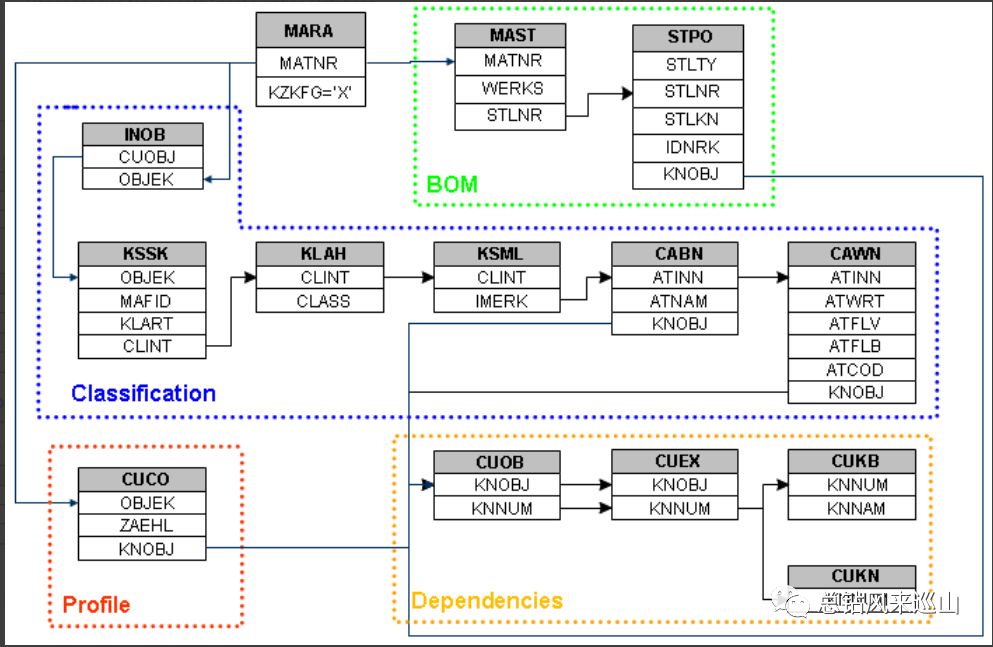
demo主页(包含paper, demo, dataset)
通过demo可以看到一个酷炫的效果,鼠标放在任何物体上都能实时分割出来。
segment anything宣传的是一个类似BERT的基础类模型,可以在下游任务中不需要再训练,直接用的效果。
而且是一种带有提示性的分割模型,
提示可以有多种:点,目标框,mask等。
为了达到像NLP那样zero-shot和few-shot的推广效果,
paper从三个方面入手:
1.Task,这个task需要能提供一个强大的pretraining模型,使下游很多任务都能推广使用。
2.Model,支持多种提示信息,在互动中实时输出分割mask。
3.数据集,现有的分割数据集都不够充足。
Task:
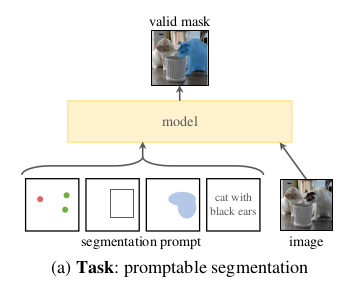
当有新的数据集时(以前没见过),通过提示信息也能做到zero-shot, few-shot。
提示就是指你要分割什么,比如通过点击图片上的一点或者给一个目标框,或者提供一个Text。
需要解决的是模糊的提示下也能给出有效的mask.
比如在一个T-shirt上给一个点,那么是要分割出T-shirt还是要分割出穿这个T-shirt的人呢。
提示性的分割task包含一个提前训练好的模型,通过提示信息解决下游任务。
Model:
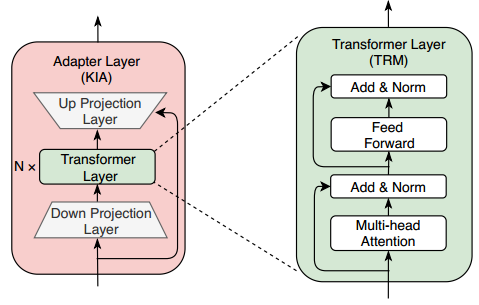
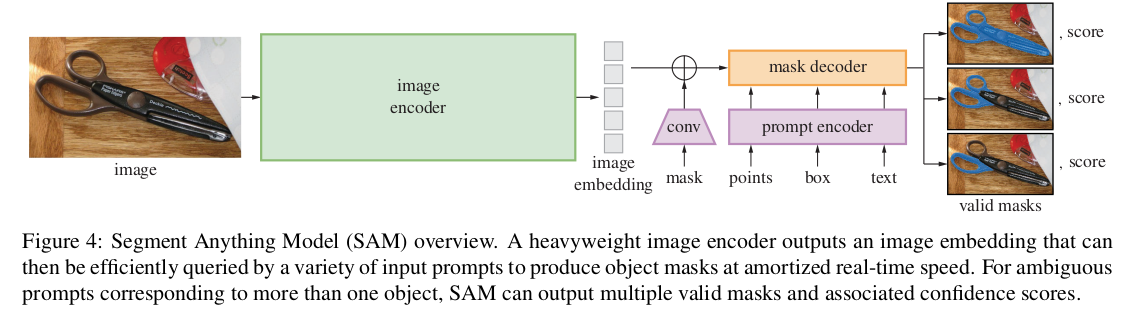
主要是transformer.
需要一个强有力的encoder计算出image embedding.
提示信息的encoder用来embed 提示信息,
然后在mask decoder中把image和提示信息的embedding融合起来。
这个模型就叫做SAM(segment anything model).
模型中image encoder和后面的decoder是分开的,
所以计算出的image embedding可以重复使用,
在给定image embedding的条件下,仅仅用提示信息encoder和mask decoder做出后面的分割预测就会达到实时效果。
比如网页上的demo效果。
所以说,SAM模型并不是真的实时,只是在提前计算好image embedding的前提下才是实时。
对于有歧义的提示(比如点在T-shirt上的案例,是分割T-shirt还是分割穿T-shirt的人)。一般会给出多个mask,
paper中指出一般3个mask就够了,一个是整体,一个部分,一个再部分。

image encoder部分需要强大的pre-training方法,paper中采用了MAE 预训练的ViT.
(MAE是2022 kaiming大牛提出的)
prompt encoder:
提示信息包含sparse信息(点,目标框,text)和dense信息(mask)。
对于点和目标框,用positional encoding, 然后和image embedding结合。
dense提示(mask)用conv层进行embed, 然后和image embedding做element-wise和。
mask decoder:
transformer decoder block的修改版。
decoder模块中用到了prompt self attention和cross attention(两个方向:提示和image embedding,反向).
损失函数:
focal loss, dice loss的线性结合。
SAM Data engine:
数据集标注问题,分为3个阶段。
1.SAM辅助人工标注
这一阶段以人工标注为主,通过点击前景/背景物体上的点,SAM会作分割。然后人工会用一个刷子,橡皮工具修改mask. 因为image embedding是提前计算好的,所以会实时给出mask.
对于语义并没有过多限制,按物体的突出程度顺序标注,过于复杂的mask(标注超过30s)这一阶段会跳过。
那么最开始的SAM用什么数据集训练呢,用的是公共数据集,比如COCO。当有了一定的标注数据集之后,会用新的标注数据重新训练,数据集多起来以后,会增加模型的复杂程度,比如把ViT-B换成ViT-H。
这样重新训练了6轮。由于模型不断精确,标注时间也在降低,从34s降到14s.
2.SAM半自动标注
这一阶段在于增加模型的多样性,标注次突出的物体。首先让模型标注一部分,然后人工标注没有被模型标注的部分。
人工标注时间又回到了34s, 因为大部分都被模型标出来了,剩下的是更加challenging的物体。
3.全自动标注
经过第一阶段,训练集多了,模型准确率有所提升,也有了mask的多样性。
第2阶段解决了提示信息有歧义情况下的预测。
现在,给模型提示32x32的grid,每个点都要对有效目标预测一系列的mask.
然后用IOU阈值选择confident masks. 最后用NMS滤掉多余的mask.
实验,discussion,conclusion部分跳过。
paper主体部分比较宏观,更多的细节部分在附录。
下次再写吧。