flink]$ ./bin/flink list
Waiting for response...
------------------ Running/Restarting Jobs -------------------
12.04.2023 15:43:50 : baed661e5b5011b4f799a53fd5999122 : Flink Streaming Job (RUNNING)
--------------------------------------------------------------
No scheduled jobs.14.查看正在运行和已经取消的Flink作业
[lxm@linux102 flink]$ ./bin/flink list -a
Waiting for response...
------------------ Running/Restarting Jobs -------------------
12.04.2023 15:43:50 : baed661e5b5011b4f799a53fd5999122 : Flink Streaming Job (RUNNING)
--------------------------------------------------------------
No scheduled jobs.
---------------------- Terminated Jobs -----------------------
12.04.2023 15:31:49 : 91b22721aed9cac74adf13498529d6e7 : Flink Streaming Job (CANCELED)
12.04.2023 15:43:01 : 9326b8e938c7ef6d408bf359af99c956 : Flink Streaming Job (FAILED)
--------------------------------------------------------------15.取消正在运行的Flink作业
[lxm@linux102 flink]$ ./bin/flink cancel baed661e5b5011b4f799a53fd5999122
Cancelling job baed661e5b5011b4f799a53fd5999122.
Cancelled job baed661e5b5011b4f799a53fd5999122.16.再次查看已经取消的作业
[lxm@linux102 flink]$ ./bin/flink list -a
Waiting for response...
No running jobs.
No scheduled jobs.
---------------------- Terminated Jobs -----------------------
12.04.2023 15:31:49 : 91b22721aed9cac74adf13498529d6e7 : Flink Streaming Job (CANCELED)
12.04.2023 15:43:01 : 9326b8e938c7ef6d408bf359af99c956 : Flink Streaming Job (FAILED)
12.04.2023 15:43:50 : baed661e5b5011b4f799a53fd5999122 : Flink Streaming Job (CANCELED)
--------------------------------------------------------------四、Yarn模式配置
YARN 上部署的过程是:客户端把 Flink 应用提交给 Yarn 的 ResourceManager, Yarn 的 ResourceManager 会向 Yarn 的 NodeManager 申请容器。在这些容器上,Flink 会部署 JobManager 和 TaskManager 的实例,从而启动集群。Flink 会根据运行在 JobManger 上的作业 所需要的 Slot 数量动态分配 TaskManager 资源。
$ sudo vim /etc/profile.d/my_env.sh HADOOP_HOME=/opt/module/hadoop-2.7.5 export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin export HADOOP_CONF_DIR=${HADOOP_HOME}/etc/hadoop export HADOOP_CLASSPATH=`hadoop classpath`注意:记得分发集群
五、输出算子(sink)
1.获取Kafka生产者的消息,打印到控制台
import org.apache.flink.api.common.serialization.SimpleStringSchema
import org.apache.flink.streaming.api.scala._
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer
import java.util.Properties
object SourceKafkaTest {
def main(args: Array[String]): Unit = {
// 获取流执行环境
val env: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment
env.setParallelism(1)
// 用Properties保存Kafka连接的相关配置
val properties = new Properties()
properties.setProperty("bootstrap.servers", "linux102:9092")
properties.setProperty("group.id", "consumer-group")
val stream: DataStream[String] = env
.addSource(new FlinkKafkaConsumer[String]("clicks", new SimpleStringSchema(), properties))
stream.print()
env.execute()
}
}2.开启kafka生产者
[lxm@linux102 flink]$ kafka-console-producer.sh -broker-list linux102:9092 --topic clicks3.启动IDEA程序,然后在生产者输入内容,控制台就能够消费到